该博客内容为 搭建 镜像集群:
RabbitMQ 单机结构:

RabbitMQ 双机集群:
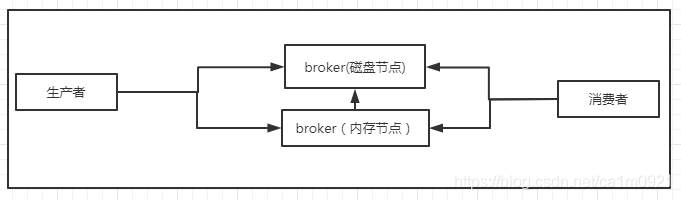
RabbitMQ 双机集群:
内存节点关闭,访问磁盘节点可以正常消费
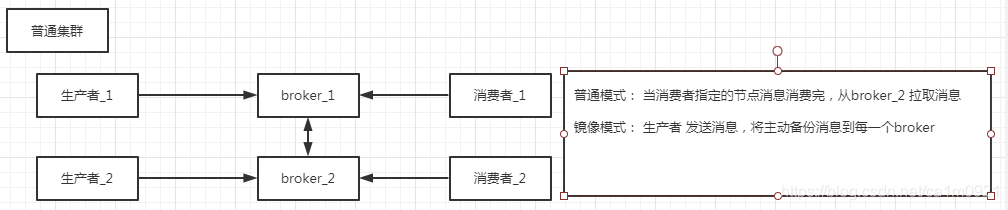
RabbitMQ 普通集群:
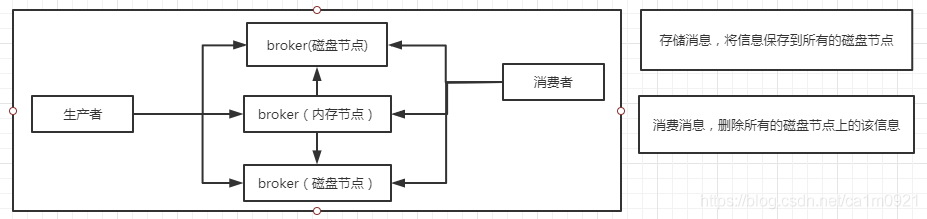
RabbitMQ 镜像集群:
RabbitMQ镜像集群是通过在RabbitMQ服务器配置相应的规则,把交换器、队列的数据进行Node之间Copy,对内网流量要求较高。在生产者扔消息时,会在所有Node之间同步完毕之后才会响应扔消息成功。
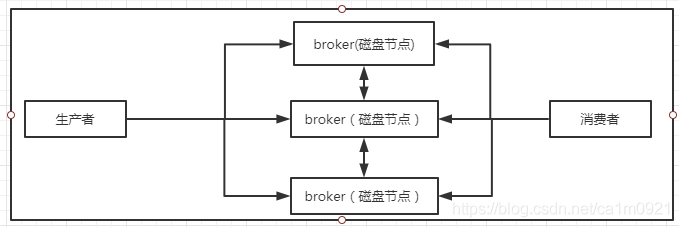
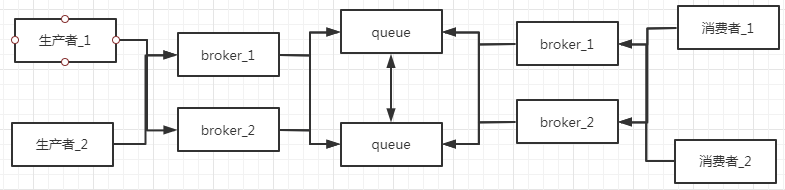
RabbitMQ 镜像集群 + HaProxy :
RabbitMQ 镜像集群 + HaProxy + KeepAlive :
Q&A:
用三台机器做了个三个磁盘节点,搭建了镜像集群,上周下班的时候,把服务停止了,今天来公司发现起不来了。三个服务都试了下,都不行,看错误日志:
2020-06-28 10:50:25.814 [warning] <0.277.0> Error while waiting for Mnesia tables: {timeout_waiting_for_tables,[rabbit_user,rabbit_user_permission,rabbit_topic_permission,rabbit_vhost,rabbit_durable_route,rabbit_durable_exchange,rabbit_runtime_parameters,rabbit_durable_queue]}
2020-06-28 10:50:25.814 [info] <0.277.0> Waiting for Mnesia tables for 30000 ms, 3 retries left
2020-06-28 10:50:55.815 [warning] <0.277.0> Error while waiting for Mnesia tables: {timeout_waiting_for_tables,[rabbit_user,rabbit_user_permission,rabbit_topic_permission,rabbit_vhost,rabbit_durable_route,rabbit_durable_exchange,rabbit_runtime_parameters,rabbit_durable_queue]}
2020-06-28 10:50:55.815 [info] <0.277.0> Waiting for Mnesia tables for 30000 ms, 2 retries left
2020-06-28 10:51:25.816 [warning] <0.277.0> Error while waiting for Mnesia tables: {timeout_waiting_for_tables,[rabbit_user,rabbit_user_permission,rabbit_topic_permission,rabbit_vhost,rabbit_durable_route,rabbit_durable_exchange,rabbit_runtime_parameters,rabbit_durable_queue]}
2020-06-28 10:51:25.816 [info] <0.277.0> Waiting for Mnesia tables for 30000 ms, 1 retries left
2020-06-28 10:51:55.817 [warning] <0.277.0> Error while waiting for Mnesia tables: {timeout_waiting_for_tables,[rabbit_user,rabbit_user_permission,rabbit_topic_permission,rabbit_vhost,rabbit_durable_route,rabbit_durable_exchange,rabbit_runtime_parameters,rabbit_durable_queue]}
2020-06-28 10:51:55.817 [info] <0.277.0> Waiting for Mnesia tables for 30000 ms, 0 retries left
2020-06-28 10:52:25.819 [error] <0.276.0> CRASH REPORT Process <0.276.0> with 0 neighbours exited with reason: {{timeout_waiting_for_tables,[rabbit_user,rabbit_user_permission,rabbit_topic_permission,rabbit_vhost,rabbit_durable_route,rabbit_durable_exchange,rabbit_runtime_parameters,rabbit_durable_queue]},{rabbit,start,[normal,[]]}} in application_master:init/4 line 138
2020-06-28 10:52:25.819 [info] <0.44.0> Application rabbit exited with reason: {{timeout_waiting_for_tables,[rabbit_user,rabbit_user_permission,rabbit_topic_permission,rabbit_vhost,rabbit_durable_route,rabbit_durable_exchange,rabbit_runtime_parameters,rabbit_durable_queue]},{rabbit,start,[normal,[]]}}看了下,发现是 Mnesia 的错,但我上周是自己在服务没有数据处理的时候,正常 kill 掉的服务,应该数据库没有问题。看了下晚上说的,可能需要把数据删除,再重启。我觉得不太行。后来想着,集群应该有一定的启动顺序才对。
然后先启动从节点,再启动主节点,尝试了下,服务起来了。
在从服务节点机器上:
rabbitmq-server -detached # 启动从服务 启动从节点
ps -aux | grep rabbitmq # 查看服务是否启动成功
rabbitmqctl status # 查看节点状态
在主服务节点机器上:
rabbitmq-server -detached # 启动主服务 启动主节点
ps -aux | grep rabbitmq # 查看服务是否启动成功
rabbitmqctl status # 查看节点状态
在搭建集群的时候,要先启动主节点, 然后将从节点 join 到主节点中,建立联系。
在重启集群的时候,要先启动从节点,然后再启动主节点,在启动主节点的时候,会查询从节点的信息,默认从节点应该存活才行。
版权声明:本文为ca1m0921原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。