部署kafka
为了防止收集的日志信息太多或者是服务器down机导致的信息丢失,我们这里引入kafka消息队列服务器,我们这里搭建单节点的kafka,生产环境中应该使用集群方式部署。部署过程参考kafka文档
部署jdk
由于zookeeper依赖java环境,所以我们需要安装jdk,官网建议最低安装jdk 1.8版本
上传软件包
[root@kafka01 ~]# ls

解压jdk
[root@kafka01 ~]# tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/
配置JDK环境变量
[root@kafka01 ~]# vim /etc/profile #在文件最后加入一下行
JAVA_HOME=/usr/local/jdk1.8.0_171
PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=$JAVA_HOME/jre/lib/ext:$JAVA_HOME/lib/tools.jar
export PATH JAVA_HOME CLASSPATH
[root@kafka01 ~]# source /etc/profile #使环境变量生效
查看java环境
[root@kafka01 ~]# java -version
安装zookeeper
配置hosts
[root@kafka01 ~]# vim /etc/hosts
192.168.10.6 kafka01解压安装装包
[root@kafka01 ~]# tar -zxf apache-zookeeper-3.5.5-bin.tar.gz -C /usr/local/
创建快照日志存放目录:
[root@kafka01 ~]# mkdir -p /data/zk/data
创建事务日志存放目录:
[root@kafka01 ~]# mkdir -p /data/zk/datalog
生成配置文件
[root@kafka01 ~]# cd /usr/local/apache-zookeeper-3.5.5-bin/conf/
[root@elk01 conf]# cp zoo_sample.cfg zoo.cfg #复制一份zoo_sample.cfg文件并命名为zoo.cfg
修改主配置文件zoo.cfg
[root@kafka01 ~]# vim zoo.cfg
dataDir=/data/zk/data #修改这一行为我们创建的目录
dataLogDir=/data/zk/datalog #添加这一行添加path环境变量
这里必须是修改配置文件添加path环境变量,不然启动报错
[root@kafka01 ~]# vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/apache-zookeeper-3.5.5-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH
[root@elk01 ~]# source /etc/profile
启动Zookeeper
[root@kafka01 conf]# zkServer.sh start

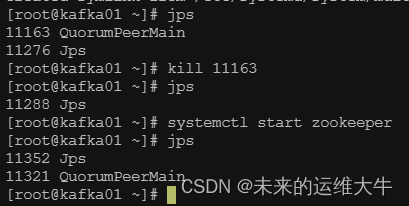
验证
[root@kafka01 ~]# zkServer.sh status

或者执行jps查看状态,其中QuorumPeerMain是zookeeper进程,启动正常
[root@kafka01 bin]# jps -m

查看zookeeper服务输出信息,其日志信息文件在
/usr/local/apache-zookeeper-3.5.5-bin/logs/zookeeper-root-server-kafka01.out
添加开机启动
将Zookeeper添加到开机自启服务
在/lib/systemd/system/文件夹下创建一个启动脚本zookeeper.service
[root@kafka01 ~]# vim /lib/systemd/system/zookeeper.service
[Unit]
Description=Zookeeper service
After=network.target
[Service]
Type=forking
Environment="JAVA_HOME=/usr/local/jdk1.8.0_171"
User=root
Group=root
ExecStart=/usr/local/apache-zookeeper-3.5.5-bin/bin/zkServer.sh start
ExecStop=/usr/local/apache-zookeeper-3.5.5-bin/bin/zkServer.sh stop
[Install]
WantedBy=multi-user.target
[root@kafka01 ~]# systemctl daemon-reload
[root@kafka01 ~]# systemctl enable zookeeper
测试:
Kafka 单节点单Broker部署
这里部署的是kafka单节点,生产环境应该部署kafka多节点集群。
解压软件到指定目录
[root@kafka01 ~]# tar -zxvf kafka_2.12-2.2.0.tgz -C /usr/local/
修改配置文件
[root@kafka01 ~]# vim /usr/local/kafka_2.12-2.2.0/config/server.properties
# broker的全局唯一编号,不能重复
broker.id=0
# 监听
listeners=PLAINTEXT://:9092 #开启此项
# 日志目录
log.dirs=/data/kafka/log #修改日志目录
# 配置zookeeper的连接(如果不是本机,需要该为ip或主机名)
zookeeper.connect=localhost:2181
创建日志目录
[root@kafka01 ~]# mkdir -p /data/kafka/log
添加path环境变量
[root@kafka01 ~]# vim /etc/profile #文件最后添以下行
export KAFKA_HOME=/usr/local/kafka_2.12-2.2.0
export PATH=$KAFKA_HOME/bin:$PATH
[root@kafka01 ~]# source /etc/profile #生效配置文件
启动kafka
后台启动kafka
[root@kafka01 ~]# kafka-server-start.sh -daemon /usr/local/kafka_2.12-2.2.0/config/server.properties
添加开机自启动
将kafka添加到开机自启服务
在/lib/systemd/system/文件夹下创建一个启动脚本kafka.service
[root@kafka01 ~]# vim /lib/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (broker)
After=network.target zookeeper.service
[Service]
Type=simple
Environment="PATH=/usr/local/jdk1.8.0_171/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin"
User=root
Group=root
ExecStart=/usr/local/kafka_2.12-2.2.0/bin/kafka-server-start.sh /usr/local/kafka_2.12-2.2.0/config/server.properties
ExecStop=/usr/local/kafka_2.12-2.2.0/bin/kafka-server-stop.sh
Restart=on-failure
[Install]
WantedBy=multi-user.target
[root@kafka01 ~]# systemctl daemon-reload
[root@kafka01 ~]# systemctl enable kafka
测试
设置filebeat
修改filebeat.yml配置文件
我们这里修改filebeat配置文件,把filebeat收集到的nginx日志保存到kafka消息队列中。把output.elasticsearch和output.logstash都给注释掉,添加kafka项。
[root@filebeat01 ~]# vim /usr/local/filebeat/filebeat.yml
enabled: true #开启此配置
paths:
- /usr/local/nginx/logs/*.log #添加收集nginx服务日志
#- /var/log/*.log #注释该行
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch: # Elasticsearch这部分全部注释掉
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
#----------------------------- Logstash output --------------------------------
#output.logstash: # logstash这部分全部注释掉
# The Logstash hosts
#hosts: ["192.168.10.4:5044"]
#在Logstash后面添加如下行
#----------------------------- KAFKA output --------------------------------
output.kafka: #把日志发送给kafka
enabled: true #开启kafka模块
hosts: ["192.168.10.6:9092"] #填写kafka服务器地址
topic: nginx_logs #填写kafka的topic(主题),自定义的
#logging.level: warning #调整日志级别
把output.elasticsearch和output.logstash都给注释掉,然后在output.logstash结尾添加KAFKA output,把日志数据发送给kafka。需要注意的是kafka中如果不存在这个topic,则会自动创建。如果有多个kafka服务器,可用逗号分隔。
[root@filebeat01 ~]# vim /etc/hosts
192.168.10.5 filebeat01
192.168.10.6 kafka01这里需要添加kafka的hosts解析,如果不添加会报如下错误:
重启filebeat
[root@filebeat01 ~]# ps -ef | grep filebeat

[root@filebeat01 ~]#kill 16732
[root@filebeat01 ~]# cd /usr/local/filebeat/ && ./filebeat -e -c filebeat.yml & #刷新nginx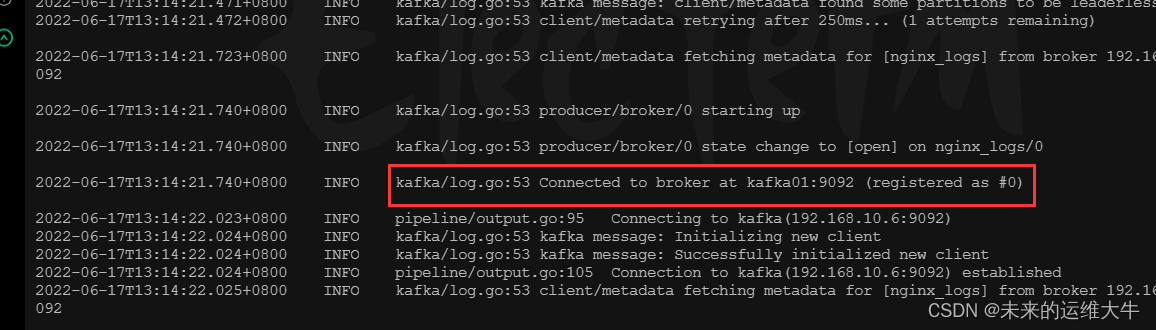
查看kafka上所有的topic信息
在kafka服务器上查看filebeat保存的数据,topice为nginx_logs
[root@kafka01 ~]# kafka-topics.sh --list --zookeeper localhost:2181
![]()
启动一个消费者获取信息
[root@kafka01 ~]# kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic nginx_logs --from-beginning

启动一个消费者去查看filebeat发送过来的消息,能看到消息说明我们的filebeat的output.kafka配置成功。接下来配置logstash去kafka消费数据。
配置logstash
配置logstash去kafka拿取数据,进行数据格式化,然后把格式化的数据保存到Elasticsearch,通过kibana展示给用户。kibana是通过Elasticsearch进行日志搜索的。
filebeat中message要么是一段字符串,要么在日志生成的时候拼接成json,然后在filebeat中指定为json。但是大部分系统日志无法去修改日志格式,filebeat则无法通过正则去匹配出对应的field,这时需要结合logstash的grok来过滤。
添加hosts解析
[root@elk01 ~]# vim /etc/hosts
192.168.10.4 elk01
192.168.10.5 filebeat01
192.168.10.6 kafka01修改logstash配置文件
[root@elk01 ~]# vim /usr/local/logstash-7.3.0/config/http_logstash.conf
input{
kafka {
codec => plain{charset => "UTF-8"}
bootstrap_servers => "192.168.10.6:9092"
client_id => "httpd_logs" #这里设置client.id和group.id是为了做标识
group_id => "httpd_logs"
consumer_threads => 5 #设置消费kafka数据时开启的线程数,一个partition对应一个消费者消费,设置多了不影响,在kafka中一个进程对应一个线程
auto_offset_reset => "latest" #从最新的偏移量开始消费
decorate_events => true #此属性会将当前topic,offset,group,partition等信息>也带到message中
topics => "nginx_logs"
}
}
output {
stdout {
codec => "rubydebug"
}
elasticsearch {
hosts => [ "192.168.10.4:9200" ]
index => "nginx-logs-%{+YYYY.MM.dd}"
}
}
可以使用相同的group_id方式运行多个Logstash实例,以跨物理机分布负载。主题中的消息将分发到具有相同的所有Logstash实例group_id。
Kafka input参数详解:
Kafka input plugin | Logstash Reference [8.2] | Elastic
重启logstash

刷新httpd服务
刷新nginx页面。产生数据
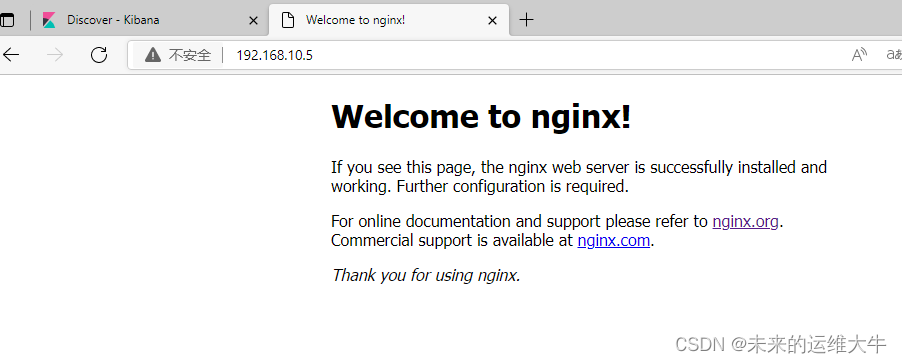
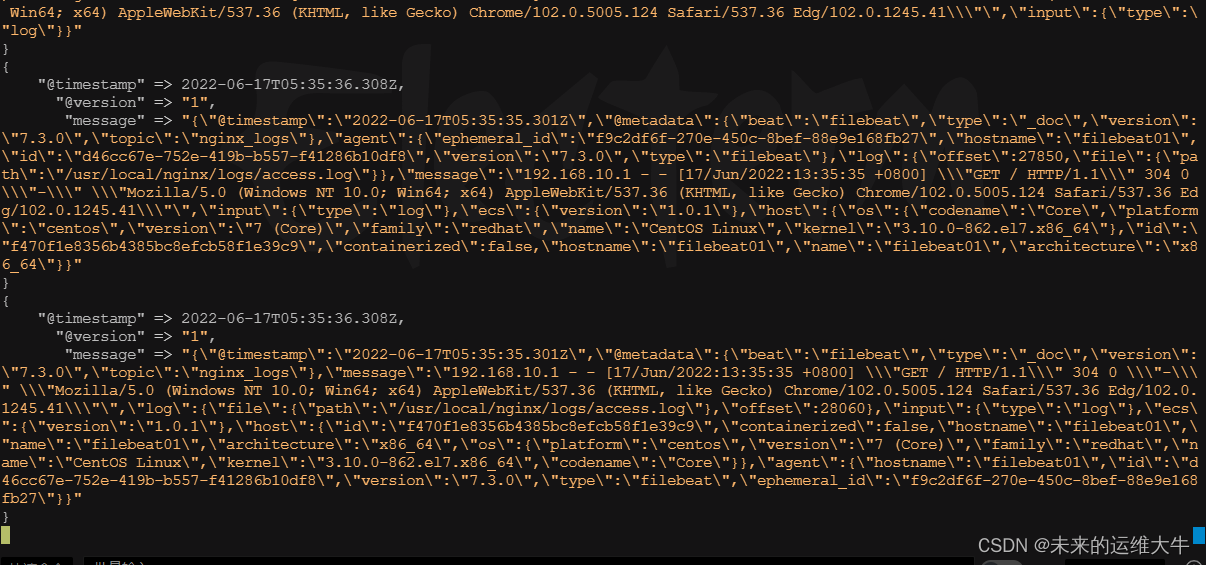
查看logstash显示数据
在kibana上查看数据
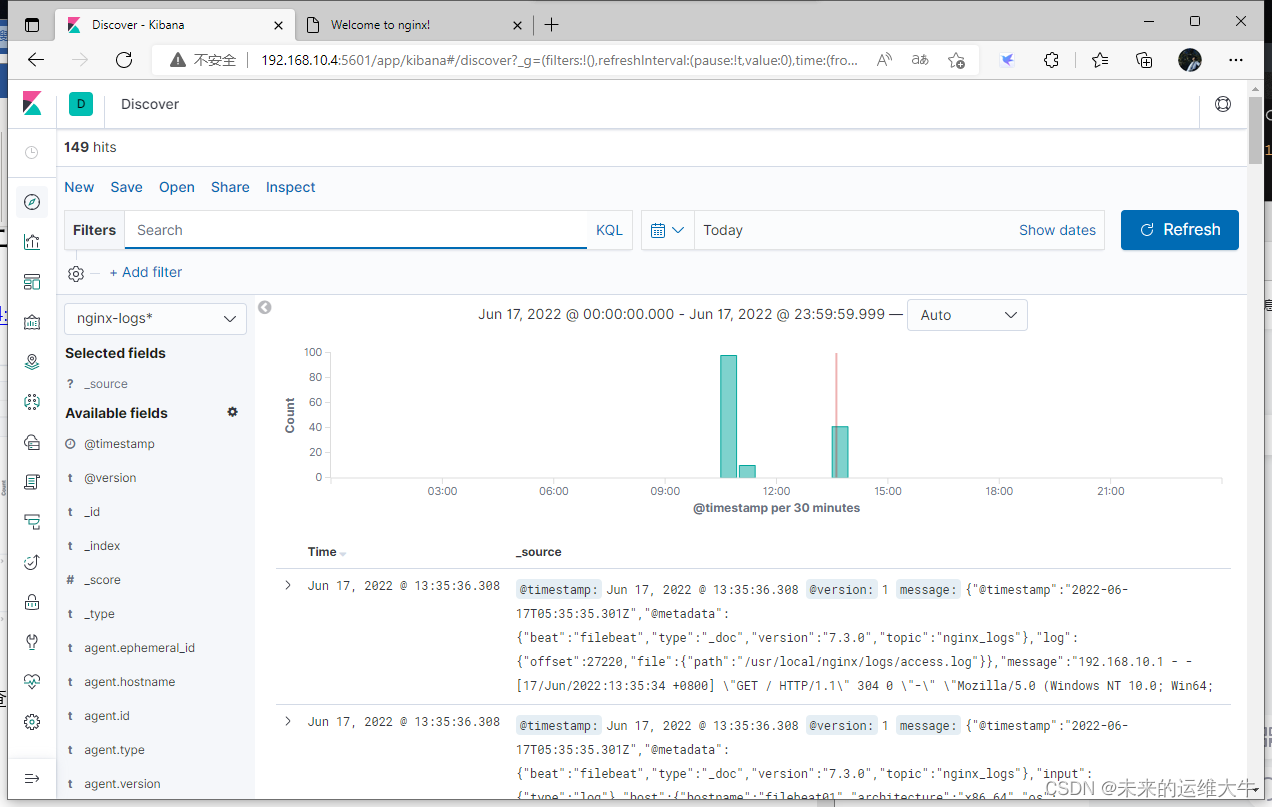
可以在kibana上查看我们最新收集到的nginx服务日志。到这里我们的ELK+filebeat+kafka部署完成。