前言
本文介绍了一个天涯网站关键词搜索的爬虫实现
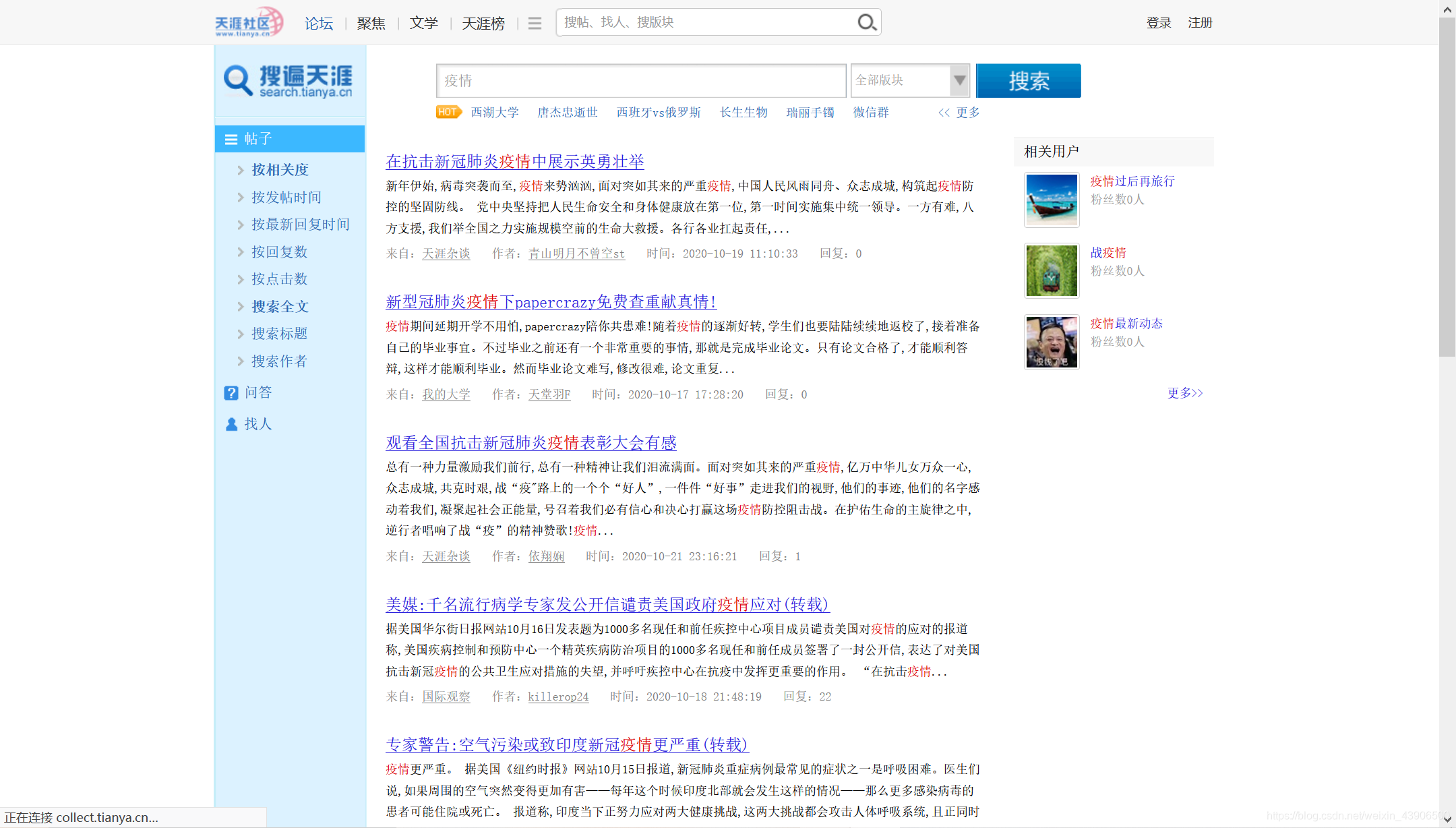
内容
相关爬取内容如下所示
代码
# 账号列表
# 对应关系二维列表
from pyquery import PyQuery as pq
import requests
from urllib.parse import quote
from time import sleep
import json
page = 75
key_word = '新冠疫情'
def prase_all_page(urls):
"""
解析所有搜索页,获取帖子url,过滤无评论帖子
:param urls:
:return: content_urls
"""
content_urls = []
for url in urls:
sleep(1)
print('正在抓取:', url)
doc = pq(requests.get(url=url, timeout=30).text)
# print(doc)
doc('.searchListOne li:last-child').remove() # 删除最后一个无用li节点
lis = doc('.searchListOne li').items() # 获取content节点生成器
for li in lis:
reverse = li('.source span:last-child').text()
a = li('a:first-child')
content_url = a.attr('href')
# print(content_url)
# print('评论数:', reverse)
content_urls.append(content_url)
return content_urls
def prase_all_content(urls):
"""
获取网页相关信息
:param urls:
:return:
"""
dic = []
i = 0
for url in urls:
print(i)
i = i + 1
try:
dic1 = {}
print('正在解析:', url)
doc = pq(requests.get(url=url, timeout=30).text)
title = doc('.atl-head .atl-title').text()
main_id = doc('.atl-head .atl-menu').attr('_host')
replytime = doc('.atl-head .atl-menu').attr('js_replytime')
replycount = doc('.atl-head .atl-menu').attr('js_replycount')
clickcount = doc('.atl-head .atl-menu').attr('js_clickcount')
article = next(doc('.bbs-content').items()).text()
dic1["title"] = str(title)
dic1["main_id"] = main_id
dic1["time"] = replytime
dic1["replycount"] = replycount
dic1["clickcount"] = clickcount
dic1["article"] = article
comments_replys = []
comments = doc('.atl-main div:gt(1)').items() # 通栏广告后的评论列表
for comment in comments: # 处理评论
dic3 = {}
dic4 = {}
dic5 = {}
host_id = comment.attr('_hostid')
# user_name = comment.attr('_host')
comment_text = comment('.bbs-content').text()
replys = comment('.item-reply-view li').items() # 评论回复
if replys != None:
for reply in replys:
rid = reply.attr('_rid')
rtext = reply('.ir-content').text()
if rid:
if rid != main_id and rid != host_id:
dic5[host_id] = rtext
if host_id:
k = comment_text.rfind("----------------------------")
if (k != -1):
comment_text = comment_text[k + 29:]
dic4[host_id] = comment_text
dic3['comment'] = dic4
dic3['reply'] = dic5
comments_replys.append(dic3)
dic1["comments_replys"] = comments_replys
dic.append(dic1)
except:
continue
string = json.dumps(dic, ensure_ascii=False, indent=4)
print(string)
f = open('data.json','w',encoding='utf-8')
json.dump(dic,f,ensure_ascii=False, indent=4)
def run(key, page):
"""
:param key:
:param page:
:return:
"""
start_urls = []
for p in range(1, page+1):
url = 'http://search.tianya.cn/bbs?q={}&pn={}'.format(quote(key), p)
start_urls.append(url)
content_urls = prase_all_page(start_urls)
# print(content_urls)
prase_all_content(content_urls)
if __name__ == '__main__':
run(key_word, page)
版权声明:本文为weixin_43906500原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。