前言
本文基于ElasticSearch6.4版本。
fuzziness
fuzziness参数可以使查询的字段具有模糊查询的特性。

通过模糊查询可以搜索出存在一定相似度的单词。对于两个单词是否有相似度以及相似度的大小,需要用到Levenshtein Edit Distance。
Levenshtein Edit Distance,即莱文斯坦编辑距离。指两个字符串之间,由一个转成另一个所需的最少编辑次数。编辑操作包括添加、更新、删除。

e.g.
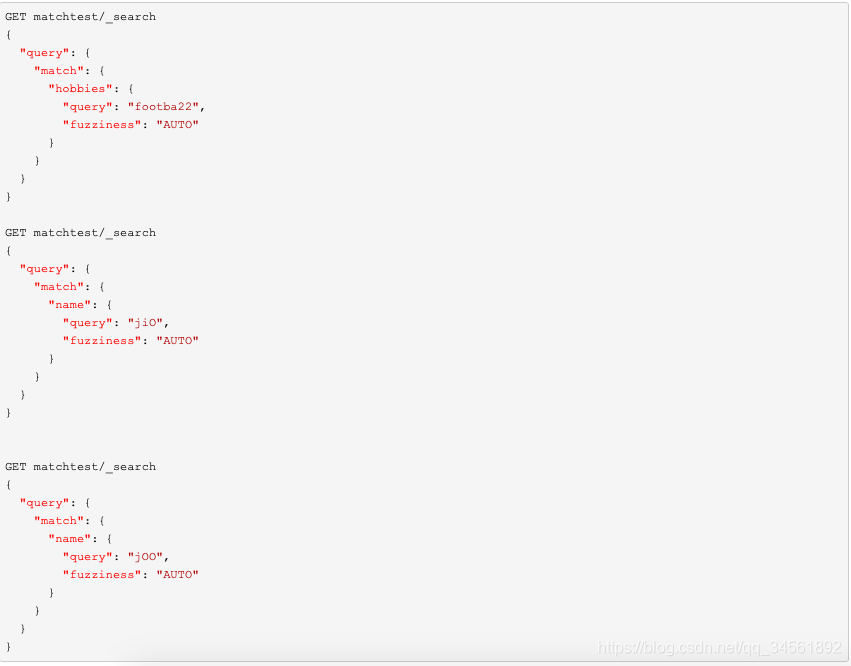
此外,默认支持(ab -> ba)这种模糊换位(fuzzy transposition)。可以通过设置fuzzy_transpositions为false,禁用这种行为。
prefix_length
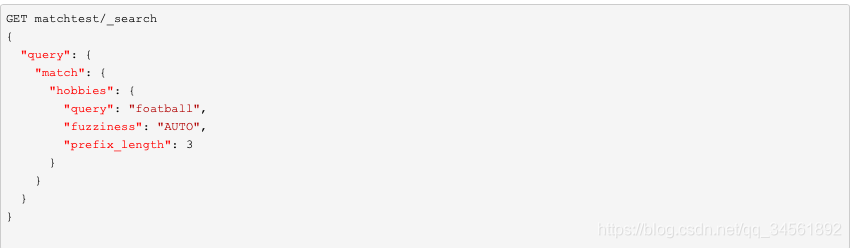
prefix_length参数:表示不能被模糊化的初始字符数。必须与fuzziness参数结合使用。
e.g.
minimum_should_match
需要至少匹配指定数量个词项。
- 整数值:比如3。表示至少需要匹配3个词项。
- 负整数值:比如-2。表示至少需要匹配 (词项的总数量 - 2)个词项。
- 比例值:比如75%。表示至少需要匹配 (词项的总数量 * 0.75 再向下取整)个词项。
- 负比例值:比如-25%。表示至少需要匹配(词项的总数量 - (词项的总数量 * 0.75 再向下取整))个词项。
- 组合值:比如3<90%。表示如果词项数量为1-3之间,需要全部匹配;如果词项数量>3,需要匹配90%个词项。
- 多个组合值:比如2<-25% 9<-3。表示如果词项数量为1-2,需要完全匹配;如果词项数量为3-9,需要匹配-25%个词项;如果词项数量>9需要匹配-3个词项。
max_expansions
控制最后一个词项会拓展多少个后缀。默认是50。

PUT book/text/1
{
"message" : "quick brown fo"
}
PUT book/text/2
{
"message" : "quick brown foo"
}
PUT book/text/3
{
"message" : "quick brown fooo"
}
需要添加routing。
GET /_search?routing=1
{
"query": {
"match_phrase_prefix" : {
"message" : {
"query" : "quick brown f",
"max_expansions" : 1
}
}
}
}
版权声明:本文为qq_34561892原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。