1. DKVMN工作机制
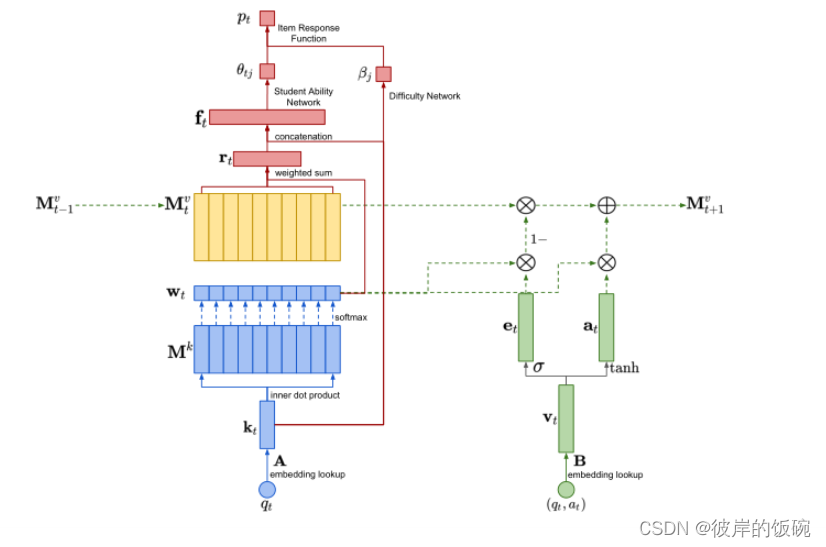
概述
蓝色分量描述获取注意权值的过程,绿色分量描述更新值记忆的过程,红色分量描述预测的过程。⊗和⊕分别表示按元素进行的乘法和加法。
1.1 获取注意力权重
接收问题q t q_tqt
从KC嵌入矩阵A AA ∈ R Q × d k R^{Q×d_k}RQ×dk 提取q t q_tqt 的嵌入向量 记作k t k_tkt
查询DKVMN模型中的密钥存储矩阵M k M_kMk 查询结果为该题目应该在每个知识点上投入的权重w t w_twt∈R N R^NRN ,计算方式如下
w t i = S o f t m a x ( M i k k t ) w_{ti}=Softmax(M^k_ik_t)wti=Softmax(Mikkt)
1.2 对该题目用户的做对概率做预测(读过程)
DKVMN模型读取t时刻值存储器M t v M^v_tMtv中的潜在知识状态,形成读取向量
r t = Σ i = 1 N w t i ( M t i v ) T r_t=Σ^N_{i=1}w_{ti}(M^v_{ti})^Trt=Σi=1Nwti(Mtiv)T
其中M t i v M^v_{ti}Mtiv是M t v M^v_tMtv的第i个行向量 表示第i个学生的知识储备状态
将读取向量r t r_trt与KC嵌入向量k t k_tkt垂直拼接在一起生成一个特征向量f t f_tft, 并计算做对该题的概率
f t = t a n h ( W f [ r t , k t ] + b f ) f_t=tanh(W_f[r_t,k_t]+b_f)ft=tanh(Wf[rt,kt]+bf)
p t = P ( a t ) = σ ( W p f t + b p ) p_t=P(a_t)=σ(W_pf_t+b_p)pt=P(at)=σ(Wpft+bp)
1.3 更新V值内存(写操作) (更新M t v M^v_tMtv矩阵)
输入元组( q t , a t ) (q_t,a_t)(qt,at) 表示t时刻输入的题目与用户做题情况
输入w t w_twt权重
从KC响应矩阵B ∈ R 2 Q × d v B∈R^{2Q×d_v}B∈R2Q×dv中检索( q t , a t ) (q_t,a_t)(qt,at)的嵌入向量,记作v t ∈ R d v v_t∈R^{d_v}vt∈Rdv
- 代表在标签为at的KC q t q_tqt上工作后的知识增长。
当更新内存的时候,一些内存首先用之前的擦除向量e t ∈ R d v e_t∈R^{d_v}et∈Rdv擦除 (擦除记忆类似于LSTM细胞的遗忘功能)
将新向量加入到内存中 a t ∈ R d v a_t∈R^{d_v}at∈Rdv每个值内存槽更新如下所示
e t = σ ( W e V t + b e ) e_t=σ(W_eV_t+b_e)et=σ(WeVt+be)
a t = t a n h ( W a v t + b a ) a_t=tanh(W_av_t+b_a)at=tanh(Wavt+ba)
M ‾ t + 1 , i v = M t i v × ( 1 − w t i e t ) T \overline{M}^v_{t+1,i}=M_{ti}^v×(1-w_{ti}e_t)^TMt+1,iv=Mtiv×(1−wtiet)T
M t + 1 , i v M_{t+1,i}^vMt+1,iv= M ‾ t + 1 , i v =\overline{M}_{t+1,i}^v=Mt+1,iv+ w t i a t T +w_{ti}a^T_t+wtiatT
(其中第三行×为元素级乘法,即两个向量里面每个元素两两相乘)