InnoDB存储原理
页(Page)
页(page): Innodb 分配内存、内存加载都是以页为单位。
- 页大小固定: 16kB
- 页内变长数据: 最大768B,超过使用
溢出页。因此根据每条数据的大小(varchar),数据大(不会超过768B)则每页数据少些,数据小则每页多些
页的组成
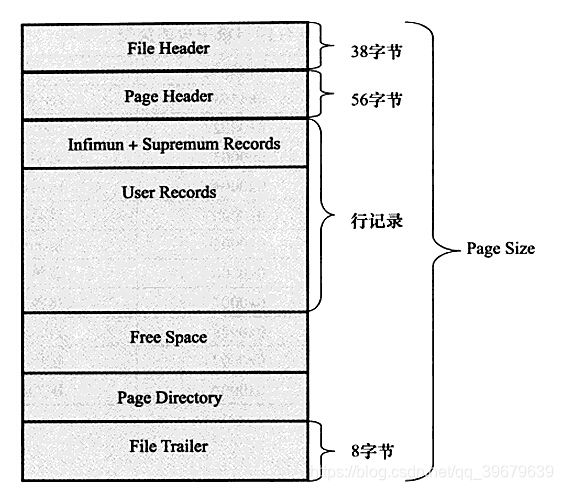
页结构说明一图片引用自
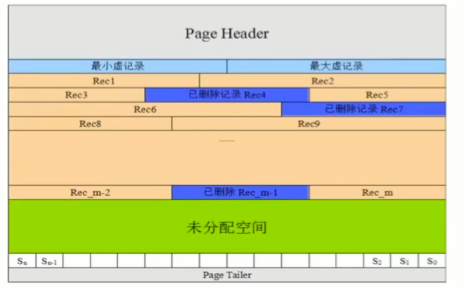
页结构说明二
File Header: 记录页的头信息- 重要字段:
FILE_PAGE_PREV: 前一页 (这俩用于寻找前后页,构成页页之间双链表)FILE_PAGE_NEXT: 后一页
- 页与页之间通过双向链表连接
- 重要字段:
Page Header: 记录当前页的使用情况等PAGE FREE自由空间链表, 已删除记录组成的链表
Infimum & Supremum: 最大最小虚记录- 最小虚记录:比页内最小
主键还小 - 最大虚记录:比页内最大
主键还大 - 记录当前页中行记录边界
- 最小虚记录:比页内最小
User Record: 记录堆, 真实行数据- 每行多个字段记录改行数据值(后面仔细说明)
Free Space: 未分配空间,页面内的可用空间Page Directory: 数据目录。维护某些数据项的相对位置,类似于跳表的操作Page Tailer:记录页内数据的校验信息
行的组成
Innodb的行记录存储在User Record区域,行与行之间通过Next指针关联,组成单链表形式的串联
行记录中除了每列数据项,还有几个数据管理字段,主要包括:
Record Header: 至少5个字节的行记录说明Next Record Offset: 2个字节,记录下一个记录的偏移(相当于单链表指针)- 另外有两项影响
Record Header的主要因素:- 变长列的长度
- NULL列的个数
- 对于主键索引的叶子节点,每个行有额外的隐藏字段
RowID: 行id(咩有主键索引时才有)Transaction ID: 每个数据行都有的事务idRoll Pointer: 回滚指针,用于在MVCC中找到前个版本的数据项
页内记录维护
- 顺序保证
- 使用逻辑连续的策略,数据与数据之间使用单向链表连接
- 插入过程中会保证插入数据大小顺序,因此会先查找,再插入
- 单向链表的查询效率很低(需要遍历),因此页内查询还需要使用跳表进行优化
- 使用逻辑连续的策略,数据与数据之间使用单向链表连接
- 插入策略
- 先找自由空间链表(已删除记录链表),优先填补已删除空挡
- 未使用空间:没有可填补的空挡,则开辟未分配的空间
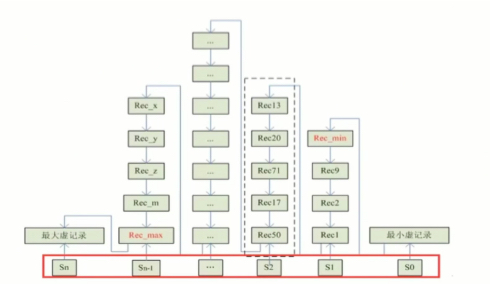
- 页内查找(单向有序链表查找,使用Slot区,跳表)
- 使用Slot区,S0、S1、S2…Sn指向单向链表中间的某些节点
版权声明:本文为qq_39679639原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。