**
python3爬取微博评论并存为xlsx
**
由于微博电脑端的网页版页面比较复杂,我们可以访问手机端的微博网站,网址为:https://m.weibo.cn/
一、访问微博网站,找到热门推荐链接
我们打开微博网站后看见热门页,按F12查看网页结构后只能看见如下图短短的几个文章。
然后我们将滚动条向下滚动,发现新的文章会在底部加载,原来微博的热门文章加载方式是Ajax加载的,那我们就不能在网页源码中找标签了,我们点击如下图所示的network标签,找找请求地址。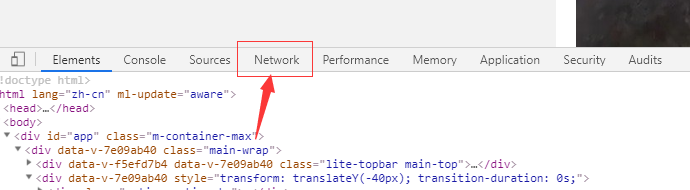
我们查看请求返回值后发现下图的请求返回的是一个json格式的数据。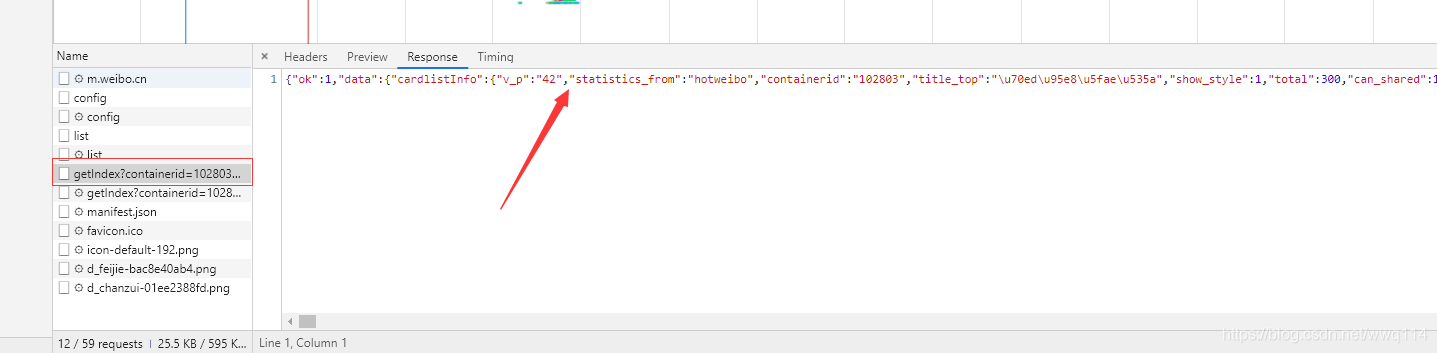
其实这就是热门文章存放的地址。在headers中找到gRequest请求的链接,是:https://m.weibo.cn/api/container/getIndex?containerid=102803&openApp=0
二、requests请求获取json数据
我们利用requests获取目标地址返回的json数据,并对其进行打印:
response = requests.get(self.con_url, headers=self.headers)
data = json.loads(response.text)
pprint.pprint(data)
使用pprint来输出,可以按json格式输出获得的结果,这样方便查看,如下图: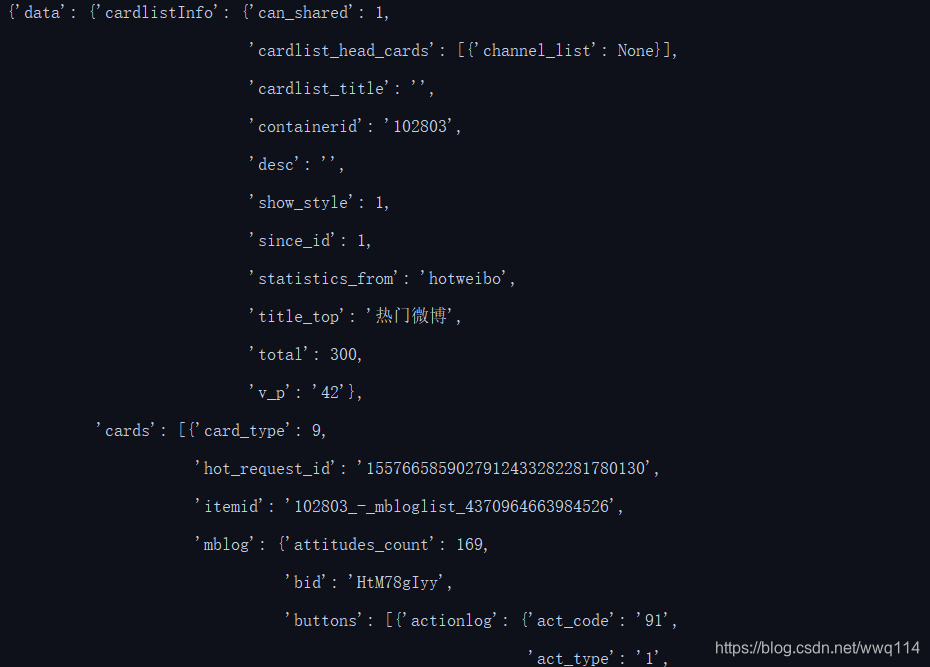
三、提取文章信息
文章的所有信息都存放在我们获取的json数据中,接下来我们只要根据键去取对应的值即可:
data1 = data['data']['cards']
# pprint.pprint(data1)
for card_group in data1:
try:
for mblog in card_group['card_group']:
pprint.pprint(mblog['mblog']['id'])
link_list.append(mblog['mblog']['id'])
# pprint.pprint(card_group['card_group'])
except:
pprint.pprint(card_group['mblog']['id'])
link_list.append(card_group['mblog']['id'])
我们获取了文章的id可以根据文章的id访问文章的详细信息。
四、访问文章详情,获取用户评论及信息
对文章的地址进行拼接,获取评论区用户信息及评论内容。
datas = {} # 存放用户ID以及评论内容
ID = [] # 存放用户ID
comment = [] # 存放用户评论
name = [] # 存放用户名
for link in links:
url = self.urlhead + link + self.urlend + link + '&max_id_type=0'
print(url)
response = requests.get(url, headers=self.headers)
try:
details = json.loads(response.text)['data']['data']
except:
print('ok--------------')
# print(details)
for content in details:
user_id = content['user']['id']
text = content['text']
user_name = content['user']['screen_name']
# print(user_id)
# print(text)
ID.append(user_id)
comment.append(text)
name.append(user_name)
datas['用户ID'] = ID
datas['昵称'] = name
datas['评论'] = comment
将获取的用户信息存为字典。
五、将用户信息存入Excel表格
def save_datas(self, datas):
datas = DataFrame(datas) # 将字典转换为DataFrame对象
datas.to_excel('pinglun/datas.xlsx', encoding='utf-8')
print('数据写入成功')
源码如下:
import requests
import json
import pprint
from pandas import DataFrame
class WeiboSpider:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"
}
self.con_url = 'https://m.weibo.cn/api/container/getIndex?containerid=102803&openApp=0'
self.urlhead = 'https://m.weibo.cn/comments/hotflow?id='
self.urlend = '&mid='
def get_link(self):
link_list = []
response = requests.get(self.con_url, headers=self.headers)
data = json.loads(response.text)
data1 = data['data']['cards']
# pprint.pprint(data1)
for card_group in data1:
try:
for mblog in card_group['card_group']:
pprint.pprint(mblog['mblog']['id'])
link_list.append(mblog['mblog']['id'])
# pprint.pprint(card_group['card_group'])
except:
pprint.pprint(card_group['mblog']['id'])
link_list.append(card_group['mblog']['id'])
self.load_page(link_list)
def load_page(self, links):
datas = {} # 存放用户ID以及评论内容
ID = [] # 存放用户ID
comment = [] # 存放用户评论
name = [] # 存放用户名
for link in links:
url = self.urlhead + link + self.urlend + link + '&max_id_type=0'
print(url)
response = requests.get(url, headers=self.headers)
try:
details = json.loads(response.text)['data']['data']
except:
print('ok--------------')
# print(details)
for content in details:
user_id = content['user']['id']
text = content['text']
user_name = content['user']['screen_name']
# print(user_id)
# print(text)
ID.append(user_id)
comment.append(text)
name.append(user_name)
datas['用户ID'] = ID
datas['昵称'] = name
datas['评论'] = comment
self.save_datas(datas)
def save_datas(self, datas):
datas = DataFrame(datas) # 将字典转换为DataFrame对象
datas.to_excel('pinglun/datas.xlsx', encoding='utf-8')
print('数据写入成功')
if __name__ == '__main__':
crawl = WeiboSpider()
crawl.get_link()
版权声明:本文为wwq114原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。