数据库性能问题一般从以下三个方面分析:
1、操作系统:看CPU、内存、IO
一般用于数据库的服务器建议是不要装其他应用,在选机器时,同价位的 ,在cpu和内存中做选择的话,可优先选内存大
2、数据库配置参数+架构
配置参数主要是一些内存池的分配大小和方案(数据缓冲池、字典缓冲池、sql缓冲池、排序缓冲等)
架构可根据业务情况,高并发的 单机无法满足应用需求的可考虑读写分离架构或共享存储架构
高IO的数据分析应用可以考虑并行计算的MPP架构
3、SQL优化
这种优化是成本最低,也是经常需要用到的优化手段,很多时候通过SQL优化就可解决用户的数据性能问题
SQL优化从哪几个方面来优化呢?
先得了解执行计划:sql语句进行语法、语义分析后,生成一系列的操作符后在数据库执行
执行计划中的操作符主要有:
单表操作符:CSCN(全部扫描)、SSCN(索引扫描)、SSEK(索引查找)、CSEK(聚集索引查找)、BLKUP(二次回表查找)
总结:SSEK+CSEK 要优于 SSCN+CSCN,如果数据页比较宽 要避免出现BLKUP(可通过设计复合索引或覆盖索引避免二次回表查找)
连接类型操作符:HASH JOIN、NEST LOOP JOIN、MERGE JOIN、
总结:一般上面代价依次变大,但如果连接表左表较小筛选记录少的情况NEST LOOP JOIN 要优于HASH_JOIN
更多操作符可查看:DM8系统管理员手册.pdf 附注4
业务SQL等价重写改变执行计划,让计划更优
构建合适索引+统计信息更新
以下通过一个案例分析来看一个sql通过语句重写、构建索引、更新统信息优化后的最优执行计划
案例分析:
准备测试数据
DROP TABLE TEST1;
CREATE TABLE TEST1(ID INT,ID1 INT,ID2 INT,ID3 INT);
insert into test1 select dbms_random.value(1,15000),dbms_random.value(1,15000),dbms_random.value(1,15000),dbms_random.value(1,15000) from dual connect by level <= 15000;
commit;
测试SQL语句:
select * from test1 a
where
a.id = 5
or
(a.id = 7 and a.id1 = 11 and a.id2 < 15)
or
a.id1 in (select id1 from test1 b where b.id2 = 8 and b.id3 = 12)
在没有任何索引情况下执行计划(包含4个全部扫描+1个hash join):
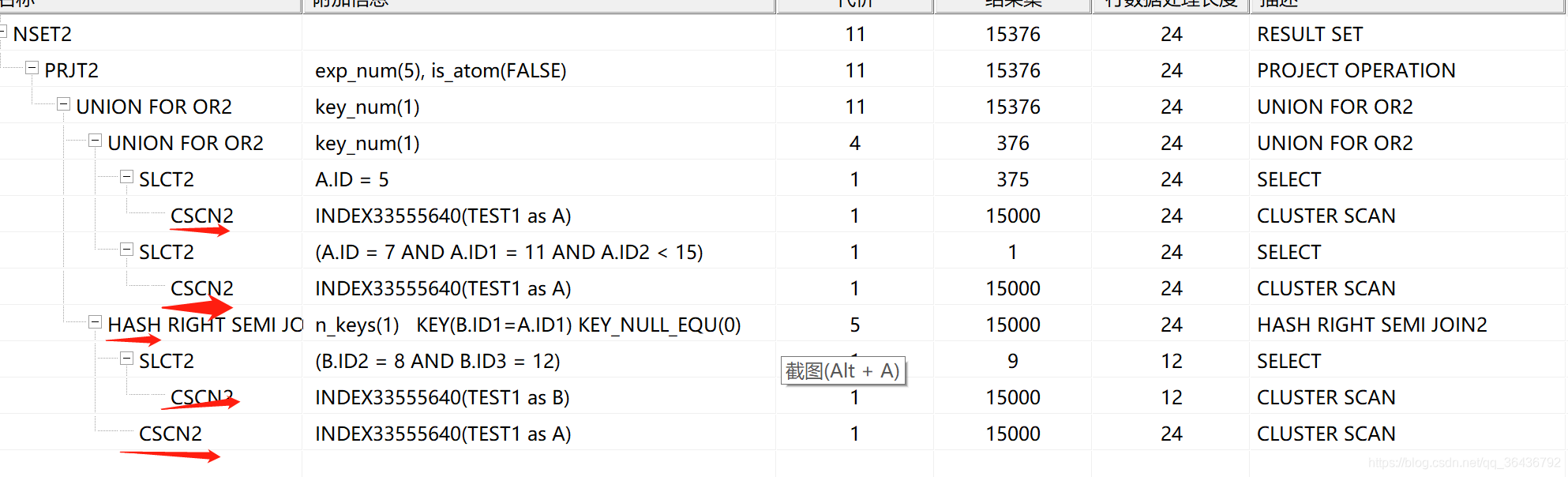
HASHJOIN 从哪来?
根据执行计划可知 从最后一个or a.id1 in (select id1 from test1 b where b.id2 = 8 and b.id3 = 12)而来,
再分析该sql 自己和自己判断的 是否可以进行sql等价改写?(假设id1字段是唯一索引)
拆成简单的sql看:
select*fromtest1 a
wherea.id1in (selectid1fromtest1 bwhereb.id2 = 8andb.id3 = 12)
实际是等价于:
select*fromtest1 a
where a.id2 = 8anda.id3 = 12
如此以上sql就可以改写成:
select*fromtest1 a
where
a.id = 5
or
(a.id = 7anda.id1 = 11anda.id2 < 15)
or
(a.id2 = 8anda.id3 = 12)
通过sql改写后看执行计划(已消除hash join,但仍存在全部扫描):

怎么把全部扫描变成索引扫描?(根据查询条件或者连接条件来初步确定索引方向):
索引1:Id
索引2:Id、id1、id2
索引3:ID2、id3
再考虑哪些索引可合并?
索引2覆盖了索引1 ,故索引1可去掉
最终确定索引2、3
CREATE INDEXIDX_IDEX1ONTEST1(ID,ID1,ID2);
CREATE INDEXIDX_IDEX2ONTEST1(ID2,ID3);
建完索引后查看执行计划(全表扫描变成了索引查找+二次回表查找):
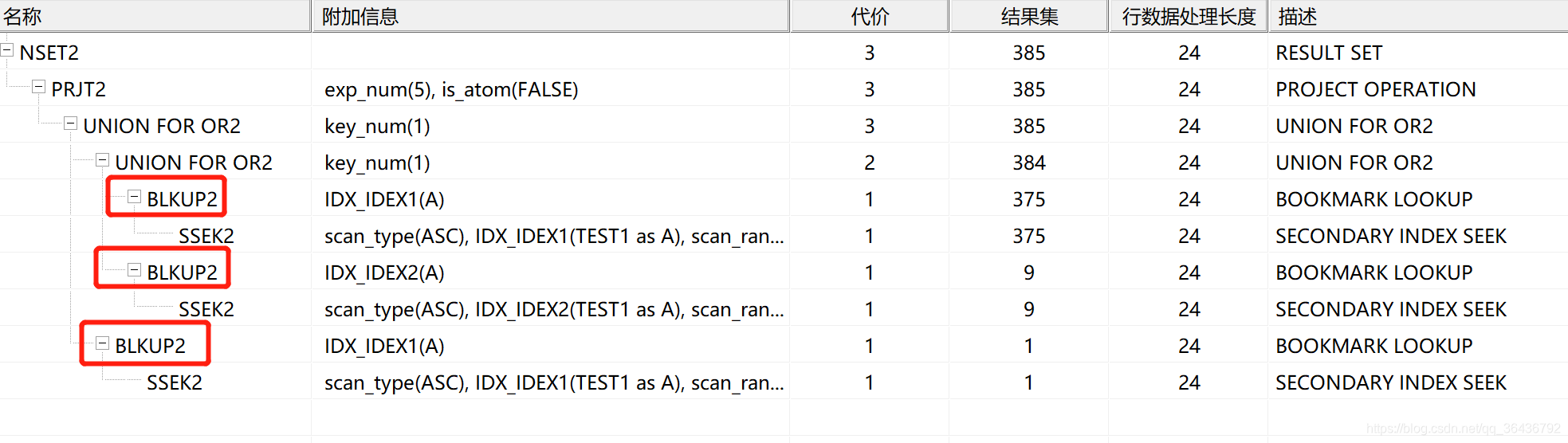
是什么引起的二次回表查找呢?
原因:要显示的列不在索引中,为了减少二次回表查找的方法就是 在索引中包括需要显示的列,因为该sql查询的结果是* 包含了行的所有列,所以二次查找无法避免。
如果该表中还存在其他大字段,最终需要显示的列都已包含在索引列中,将可消除二次回表查询
即:
假设sql中* 替换成如下:
selectid,id1,id2,id3
fromtest1 a
where
a.id = 5
or
(a.id = 7anda.id1 = 11anda.id2 < 15)
or
- id2 = 8anda.id3 = 12)
索引可调整设计如下:
索引1:Id、id1、id2,id3
索引2:ID2、id3,id1,id
CREATE INDEXIDX_IDEX1ONTEST1(ID,ID1,ID2,ID3);
CREATE INDEXIDX_IDEX2ONTEST1(ID2,ID3,ID,ID1);
执行计划变成如下(只存在索引查找):
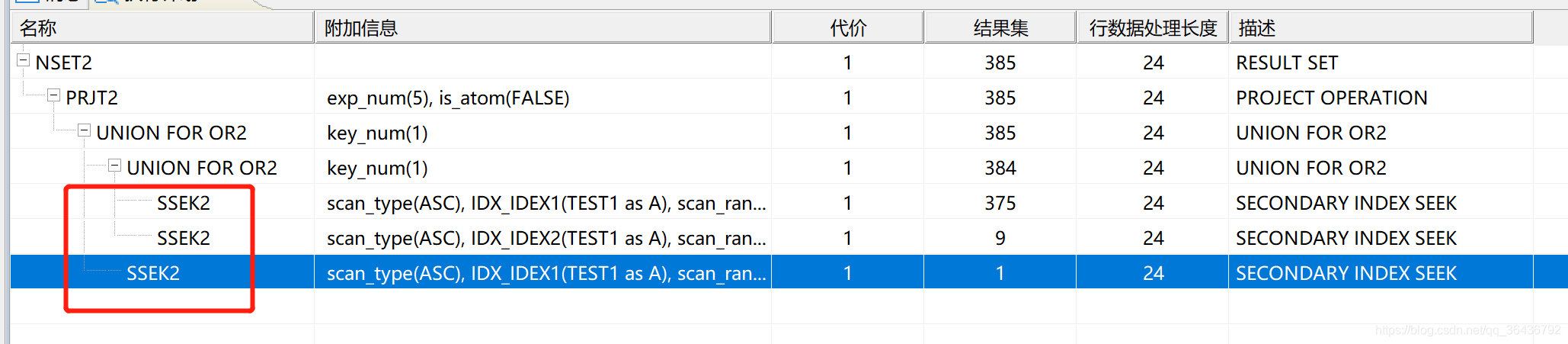
统计信息更新对优化的影响:
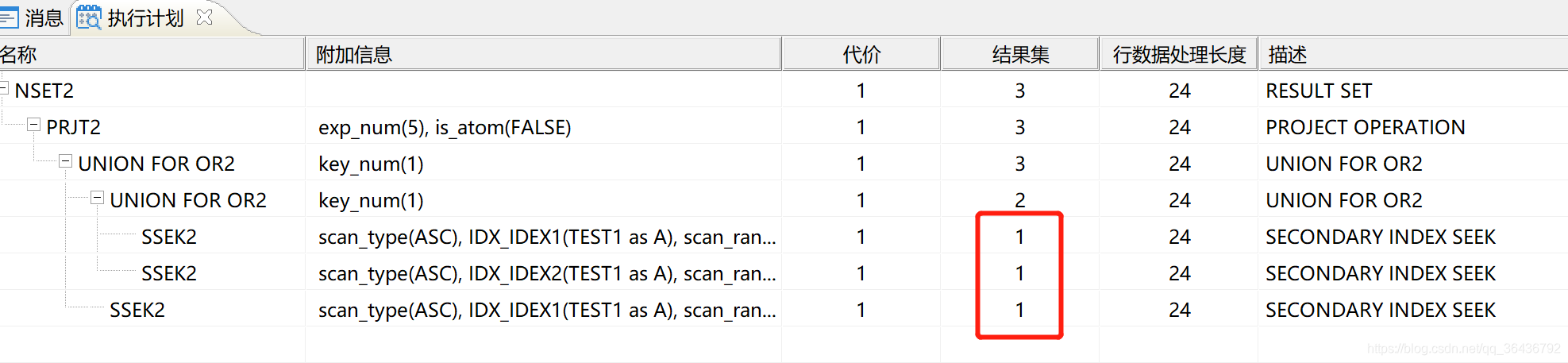
从上图可看成结果集数量分布是1、9、375 这些都是估算的
如果统计信息更新了 这些结果集数据将变更准确
执行统计信息收集后的执行计划可看出:
CALL SP_SQL_STAT_INIT('SELECT * FROM TEST1'); --该存储过程表示收集SQL语句涉及列的统计信息
达梦技术社区:https://eco.dameng.com