
摘要
在 公开课笔记 | 多模态短视频内容标签技术及应用 [1]文章中介绍的诸多内容: 内容标签是对文本、图文或者短视频等内容的表征,根据内容来生成的标签,标签的集合是开放的;内容标签在各种推荐系统里面使用比较广泛,爱奇艺视频以及当前各个相关公司的信息流+短视频业务中内容标签都扮演这一个重要的角色:一个不可缺少的抽象表征步骤,以及对最终推荐效果有重大影响的步骤。爱奇艺在视频标签技术中应用多模态特征融合为视频打标取得良好效果,证实多模态技术的有效性。本文介绍视频多模态系列的框架和一些实践方法。
一、介绍
关于多模态方法,本文认为是一项通用的解决方案。但似乎NLP问题以及普通CV问题极少提及,而在视频(短视频及小视频)领域提及并应用较多,原因认为是文本及图片较容易采集有效特征并进行很好地表征,而视频由于是抽帧后进行学习(实际对一段视频抽帧比例还不会太高),这对直接使用视频抽帧后的图谱进行学习的方法直接产生了较低的上限,需要通过其他数据源来进行补充学习。
想要理解为什么需要在视频标签领域使用多模态技术,并且该方法会起作用,先了解一下短视频内容标签有什么样的难点[1]:
- 第一,内容标签集合是一个开放集合,它的数量可以达到十万级甚至数百万,所以不能使用分配的方法(如分类),来生成标签。[标签数量较大且基本会呈现长尾形态]
- 第二,短视频内容标签的标准很难统一,两个人给同一批短视频标注内容标签,标注完全一致率只有22.1%。所以对于一个短视频哪些词可以作为内容标签,并没有统一的标准。[标签系统可变]
- 第三,抽象标签占比较高,抽象标签学术上叫absence标签。就是这个标签它没有在标题中出现,经过统计在短视频中抽象标签占比高于40%。同时,标题因为长度也比较短,特别是短视频标题,很多情况下它并不是一个完全的句子,而是一些关键词的拼接,在信息比较少又不规范的情况下,语义理解起来也就更加困难。
- 第四,融合多模态,包括封面图和视频内容,比如,在一个短视频的标题为“男子开车堵在女子家门口,女子不费吹灰之力,连人带车一块弄走”,看不出这个视频是什么含义,但这个视频内容描述的是关于明星张歆艺的相关的内容,所以这类内容需要结合多模态的信息才能准确抽取出准确的内容标签。
二、Multimodal
针对视频标签多模态技术中,常使用speech/vision/language三种模态其中两种或者三种进行融合。
爱奇艺文章[1]中给出了一个在短视频标签方面的总体框架。
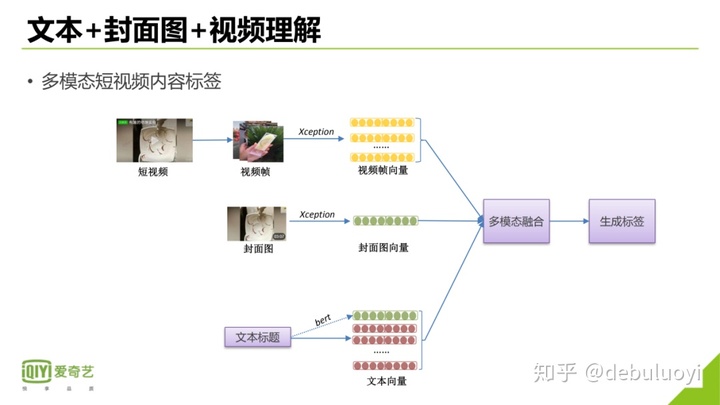
内容表征融合有互补性和冗余性的特点,融合方式有 joint representation和coordinated representation两种方式:

- Joint Representation
1.Simple concatenation
2.Element wise multiplication or summation
3.Multilayer perceptron
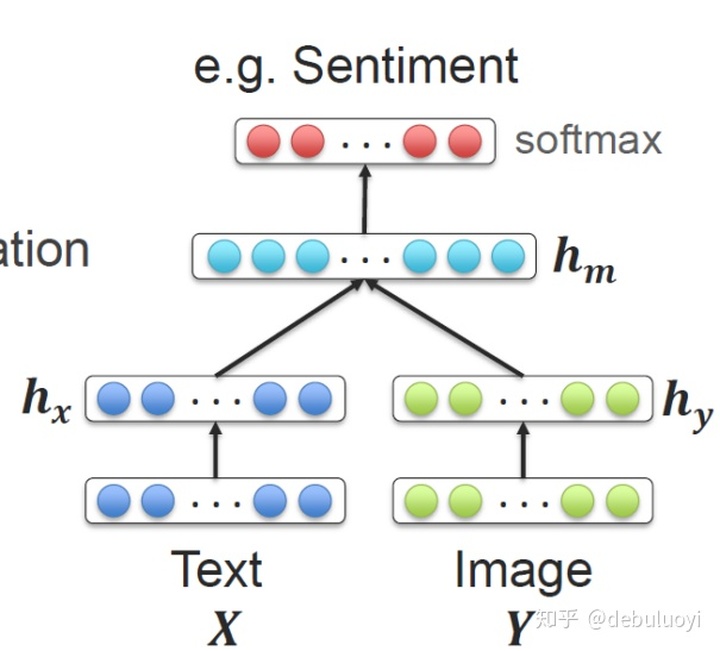
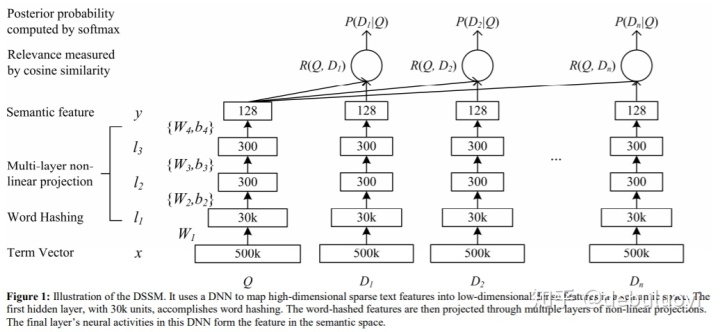
- Coordinated Representations
Huang, P. S. , He, X. , Gao, J. , Deng, L. , & Heck, L. . (2013)[3]提出的这种多塔网络,将文中的搜索曝光数据换成对不同数据源(e.g. image + text)网络输出层进行交互计算形成融合也就是 Coordinated Representations了。
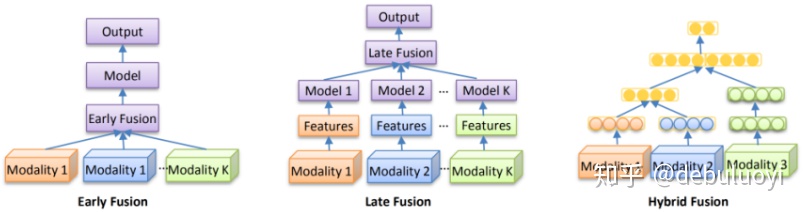
当然基于不同位置的融合也可以分为三种方式,实际操作时很多情下都是数据层面和前向网络层面都会进行融合处理。
- early fusion:即特征融合,不同模态原始数据进行融合;
- late fusion:结果融合,单模态单独决策,最后在分数上进行融合包括max,avg以及加权平均等措施,打过比赛的同学应该比较清楚机器学习比赛里面是常用的;
- hybrid fusion:模型中不同层级进行融合,正真大幅有效的可能是这一种,其他两种可能效果有限,当然也可以结合使用。
三、视频多模态应用
我们面临的实际问题就是对一个短视频比如电视剧中的一个精彩片段,e.g. 以下视频(展示关键帧)需要预测tag:内地剧,古装剧。

实际视频关键帧/图像处理仍然是CNN为主体的模型,而标题文本的表征使用bert-base模型。视频的多个关键帧表征的向量与bert语义向量进行拼接融合。
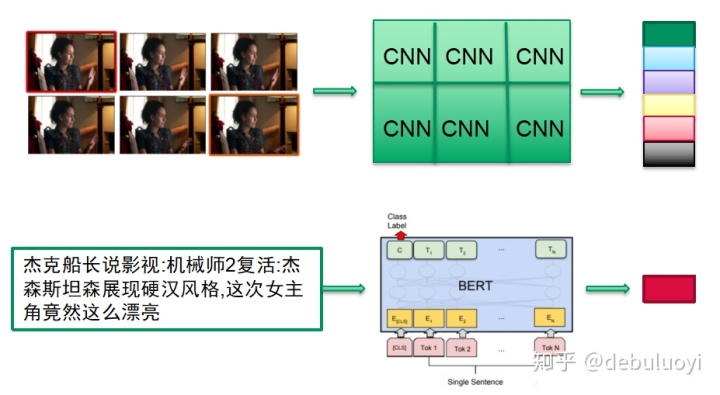
那么实际要怎么融合呢?首先想到的肯定是将cv结果和文本结果进行concat/summation/attention_sumation等基本朴素的思路(v1_att_sum:效果最好,同时可以分析视觉和文本的各自贡献度):
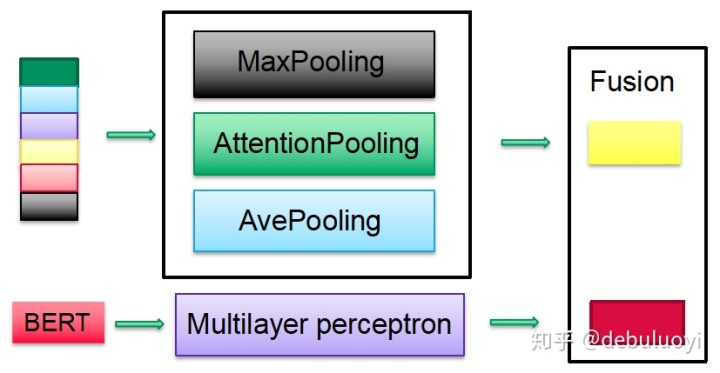
实际操作就会发现,bert表征向量768维度太大,而一般CNN模型不会处理成这么大,而且bert模型的预训练使得文本语义表征非常强,造成整体融合仍然偏向于bert的表征结果。如何解决这个问题呢?
总体思路是对多种模态的特征进行平衡:这里是指加强每帧与bert的联系从而平衡图像和文本的特征防止其中一方变得过强,如下两种方式:
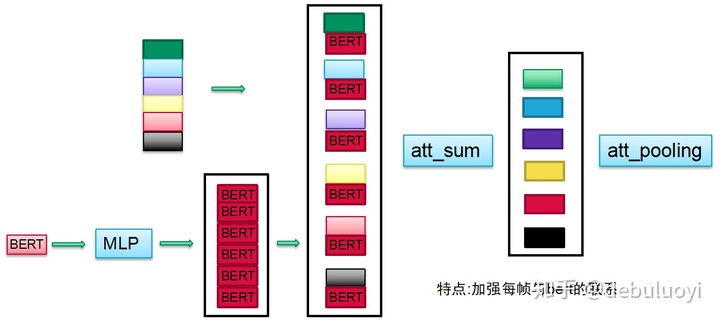
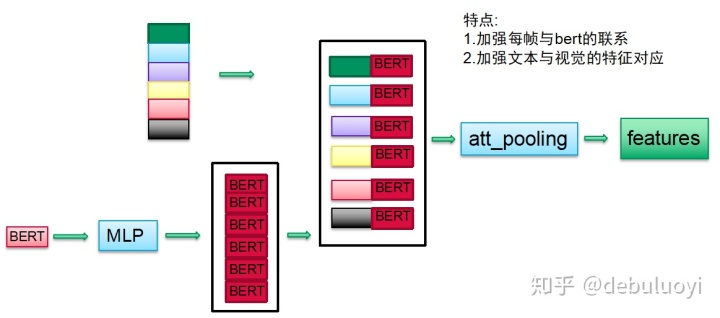
四、多模态前沿
介绍两篇2019年的比较前沿的文章:
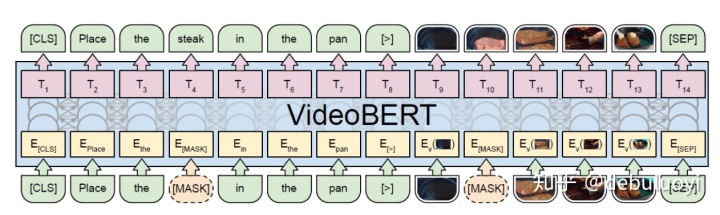
VideoBERT: A Joint Model for Video and Language Representation Learning
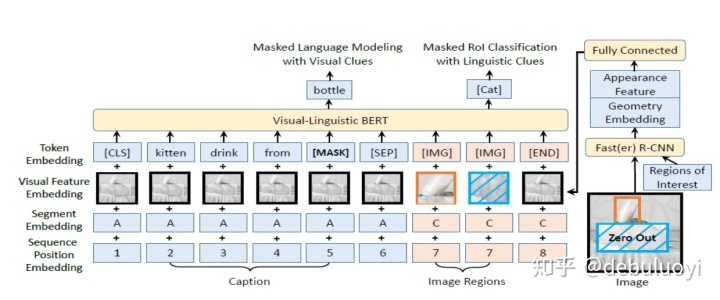
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
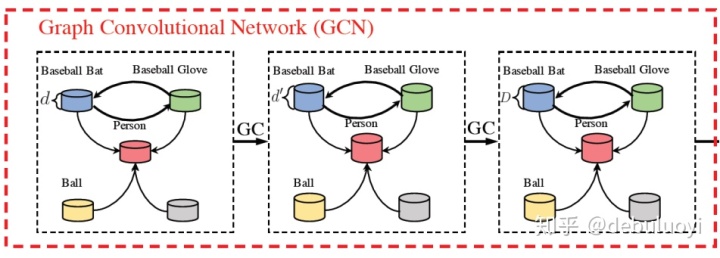
GCN:增加标签之间的相关性【这个可以尝试,或者专门搜集标签数据进行一个预训练来专门表征标签】
五、小结
前沿研究值得关注主要是为了进一步提升模型的表征推理能力。但工业上操作还是有一些其他的tricks,特别是在数据层面的操作是最为直观而又有效的。
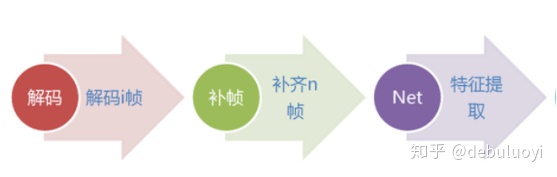
1.对视频抽关键帧,并随机补齐或采样:
2.BERT模型随机mask部分词语:实际bert是按照token mask的,对于中文来说主要是字级别。但中文词语义的固定性要远远高于字符,对部分词mask能有效提升效果,这在bert后续很多模型中得到印证。
3.增加尾部标签对应样本的采样率:这个也是针对长尾问题常用的方法了,图像可以进行多种方式;文本出了简单的copy也可以进行截断及加mask的方式。
4.圈定更有效范围更小的tag 集合。这个思路很朴素但是很有效,而且在实际工作中是应该做的一步,商业应用本身就应该针对有用且有曝光需求的标签进行操作的。
5.人工纠正标注样本的缺失+引入人工规则精修预测结果;
6.多轮预测模型结果补充训练集标注缺失:这里可以结合一些主动学习的思路,在少量标注补充的时候,使用训练的模型去预测训练集,只标注预测本身错误的样本,这样会比较有效且工作量小很多;
7.视频理解中的多模态-Loss函数:引入平衡权重。
参考文献
[1] 爱奇艺视频多模态: https://mp.weixin.qq.com/s/CEPBXaJfrIO1w0yX7YdZZA
[2] BERT:Bidirectional Encoder Representation from Transformers
[3] Huang, P. S. , He, X. , Gao, J. , Deng, L. , & Heck, L. . (2013). Learning deep structured semantic models for web search using clickthrough data.Proceedings of the 22nd ACM international conference on Conference on information & knowledge management. ACM.
[4] VideoBERT: A Joint Model for Video and Language Representation Learning(2019)
[5] VL-BERT: Pre-training of Generic Visual-Linguistic Representations(2019)