有用的爬虫实战教程不多,本人学习和开发实为不易,转载还请注明出处。
系列文章:
Python爬虫实践(二) -- 爬虫进阶:爬取数据处理、数据库存储
Python爬虫实践(三) -- 用户全量数据爬取、多媒体信息爬取
Selenium爬虫 -- 图片视频的src绝对地址链接分析
Selenium爬虫 -- WebDriver多标签页创建与切换
使用Selenium爬取数据时,网页切换之后原先获取的元素变量失效的问题
Python爬取图片时,urllib提示没有属性urlretrieve的问题
最终可运行代码已上传:
目录
实现目标
在前一篇博客Python爬虫实践(一) -- 社交网站用户信息爬取中,描述的要求的基础上,将用户的所有信息爬取下来,并按约束与数据类型存入关系型数据库MySQL。
知识基础
Selenium学习
在前一篇博客中最终决定使用的便是Selenium包,这次仅做概述。
开发包的API的详细使用可以看这篇博客,写的很详细。【Selenium学习】WebDriverApi接口和二次开发
元素定位(XPath):selenium提供了八种元素定位:id、name、class、tag、link、patail_link、xpath、css。
xpath定位基本上可以解决80%的元素定位问题,但是比较笨重,定位元素慢,语法很长,还不稳定;辅助定位工具:xpath helper、firepath、firebug。
css:定位速度快,稳准狠,轻巧,语法简洁。有些模糊匹配的地方,还是得靠xpath来搞定。
html:网页结构,各种标签。
操作元素:定位好元素之后接下来就是操作元素了,主要有困难的是鼠标事件和键盘事件
判断元素:操作完后,就是获取返回结果了,或者是判断元素是不是期望结果
测试报告:用例执行完之后,需要用到html的测试报告
发送邮件:自动发送测试报告,要自动发报告,学习smtplib模块吧,它能让你的报告以邮件的形式发送到任何人的手中。
js:很多selenium无法完成的场景,比如浏览器的滚动条,这时候需要学js
Scrapy学习
安装scrapy:直接使用pip命令。
pip install Scrapy
新建scrapy工程:在控制台模式下进入你要建立工程的文件夹执行如下命令创建工程,这里的hellospider是工程名,框架会自动在当前目录下创建一个同名的文件夹,工程文件就在里边。
scrapy startproject hellospider
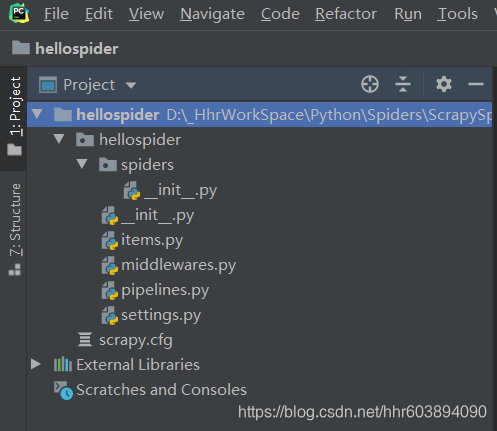
目录结构:
scrapy.cfg: 项目的配置文件
hellospider/: 该项目的python模块。之后您将在此加入代码。
hellospider/items.py:需要提取的数据结构定义文件。
hellospider/middlewares.py: 是和Scrapy的请求/响应处理相关联的框架。
hellospider/pipelines.py: 用来对items里面提取的数据做进一步处理,如保存等。
hellospider/settings.py: 项目的配置文件。
hellospider/spiders/: 放置spider代码的目录。
在items.py中定义自己要抓取的数据:类中的title、author、reply就像是字典中的“键”,爬到的数据就像似字典中的“值”。
import scrapy
class DetailItem(scrapy.Item):
# 抓取内容:1.帖子标题;2.帖子作者;3.帖子回复数
title = scrapy.Field()
author = scrapy.Field()
reply = scrapy.Field()然后在spiders目录下新建和编辑myspider.py文件: 这是具体的爬虫逻辑程序。
import scrapy
import sys
from hellospider.items import DetailItem
class MySpider(scrapy.Spider):
"""
name:scrapy唯一定位实例的属性,必须唯一
allowed_domains:允许爬取的域名列表,不设置表示允许爬取所有
start_urls:起始爬取列表
start_requests:它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入
我们自定义的规律的链接
parse:回调函数,处理response并返回处理后的数据和需要跟进的url
log:打印日志信息
closed:关闭spider
"""
# 设置name
name = "spidertieba"
# 设定域名
allowed_domains = ["baidu.com"]
# 填写爬取地址
start_urls = [
"http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=utf-8",
]
# 编写爬取方法
def parse(self, response):
for line in response.xpath('//li[@class=" j_thread_list clearfix"]'):
# 初始化item对象保存爬取的信息
item = DetailItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
item['title'] = line.xpath('.//div[contains(@class,"threadlist_title pull_left j_th_tit ")]/a/text()').extract()
item['author'] = line.xpath('.//div[contains(@class,"threadlist_author pull_right")]//span[contains(@class,"frs-author-name-wrap")]/a/text()').extract()
item['reply'] = line.xpath('.//div[contains(@class,"col2_left j_threadlist_li_left")]/span/text()').extract()
yield item可以通过命令进入scrapy shell来方便的查看xpath代码所获得的结果,以便调试。
scrapy shell http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=utf-8仍在项目目录中,执行命令 scrapy crawl [类中name值]:由于第二步中我们在类MySpider下定义了 name ="spidertieba" ,所以执行命令:(若报错ModuleNotFoundError: No module named 'win32api',可以通过pip安装win32api解决,记得更新pip)
scrapy crawl [类中name的值] -o [要生成的文件名]
scrapy crawl spidertieba -o items.json
scrapy crawl spidertieba -o items.csv其中-o指定文件。这样我们就会看到此目录下生成了items.json文件。items.json文件的内容就是爬取的内容。
运行myspider.py文件,进行数据抓取。
到此就完成了示例的编写运行,接下来对其进行修改,使其符合爬取FB的要求。
实现自动翻页一般有两种方法:在页面中找到下一页的地址;自己根据URL的变化规律构造所有页面地址。一般情况下我们使用第一种方法,第二种方法适用于页面的下一页地址为JS加载的情况。
一个Request对象表示一个HTTP请求,它通常是在爬虫生成,并由下载执行,从而生成Response。
一个Response对象表示的HTTP响应,这通常是下载(由下载),并供给到爬虫进行处理。
使用FormRequest通过HTTP POST发送数据,如果你想在你的爬虫中模拟HTML表单POST并发送几个键值字段,你可以返回一个FormRequest对象(从你的爬虫)像这样:
return [FormRequest(url="http://www.example.com/post/action",
formdata={'name': 'John Doe', 'age': '27'},
callback=self.after_post)]
使用FormRequest.from_response()来模拟用户登录,网站通常通过元素(例如会话相关数据或认证令牌(用于登录页面))提供预填充的表单字段。进行剪贴时,您需要自动预填充这些字段,并且只覆盖其中的一些,例如用户名和密码。您可以使用 此作业的方法。这里有一个使用它的爬虫示例:
import scrapy
class LoginSpider(scrapy.Spider):
name = 'example.com'
start_urls = ['http://www.example.com/users/login.php']
def parse(self, response):
return scrapy.FormRequest.from_response(
response,
formdata={'username': 'john', 'password': 'secret'},
callback=self.after_login
)
def after_login(self, response):
# check login succeed before going on
if "authentication failed" in response.body:
self.logger.error("Login failed")
return
# continue scraping with authenticated session...Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
Xpath与Selector的使用:Scrapy入门教程
xpath语法可参考:http://www.w3school.com.cn/xpath/xpath_syntax.asp ,或使用xpath helper,这个Chorme浏览器的插件。学习xpath路径可以在Chorm中按F12或右键检查,然后右键元素标签,选择copy,完整的xpath或者xpath。
具体的XPath使用:比如在XPath Helper中查看某一元素(帖子标题)的query路径如下:
/html/body[@class='special_conf_skin']/div[@class='wrap1']/div[@class='wrap2']/div[@id='content']
/div[@id='pagelet_frs-base/pagelet/content']/div[@class='forum_content clearfix']
/div[@id='content_wrap']/div[@id='pagelet_frs-list/pagelet/content']/div[@id='pagelet_frs-list
/pagelet/thread']/div[@id='content_leftList']/div[@id='pagelet_frs-list/pagelet
/thread_list']/ul[@id='thread_list']/li[@class='j_thread_list clearfix'][6]/div[@class='t_con cleafix']/div[@class='col2_right j_threadlist_li_right ']
/div[@class='threadlist_lz clearfix'] #这里是需要的
/div[@class='threadlist_title pull_left j_th_tit ']/a #这里是需要的
[@class='j_th_tit'] #这里不用管则在爬虫中应这样写(技巧:找整个路径中的最后一个@class):
for line in response.xpath('//li[@class=" j_thread_list clearfix"]'):
# 初始化item对象保存爬取的信息
item = DetailItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
item['title'] = line.xpath(
'.//div[contains(@class,"threadlist_title pull_left j_th_tit ")]/a/text()').extract()
# contains检索标签 # /text()与extract()提取文字BeautifulSoup学习
单个索引爬取:
1、导入即将需要所有的库。
2、定义一个变量来保存目标网页的 url
3、利用 Python 的 urllib2 库获取上一步指定 url 的 HTML 源码。
4、将这个 page 变量的内容用 BeautifulSoup 格式化,就可以使用 BeautifulSoup 做进一步的处理。
5、现在我们获得了一个 soup 变量,它包含了这个页面的 HTML 源码。 这就是我们开始提取我们所需要的数据的准备工作。
6、接下来我们可以使用 BeautifulSoup 提供的 find() 方法来定位我们的数据,因为 Class 为 name 的标签在此页面上是唯一的,所以我们可以直接利用
7、一旦我们获取到标签,我们即可使用 text 方法来获取里面的内容:
多个索引爬取:
1、首先,修改 quote_page 为一个 URL 数组。
2、接着我们把数据提取码改成 for 循环,它将逐个处理这些 URL 并将所有数据以元组形式存储到变量 data 中。
3、另外,修改保存部分以逐行保存数据。
结论:
BeautifulSoup 非常简单,非常适合小规模的网页抓取。但是如果您有兴趣更大规模地抓取数据,您应该考虑使用这些其他备选方案:
Scrapy,一个强大的 Python 爬虫框架。
尝试将一些公共 API 整合到你的代码中。数据检索的效率远高于页面爬取。例如, 查看一下 Facebook Graph API,这将能帮你获取 Facebook 页面的隐藏数据。
当数据量过大的时候,考虑使用类似 MySQL 的数据库后端来存储你的数据。
Python与数据库学习
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb几乎相同。但目前pymysql支持python3.x,而MySQLdb不支持3.x版本。
pip install pymysql #安装pymysql
数据库表的插入操作:
import pymysql
# 创建mysql的连接
db= pymysql.connect(host = "localhost",
user = "root",
password = "*******",
db = "fbtest",
port = 3306)
# 使用cursor()方法获取操作游标
cur = db.cursor()
# 插入数据的语句
sql_insert01 = """insert into facebook_blog(fid,content,fu_id) values ('000000001', 'aaaaaaaaaaaa', '000000002')"""
fid = '000000002'
content = 'bbbbbbbbbb'
fu_id = '000000003'
sql_insert02 = "insert into facebook_blog(fid,content,fu_id) values ('%s','%s','%s')" % (fid,content,fu_id)
try:
#执行
#cur.execute(sql_insert01)
cur.execute(sql_insert02)
#提交
db.commit()
print("sucess")
except Exception as e:
#错误回滚
print("error")
print(e)
db.rollback()
finally:
#关闭
db.close()
SQL语句的形式(单个的\为换行标记):
"""INSERT INTO EMPLOYEE(FIRST_NAME,
LAST_NAME, AGE, SEX, INCOME)
VALUES ('Mac', 'Mohan', 20, 'M', 2000)""""INSERT INTO EMPLOYEE(FIRST_NAME, " \
"LAST_NAME, AGE, SEX, INCOME) " \
"VALUES (%s, %s, %s, %s, %s ) " \
% ('Mac', 'Mohan', 20, 'M', 2000)使用变量向SQL语句中传递参数(单个的\为换行标记):
user_id = "test123"
password = "password"
con.execute('insert into Login values(%s, %s)' % \
(user_id, password))自增ID设置与插入数据语句方法:
#就是把id的那列不写。
#手动指定需要插入的列,不插入自增长这个字段id的数据
insert into table (field1, field2, ...) values (value1, value2, ...)
#或者可以把id的值设为null或者0,这样MySQL会自己做处理
insert into table values (NULL, value1, value2, ...)cookie知识学习
在网站里, http 请求是无状态的,在首次与服务器连接并成功登陆后,服务器识别出登陆者是谁,但当第二次登陆时,服务器无法识别登陆者是谁。而使用cookie可以解决这个问题,在第一次登陆后服务器会返回一些 cookie 信息给浏览器,浏览器会将这些信息保存在本地,当第二次发送请求时,浏览器会同时将 cookie 信息也传给服务器,从而帮助浏览器辨别使用者身份。
cookie的格式——{'domain': '.facebook.com', 'expiry': 1594184261, 'httpOnly': False, 'name': 'wd', 'path': '/', 'sameSite': 'None', 'secure': True, 'value': '**********'}
爬虫设计
框架技术选择:
1、使用Scrapy框架,对FB的手机端界面(比PC端更好获取元素)进行抓取。
2、使用Selenium包,对FB的手机端或者PC端的信息进行爬取。
通用技术选择:
1、使用XPath定位元素,使用Chorme浏览器的XPath Helper辅助找到正确的XPath。
2、使用Selector或者BeautifulSoup解析页面内容。
3、使用pymysql包来实现数据在MySQL中的存储。
4、先做单个用户全量信息爬取,再做批量用户。
5、使用cookie来保持登录会话状态。
PS:看了几天Scrapy的教程和源码,由于能找到的开源代码根本没有注释,讲解也是模糊的一匹。还要学车和游泳课程,时间上不允许,所以最终还是选择用Selenium+XPath来开发。
代码实现
Cookies获取
使用代码获取和浏览器F12获取两种方式,但是代码获取时会自动生成dict格式。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
class MySpider(object):
def __init__(self):
print("==============================")
print(" Geting Cookies! ")
print("==============================")
# 选择浏览器
self.browser = webdriver.Chrome()
# 访问******网页 # 网络容易出错
self.browser.get('https://m.******.com/login/save-device/?login_source=login')
time.sleep(1)
# 输入模拟登陆的账户密码
self.browser.find_element_by_name('email').clear()
self.browser.find_element_by_name('email').send_keys('***********')
self.browser.find_element_by_name('pass').clear()
self.browser.find_element_by_name('pass').send_keys('***********')
time.sleep(1)
# 模拟点击登录按钮
self.browser.find_element_by_name('login').send_keys(Keys.ENTER)
# 获取cookies,且自动生成dict
cookies = self.browser.get_cookies()
print("cookies:")
print(cookies)
def main(self):
print("==============================")
if __name__ == '__main__':
spider = MySpider()
spider.main()
使用Cookies登陆
获取并添加之后,并不能如期登陆,暂时不用cookie登陆了。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
class MySpider(object):
def __init__(self):
print("==============================")
self.browser = webdriver.Chrome()
time.sleep(1)
cookies={'domain': '.*****.com', 'expiry': '*********', 'httpOnly': False, 'name': '_datr', 'path': '/', 'secure': True, 'value': '*********************'}
self.browser.get('https://m.*****.com')
self.browser.delete_all_cookies()
self.browser.add_cookie(cookie_dict=cookies)#或以列表加5个
print("cookie已加载")
self.browser.get('https://m.*******.com')
def main(self):
print("==============================")
if __name__ == '__main__':
spider = MySpider()
spider.main()
数据库表设计
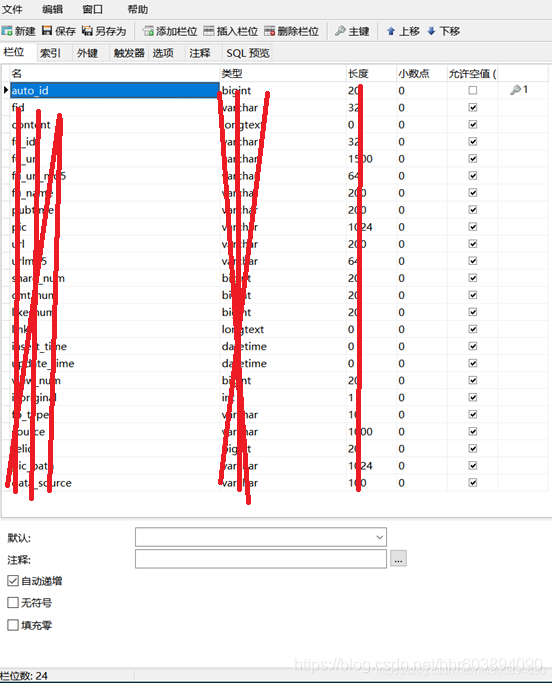
模拟登陆、元素定位、数据存储(最终版)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
import datetime
import hashlib
import pymysql
class MySpider(object):
def __init__(self):
print("===========开始,进入登陆状态===========")
self.browser = webdriver.Chrome()
self.browser.get('https://m.******.com/login/save-device/?login_source=login')
self.browser.find_element_by_name('email').clear()
self.browser.find_element_by_name('email').send_keys('************')
self.browser.find_element_by_name('pass').clear()
self.browser.find_element_by_name('pass').send_keys('************')
self.browser.find_element_by_name('login').send_keys(Keys.ENTER)
time.sleep(5)
print("===========登陆成功,由ID寻找用户主页===========")
uidN = '********'
self.browser.get('https://m.*****.com/profile.php?id=' + uidN)
#uidE = '********'
#self.browser.get('https://www.m.*****.com/' + uidE)
time.sleep(5)
print("===========开始抓取发帖数据===========")
db= pymysql.connect(host = "localhost",
user = "********",
password = "********",
db = "********",
port = 3306)
cur = db.cursor()
articles = self.browser.find_elements_by_xpath('//article[@class="_55wo _5rgr _5gh8 async_like"]')
for article in articles:
fid = article.find_element_by_xpath('./div/div/a').get_attribute('href')
print('发帖的站点ID值:' + fid)
content = article.find_element_by_xpath('./div/div/span/p').text
print('内容:' + content)
fu_id = article.find_element_by_xpath('./div/div/a').get_attribute('href')
print('用户的站点ID值:' + fu_id)
fu_url = 'https://m.facebook.com/profile.php?id=' + uidN
print('用户url链接:' + fu_url)
fu_url_md5 = hashlib.md5(fu_url.encode('utf-8')).hexdigest()
print('用户url链接的MD5值:' + fu_url_md5)
fu_name = article.find_element_by_xpath('./div/header/div/div/div/div/h3/strong/a').text
print('用户名称:' + fu_name)
pubtime = article.find_element_by_xpath('./div/header/div/div/div/div/div/a/abbr').text
print('发布时间:' + pubtime)
pic= ' '
print('图片链接:' + pic)
url = article.find_element_by_xpath('./div/div/a').get_attribute('href')
print('帖子url链接:' + url)
urlmd5 = hashlib.md5(url.encode('utf-8')).hexdigest()
print('帖子url链接的MD5值:' + url_md5)
share_num = article.find_element_by_xpath('./div/footer/div/div/div[2]/a').text
print('分享数:' + share_num)
cmt_num = article.find_element_by_xpath('./div/footer/div/div/a/div/div/span').text
print('评论数:' + cmt_num)
like_num = article.find_element_by_xpath('./div/footer/div/div/a/div/div/div').text
print('点赞数:' + like_num)
view_num = ' '
print('浏览数:' + view_num)
links = ''
print('帖子中的外链接:' + links)
insert_time = datetime.datetime.now().strftime("%Y-%m-%d%H:%M:%S")
print('数据库表记录插入时间:' + update_time)
update_time = datetime.datetime.now().strftime("%Y-%m-%d%H:%M:%S")
print('数据库表记录更新时间:' + insert_time)
isoriginal = 0
print('是否原创:' + isoriginal)
data_type = '文本'
print('信息类型:' + data_type)
source = "手机端"
print('网站来源:' + source)
relid = article.find_element_by_xpath('./div/div/a').get_attribute('href')
print('帖子的ID值:' + relid)
pic_path = ' '
print('保存图片的路径:' + pic_path)
print("===========存入一条数据库表记录===========")
sql_insert = "insert into facebook_blog(fid,content,fu_id,fu_url,fu_url_md5,fu_name,pubtime,pic,url,urlmd5,share_num,cmt_num,like_num,links,insert_time,update_time,view_num,isoriginal,type,source,relid,pic_path) values ('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % (fid,content,fu_id,fu_url,fu_url_md5,fu_name,pubtime,pic,url,urlmd5,share_num,cmt_num,like_num,links,insert_time,update_time,view_num,isoriginal,data_type,source,relid,pic_path)
try:
cur.execute(sql_insert)
db.commit()
print("sucess")
except Exception as e:
print("error")
print(e)
db.rollback()
db.close()
print("============数据存储完成============")
def main(self):
print("================结束================")
if __name__ == '__main__':
spider = MySpider()
spider.main()
测试中出现的问题与代码调试改进
针对最终版代码出现的各种问题,进行了改进与测试。
1、元素定位失败的问题
通过查找修改对应的XPath,以及在定位时加入找不到元素的异常处理,解决了找不到元素或者本来就不存在的元素的定位失败问题。
多个平行div可以在XPath中以div[2]等标号来区分。右键检查可以选择XPath查看。
2、Python异常处理时,全局变量的问题
捕捉异常可以使用try/except语句。try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。如果你不想在异常发生时结束你的程序,只需在try里捕获它。
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'name'异常
except <名字>,<数据>:
<语句> #如果引发了'name'异常,获得附加的数据
else:
<语句> #如果没有异常发生注意try块内的变量是不能被后面主程序使用来存入数据库的,需要在try外部先声明一下。
3、Python的字符串与数字变量连接的问题
比如print函数或者正常的字符串变量连接时,不能将一个字符串与int变量直接连接成字符串(JavaScript中就可以,很烦),需要用str函数将int变量转换一下再连接。
print('分享数:' + str(share_num)) #可以
print('分享数:' + share_num) #不可以4、时间格式与数据库存储问题
使用datetime的方法来定义格式和获取当前时间时,需要先引入datetime模块。
import datetime
insert_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print('数据库表记录插入时间:' + insert_time)数据库的存入需要非常严格的格式,变量名一定不能错。
5、字符串中子串的查找与特定子串的截取
string = 'abc123'
index = string.find('abc1') # index为0
index = string.find('123') # index为3
substr1 = string[0:3] # 截取012位置,前三个字符,abc6、 加入异常、全局变量和字符串连接处理的代码
cmt_num = 0
share_num = 0
try:
span1 = article.find_element_by_xpath('./footer/div/div/a/div/div[2]/span').text
except Exception:
print(Exception)
else:
if span1.find('次分享'):
share_num = span1[0:span1.find('次分享')]
else:
cmt_num = span1[0:span1.find('条评论')]
print('分享数:' + str(share_num))
print('评论数:' + str(cmt_num))参考文章:
https://www.cnblogs.com/wumingxiaoyao/p/6183101.html
https://www.cnblogs.com/gtea/p/12715818.html
https://zhuanlan.zhihu.com/p/24669128
https://zhuanlan.zhihu.com/p/24769534
https://zhuanlan.zhihu.com/p/25200262
https://www.jianshu.com/p/60eb6ed5b6b1
https://www.cnblogs.com/lifei01/p/10672378.html
https://learnku.com/python/t/22993/crawling-with-python-and-beautifulsoup
https://www.cnblogs.com/liuzhongchao/p/8315713.html
https://blog.csdn.net/qq_40244755/article/details/88827455
https://blog.csdn.net/u013977714/article/details/51771827
https://blog.csdn.net/wangzi11111111/article/details/79601860