数据集:https://paperswithcode.com/paper/celeba-spoof-large-scale-face-anti-spoofing
train num:499231, {‘live’: 162462, ‘photo’: 35547, ‘poster’: 31221, ‘A4’: 31776, ‘face_mask’: 33646, ‘upper_body_mask’: 30167, ‘region_mask’: 33285, ‘PC’: 31072, ‘Pad’: 33085, ‘phone’: 31527, ‘mask’: 40616, ‘cartoon’: 3400, ‘sketch’: 1427}
val num:67543, {‘live’: 19923, ‘photo’: 3600, ‘poster’: 5421, ‘A4’: 6083, ‘face_mask’: 4287, ‘upper_body_mask’: 6097, ‘region_mask’: 3530, ‘PC’: 6477, ‘Pad’: 3659, ‘phone’: 4483, ‘mask’: 3610, ‘cartoon’: 100, ‘sketch’: 273}
尝试的方案:
第一阶段:
1 tensorflow 基于mioblenetv2 fintun
准确率极低,没法看
2, tensorflow 基于mioblenetv2 fintun,增加傅立叶变换分支,指导模型训练。
踩坑记录:傅立叶变换在tensorflow2.+上支持不是很好,在数据处理模块加傅立叶变换后,图像矩阵一些增强操作没法做,便放弃在tensorflow上处理,将数据处理模块全部放到Numpy上处理,在线增加傅立叶变换分支,然后再map,再cache.
def build_dataset(self, ):
dataset = tf.data.Dataset.from_generator(self.data_generator,
output_types=(tf.float32, tf.float32,tf.float32),
output_shapes=(
[None, None, None],[None, None], 4))
print("Dataset built from generator: {}".format('test g_data'))
subdirs = np.sort(self.cfg['subdirs'])
if self.train:
cachefile = "train_"
else:
cachefile = "test_"
for subdir in subdirs:
cachefile = cachefile + str(subdir)
if self.cfg['use_cache']:
mkr(self.cfg["cache_dir"])
cache = self.cfg["cache_dir"] + cachefile
dataset = dataset.map(map_func=self.wrapped_complex_calulation,num_parallel_calls=None).cache(cache)
if self.shuffle:
dataset = dataset.shuffle(1024)
dataset = dataset.batch(self.cfg['batch_size'], drop_remainder=True)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
return dataset
数据处理全部放到self.data_generator里实现。
def data_generator(self, ):
for img_file, label_file in self.data_dict:
if not os.path.exists(img_file):
continue
image = cv2.imread(img_file)
loc_label,class_label=label_file[0:4],label_file[4:]
x1,y1,x2,y2=int(loc_label[0]),int(loc_label[1]),int(loc_label[2]),int(loc_label[3])
crop_img=image[y1:y2,x1:x2,:]
crop_img = cv2.resize(crop_img, (self.cfg['img_h'], self.cfg['img_w']))
ft_sample=self.generate_FT(crop_img)
fft_img = cv2.resize(ft_sample, (self.ft_width, self.ft_height))
class_label = np.array(class_label,dtype=np.float32)
crop_img = cv2.cvtColor(crop_img, cv2.COLOR_BGR2RGB)
crop_img=normalize(crop_img)
yield crop_img.astype(np.float32), fft_img.astype(np.float32),class_label.astype(np.float32)
3.根据相关活体检测论文结论,在傅立叶变换分支以及最后的活体分类器分支各自加了SE模块,在channal 维度上增加Attention机制。傅立叶变换分支使用MSE做损失函数。
4.celeba-spoof数据集类别太多,且区分度不大,便合并类别,将原来13类合并为4类。label: [“live”,“paper”,“Screen”,“mask”]
进过上述一通骚操作,最终效果:
每个类别的准确率为(准确率=预测正确的数目/预测出来的数目):
{‘live’: 0.6668, ‘paper’: 0.91, ‘Screen’: 0.877, ‘mask’: 0.99}
每个类别的召回率为(召回率=预测正确的数目/类别标签的数目):
{‘live’: 0.997, ‘paper’: 0.84, ‘Screen’: 0.63, ‘mask’: 0.728}
第二阶段:
1,经过上述失败经验,总结失败原因:
(1)公开的celeba-spoof数据集,数据集确实大,但数据难度较大,而且还有很多脏数据。
(2)静默活体检测,不同类别图像之间的差别不是很大,当作普通分类任务难度很大。
2解决:根据(1),自己采集一批数据集,再加上celeba-spoof清洗后的一批,对抗数据集不容易采集,基本上用的celeba-spoof。
根据(2),换新的训练策略,fintun别人训练好的模型,使用多尺度多模型结合策略。
(https://blog.csdn.net/uncle_ll/article/details/117668353)
训练过程:
(一)数据组成:
Live:7千+,数据来源:办公室摄像头采集,手机采集,talkline_d5_segment,网络公开数据集,买的那批;
paper:5千+,数据来源:手机拍打印出的照片100+,其他均celeba-spoof,
screen:5千+,数据集来源:手机拍照,mac拍照,平板拍照共2千+,剩下均celeba-spoof。
(二)训练过程
网络训练流程: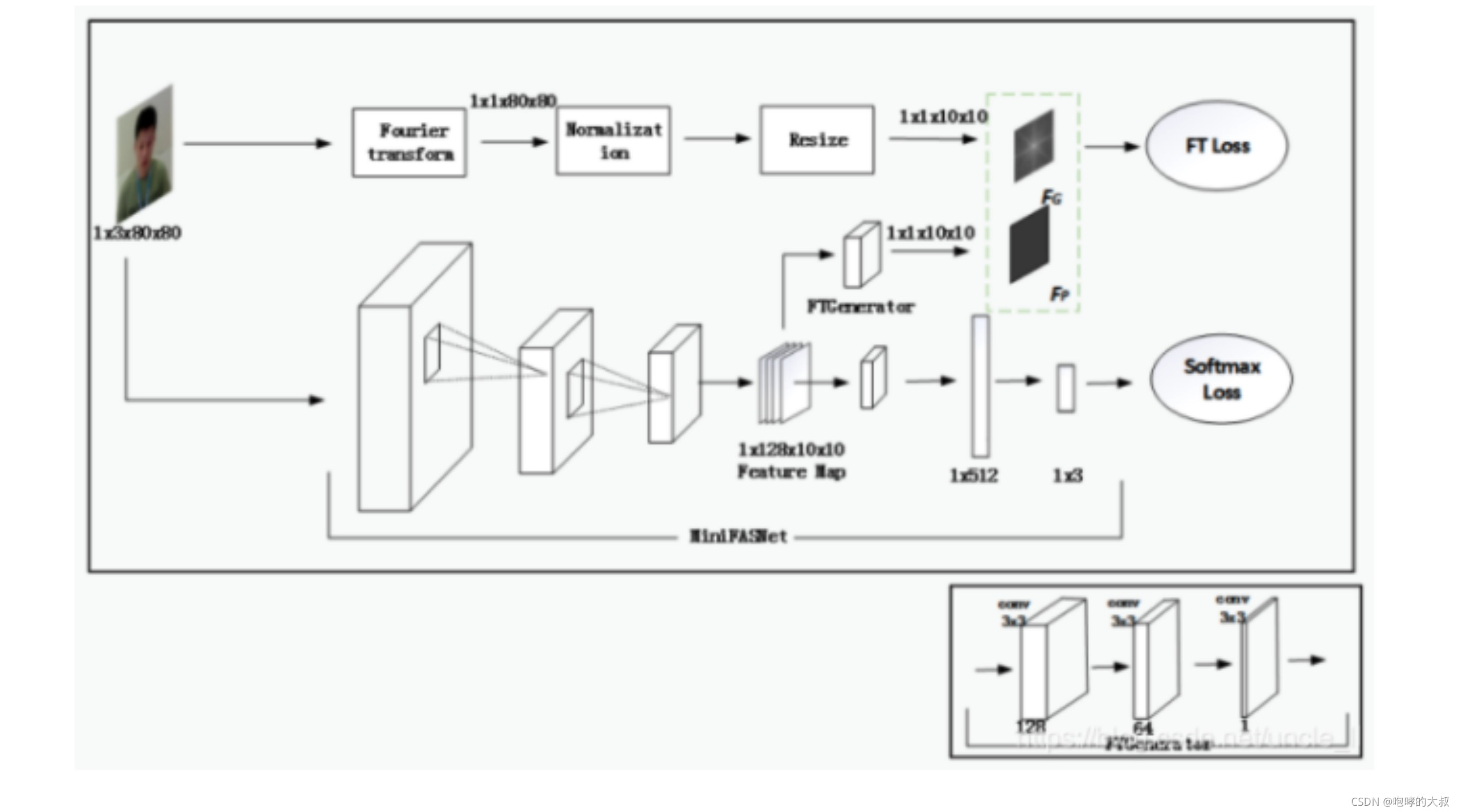
在网络中增加傅立叶变换分支指导训练,傅立叶变化对live和非live的结果呈现:
Live:
可以看出,live生成的傅立叶变换图像较为自然,三者相比,还是有细微差别,可以作为指导模型训练的先验知识。
在训练时,为了使网络更倾向学习傅立叶分支的差别,增大了傅立叶分支loss权重,好像并没有起多大作用。
loss = loss_cls + 50*loss_fea
虽然代码部分,支持MiniFASNetV2SE,MiniFASNetV1SE,MiniFASNetV2,
MiniFASNetV1四种网络的训练,但作者只公开了2.7_80x80_MiniFASNetV2.pth和4_0_0_80x80_MiniFASNetV1SE.pth两个预训练模型,所以后面我加载了这两个预训练模型,只训了MiniFASNetV2和MiniFASNetV1SE两个网络。
def _load_weights(self):
pre_dict = torch.load(self.premodel_path,map_location=self.device)
new_dict=self.model.state_dict()
pre_list = list(pre_dict.keys())
new_list = list(new_dict.keys())
minlen=min(len(pre_list),len(new_list))
for n in range(minlen):
if pre_dict[pre_list[n]].shape!=new_dict[new_list[n]].shape:
continue
new_dict[new_list[n]]=pre_dict[pre_list[n]]
self.model.load_state_dict(new_dict)
从代码看,MiniFASNetV1和MiniFASNetV2结构一样,只不过有些通道维度不同而已,MiniFASNetV1SE和MiniFASNetV2SE也是结构一样,有些通道维度不同,MiniFASNetV1与MiniFASNetV1SE之间的差别,MiniFASNetV1SE是将MiniFASNetV1残差模块替换成了SE模块。
# (80x80) flops: 0.044, params: 0.41
def MiniFASNetV1(embedding_size=128, conv6_kernel=(7, 7),
drop_p=0.2, num_classes=3, img_channel=3):
return MiniFASNet(keep_dict['1.8M'], embedding_size, conv6_kernel, drop_p, num_classes, img_channel)
# (80x80) flops: 0.044, params: 0.43
def MiniFASNetV2(embedding_size=128, conv6_kernel=(7, 7),
drop_p=0.2, num_classes=3, img_channel=3):
return MiniFASNet(keep_dict['1.8M_'], embedding_size, conv6_kernel, drop_p, num_classes, img_channel)
def MiniFASNetV1SE(embedding_size=128, conv6_kernel=(7, 7),
drop_p=0.75, num_classes=3, img_channel=3):
return MiniFASNetSE(keep_dict['1.8M'], embedding_size, conv6_kernel,drop_p, num_classes, img_channel)
# (80x80) flops: 0.044, params: 0.43
def MiniFASNetV2SE(embedding_size=128, conv6_kernel=(7, 7),
drop_p=0.75, num_classes=4, img_channel=3):
return MiniFASNetSE(keep_dict['1.8M_'], embedding_size, conv6_kernel,drop_p, num_classes, img_channel)
左为MiniFASNetV1结构图,右为MiniFASNetV1SE结构图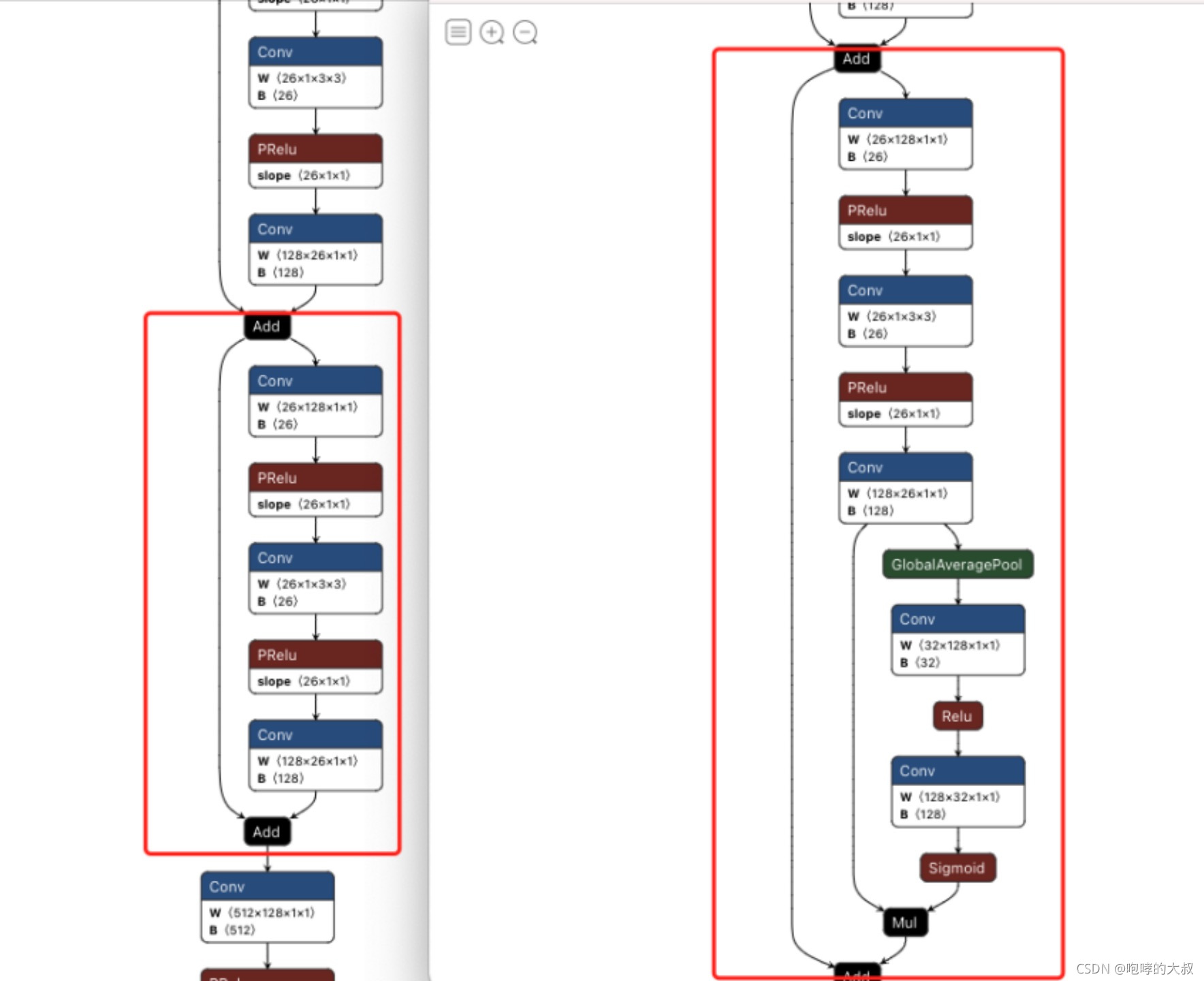
最后融合两个模型的结果作为最终预测结果。
prediction += model_test.predict(image, os.path.join(model_dir, model_name))
尝试80 * 80与128*128两组输入。效果差不太多,还是模型性能不够。
增强操作部分:1,随机裁剪,2,颜色亮度饱和度增强,3,随机旋转小角度,4,随机水平翻转(P默认0.5)
trans.RandomResizedCrop(size=tuple(conf.input_size),
scale=(0.9, 1.1)),
trans.ColorJitter(brightness=0.5,
contrast=0.5, saturation=0.5, hue=0.1),
trans.RandomRotation(10),
trans.RandomHorizontalFlip(),
loss部分:1,分类:多分类交叉熵,2,傅立叶分支:均方损失
self.cls_criterion = CrossEntropyLoss()
self.ft_criterion = MSELoss()
(三)实时测试
以128* 128输入结果分析:
MiniFASNetV2_35_128:MiniFASNetV2网络,3.5_org,128* 128输入,在验证集上的表现如下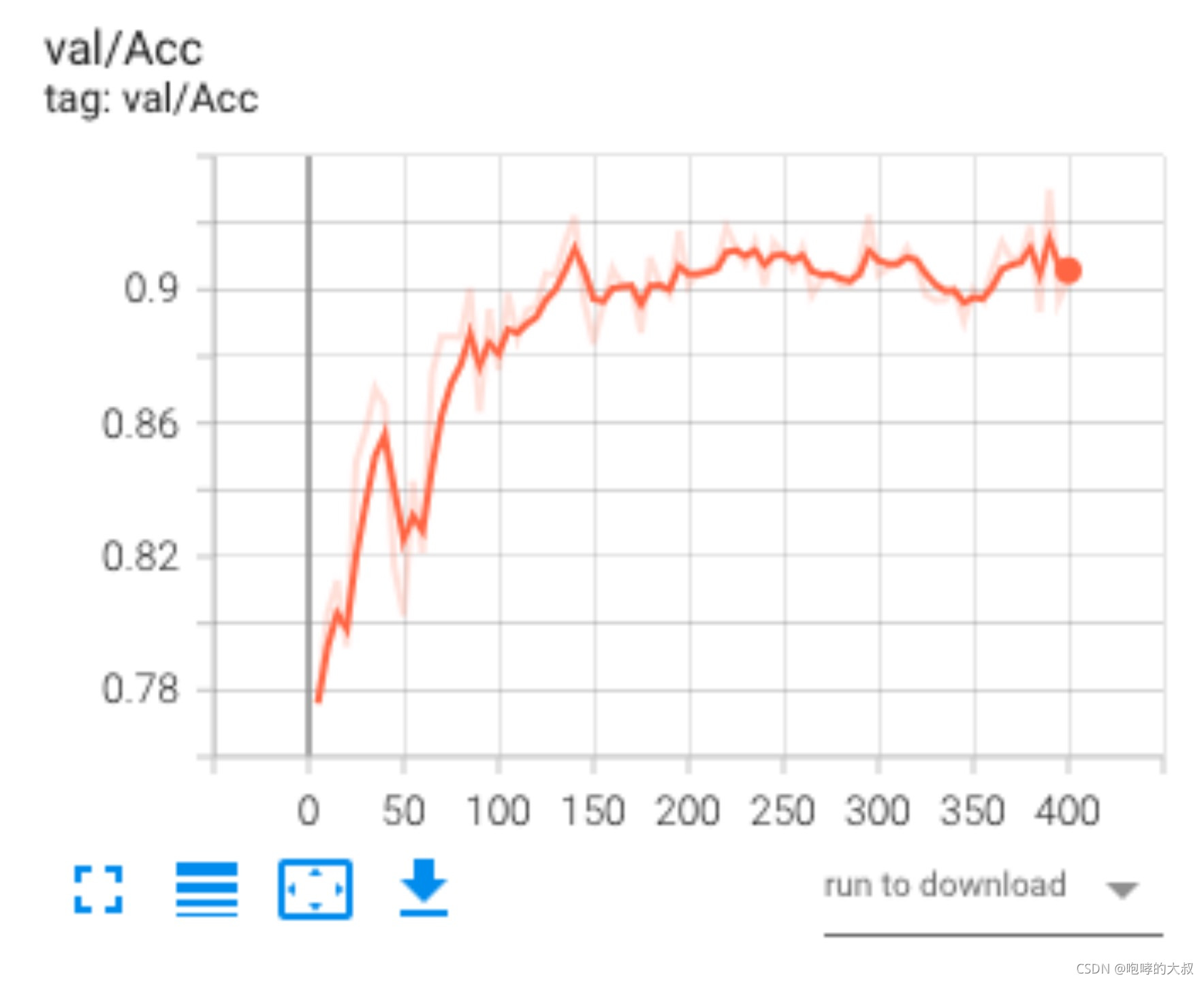
MiniFASNetV1SE_25_128: MiniFASNetV1SE网络,2.5_org, 128* 128输入,在验证集上的表现如下;

所以结合两个模型之后的结果,最终的准确率在89%左右。
实际接入摄像头的表现:在弱光或者强光,在有一定偏转角度的情况下,活体容易误判为欺诈图。
结论:活体检测,单纯靠训练模型实现难度较大,目前业界多用配合式,比如微信用的是不同颜色打光,看反射程度,支付宝是眨眼等,如果纯训,数据量至少百万级别。