1 为什么要剪枝
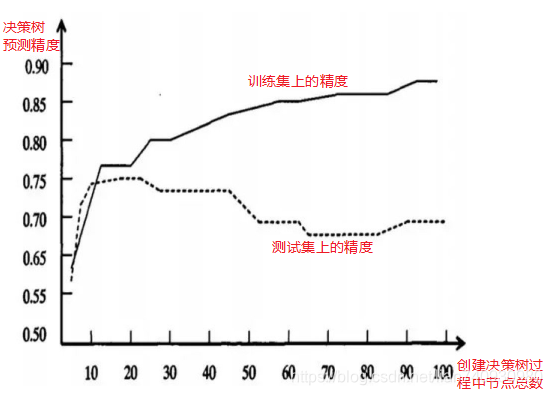
出现这种情况的原因:
- 原因1:噪声、样本冲突,即错误的样本数据。
- 原因2:特征即属性不能完全作为分类标准。
- 原因3:巧合的规律性,数据量不够大。
剪枝 (pruning)是决策树学习算法对付"过拟合"的主要手段。主动去掉一些分支来降低过拟合的风险。
2 常用的减枝方法
决策树剪枝的基本策略有"预剪枝" (pre-pruning)和"后剪枝"(post- pruning) 。
- 预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分并将当前结点标记为叶结点;基于信息增益准则。
- 后剪枝则是先从训练集生成一棵完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
2.1 预剪枝

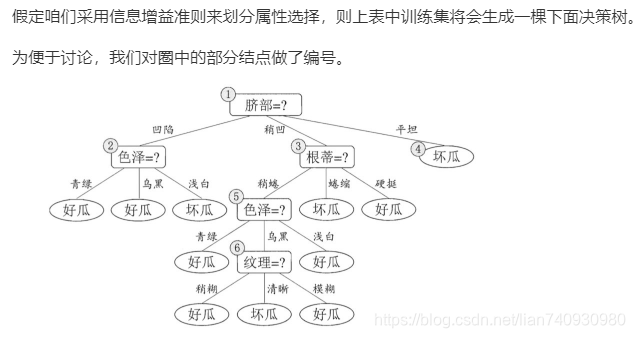
在划分之前,所有样例集中在根结点。
- 若不进行划分,该结点将被标记为叶结点,其类别标记为训练样例数最多的类别,假设我们将这个叶结点标记为"好瓜"。
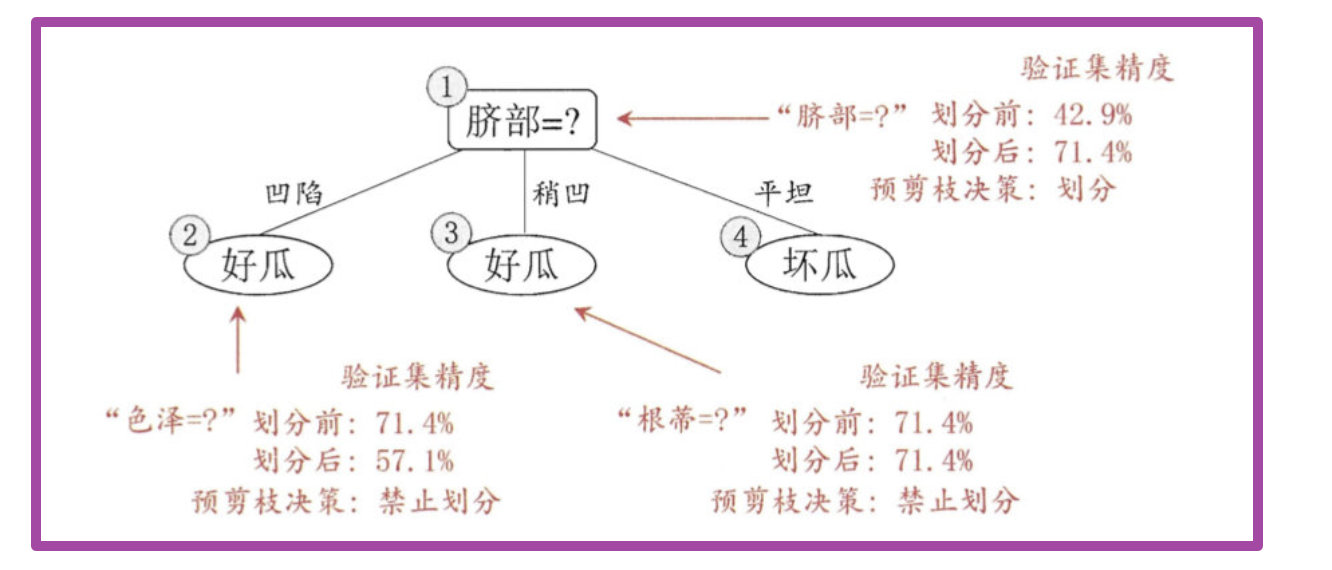
- 用前面表的验证集对这个单结点决策树进行评估。则编号为 {4,5,8} 的样例被分类正确。另外 4个样例分类错误,于是验证集精度为3/7= 42.9%。
在用属性"脐部"划分之后,上图中的结点2、3、4分别包含编号为 {1,2,3, 14}、 {6,7, 15, 17}、 {10, 16} 的训练样例,因此这 3 个结点分别被标记为叶结点"好瓜"、 "好瓜"、 "坏瓜"。
此时,验证集中编号为 {4, 5, 8,11, 12} 的样例被分类正确,验证集精度为5/7 = 71.4\% >42.9%.
于是,用"脐部"进行划分得以确定。
然后,决策树算法应该对结点2进行划分,基于信息增益准则将挑选出划分属性"色泽"。然而,在使用"色泽"划分后,编号为 {5} 的验证集样本分类结果会由正确转为错误,使得验证集精度下降为 57.1%。于是,预剪枝策略将禁 止结点2被划分。
对结点3,最优划分属性为"根蒂",划分后验证集精度仍为 71.4%. 这个 划分不能提升验证集精度,于是,预剪枝策略禁止结点3被划分。
对结点4,其所含训练样例己属于同一类,不再进行划分.
于是,基于预剪枝策略从上表数据所生成的决策树如上图所示,其验证集精度为 71.4%. 这是一棵仅有一层划分的决策树,亦称"决策树桩" (decision stump).
2.2 后剪枝
后剪枝先从训练集生成一棵完整决策树,继续使用上面的案例,从前面计算,我们知前面构造的决策树的验证集精度为42.9%。
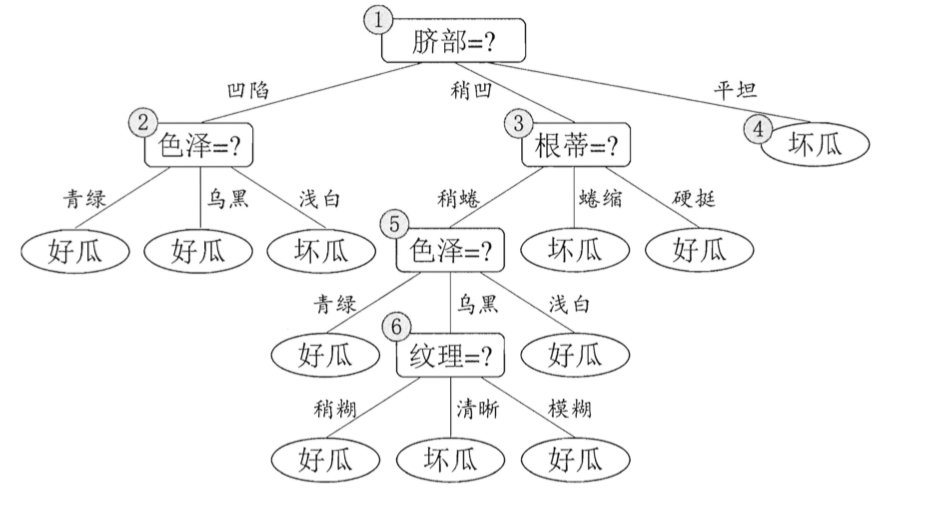
后剪枝首先考察结点6,若将其领衔的分支剪除则相当于把6替换为叶结点。替换后的叶结点包含编号为 {7, 15} 的训练样本,于是该叶结点的类别标记为"好瓜",此时决策树的验证集精度提高至 57.1%。于是,后剪枝策略决定剪枝,如下图所示。
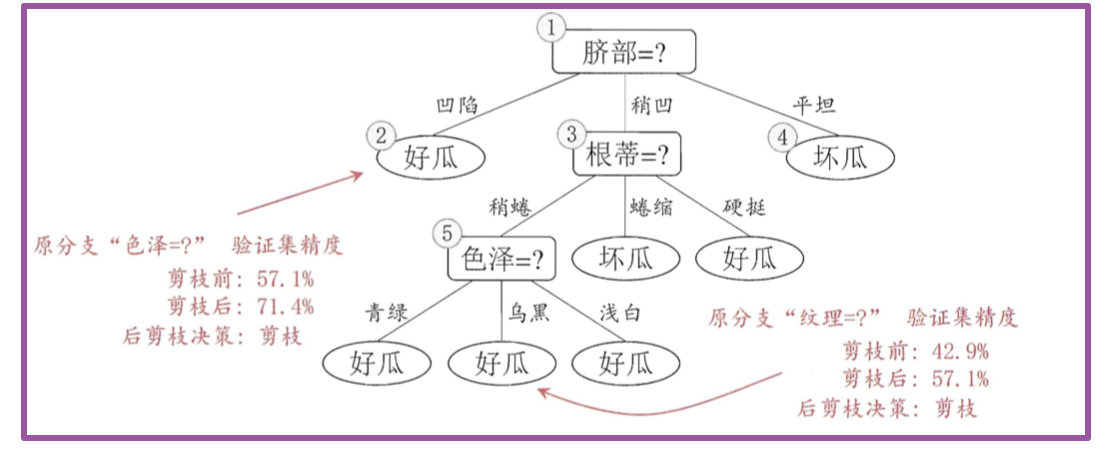
然后考察结点5,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号为 {6,7,15}的训练样例,叶结点类别标记为"好瓜';此时决策树验证集精度仍为 57.1%. 于是,可以不进行剪枝.
对结点2,若将其领衔的子树替换为叶结点,则替换后的叶结点包含编号 为 {1, 2, 3, 14} 的训练样例,叶结点标记为"好瓜"此时决策树的验证集精度提高至 71.4%. 于是,后剪枝策略决定剪枝.
对结点3和1,若将其领衔的子树替换为叶结点,则所得决策树的验证集 精度分别为 71.4% 与 42.9%,均未得到提高,于是它们被保留。
最终,基于后剪枝策略所生成的决策树就如上图所示,其验证集精度为 71.4%。
对比两种剪枝方法,
- 后剪枝决策树通常比预剪枝决策树保留了更多的分支。
- 一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。
- 但后剪枝过程是在生成完全决策树之后进行的。 并且要自底向上地对树中的所有非叶结点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多.
3 小结
- 剪枝原因【了解】
- 噪声、样本冲突,即错误的样本数据
- 特征即属性不能完全作为分类标准
- 巧合的规律性,数据量不够大。
- 常用剪枝方法【知道】
- 预剪枝
- 在构建树的过程中,同时剪枝
- 限制节点最小样本数
- 指定数据高度
- 指定熵值的最小值
- 在构建树的过程中,同时剪枝
- 后剪枝
- 把一棵树,构建完成之后,再进行从下往上的剪枝
- 预剪枝