一、交换排序
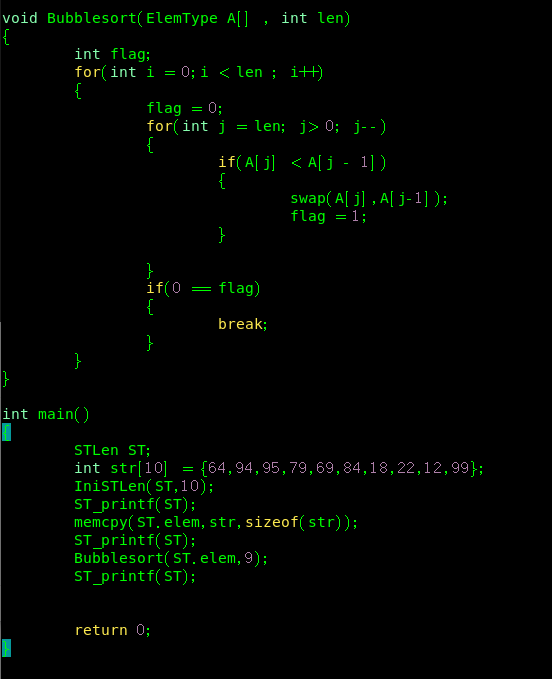
1.冒泡排序
对于冒泡排序的理解有问题,它不是只针对最后一个元素进行依次交换,而是针对所有元素,相当于第一遍从最后一个元素遍历到第一个元素,第二遍从倒数第二个元素遍历到第一个元素,依次如此
上机测试
一遍过,没有问题
2.快速排序
(挖坑法与交换法对比)
下面两个代码分别是挖坑法和交换法:

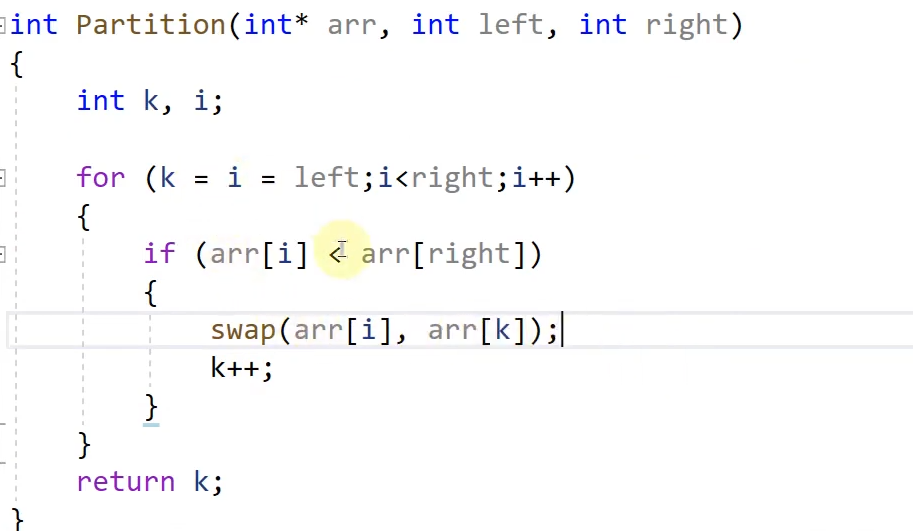
以最左边作为分隔值,而交换法则是以最右边作为分隔值
发现一个问题,这个的前题条件是low和hight,它是代表着数组的空间位置,并不是数组中的数据
所以low刚开始一定是小于hight的
两者最本质的区别就是,挖坑法需要设置一个单独的坑,也就是一个整形,来存放我们用来标定的值(如最左边的值),而交换法,无需这一步,只需要右边不动,左边不断进行交换(方法是设置一个k和一个i,不断加1,与右边的值比较)。当然也可以反过来。
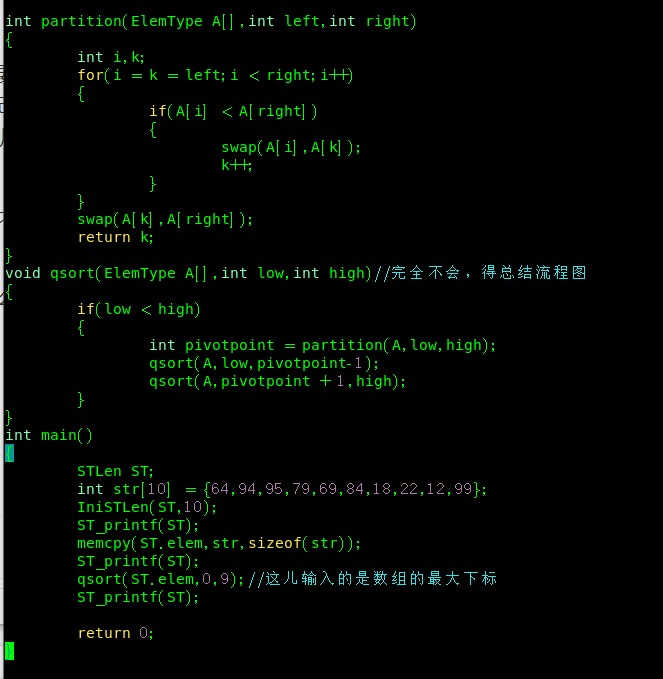
(1).交换法
两个单词的学习 partition (分隔) pivot point(枢纽点)
首先,这个代码的关键在于partition 也就是分隔,必须要找到分隔的这个位置,我们设为k
首先我们先确定他的low和high 也就是数组的最小下标和最大下标,low<high 时开始循环
然后我们就要找枢纽点,就是中间的那个位置,此时就是交换法与挖坑法的根本区别,交换法是直接确定数组最后一个位置为枢纽点的值,然后利用i(从数组第一位到最后一位遍历)利用循环让i与枢纽点不断比较,若是i小,那么就让i与k进行交换,因为我们最后要从小到大排序,(k一开始与i相同,只有当交换后才进行+1),
当i等于最右边的位置时(i = right),这时则不再循环,返回到qsort函数中,继续再一次调用**qsort*(因为我们不止排一次,我们要排好几次,直到数据从小到大有序);(递归)
上机测试
这个代码问题大了
首先这个代码要有三个函数值,我一开始感觉不需要第二个也可以,这儿的问题是没有理解递归,这儿递归调用自己本身,一开始认为调用的是partition,脑子有点不在线,注意递归一定是用if绝对不可以用while
然后partition函数只有小于最右边的值,这时我们才交换,也就是做到从小到大的顺序。
最后,其实我感觉很简单,但不知道为什么会有这么多的误区,还是不熟悉
(2).挖坑法
首先对于之前的理解有问题,现在必须重新纠正一下,就是原理问题,这个方法很重要,我刚练习了考研的题,它的快速排序都是按照这个来的
我之前认为这个方法是先进行右边遍历,遍历出小的与左边交换,一直遍历完,然后遍历一边左边,最后得出结果
现在我发现这个和交换法是类似的,相当于一个i和一个k,i是左,k是右,先是右边遍历,当遍历到小于pivot的时候,这时我们就交换,然后开始左边遍历,当遍历到大于pivot的时候,这时我们与右边交换,然后开始右边遍历。就这样不断循环,直到left = hight 的时候这时候退出循环,这时我们需要把pivot的值放到中间,也就是这时left或者right的位置
上机测试
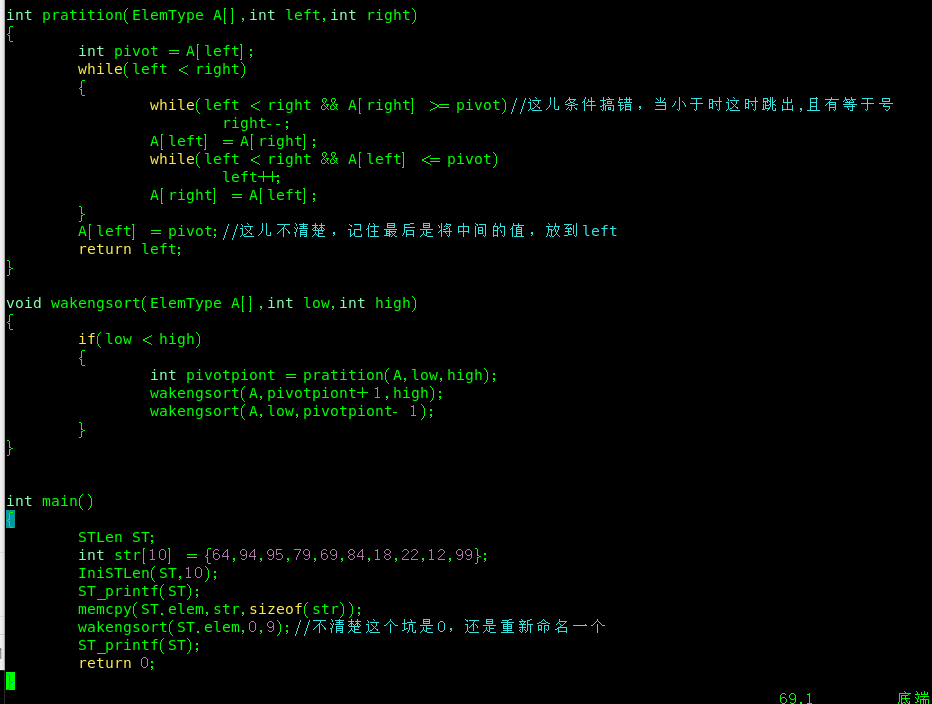
写这个代码的时候,出现了好多问题,其中很关键的一个地方是,什么时候跳出右边遍历,什么时候跳出左边遍历,当比pivot小的时候跳出右边遍历,也就是*>=* ,左边同样这样推理。
三、插入排序
1.直接插入排序
与顺序表的插入一样,但是利用了哨兵,找到小的数,然后放到哨兵中,然后依次与前面的数进行比较,若前面的数大则向后移动一位,直到放入这个哨兵中
上机测试
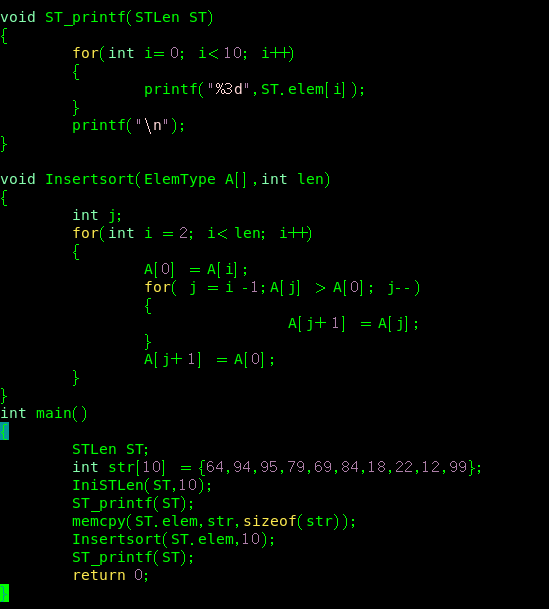
发现一个写代码的好方法,可以画图,根据画的图来写,准确率更高
2.折半插入排序
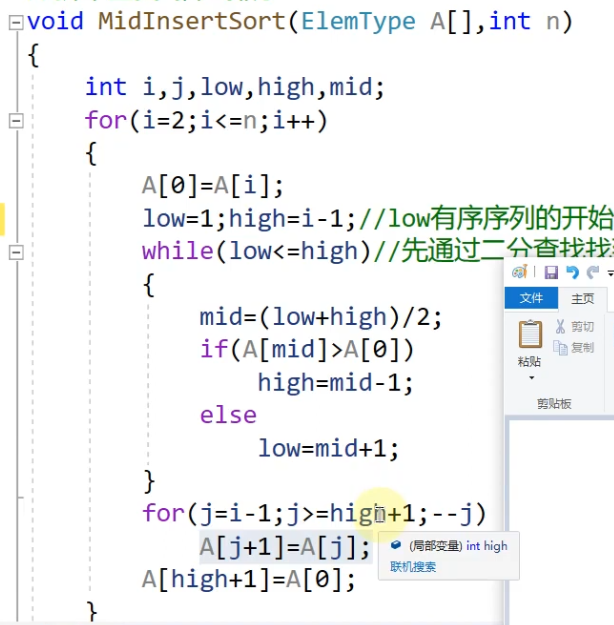
优势不是很大,实际中往往不用,这个代码可以和直接插入对比理解
只是减少了比较的次数
分析他的时间复杂度,相当于第一个数,进来向前移动一位,第二个数,向前移动两位,依次都是如此,所以总共是n(1+n)/2 所以就是n的平方
说实话不是太懂,所以看书再理解理解
有一个疑问,为什么最后一行代码是赋值给high+1,这儿有些不懂
弄不清楚了,越看越糊涂,一会看吧
现在弄清楚了,就是相当于先进行查找,然后在进行插入,查找的时候很麻烦,相当于从第二个元素开始,判断第二元素之前的元素,取中间值,看它是否比我们取的哨兵大,判断完了之后,这时我们利用high的位置,**让比哨兵的值大的都往后移(我们判断大小的依据是第一个元素(相对于第二元素来说的)比high+1大的进行后移),**最后把哨兵的值赋给high+1;然后接下来判断第三个元素。依次进行。
这个代码的好处是可以少比较一些数值,少比很多数,每个数只比一半。
上机测试
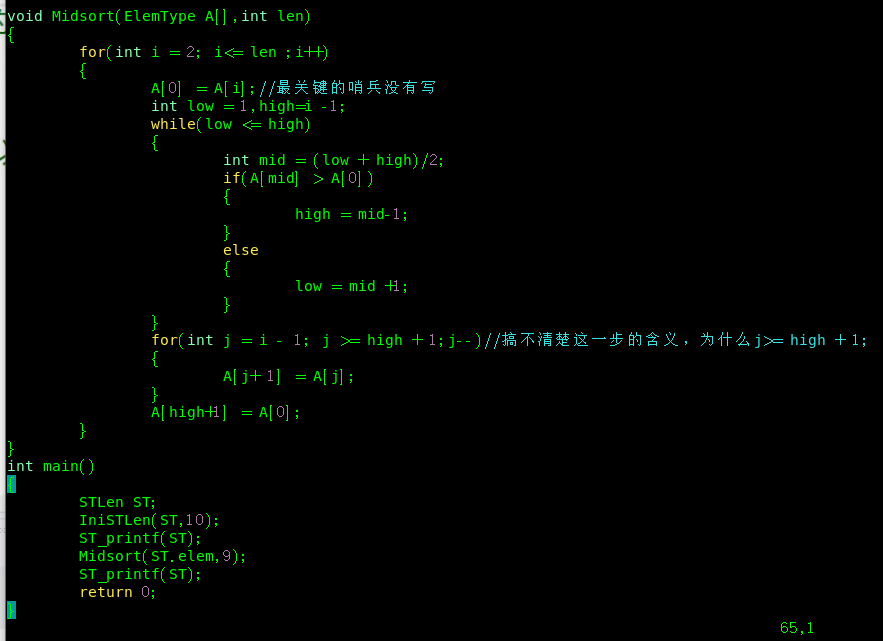
问题挺严重的,但是想明白了,不知道你之后还能想明白吗
3.希尔排序
它的时间复杂度是一个经验值,n的1.3,记住就可以,没有最好与最坏
一个小点:5/2=2 注意这儿是取整不是取余
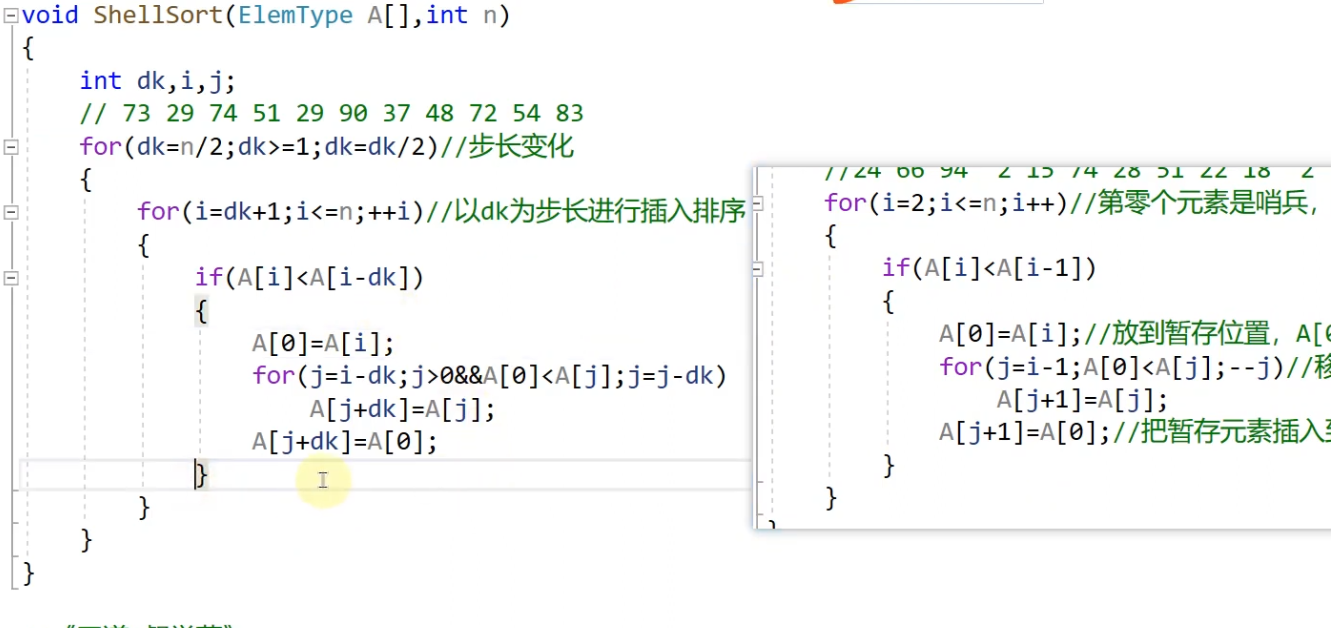
代码比插入排序多一层循环,且时间复杂度低
步长,也就是代码中的dk,要记住这个代码,考研会考
for(dk = n/2;dk>=1;dk = dk/2) 记住这个代码,剩下的代码就是直接插入排序中的插入代码
希尔排序的本质是:每一个元素都与元素加一个步长进行比较,小前大后
我感觉人工搞,还是挺麻烦的,需要弄好多次,才能得到结果
理解有误,步长为2,第一趟的时候不是两两交换,而是所有步长为2的元素,统一排成从小到大的顺序
我一开始认为的是第一个元素,与第一个元素加步长,第二个元素与第二个元素加步长,依次这样
而实际上是第一个元素可以与第一个元素加两个步长进行比较
希尔排序的代码就是将直接插入代码中的1改成dk,在一开始写清楚步长的变化
memcpy使用的是string.h文件

考研如果选择排序作为大题,很大程度上是堆排和快排,像希尔排序,插入排序在工业上没有应用
四、选择排序
1.简单选择排序
这个和冒泡是类似的
就是先选择一个数,如A[min] ,,可以从左往右依次找,也可以从右往左,假设它是最小的,然后我们依次遍历所有的数,只要比我们选择的数小,这时我们就把这个小的数赋值给我们一开始选择的这个地方
相当于每一轮只交换一次


注意:i只要取到8就可以,因为j=i+1;
我感觉这儿有一个地方你会弄混,就是一开始交换的是位置,也就是空间位置 min 与 j 只有交换了空间位置,然后才交换元素位置,也就是A[min]
上机测试
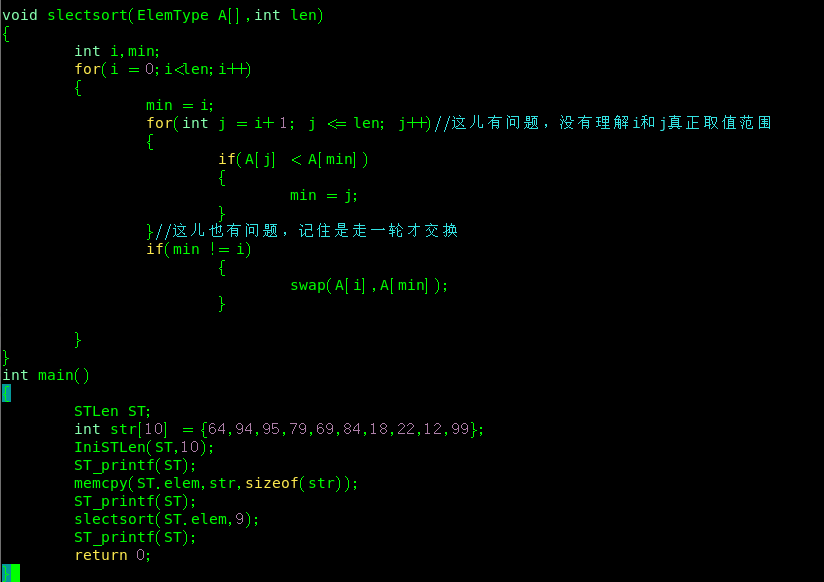
别看代码简单,但是自己出现了很大的问题,具体问题,看图
2.堆排序(重点)
堆的本质就是树(层次建树)
将树放到数组中就是堆
排序后的结果是大顶堆,也就是父亲节点是最大的
完全二叉树
层次建树得到的是完全二叉树(遗忘知识点)
一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
规律
n/2 - 1 得到的就是最后一个父亲节点(n为总共的节点数),算出来的结果是,数组中的位置
左孩子子节点的位置(下标) = 2 * 父亲节点的位置+1;

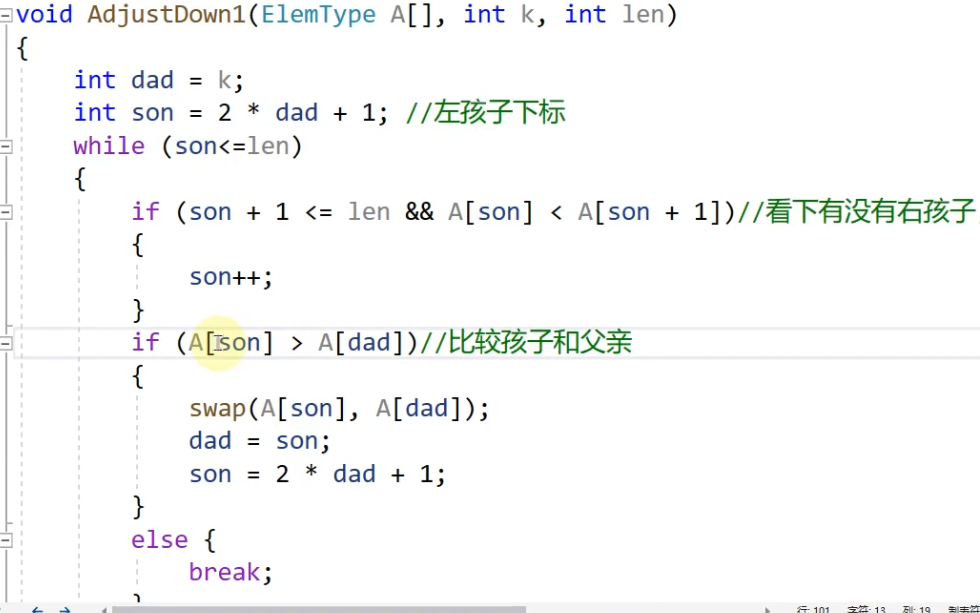
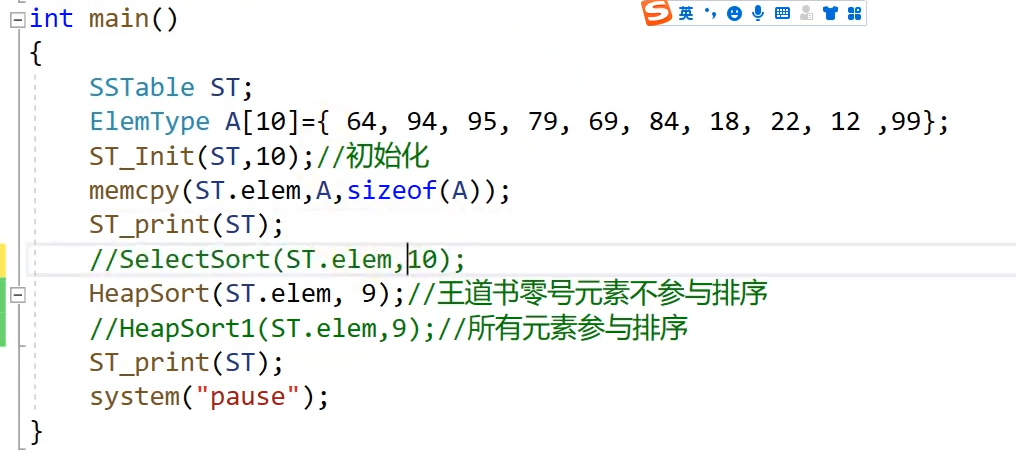
感觉已经拿下,但是还没有实操,先总结一遍:
1.堆排序,首先必须建立一个结构体,这个结构体就是数组,因为要用到数组的长度,所以要建立这个结构体(认识错误,这儿建立结构体的目的是为了跑代码,利用随机数生成,确保代码的正确性,否则不需要结构体)
2.现在我们初始化完毕,直到数组里的数据,直到数组的空间大小,然后使用堆排序,heapsort
3.现在我们写堆排序的代码
首先我们做的第一步是找最后一个节点的父节点,我们要通过这个节点不断循环构建成大根堆,然后达到排序的目的
其次两个关键的公式,最后一个父节点等于数组空间的大小除以2加1 i = len/2 + 1; i = lens/2; (lens代表的是数组空间的最大下标)
第二个公式:父亲节点的左孩子等于二倍的父亲节点的位置加1 son = 2*i +1;
之后我们要做的就是循环,我们已经直到父亲节点的位置了,这时我们就要调用调整大根堆的函数,adjest ,定义一个father 一个son,判断是否有孩子,若是有,那么就开始调整,否则不执行该函数。假设现在有孩子节点,son <= lens,之后判断是否有右孩子并且右孩子是否比左孩子的值大,若是右孩子大,现在son++;再判断是否孩子比父亲的值大,如果大则交换,否则跳出循环。这时候注意,一个关键的代码,就是我么这时交换后,为了实现我们之后的调整第一个位置的函数(也就是adject (A,0,i),此时的情况是我们得到最大的数,放到最后一个位置,但是第一个位置所构成的不是大根堆,所以要不断修改第一个位置的树),我们要把儿子节点赋值给父亲,根据父亲节点,再找儿子节点。
这时候我们的调整函数写完,并且执行完一个for循环,得到大根堆,此时交换第一个和最后一个元素,如上诉括号中所说,我们现在还需要调整大根堆,这时将长度减- 再次循环,直到循环到i= 0,并且不断把最大的放到最后,这是我们就可以得到一个从小到大的顺序。
简单的来说就是,先进行大顶堆的构造,然后将树根最后的值交换,这时调整树根变成大顶堆,一直循环
上机测试
1.对于最基础的问题,swap,没有用应用,导致一直都是原始数据,而且看了一遍还没有查出问题!这证明自己还不是太理解
2.对于原理性的东西,也就是我使用ST来进行堆排序,感觉没有问题,因为ST也是数组,我完全可以用ST.elem来完成一系列的交换,但是事实证明是不可以的,会报错,不太清楚是什么问题,所以现在先记住当堆排序的时候,需要重新命名一个数组,并且注意数组就相当于是指针,不需要引用,它本身就代表地址
3.最关键的地方忘记了,就是上面反复强调的,当孩子的数比父亲节点的数大的时候,交换之后,我们一定要让父亲节点等于孩子节点,来完成堆排序的第二个循环,以后写代码的时候一块一块的写,否则容易遗漏。



注意
以上代码都没有初始化ST.len,因为用不到