前言
首先要知道什么是值类型和引用类型,这个基础的知识点如果还不知道就去百度一下。
这里加些补充,图片来源慕课。
值类型: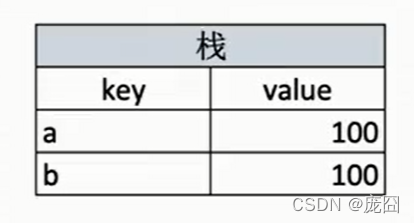
引用类型: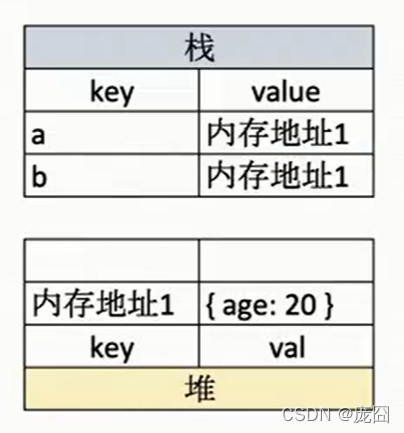
这种机制就是为了优化空间和性能。
空间:例如,栈的空间可以做到很小,因为引用类型放在栈中只是一个引用地址而已。
性能:一般来说值类型的数据量不会很大,但是引用类型可以做到很大,例如十几mb的树结构数据,十几mb的图表数组数据等等,引用类型做拷贝时只是复制地址,所以性能较好。
值类型:数字、字符、undefined、symbol等。
引用类型:对象、函数(也可以单独看作是函数类型)、数组、null(指向空地址)等。
浅拷贝
只要对引用类型进行直接赋值拷贝,都会发生浅拷贝现象。因为引用类型存的其实是堆内存中引用特定某个存储空间的地址,而真正内容在这个地址对应的存储空间上。也就是多个引用类型可能共用一个存储空间。
比如,数组
var arr = [1, 2, 3];
var brr = arr; // 将arr拷贝给brr,也就是指针的拷贝
arr[0] = 'zhangsan';
console.log(arr, brr); // 一起改变
再比如对象
var obj1 = {
a: "hello"
}
var obj2 = obj1; // 引用类型拷贝,都指向同一个原生对象
obj2.a = "world";
console.log(obj1.a, obj2.a) // a都变成"world"
当然,这样子把对象的基本类型属性直接赋值给其他变量者不会发生浅拷贝现象:
let obj = {
a: '1'
}
let a = obj.a
a = '2'
consolo.log(obj.a) // 还是1
如果是引用类型的属性直接赋值就会发生浅拷贝现象。
来个简单的题开个胃:
var obj1 = {
age:18,
arr:[1,2,3] //object类型 引用类型
}
function copy(obj1){ // 函数:把一个对象里的属性遍历赋值给一个新的对象并返出
var obj2 = {}
for(var k in obj1){
obj2[k]=obj1[k] //万变不离其宗,当把属性值为数组的东西赋值给另一个对象的属性,也是引用
}
return obj2;
}
var obj2 = copy(obj1);
obj1.arr[0]='ooo';
console.log(obj1.arr,obj2.arr) // 请自己思考一下再去打印
题外话:
obj1={a:1}; obj2={a:1}这两者虽然值是一样的,但是引用地址是不一样的,所以二者不相等。
深拷贝
与浅拷贝相对应的就是深拷贝,是单独开一个堆内存空间存放变量的内容。也就是一个变量对应一个单独的内存空间。
举个实现深拷贝函数的例子:
function deepClone(value = {}) {
// 递归中,如果是值类型直接返回
if (typeof value !== 'object' || value === null) return value
// 数组还是对象的初始化,为了不让下面的循环报错
let result
result = value instanceof Array ? [] : {}
// 循环进行递归
for (let i in value) {
if (value.hasOwnProperty(i)) result[i] = deepClone(value[i]) // 先判断不是原型上的属性才进行递归操作
}
// 递归返回
return result
}
使用:
let arr = [1, 2, 3, [4, 5]]
let brr = deepClone(arr)
arr[3][0] = 6
console.log(arr[3], brr[3]) // [6, 5] [4, 5]
引用类型作为函数实参
如果把一个引用类型变量作为实参传入一个函数中,函数内部再对其重新赋值,那么函数外的这个变量指针会被改变吗?
var type = "image";
var size = {width: 800, height:600};
var format = ['jpg','png'];
function change(type, size, format){
type = 'video';
size = {width:1024, height:768};
format.push('mp4');
}
change(type, size, format); //考点:函数的传参也会分析参数的引用类型
console.log(type,size,format); // 思考一下再去运行啊
解析:把引用类型当做参数去使用时,如果是重新赋值 =
,那么会为它单独创建一个引用地址,也就是这个重新赋值的变量是另外一个变量,如果是修改就还是引用特性。
重点:如果遇到符合这个情况的函数就不要多写一步深拷贝了,但!如果本身就是个递归函数,涉及到了把赋得的值传入递归函数中,就会形成闭包,需要手动在赋值的哪一步进行深拷贝操作!!!!
例如,一个变量需要不断的重复作为入参调用某个函数,就需要进行深拷贝。
连续赋值
来道连续赋值的题(以下简称连等)
var a = {n:1}
var b = a
a.x = a = {n:2}
// 请问一下打印什么
console.log(a.x)
console.log(b.x)
是不是打印出来有点蒙?哈哈。
先记住规则:
1 连等是从右向左分析
2 连等赋值之前,程序会把变量的引用都保存起来,连等过程都是假设等于,等到全部假设完了再一起赋值
解释:
容我用ppt画几个图。
首先a变量引用堆内存中的{n:1},b变量也引用它。

然后执行到连等 a.x = a = {n:2}
先分析右边第一个等,a = {n:2},a假设引用{n:2}(但是还没真正引用,所以a还是在引用{n:1})。
然后再分析a.x = a,a在引用{n:1}的内存空间内又假设x:{n:2}。

最后,两个假设全部成立,此时a引用对象成为{n:2},b因为自始至终都引用{n:1}的那个内存空间,所以b为{n:1,x:{n:2}}。

够清楚了吧,哈哈。
个人在工作中喜欢使用的深拷贝方法
有时候,浅拷贝使用得当能很灵活的处理一些问题,但如果所有情况都不加以控制,工程量一大,容易导致数据流出问题,下面举例个人在工作中喜欢使用的深拷贝方法。
对象和数组都可以使用
json转换
let obj = JSON.parse(JSON.stringify(obj)) // json转换,但这种方式如果数据量很大的话,会非常影响性能
这个方式的好处是,无论一维还是多维的对象和数组都是可以深拷贝的。
但也有缺点:例如对象中存在函数属性转换后会直接消失,存在Date类型的属性转换后会变成字符串格式,超长的数字字符串转换完后会有精度损失等。所以使用的时候还是要谨慎。
es6的…
arr = [1, 2, 3, ...brr] // es6语法,只能拷贝一维数组
obj = {{}, ...obj1, ...obj2} // 只能拷贝一维对象
这种拷贝方式个人感觉比Object.assign() 要灵活。
Object.assign()
let obj = Object.assign({},obj) // 只能拷贝一维对象
let obj = Object.assign([],arr) // 只能拷贝一维数组
这个方式有副作用,如果把原值放在第一个参数,那么原值就会被改变:
let obj = { a: 1 }
Object.assign(obj, { b: 1 })
console.log(obj) // { a: 1, b: 1 }
拆分拷贝
具体看上面深拷贝函数实现的例子…这是最稳妥的方式。
数组专用
arr1 = [].concat(arr2) // 只能拷贝一维数组
brr = arr.slice() // 只能拷贝一维数组
注意:通过以上方式进行的深拷贝都不会== 或者 === 于原来的变量。
总结
每当进行变量拷贝的时候,就要条件反射的考虑到深浅拷贝的问题。