首先,我们有一份带表头的数据
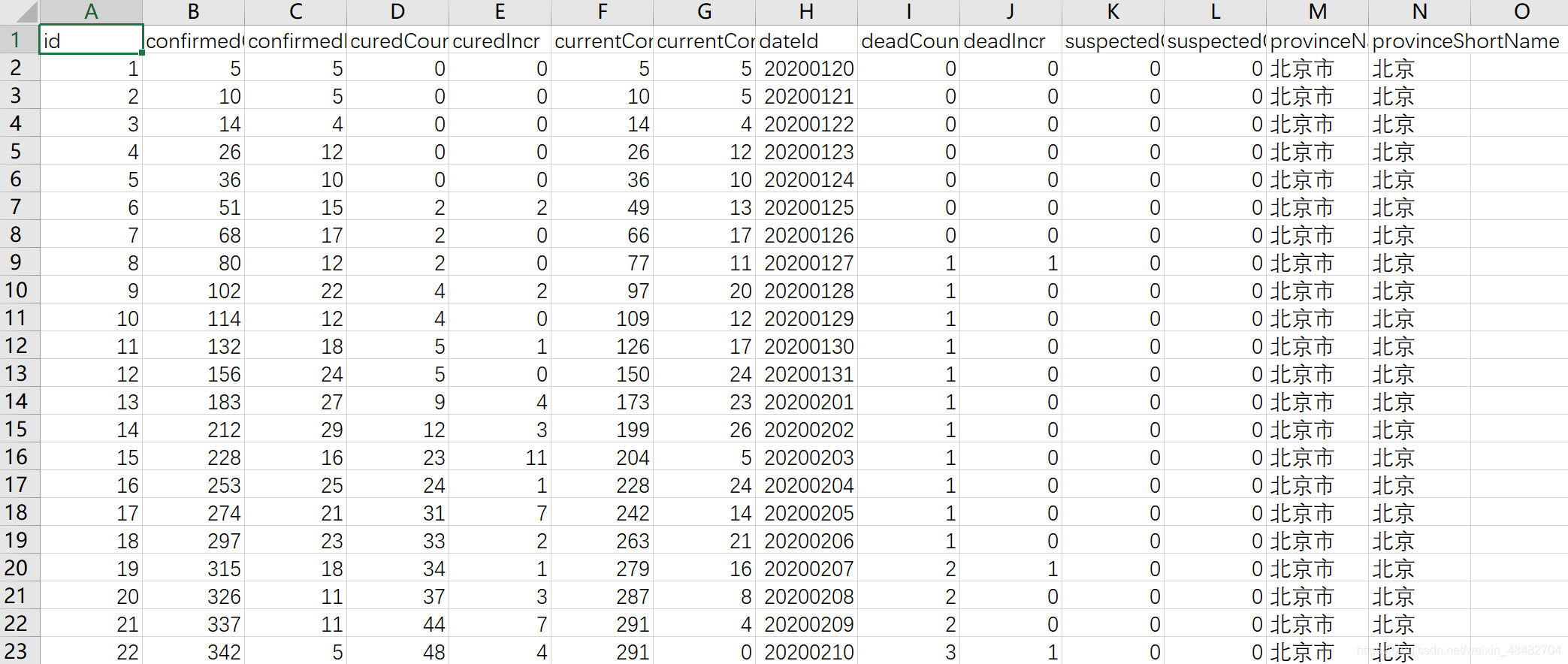
数据已经保存在HDFS上,先创建SparkSession和SparkContext
val spark: SparkSession = SparkSession.builder()
.appName("header")
.master("local[*]")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
一、返回DataFrame
如果是要DataFrame,则使用如下方法
val frame: DataFrame = spark.read
.option("header", "true") //是否将第一行作为表头header
.option("delimiter", ",") //字段分隔符
.csv("hdfs://single:9000/app/data/exam/china_provincedata.csv")
frame.show()
运行结果
二、返回RDD
先加载RDD
val rdd: RDD[String] = sc.textFile("hdfs://single:9000/app/data/exam/china_provincedata.csv")
① mapPartitionsWithIndex算子
rdd.mapPartitionsWithIndex((ix,it)=>{
if(ix==0) it.drop(1)
it
}).collect().take(5).foreach(println)
运行结果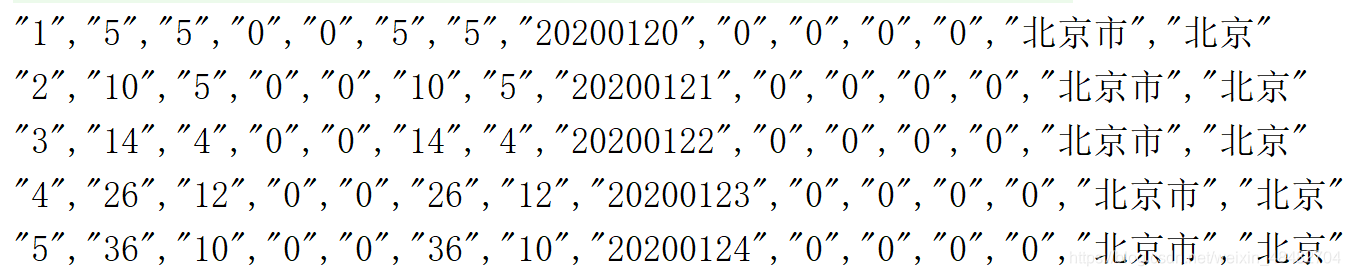
② 正则+偏函数
val r: Regex = "(\"?\\d.*?)".r
rdd.collect({
case r(a)=>a
}).collect().take(5).foreach(println)
运行结果
③ 使用过滤器filter
rdd.filter(x=> ! (x.startsWith("id") || x.startsWith("\"id"))).collect().take(5).foreach(println)
运行结果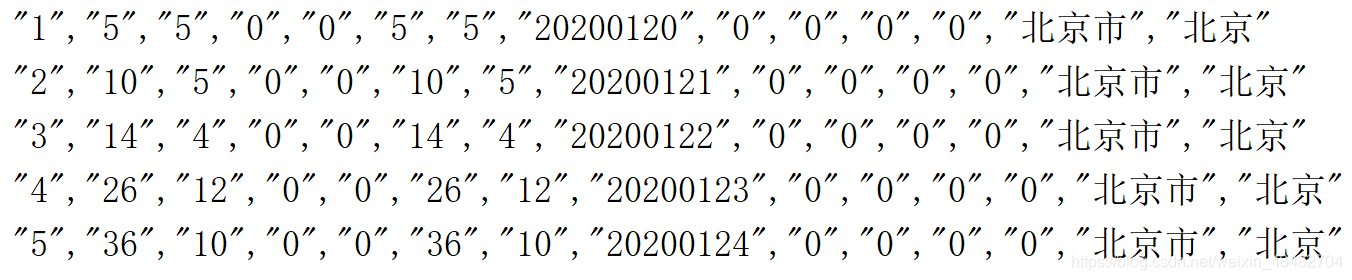
版权声明:本文为weixin_48482704原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。