pytorch 提供两种多GPU训练方案:nn.DataParallel 和 nn.DistributedDataParallel.
nn.DataParallel
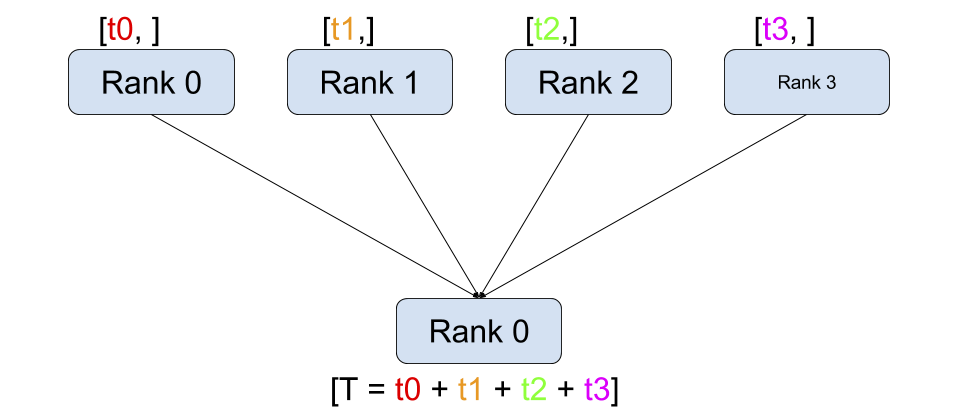
(支持单机多卡)很容易使用,但是速度慢(主要原因是它采用parameter server 模式,一张主卡作为reducer,负载不均衡,主卡成为训练瓶颈)
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
input_size = 5
output_size = 2
batch_size = 30
data_size = 100
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class RandomDataset(Dataset):
def __init__(self, size, length):
self.len = length
self.data = torch.randn(length, size)
def __getitem__(self, index):
return self.data[index]
def __len__(self):
return self.len
# dataloader
rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
batch_size=batch_size, shuffle=True)
class Model(nn.Module):
def __init__(self, input_size, output_size):
super(Model, self).__init__()
self.fc = nn.Linear(input_size, output_size)
def forward(self, input):
output = self.fc(input)
print("\tIn Model: input size", input.size(),
"output size", output.size())
return output
model = Model(input_size, output_size)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs
# 将batchsize 30 分配到N个GPU上运行
model = nn.DataParallel(model)
model.to(device)
for data in rand_loader:
input = data.to(device)
output = model(input)
print("Outside: input size", input.size(),
"output_size", output.size())nn.DistributedDataParallel
(支持单机多卡和多机多卡)采用All-reduce模式:
复制模型到多个GPU上,每个GPU通过一个进程来控制,进程之间互相通信,只有梯度信息是需要不同进程gpu之间通信,所有瓶颈限制没有那么严重。
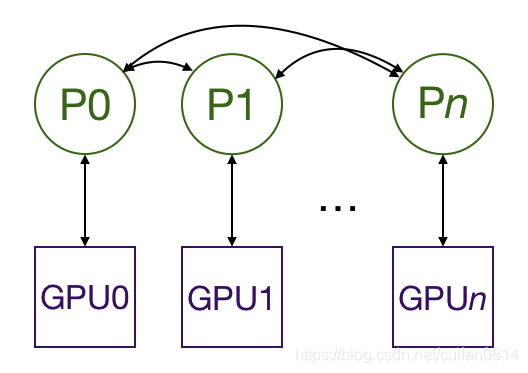
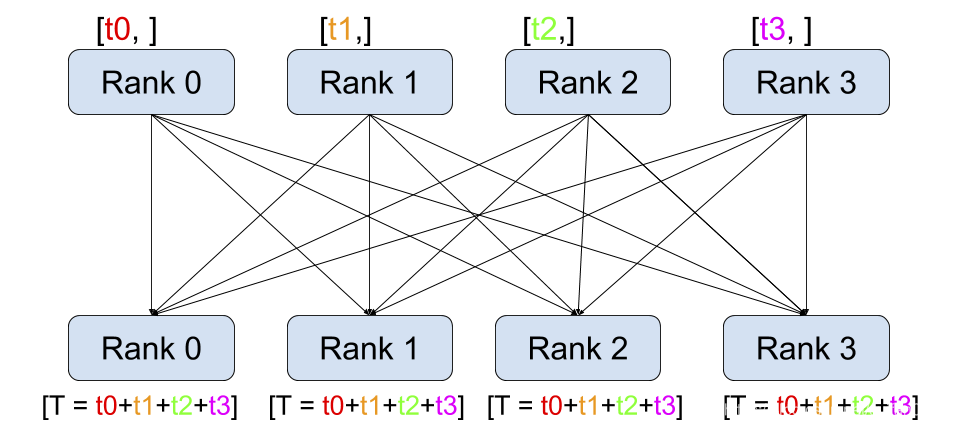
在训练时,每个进程/GPU load 自己的minibatch数据(所以要用distributedsampler), 每个GPU做自己独立的前向运算,反向传播时梯度all-reduce在各个GPU之间,各个节点得到平均梯度,保证各个GPU上的模型权重同步。 多进程之间同步信息通信是通过 distributed.init_process_group实现,找到主进程和总的进程数,总的进程数称为world_size。
一种方式是通过使用multiprocessing:
# 每个进程run一次train(i, args), i在(0 到 args.gpus-1)的范围。
def train(local_rank, args):
rank = args.nodes * args.gpus + local_rank #得到全局rank
# 初始化进程,join 其他进程,pytorch docs解释nccl 通讯后台 backend 是最快的。
# https://pytorch.org/docs/stable/distributed.html
dist.init_process_group(
backend='nccl',
init_method='env://',
world_size=args.world_size,
rank=rank
)
torch.manual_seed(0)#设置随机种子每个进程中,使得每个进程以同样的参数做初始化
model = model()
torch.cuda.set_device(gpu)
model.cuda(gpu)
batch_size = 100
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Wrap the model
model = nn.parallel.DistributedDataParallel(model,
device_ids=[gpu])
# Data loading code
train_dataset = xxx
#train_sampler 使得每个进程得到不同切分的数据
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=args.world_size,
rank=rank
)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=args.num_workers,
pin_memory=True,
sampler=train_sampler)
…
def main():
parser = argparse.ArgumentParser()
parser.add_argument('-n', '--nodes', default=1,
type=int, metavar='N')
parser.add_argument('-g', '--gpus', default=1, type=int,
help='number of gpus per node')
parser.add_argument('-nr', '--nr', default=0, type=int,
help='ranking within the nodes')
parser.add_argument('--epochs', default=2, type=int,
metavar='N',
help='number of total epochs to run’)
args = parser.parse_args()
args.world_size = args.gpus * args.nodes #
os.environ['MASTER_ADDR'] = ‘xx.xx.xx.xx' #
os.environ['MASTER_PORT'] = ‘xxxx' #
mp.spawn(train, nprocs=args.gpus, args=(args,)) #另一种方式使用torch.distributed.launch:
def main():
parser = argparse.ArgumentParser()
parser.add_argument(‘—-local_rank’, type=int, default=0)
dist.init_process_group(backend='nccl')
world_size = torch.distributed.get_world_size()
torch.manual_seed(0)
model = model()
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
model.cuda(args.local_rank)
batch_size = 100
criterion = nn.CrossEntropyLoss().cuda(gpu)
optimizer = torch.optim.SGD(model.parameters(), 1e-4)
# Wrap the model
model = nn.parallel.DistributedDataParallel(model,
device_ids[args.local_rank])
# Data loading code
train_dataset = xxx
#train_sampler 使得每个进程得到不同切分的数据
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=world_size,
rank=rank
)
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=args.num_workers,
pin_memory=True,
sampler=train_sampler)
# python -m torch.distributed.launch --nproc_per_node=2 main.py
参考: https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html
版权声明:本文为cuifan0814原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。