数据集一、Dailydialogue
论文《DailyDialog_ A Manually Labelled Multi-turn Dialogue Dataset》。
该数据集是从英语学习者相关的网站上爬取的对话数据集,主题相对集中,语法相对规范。
总共有一万多对对话,每个对话大概8轮。
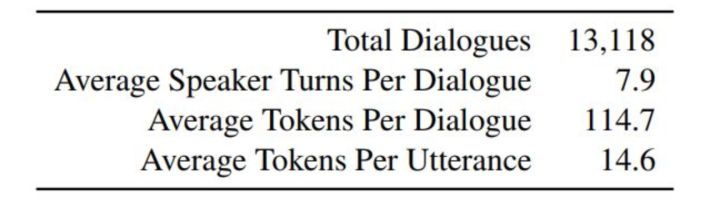
数据集众包含的文件有:
1)dialogues_text.txt:包含所有的一万多个对话,每行代表一对对话,对话之间用_eou_隔开,对话结尾也有一个_eou_。
2)dialogues_topic.txt:每行对应于一对对话所包含的主题,用数字1——10表示,其中1代表日常生活,2代表学校生活,3代表文化和教育,4代表态度和情感,5代表关系,6代表旅游,7代表健康,8代表工作,9代表政策/政治,10代表经济。
3)dialogues_act.txt:每行代表对话行为的解释,用数字1——4表示,其中1代表通知,2代表询问,3代表指示,4代表同情。
4)dialogues_emotion.txt:每行代表对话所包含的情感,用数字0——6表示,其中0代表没情感/中性,1代表生气,2代表厌恶,3代表:恐惧,4代表快乐,5代表悲伤,6代表惊讶。
5)train.zip,validation.zi和test.zip分别代表训练集、验证集和测试集,每个文件下有三个文件,有对话信息、情感信息和行为解释信息。
数据集二、MELD
论文《MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation》。
MELD是从电影老友记上摘取的片段。是一个多模态数据集,既包括文本信息,也包括与文本对应的音频和视频信息。MELD有超过1400对对话,总共13000句。其包含7种情感,分别是 Anger, Disgust, Sadness, Joy, Neutral, Surprise and Fear。对每句话还有情绪注释(positive、negative和neutral)。
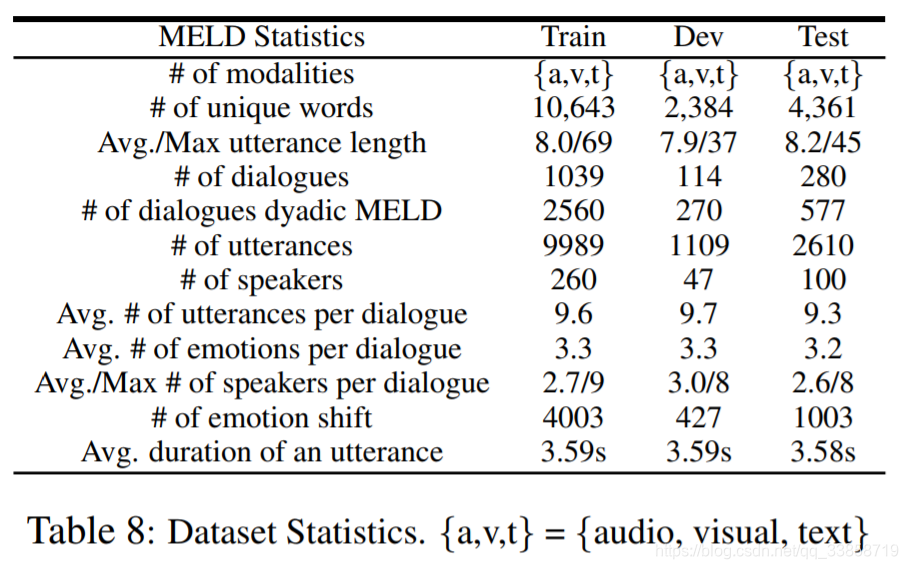
该数据集文本信息里面包含三种文件:train_sent_emo.csv、dev_sent_emo.csv和test_sent_emo.csv。每个csv文件里包含的信息有No.,Utterance,Speaker,Emotion,Sentiment,Dialogue_ID,Utterance_ID,Season,Episode,StartTime,EndTime,用逗号隔开。