GlobalPointer模型的基础细节和实现方式可以参考苏神的文章:
GlobalPointer:用统一的方式处理嵌套和非嵌套NER - 科学空间|Scientific Spaces
如果把下面的几个小不足能够用一种通用的方法解释清楚并解决,可能就够水文章了吧,哈哈哈哈哈哈哈哈哈。。。
1.例如在下述场景中,生活中的先验知识告诉我们楼号后面跟的不论是数字还是文字一般都是单元号,或者楼的其他实体信息,实体和实体之间是有一定规律的,比如一般就是小区名称+几号楼+几单元,这样的形式,但是在GlobalPointer模型中,我们只能理解到所谓标记的"2号楼"这个片段的实体信息,其余周边实体信息是关注不到的!并不是像CRF那样站在全局的角度对实体类型的一个约束,CRF的一个好处就是会限制实体或者实体标签全局的一个实体顺序的约束
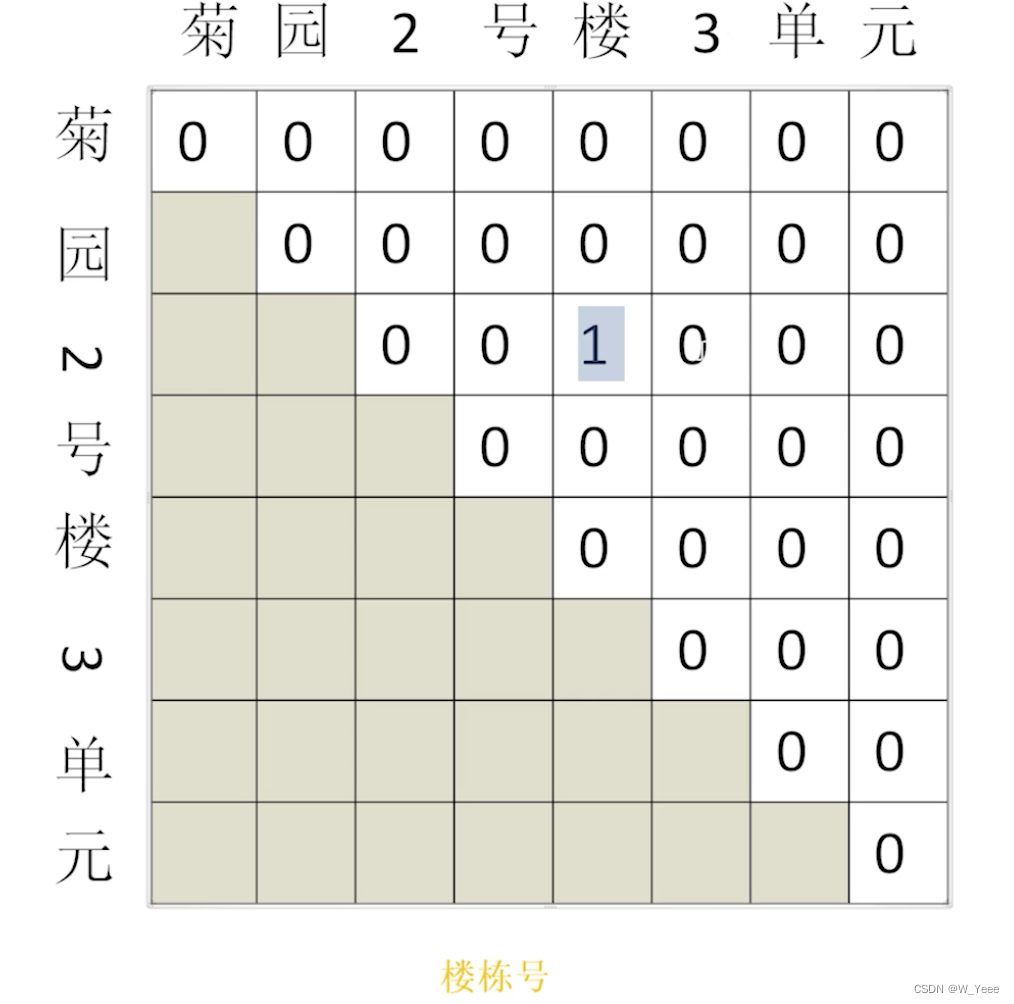
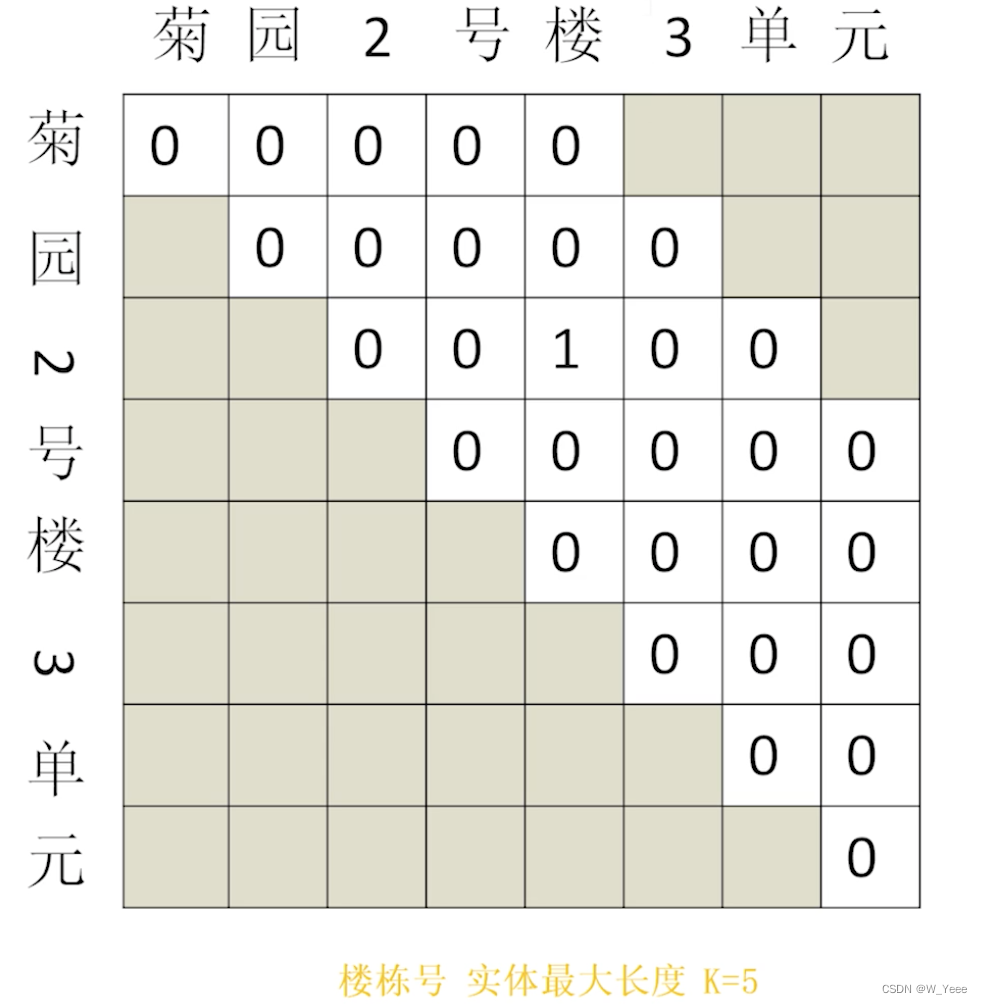
2.最大长度的约束:还是拿上面的图片举例子,识别出“2号楼”可以知道该实体的长度为3,但是如果是实体的长度达到100个字或者200个字的话,这样也会识别出为“小区楼号”实体类型吗?很显然是不能的,因为该模型没有对负样本的长度去做限制,所以导致在实体较少的数据中负样本非常的多,如下图所示,我们把实体的最大长度设置为5,可以看到右上角的“3单元”被mask掉了,以达到一个减少负样本,正负样本的比例就没有那么悬殊了,但是从通用实现的角度来讲,需要自己做一个定制化的开发,还是有一点难度的。
3.解码的时候会生成重叠的实体,在嵌套的实体中经常会出现重叠,比如说“北京师范大学”模型可能识别为实体,也可能是“师范大学”识别为一个实体,直接就把“北京”排除在外了,但是师范大学是包含在北京师范大学里面的,那么这两个哪个跟合理呢?模型是没有考虑到这样一个机制的。
版权声明:本文为weixin_48592695原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。