6
1.理论篇
光学字符识别(Optical Character Recognition,OCR)一般包括文本检测(主要用于定位文本的位置)和文本识别(主要用于识别文本的具体内容)两个步骤。而图像质量的好坏对于检测率与识别率的高低影响很大,不容忽视。下面将重点介绍图像预处理中的二值化、去噪和倾斜角检测校正的常用算法。
1.1 二值化方法
图像二值化,Image Binarization,即通过将像素点的灰度值设为0或255使得图像呈现明显的黑白效果。在传统方法甚至是现在的流行方法中,高质量的二值化图像仍然可以显著提升OCR效果,一方面减少了数据维度,另一方面排除噪声凸显有效区域。目前,二值化方法主要分为四种:
• 全局阈值方法
• 局部阈值方法
• 基于深度学习的方法
• 基于形态学和阈值的文档图像二值化方法
1.1.1 全局阈值方法
(1)固定阈值方法
该方法是对于输入图像中的所有像素点统一使用同一个固定阈值,类似于NLP中相似度计算的阈值选择方法。其基本思想就是个分段函数:
公式中的T就是选择的固定全局阈值。
在NLP领域的相似度计算中,不同领域的文本阈值不同,而在图像领域也是一样,固定阈值方法存在一个致命缺陷:很难为不同的输入图像确定最佳阈值。因此提出了接下来的计算方法。
(2)Ostu方法
Ostu方法又被称为最大类间方差法,是一种自适应的阈值确定方法。
对于图像I(x,y),前景(即目标)和背景的分割阈值记作T,属于前景的像素点数占整幅图像的比例记为ω0,其平均灰度μ0;背景像素点数占整幅图像的比例为ω1,其平均灰度为μ1。图像的总平均灰度记为U,类间方差记为G。 假设图像的背景较暗,并且图像的大小为M×N,图像中像素的灰度值小于阈值T的像素个数记作N0,像素灰度大于阈值T的像素个数记作N1,则有:
将式(5)代入式(6),得到等价公式:
采用遍历的方法得到使类间方差G最大的阈值T。
注:opencv可以直接调用这种算法,threshold(gray, dst, 0, 255, CV_THRESH_OTSU);
• 优点:算法简单,当目标与背景的面积相差不大时,能够有效地对图像进行分割。
• 缺点:当图像中的目标与背景的面积相差很大时,表现为直方图没有明显的双峰,或者两个峰的大小相差很大,分割效果不佳,或者目标与背景的灰度有较大的重叠时也不能准确的将目标与背景分开。
• 原因:该方法忽略了图像的空间信息,同时将图像的灰度分布作为分割图像的依据,对噪声也相当敏感。
1.1.2 局部阈值方法
(1)自适应阈值算法
自适应阈值算法用到了积分图,是一个快速且有效地对网格的矩形子区域计算和的算法。积分图中任意一点(x,y)的值是从图左上角到该点形成的矩形区域内所有值之和。
(2)Niblack算法
Niblack算法同样是根据窗口内的像素值来计算局部阈值的,不同之处在于它不仅考虑到区域内像素点的均值和方差,还考虑到用一个事先设定的修正系数k来决定影响程度。
(3)Sauvola算法
Sauvola是针对文档二值化进行处理,在Niblack算法基础上进一步改进。在处理光线不均匀或染色图像时,比Niblack算法拥有更好的表现。
1.1.3 基于深度学习的方法
2017年提出了一种使用全卷积的二值化方法(Multi-Scale Fully Convolutional Neural Network),利用多尺度全卷积神经网络对文档图像进行二值化,可以从训练数据中学习并挖掘出像素点在空间上的联系,而不是依赖于在局部形状上人工设置的偏置。
1.1.4 基于形态学和阈值的文档图像二值化方法
该方法大体分为四步操作:
• 1)将RGB图像转化为灰度图;
• 2)图像滤波处理;
• 3)数学形态学运算;
• 4)阈值计算。
其中,数学形态学运算包括腐蚀、膨胀、开运算和闭运算。
1.2 图像去噪
在图像的采集、量化或传输过程中会导致图像噪声的出现,这对图像的后处理、分析会产生极大的影响。目前去噪方法分为4种:
• 空间滤波
• 小波阈值去噪
• 非局部方法
• 基于神经网络的方法
(1)空间滤波
空间滤波由一个邻域和对该邻域内像素执行的预定义操作组成,滤波器中心遍历输入图像的每个像素点之后就得到了处理后的图像。其中线性空间滤波器指的是在图像像素上执行的是线性操作,非线性空间滤波器的执行操作则与之相反。
线性空间滤波器包括平滑线性滤波、高斯滤波器。
非线性空间滤波器包括中值滤波、双边滤波。
维纳滤波和逆滤波解决运动模糊
维纳滤波原理:
链接: link
(1)有限长滤波器
对于一列输入信号x,一般的无限长线性滤波器输出为:
y(n)= Σh(m)x(n-m) m=0…∞
实际中,滤波器的长度,即阶数是有限长的,设为M,则有:
y(n)= Σh(m)x(n-m) m=0…M
即滤波器的当前时刻输出为前M个时刻的值经过加权之后得到的。
为便于书写与理解,上式可以写为矩阵形式:
y(n)=H(m)*X(n)
如果期望信号d已知,则可以计算输出与期望信号之间的误差:
e(n)=d(n)-y(n)= d(n)- H(m)*X(n) m=0…M
Wiener滤波的目标就是,如何确定一个长为M的系数序列H,使得上述误差值最小。
(2)最小均方误差滤波
根据目标函数的不同,又可以将滤波算法细分为不同的类别,一般来说有最小均方误差,最小二乘误差等等,这里只讨论最小均方误差。
令目标函数为:
Min E[e(n)^2]= E[(d(n)- H(m)*X(n))^2]
当滤波器的系数最优时,目标函数对系数的偏导应该为0,即:
dE[e(n)^2]/dH=0
2 E[ (d(n)- H(m)X(n))] X(n)=0
E[(d(n) X(n))- H(m)E[X(n)X(n)]=0
根据随机过程的知识,上式可以表达为:
Rxd-H*Rxx=0
其中Rxd与Rxx分别为输入信号与期望信号的相关矩阵与输入信号的自相关矩阵。
从而有:
H=Rxx-1*Rxd
至此,便得到了Wiener滤波的基本原理与公式推导。
(2)小波阈值去噪
基本思路包括3个步骤:1)二维图像的小波分解;2)对高频系数进行阈值量化;3)二维小波重构。
(3)非局部方法
该类型方法包括NL-means和BM3D。其中BM3D是当前效果最好的算法之一,具体可参考this repo。
(4)基于神经网络的方法
目前已经逐渐流行使用这种方法进行降噪处理,从简单的MLP发展到LLNet。
(5)防抖 base gyro method
1.3 倾斜角检测校正
在扫描过程中,很容易出现文档旋转和位移的情况,因此后续的OCR处理与倾斜角检测校正步骤密不可分。常见的方法有:霍夫变换、Randon变换以及基于PCA的方法。
针对霍夫变换的使用一般分为3个步骤:
1)用霍夫变换探测出图像中的所有直线;
2)计算出每条直线的倾斜角,求它们的平均值;
3)根据倾斜角旋转矫正图片。
1.3.1霍夫变换原理
Hough直线检测的基本原理在于利用点与线的对偶性,在我们的直线检测任务中,即图像空间中的直线与参数空间中的点是一一对应的,参数空间中的直线与图像空间中的点也是一一对应的。这意味着我们可以得出两个非常有用的结论:
1)图像空间中的每条直线在参数空间中都对应着单独一个点来表示;
2)图像空间中的直线上任何一部分线段在参数空间对应的是同一个点。
因此Hough直线检测算法就是把在图像空间中的直线检测问题转换到参数空间
以上就是在直线检测任务中关于对偶性的直观解释。这个性质也为我们解决直线检测任务提供了方法,也就是把图像空间中的直线对应到参数空间中的点,最后通过统计特性来解决问题。假如图像空间中有两条直线,那么最终在参数空间中就会对应到两个峰值点,依此类推。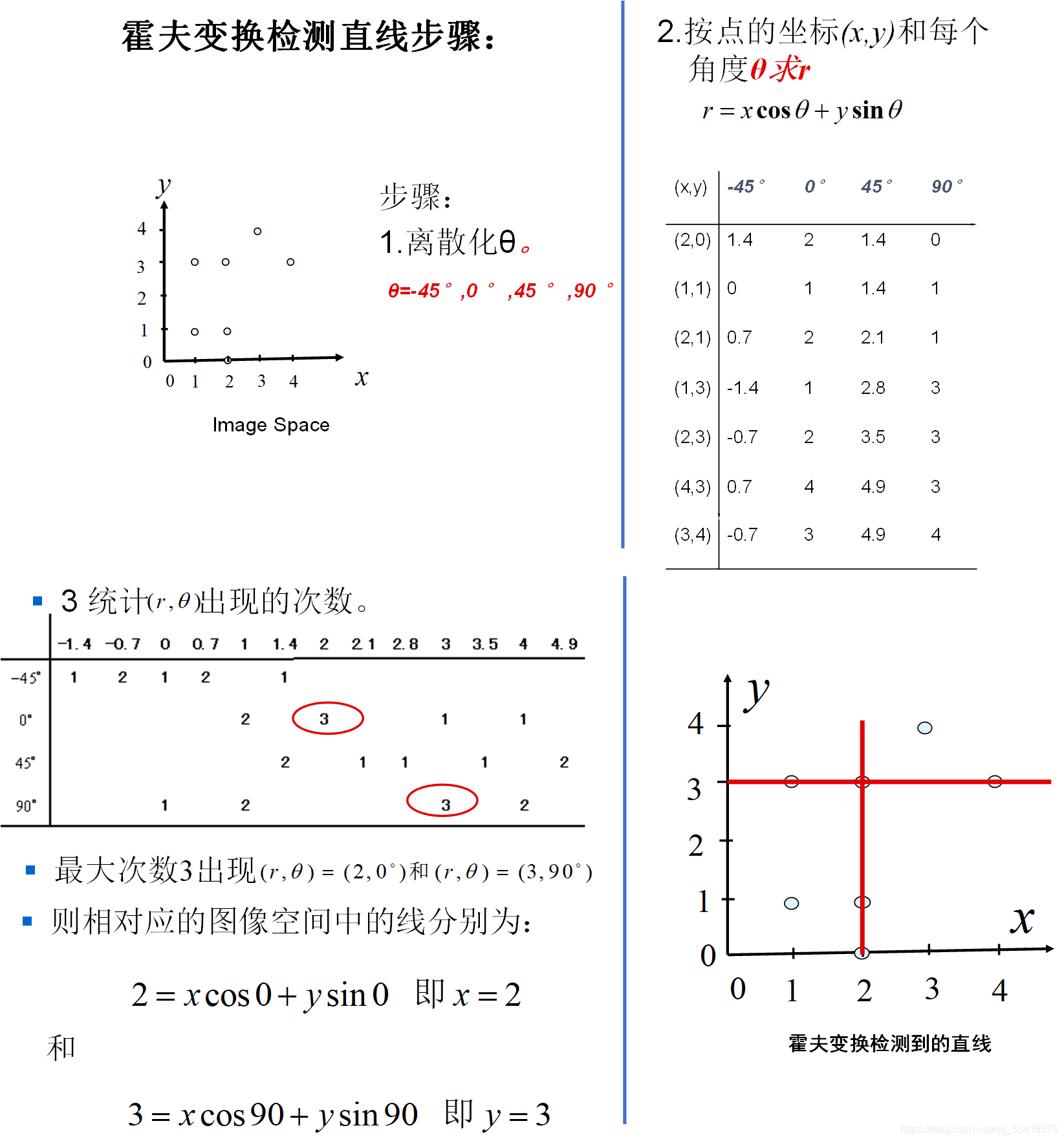
总结:使用霍夫变换检测直线具体步骤:
1.彩色图像->灰度图
2.去噪(高斯核)
高斯核:
距离越近的点权重越大,距离越远的点权重越小,权重大小和到中心距离的关系符合高斯分布,σ =1.5的高斯核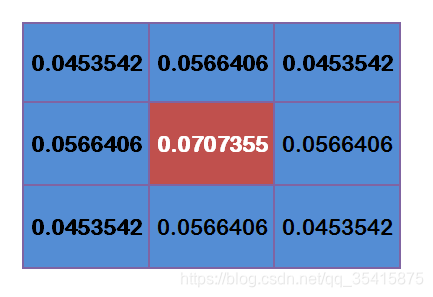
3.边缘提取(梯度算子、拉普拉斯算子、canny、sobel)
canny最好:
step1: 用高斯滤波器平滑图象;
step2: 用一阶偏导的有限差分来计算梯度的幅值和方向;
step3: 对梯度幅值进行非极大值抑制
step4: 用双阈值算法检测和连接边缘
链接: link.
4.二值化(判断此处是否为边缘点,就看灰度值==255)
5.映射到霍夫空间(准备两个容器,一个用来展示hough-space概况,一个数组hough-space用来储存voting的值,因为投票过程往往有某个极大值超过阈值,多达几千,不能直接用灰度图来记录投票信息)
6.取局部极大值,设定阈值,过滤干扰直线
7.绘制直线、标定角点