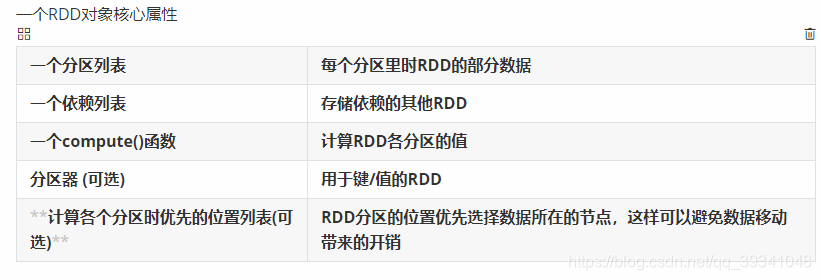
sparkcore:基本数据抽象是rdd
RDD:弹性分布式数据集 分布存储,分散在各个节点上,便于并行对RDD的数据进行并行计算
特点:
1.RDD是只可读的,一旦生成,内容就无法修改
2.RDD可以指定缓存在内存中。一般计算都是流水式生成、使用RDD,新的RDD生成后,旧的RDD不再使用,并被java虚拟机回收掉。当后续有多个计算依赖于某个RDD时,可以让这个RDD缓存到内存中,避免重复计算。
3.RDD可以通过计算得到,RDD的可靠性不是靠复制实现的,而是通过记录足够的计算过程,在需要重新从头或者某个镜像重新计算来恢复的。
RDD的依赖
1.窄依赖:依赖上级RDD的部分分区
使用窄依赖时,可以精确知道依赖的上级RDD的分区。一般情况下,会选择与自己在同一节点的上级RDD分区,这样计算在同一节点上,没有IO开销,常见的map,filter,flatmap
2.shuffle依赖:依赖上级RDD的所有分区。以shuffle依赖为分隔,Task被分成Stage,方便计算时的管理
3.RDD维护依赖关系和计算方法保证重新计算来恢复RDD。
问题:当依赖链太长,通过恢复的代价太大?
Spark提供一种检查点机制,对于依赖链太长的计算,对中间结果保存一份快照,这样就不需要从头开始计算了。
Shuffle
1.依赖关系是宽依赖,即依赖前一个RDD的所有分区。将相同的key但是分布在不同节点上的成员聚合到一个节点上,重组的过程就是shuffle。
2.shuffle操作的结果就是一次调度的Stage的结果,而一次Stage包含多个Task
3.shuffle使用本地磁盘目录有 spark.local.dir 属性指定
sparkSql
底层基本数据抽象是dataframe(新版本是dataset[ROW]),就是Spark生态系统中一个开源的数据仓库组件,可以认为是Hive在Spark的实现,用来存储历史数据,做OLAP、日志分析、数据挖掘、机器学习等等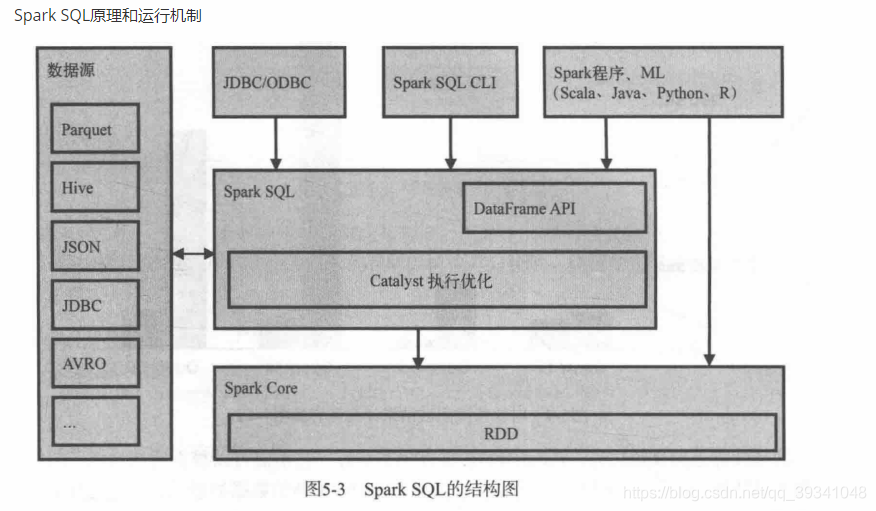
版权声明:本文为qq_39341048原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。