为什么要关心CPU的性能

哪些东西影响了CPU的性能
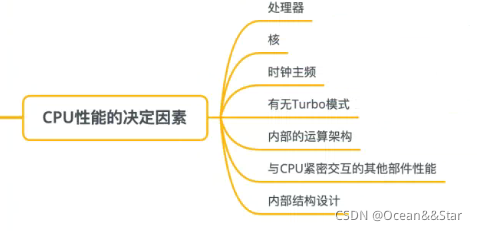
CPU的性能决定因素
下表了一些CPU的发展: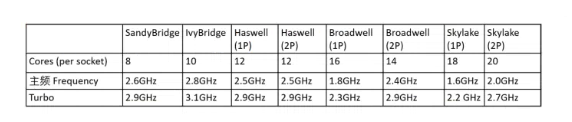
从上面我们可以看出:
- 虽然CPU更新换代,但是处理器的时钟主频基本不再提高,甚至变得更低了
- 为了提高单个处理器的性能,每个处理器里面的核数却越来越多,这样就可以尽量的提升并行处理能力
- 每一代CPU都允许Turbo模式,就是让CPU的主频提高。目的是可以让处理器在特殊情况下,用提高功耗的代价来增加主频,从而获得更高性能
CPU的内部结构
CPU的性能也取决于它的内部结构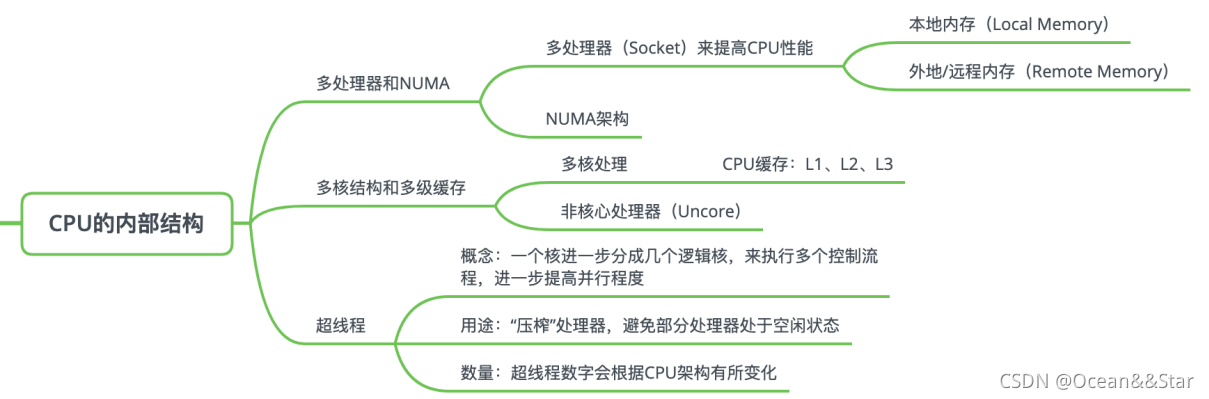
如何迅速分析出系统CPU的瓶颈在哪⾥
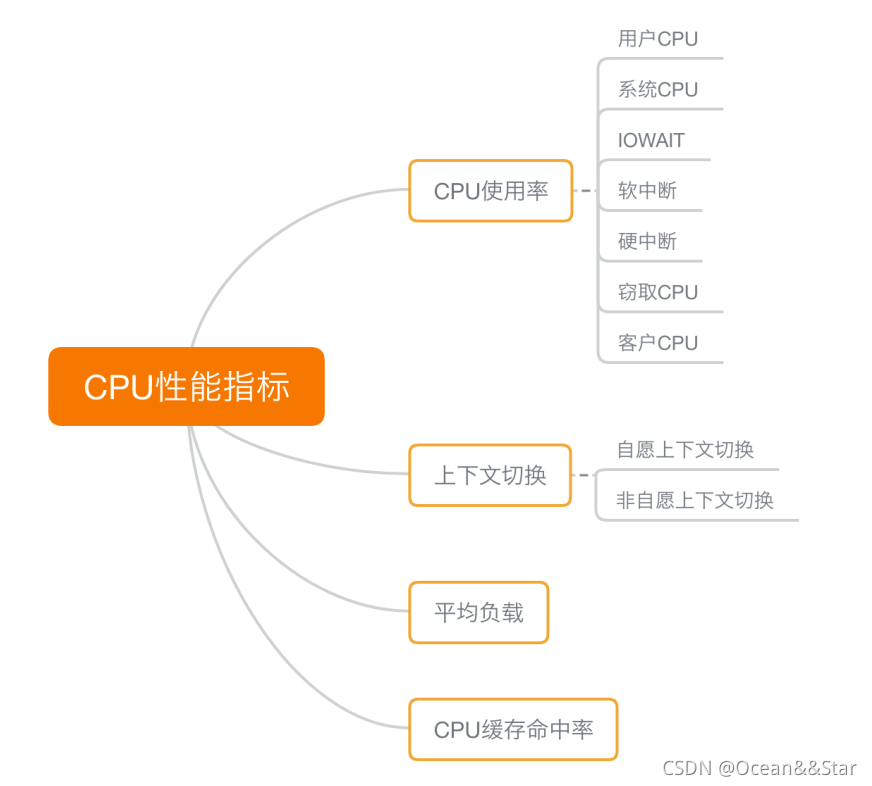
先搞清楚CPU的性能指标
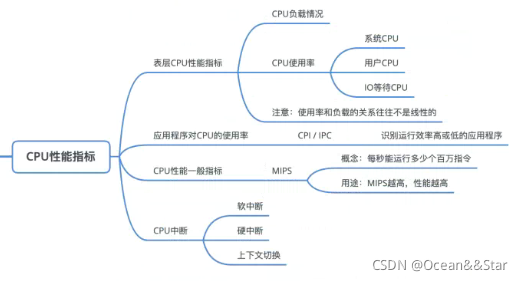
CPU的负载(最表层的指标)
- 常用平均负载(load average)来衡量,指的是系统的平均活跃进程数。
- 它反映了系统的整体负载情况,主要包括三个数值,它反应了系统的整体负载情况,主要包括三个数值,分别指过去1分钟、过去5分钟和过去15分钟的平均负载。
- 理想情况下,平均负载等于逻辑 CPU 个数,这表示每个 CPU 都恰好被充分利⽤。如果平均负载⼤于逻辑CPU个数,就表示负载⽐较重了。
CPU的使用率(最表层的指标)
定义
- CPU使用率描述了非空闲时间占总CPU时间时间的百分比
分类
- 根据CPU上运行任务的不同,又被分为用户CPU、系统CPU、等待IO CPU、软中断和硬中断CPU使用率等
- 用户CPU使用率,包括用户态CPU使用率(user)和低优先级用户态CPU使用率(nice),表示CPU在用户态运行的时间百分比。用户CPU使用率高,通常说明有应用程序比较繁忙
- 系统CPU使用率,表示CPU在内核态运行的时间百分比(不包括中断)。系统CPU使用率高,说明内核比较繁忙
- 等待IO的CPU使用率,也就是iowait,表示等待IO的时间百分比。iowait高,说明系统与硬件设备的IO交互时间比较长
- 软中断和硬中断CPU使用率,分布标度内核调用软中断处理程序,硬件中处理程序的时间百分比。他们的使用率高,通常说明系统发生了大量的中断。
- 除了上面这些,还有虚拟化环境会用到的窃取 CPU 使⽤率(steal)和客户 CPU 使⽤率(guest),分别表示被其他虚拟机占⽤的 CPU 时间百分⽐,和运⾏客户虚拟机的 CPU 时间百分⽐。
CPU使用率与负载使用率的关系
- 需要注意的是,因为CPU架构的复杂性,以及和其他部件的交互,CPU的使用率和负载关系往往不是线性的。
- 也就是说,如果10%的CPU使用率可以每秒处理1000个请求,那么80%的CPU使用率能够处理多少请求呢?不太可能处理每秒 8 千个请求,往往会远远小于这个数字。
进程上下文切换
- ⽆法获取资源⽽导致的⾃愿上下⽂切换;
- 被系统强制调度导致的⾮⾃愿上下⽂切换。
上下文切换,本身是保证Linux正常运行的一项核心功能,但过多的上下文切换,会将原本运行进程的CPU时间,消耗在寄存器、内核栈以及虚拟内存等数据的保存和恢复上,缩短进程真正运行的时间,成为性能瓶颈。
CPU缓存的命中率
由于CPU发展的速度远快于内存的发展,CPU的处理速度就比内存的访问速度快得多。这样,CPU在访问内存的时候,免不了要等待内存的响应。为了协议这两者巨大的性能差距,CPU缓存(通常是多级缓存)就出现了。
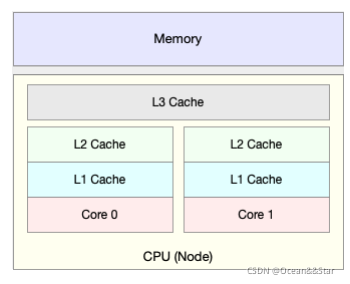
就像上⾯这张图显示的,CPU缓存的速度介于CPU和内存之间,缓存的是热点的内存数据。根据不断增⻓的热点数据,这些缓存按照⼤⼩不同分为 L1、L2、L3 等三级缓存,其中 L1 和 L2 常⽤在单核中, L3 则⽤在多核中。
从 L1 到 L3,三级缓存的⼤⼩依次增⼤,相应的,性能依次降低(当然⽐内存还是好得多)。⽽它们的命中率,衡量的是CPU缓存的复⽤情况,命中率越⾼,则表示性能越好。
下表是一块2GHZ主频的COU,进行寄存器和缓存访问的一般延迟,分别用时钟周期数和绝对时间来表示,同时也给出了在每个CPU核上面的字节大小。注意,数字仅供参考,因为每款 CPU 都不同。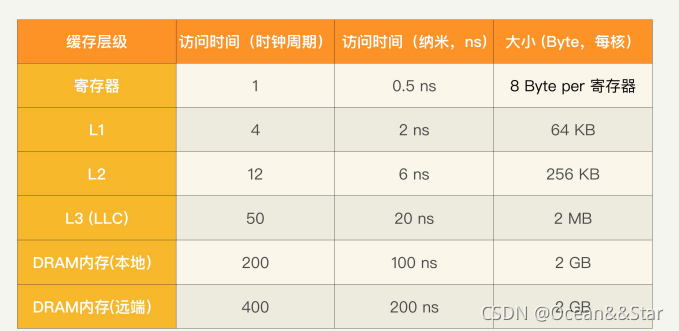
为了方便对比,我们把内存的性能也放在同一个表格里。指的一体的是现在NUMA(非统一内存访问,Non-Uniform Memory Access)处理前会有本地和远端内存的区别,访问本地节点的内存会快一点
CPU有哪些性能检测工具?
掌握了 CPU 的性能指标,我们还需要知道,怎样去获取这些指标,也就是⼯具的使⽤。
- ⾸先,平均负载。
- 我们先⽤ uptime, 查看了系统的平均负载;
- ⽽在平均负载升⾼后,⼜⽤ mpstat 和 pidstat ,分别观察了每个 CPU 和每个进程 CPU 的使⽤情况,进⽽找出了导致平均负载升⾼的进程,也就是我们的压测⼯具 stress。
- 第⼆个,上下⽂切换。
- 我们先⽤ vmstat ,查看了系统的上下⽂切换次数和中断次数;
- 然后通过 pidstat ,观察了进程的⾃愿上下⽂切换和⾮⾃愿上下⽂切换情况;
- 最后通过 pidstat ,观察了线程的上下⽂切换情况,找出了上下⽂切换次数增多的根源,也就是基准测试⼯具 sysbench。
- 第三个,进程 CPU 使⽤率升⾼。
- 我们先⽤ top ,查看了系统和进程的CPU使⽤情况,发现 CPU 使⽤率升⾼的进程是php-fpm
- 再⽤ perf top ,观察 php-fpm 的调⽤链
- 最终找出 CPU 升⾼的根源,也就是库函数 sqrt() 。
- 第四个,系统的 CPU 使⽤率升⾼。
- 我们先⽤ top 观察到了系统CPU升⾼,但通过 top 和 pidstat ,却找不出⾼ CPU 使⽤率的进程。
- 于是,我们重新审视 top 的输出,⼜从 CPU 使⽤率不⾼但处于 Running 状态的进程⼊⼿,找出了可疑之处
- 最终通过 perf record 和 perf report ,发现原来是短时进程在捣⻤。
- 另外,对于短时进程,有⼀个专⻔的⼯具 execsnoop,它可以实时监控进程调⽤的外部命令。
- 第五个,不可中断进程和僵⼫进程的案例。
- 我们先⽤ top 观察到了 iowait 升⾼的问题,并发现了⼤量的不可中断进程和僵⼫进程;
- 接着我们⽤ dstat 发现是这是由磁盘读导致的,于是⼜通过 pidstat 找出了相关的进程。
- 但我们⽤ strace 查看进程系统调⽤却失败了,最终还是⽤ perf 分析进程调⽤链,才发现根源在于磁盘直接 I/O 。
- 最后⼀个,软中断。
- 我们通过 top 观察到,系统的软中断 CPU 使⽤率升⾼;
- 接着查看 /proc/softirqs, 找到了⼏种变化速率较快的软中断;
- 然后通过 sar 命令,发现是⽹络⼩包的问题
- 最后再⽤ tcpdump ,找出⽹络帧的类型和来源,确定是⼀个 SYN FLOOD 攻击导致的。
这么多的⼯具要怎么区分呢?在实际的性能分析中,⼜该怎么选择呢?
从两个不同的维度来理解它们,做到活学活⽤。
- 第⼀个维度,从 CPU 的性能指标出发。也就是说,当你要查看某个性能指标时,要清楚知道哪些⼯具可以做到
- ⽐如⽤ top 发现了软中断 CPU 使⽤率⾼后,下⼀步⾃然就想知道具体的软中断类型。那在哪⾥可以观察各类软中断的运⾏情况呢?当然是 proc ⽂件系统中的 /proc/softirqs 这个⽂件。
- ⽐如说,我们找到的软中断类型是⽹络接收,那就要继续往⽹络接收⽅向思考。系统的⽹络接收情况是什么样的?什么⼯具可以查到⽹络接收情况呢? dstat。
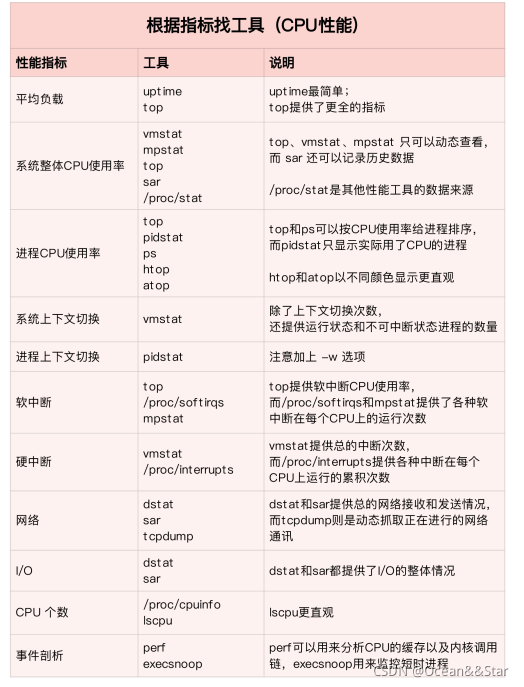
- 第⼆个维度,从⼯具出发。也就是当你已经安装了某个⼯具后,要知道这个⼯具能提供哪些指标。
- 这在实际环境特别是⽣产环境中也是⾮常重要的,因为很多情况下,你并没有权限安装新的⼯具包,只能最⼤化地利⽤好系统中已经安装好的⼯具,这就需要你对它们有⾜够的了解。
- 具体到每个⼯具的使⽤⽅法,⼀般都⽀持丰富的配置选项。不过不⽤担⼼,这些配置选项并不⽤背下来。你只要知道有哪些⼯具、以及这些⼯具的基本功能是什么就够了。真正要⽤到的时候, 通过man 命令,查它们的使⽤⼿册就可以了。
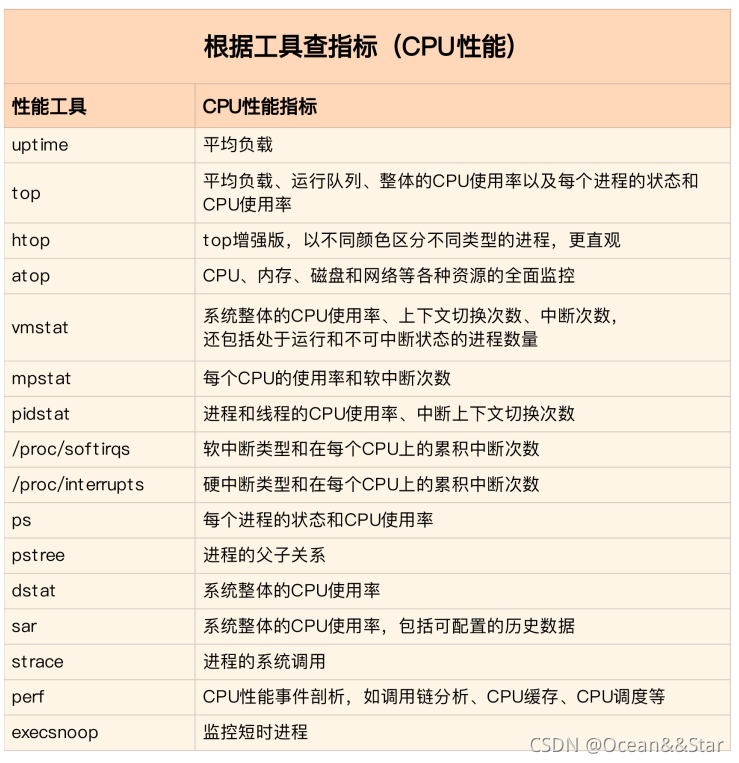
如何迅速分析CPU的性能瓶颈
在实际⽣产环境中,我们通常都希望尽可能快地定位系统的瓶颈,然后尽可能快地优化性能,也就是要⼜快⼜准地解决性能问题。
那有没有什么⽅法,可以⼜快⼜准找出系统瓶颈呢?答案是肯定的。
- 虽然 CPU 的性能指标⽐较多,但要知道,既然都是描述系统的CPU性能,它们就不会是完全孤⽴的,很多指标间都有⼀定的关联。想弄清楚性能指标的关联性,就要通晓每种性能指标的⼯作原理。
- 举个例子,用户CPU使用率高,我们应该去排查进程的用户态而不是内核态。因为用户CPU使用率反映的就是用户态的CPU使用情况,而内核态的CPU使用情况只会发现到系统CPU使用率上
有这样的基本认识,我们就可以缩⼩排查的范围,省时省⼒。
所以,为了缩⼩排查范围,通常会先运⾏⼏个⽀持指标较多的⼯具,如 top、vmstat 和 pidstat。
为什么是这三个⼯具呢?
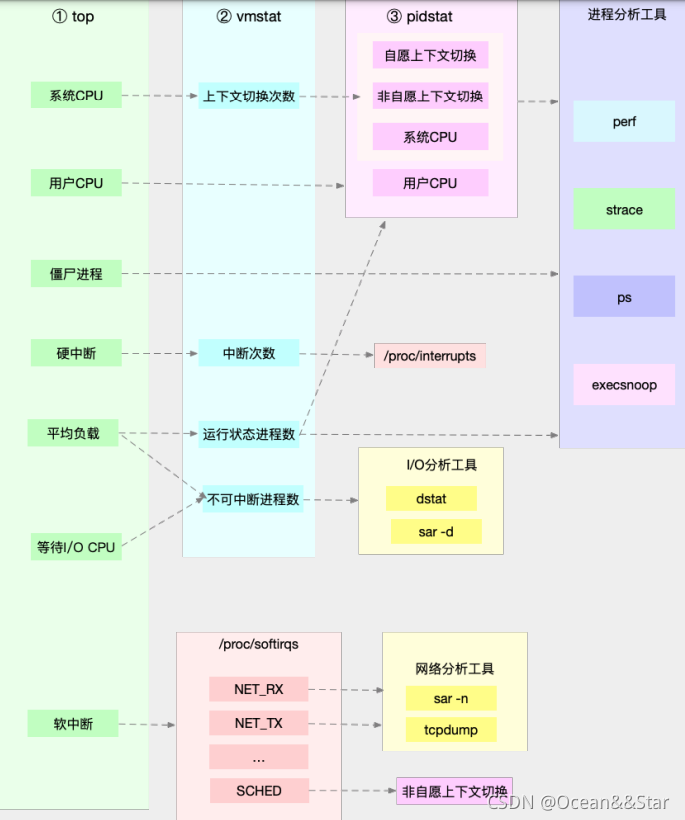
通过这张图你可以发现,这三个命令,⼏乎包含了所有重要的 CPU 性能指标,⽐如:
- 从 top 的输出可以得到各种 CPU 使⽤率以及僵⼫进程和平均负载等信息。
- 从 vmstat 的输出可以得到上下⽂切换次数、中断次数、运⾏状态和不可中断状态的进程数。
- 从 pidstat 的输出可以得到进程的⽤户 CPU 使⽤率、系统 CPU 使⽤率、以及⾃愿上下⽂切换和⾮⾃愿上下⽂切换情况。
另外,这三个⼯具输出的很多指标是相互关联的(上图中用虚线表示了它们的关联关系)。举几个例子
第一个例子:pidstat输出的进程用户CPU使用率升高,会导致top输出的用户CPU使用率升高
- 所以,当发现 top 输出的⽤户 CPU 使⽤率有问题时,可以跟 pidstat 的输出做对⽐,观察是否是某个进程导致的问题。
- ⽽找出导致性能问题的进程后,就要⽤进程分析⼯具来分析进程的⾏为,⽐如⽤ strace 分析系统调⽤情况,以及使⽤ perf分析调⽤链中各级函数的执⾏情况。
第⼆个例⼦,top 输出的平均负载升⾼,可以跟 vmstat 输出的运⾏状态和不可中断状态的进程数做对⽐,观察是哪种进程导致的负载升⾼。
- 如果是不可中断进程数增多了,那么就需要做 I/O 的分析,也就是⽤ dstat 或 sar 等⼯具,进⼀步分析 I/O 的情况。
- 如果是运⾏状态进程数增多了,那就需要回到 top 和 pidstat,找出这些处于运⾏状态的到底是什么进程,然后再⽤进程分析⼯具,做进⼀步分析。
最后⼀个例⼦,当发现 top 输出的软中断 CPU 使⽤率升⾼时,可以查看 /proc/softirqs ⽂件中各种类型软中断的变化情况,确定到底是哪种软中断出的问题。⽐如,发现是⽹络接收中断导致的问题,那就可以继续⽤⽹络分析⼯具 sar 和 tcpdump 来分析。
注意,上图中只列出了最核⼼的⼏个性能⼯具,并没有列出所有。先把重⼼放在核⼼⼯具上,毕竟熟练掌握它们,就可以解决⼤多数问题。小众工具可以以后学
CPU常见性能问题
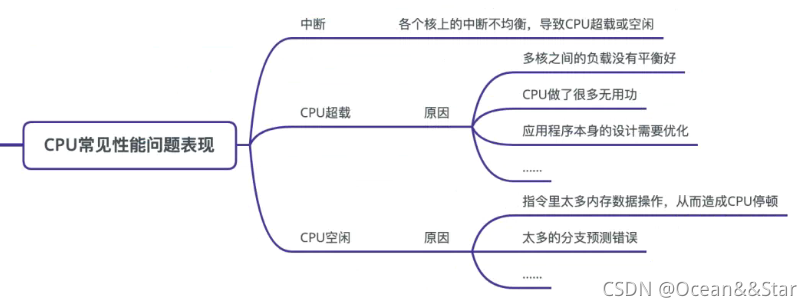
和CPU相关的性能问题,基本上就是表现为超载或者空闲
- 如果是CPU超载,那么就要分析为什么超载。多数情况下都不一定是合理的超载,比如说多核之间的负载没有平衡好,或者CPU干了很多没用的活,或者应用程序本身的设计需要优化等等
- 如果是CPU空闲,那么就要了解为什么空闲。可能是指令里面太多内存数据操作,从而造成CPU停顿;可能是太多的分支预测错误等。具体问题具体分析优化