文章目录
(本文来自 VLDB2006 ,A Decade of Progress in Indexing and Mining Large Time Series Databases的翻译,PPT链接见文末,这里只翻译了一半)
1.什么是时间序列?
时间序列是一系列的观察点按照时间顺序排列的集合。
时间序列是无处不在的:
- 一个人的几个月以来的血压变化情况
- 某个明星的欢迎度评分变化趋势
- 某城市近几年的降雨量
- 某只股票的变化趋势
时间序列遍布在医疗、科技、金融等各个领域。
1.1 高维特征转成一维信号
我们可以把高维的形状转化为一维的信号,然后移除信号中的scale和offset,再送给我们的算法进行分析。

- 如文本类型的数据,我们也可以看作是时间序列来处理!
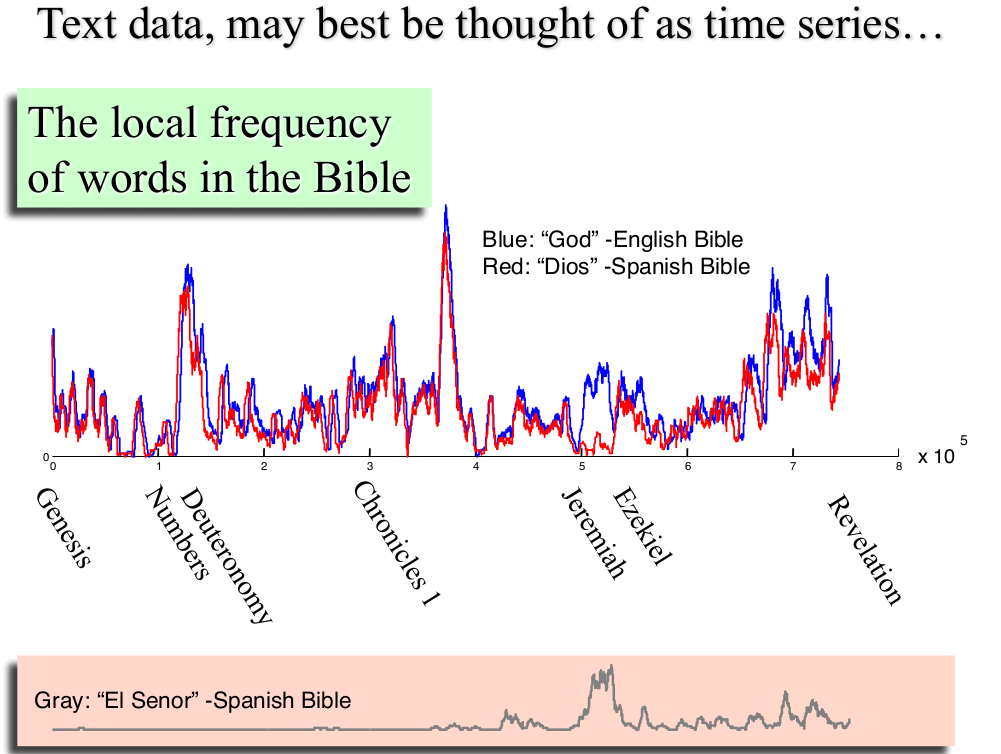
- 如视频类型的数据,我们也可以看作是时间序列来处理!
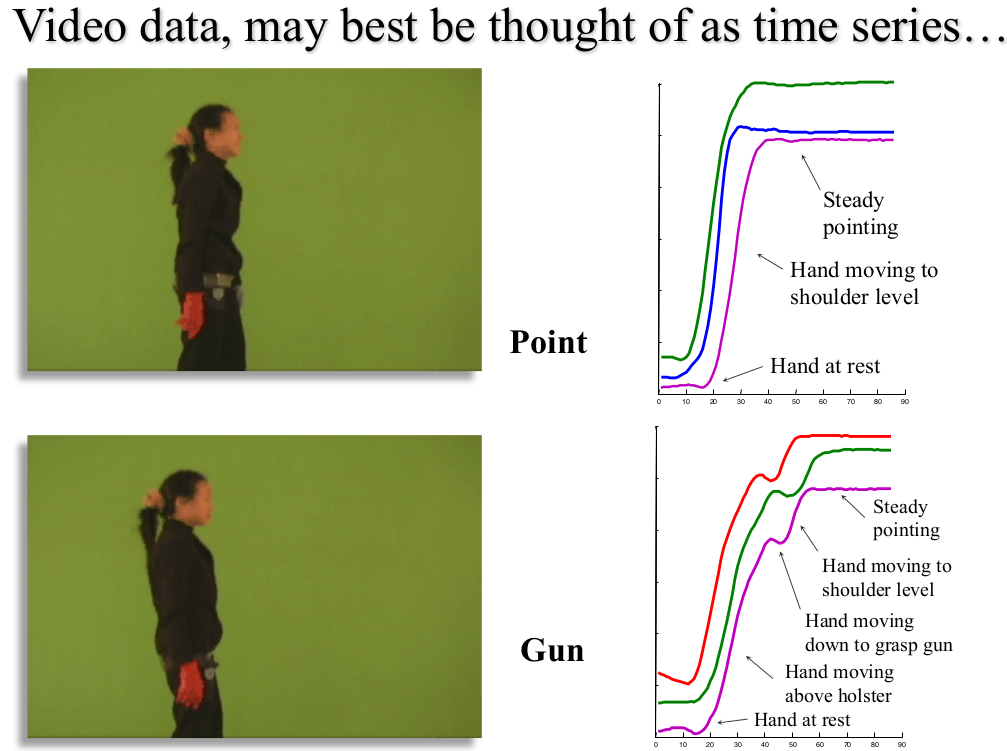
我们将视频中人物一系列的动作,分解成一个个的时间步骤,如射击过程,分解为:手向下 → \rightarrow→ 手抬起到皮套位置 → \rightarrow→ 手拿出枪 → \rightarrow→ 手移动至肩膀高度 → \rightarrow→ 稳定射击
类似地,还有手写体数据、3D模型等数据,也都适合看作为时间序列类型数据进行分析。
1.2 时间序列分析难在哪?
- 对于大型的时间序列数据难以分析。时间序列可以源源不断地产生,如一小时的心电图(EKG)数据,就有1个G的大小。大多数数据存储在硬盘里,我们需要一种时间序列的表示方法,将它们加载到内存中以便于操作和分析;
- 我们的分析,带有一定的主观性。对于不同用户、领域、任务来说,相似性的度量标准不尽相同,我们需要考虑这种主观性带来的影响;
- 时间序列自身的繁杂性(不同的数据格式、不同的采样比、噪音、缺失值等);
1.3 时间序列数据可以做哪些事情?
- 聚类
- 分类
- 主题发现
- 规则发现
- 按内容查找
- 可视化
- 异常检测
举一个时间序列应用的小例子
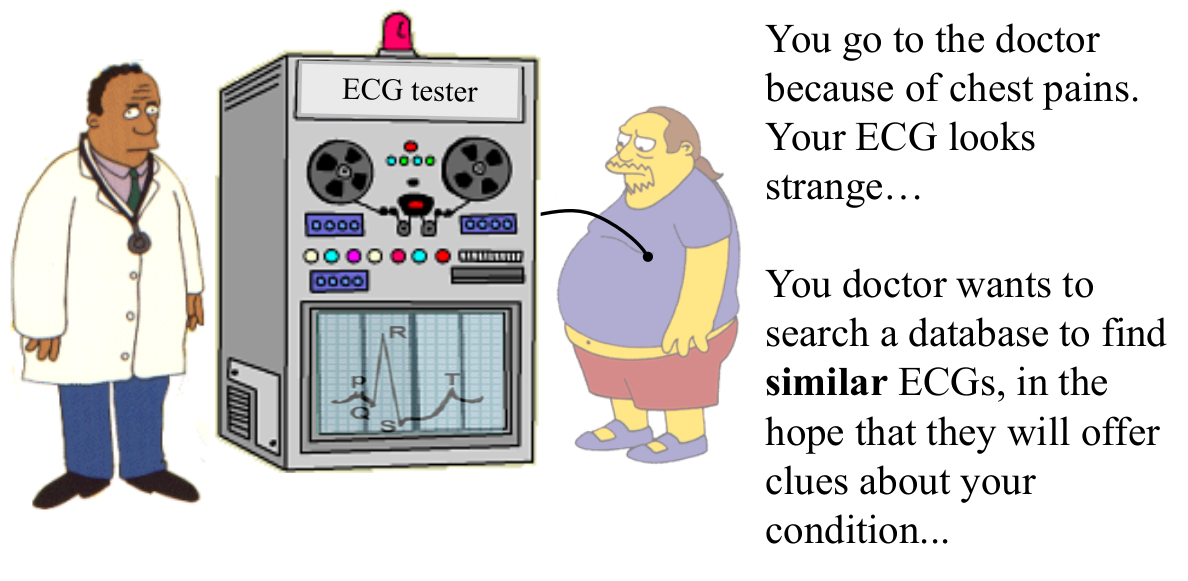
假如你因为胸口疼痛,去医院看医生,医生拍了你的心电图之后,发现不太正常,于是在医疗库中搜寻跟你心电图相似的案例,根据相似的案例,它可以得出你现在的健康状况的判断。
上面的这些功能的实现,都依赖于相似度匹配!那么,什么是相似度呢?
2.什么是相似度?

相似度很难定义,但是 W e    k n o w    i t    w h e n    w e    s e e    i t . We \;know \;it\; when\; we\; see\; it.Weknowitwhenweseeit.
2.1 我们下面针对不同类型的数据,对相似进行探讨。
- 文本类型的相似
- 单个词语层面上的相似
- 整体结构层面上的相似

- 单个词语层面上的相似
- 时间序列的相似
- 形状层面上的相似
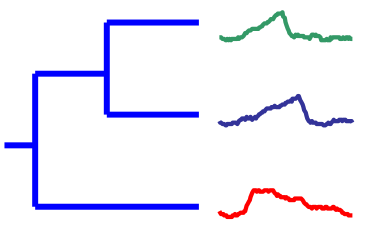
- 结构层面上的相似
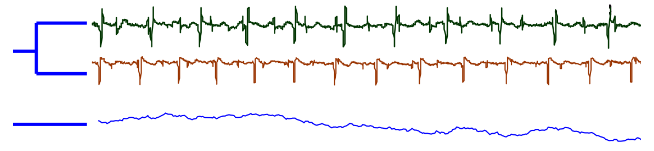
- 形状层面上的相似
2.2 定义距离度量标准
距离度量标准,必须满足以下四个特性:
- 对称性 D ( A , B ) = D ( B , A ) D(\mathrm{A}, \mathrm{B})=D(\mathrm{B}, \mathrm{A})D(A,B)=D(B,A)
- 恒定性 D ( A , A ) = 0 D(\mathrm{A}, \mathrm{A})=0D(A,A)=0
- 正值性 D ( A , B ) = 0    I I f    A = B D(\mathrm{A}, \mathrm{B})=0 \;\mathrm{IIf}\; \mathrm{A}=\mathrm{B}D(A,B)=0IIfA=B ,即如果AB不相等,那么距离一定大于零!
- 三角不等性 D ( A , B ) ≤ D ( A , C ) + D ( B , C ) D(\mathrm{A}, \mathrm{B}) \leq D(\mathrm{A}, \mathrm{C})+D(\mathrm{B}, \mathrm{C})D(A,B)≤D(A,C)+D(B,C)
三角不等性的作用是什么呢?
我们在图中有a,b,c三个点,已知a和b的距离为6.70,a和c的距离为7.07,b和c的距离为2.30,Q是观测点,我们想找到图中距离Q最近的点。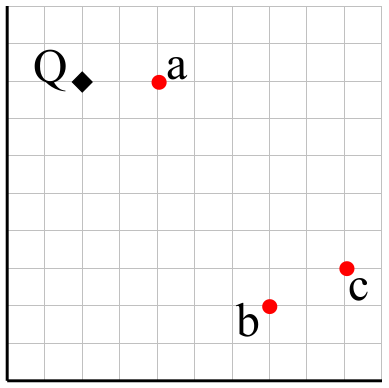
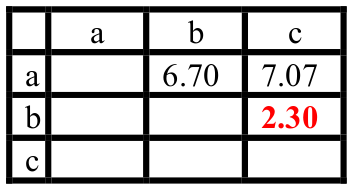
目前我们所知的是,Q到a点的距离为2,到b的距离为7.07,b和c的距离为2.30,那么我们就不需要计算Q到c点的距离了!因为:
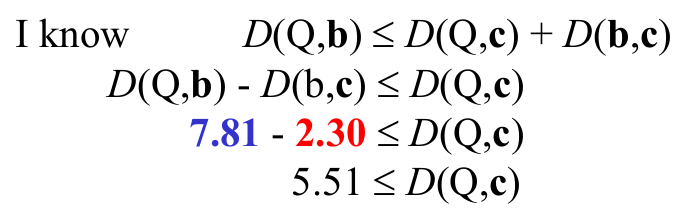
关于三角不等性的思考
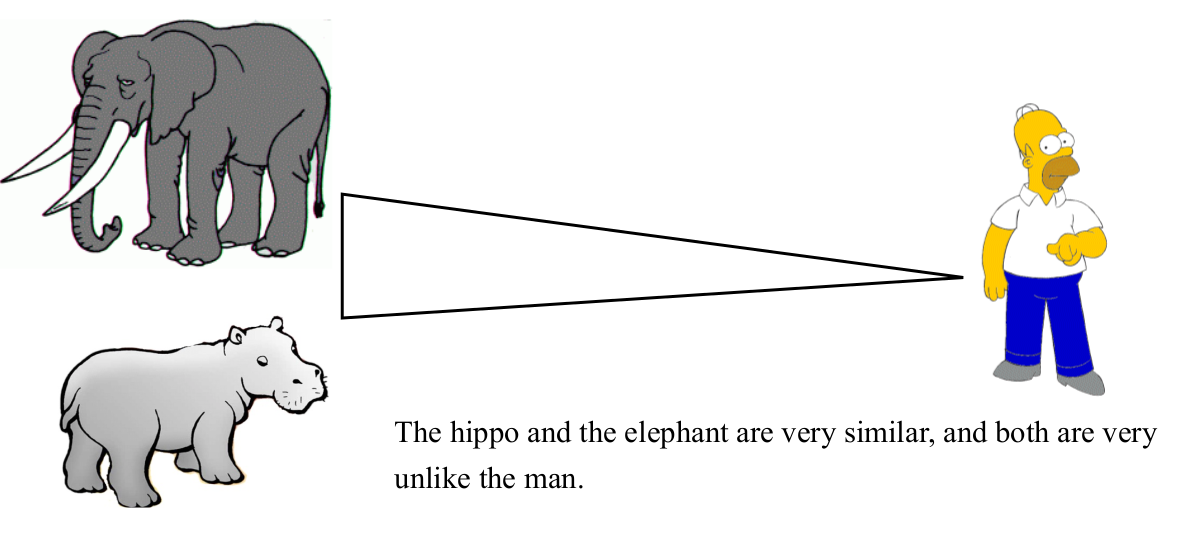
可以发现,图中满足三角不等性,D ( h i p p o , e l e p h a n t ) ≤ D ( h i p p o , m a n ) + D ( e l e p h a n t + m a n ) D(hippo,elephant)\leq D(hippo,man)+D(elephant+man)D(hippo,elephant)≤D(hippo,man)+D(elephant+man)
但是也有意外情况,如
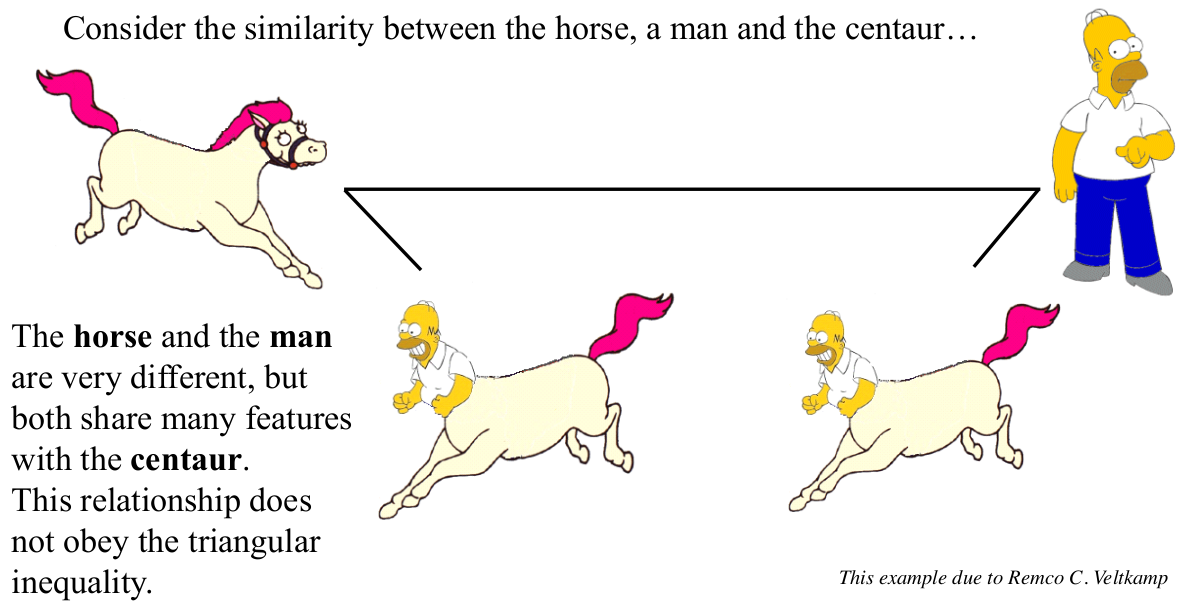
明显,D ( h o r s e , m a n ) ≥ D ( h o r s e , c e n t a u r ) + D ( m a n + c e n t a u r ) D(horse,man) \geq D(horse,centaur)+D(man+centaur)D(horse,man)≥D(horse,centaur)+D(man+centaur)
2.3 欧式距离度量
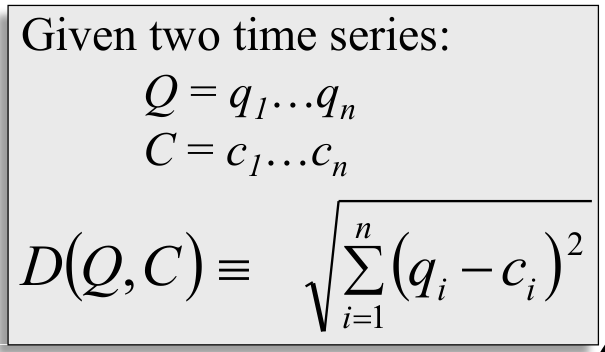
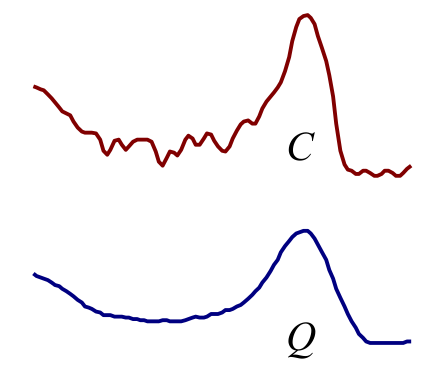
如果我们直接计算两条时间序列的欧氏距离,那么我们很有可能得到非常不理想的结果。因为欧氏距离对于信息中存在的异常是非常敏感的,所以我们在计算之前,一定要先消除这些异常!
- Offset Translation(偏移转换)
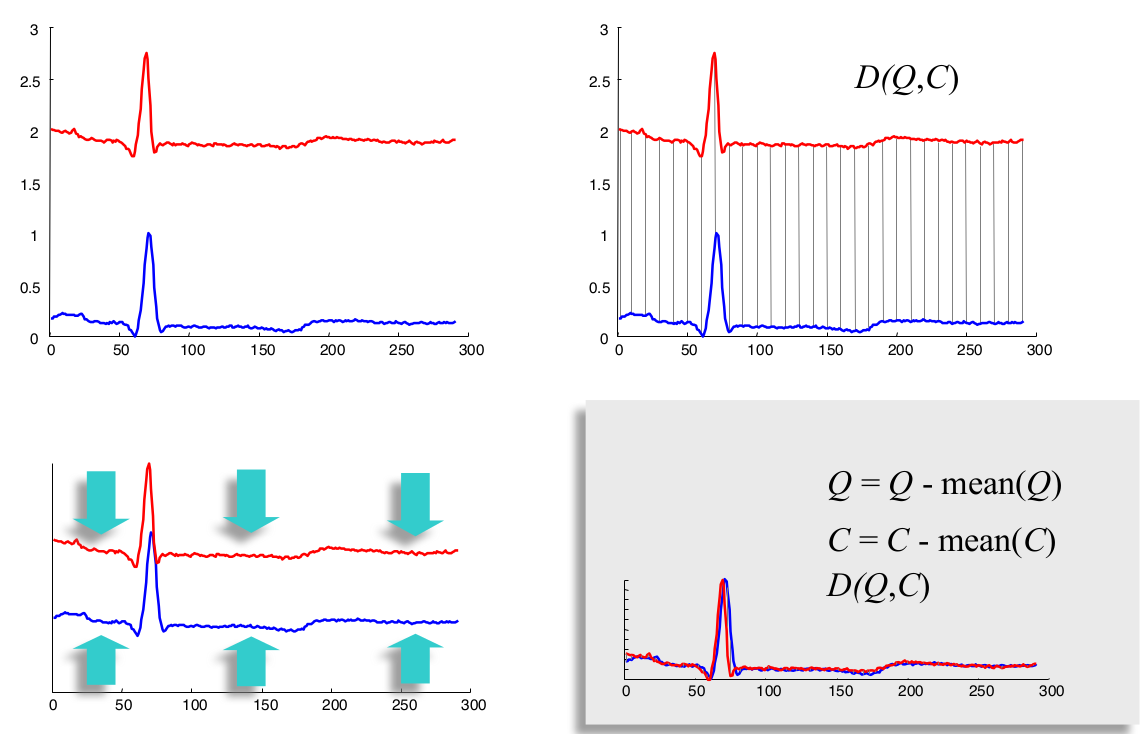
可以看到,处理之前,二者的欧氏距离非常大,处理之后,红线向下平移,蓝线向上平移,最终二者的欧氏距离变得很小。 - Amplitude Scaling(振幅缩放)
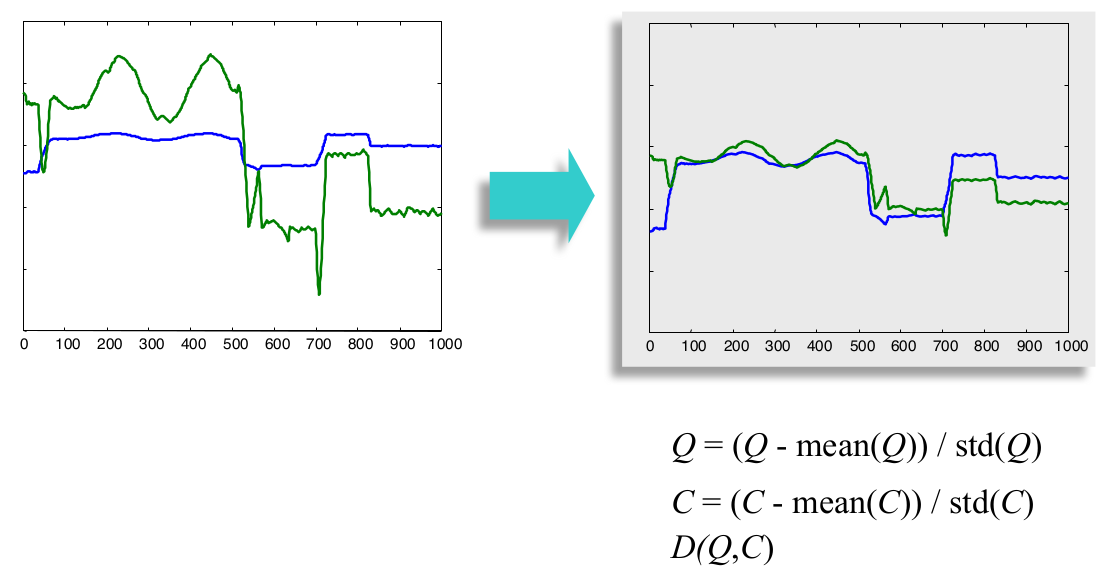
这里是进行了零均值归一化处理,也称 Z-Score Normalization,这是因为两条时间序列的量纲不同,归一化之后,二者的欧氏距离也明显减小。 - Linear Trend(线性趋势)
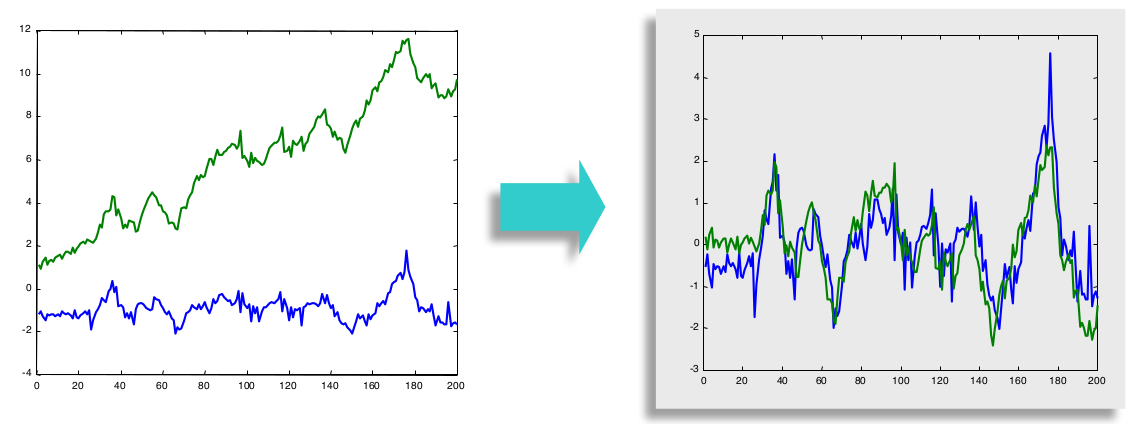
- Noise(噪音)
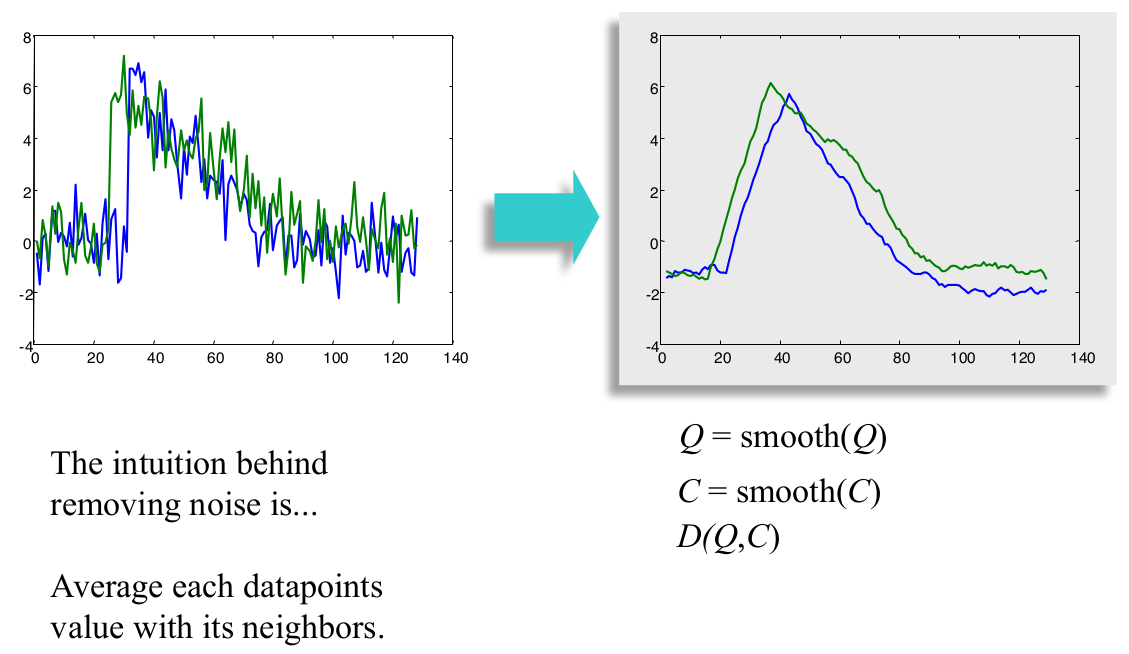
使用平滑方法之后,两条时间序列的欧氏距离也变小了。
下面用一个例子,来展示以欧式距离作为相似性度量标准,数据预处理之前与预处理之后的相似分布图: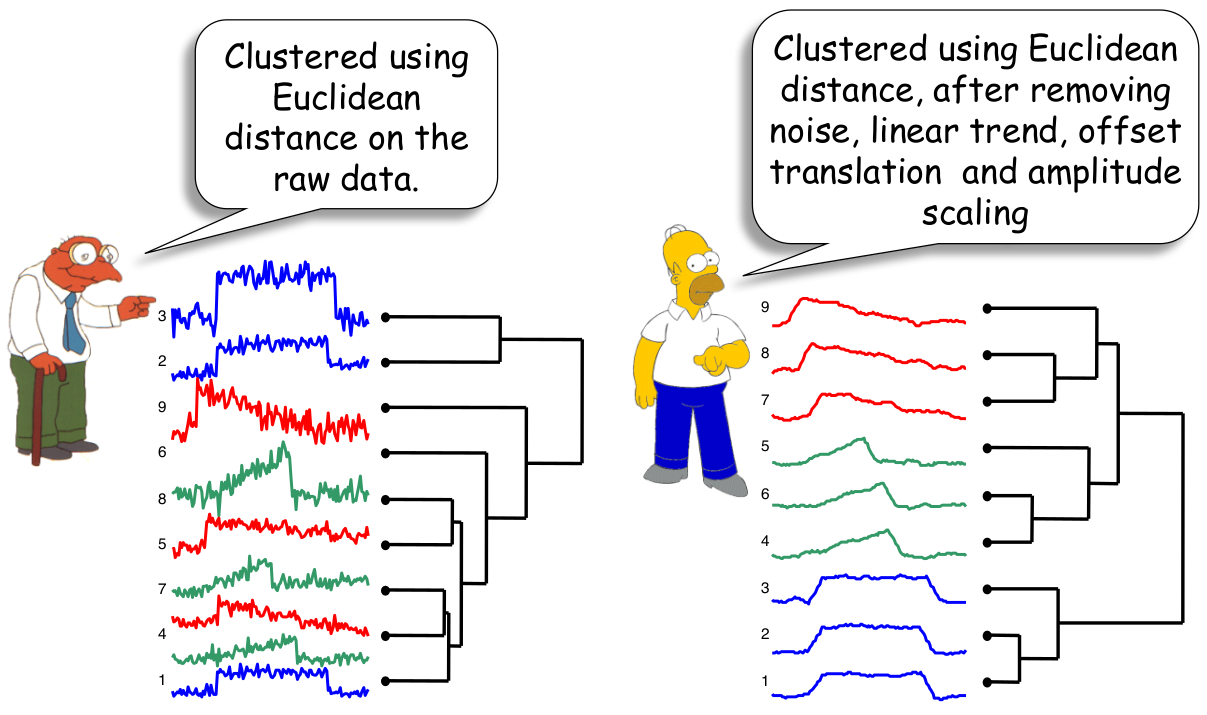
2.4 Dynamic Time Warping
译为动态时间规整法,简称DTW,区别于传统欧氏距离度量的另外一种度量法,它的时间轴可以是扭曲的(warping)。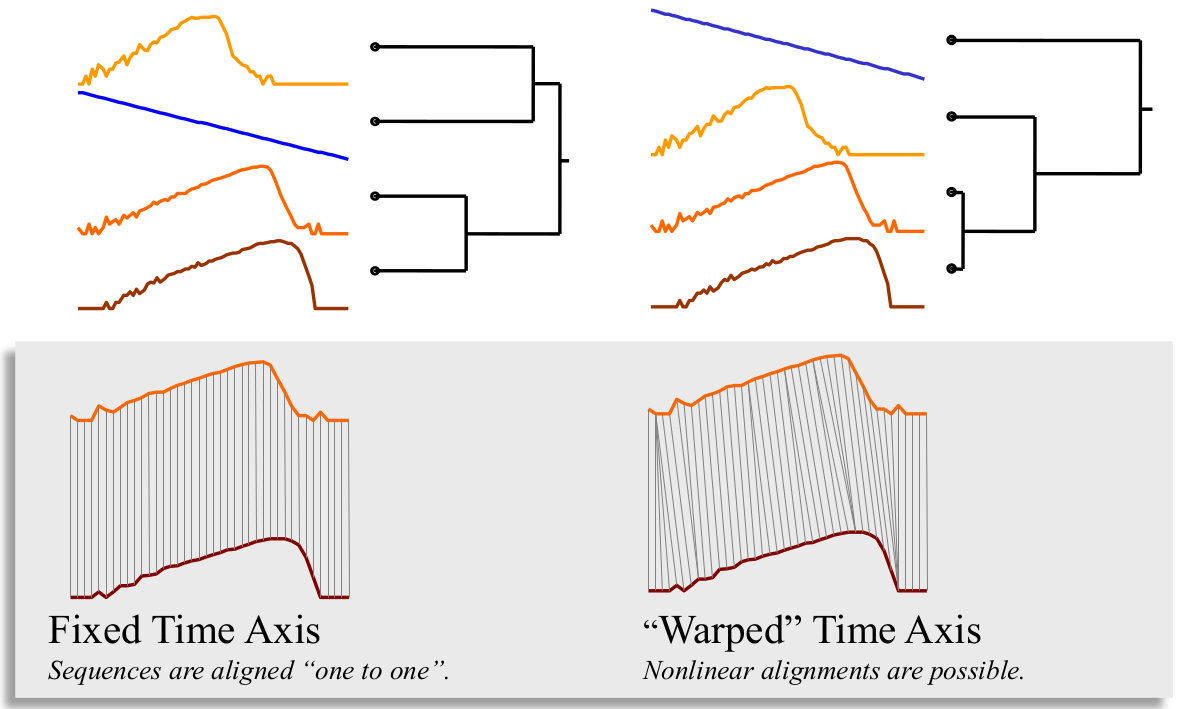
2.4.1 欧氏距离与DTW的在不同应用场景下的对比
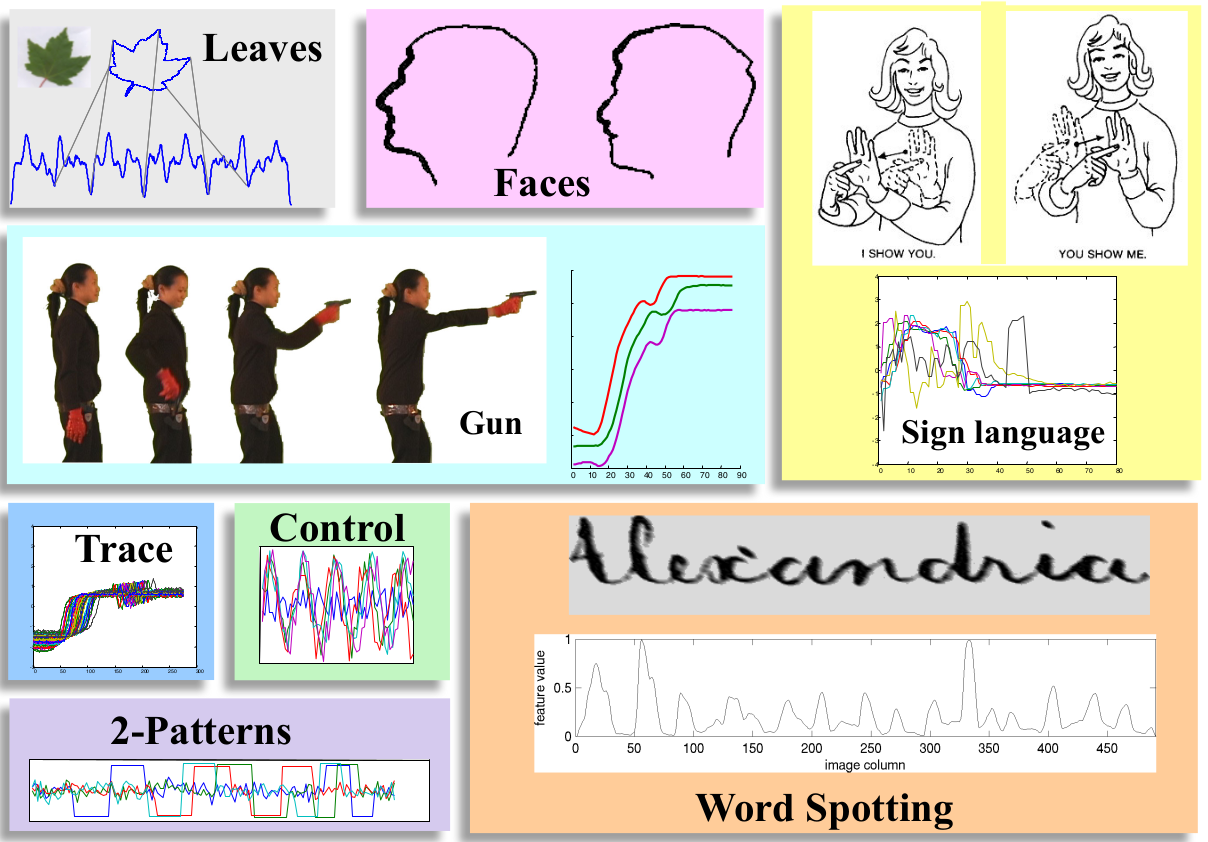
- 错误率
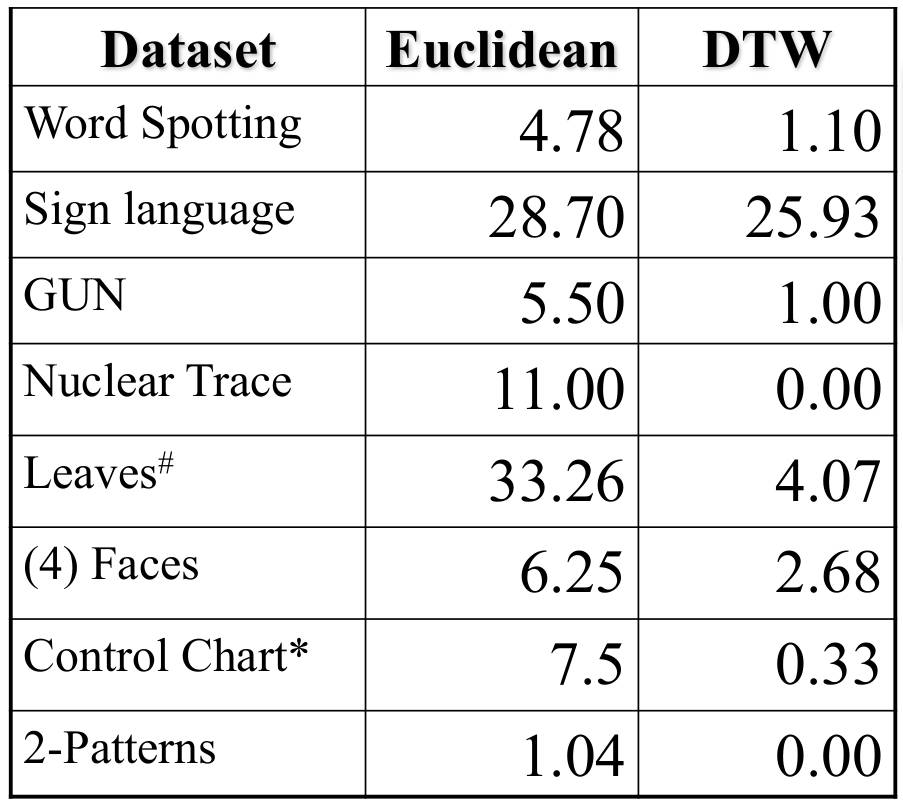
- 计算时间(单位:毫秒)
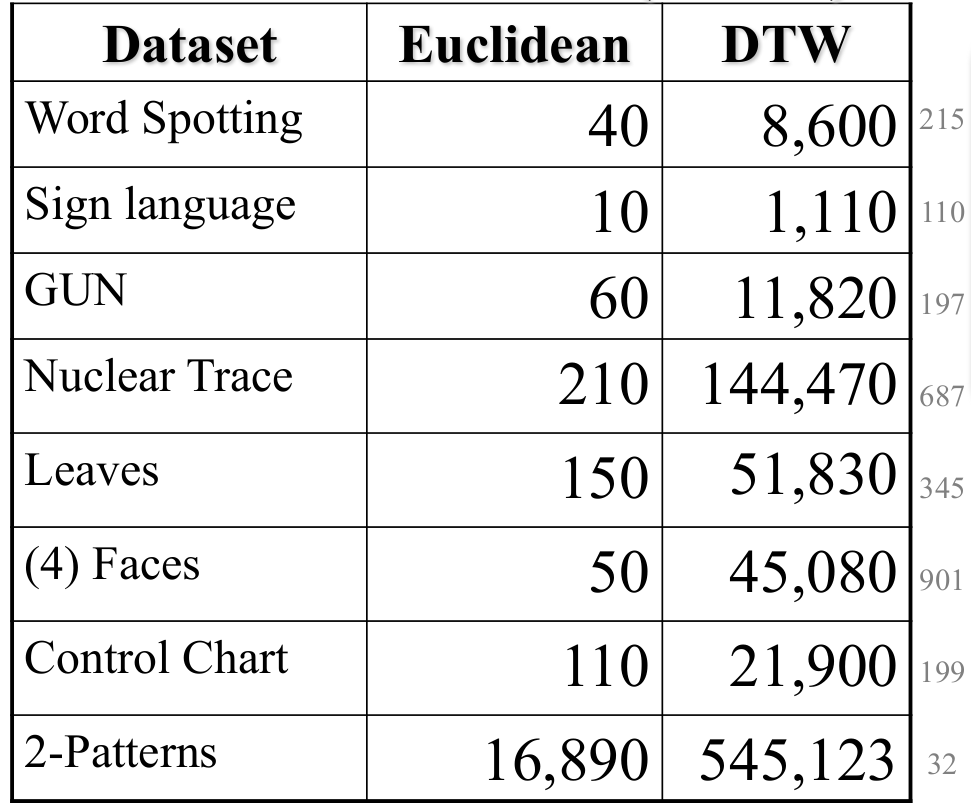
(最右侧是运行时间的倍数)
2.4.2 DTW是如何计算的
- 构建一个行数为∣ ∣ Q ∣ ∣ ||Q||∣∣Q∣∣,列数为∣ ∣ C ∣ ∣ ||C||∣∣C∣∣的矩阵,矩阵中的每一个元素值,等于两条时间序列中对应点的欧氏距离;
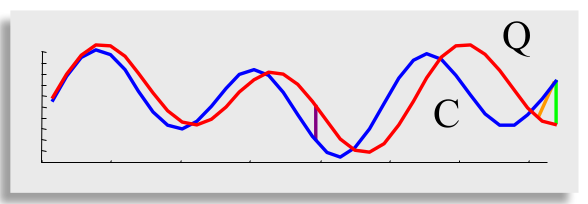
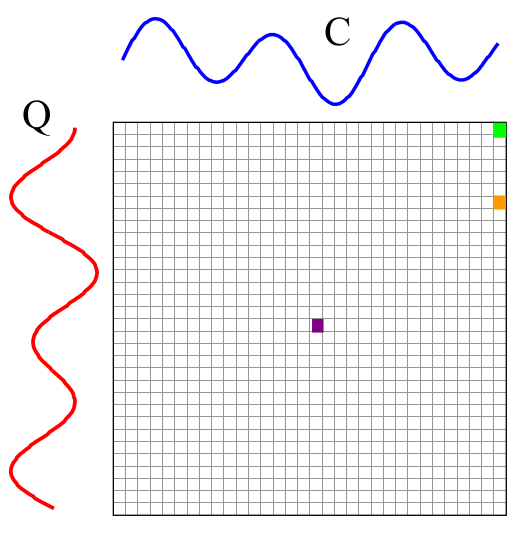
- 我们希望能够找到一条,穿过矩阵的元素和最小的一条路径;
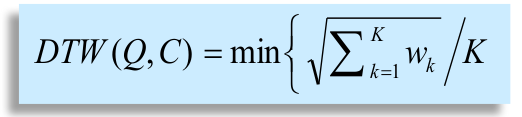
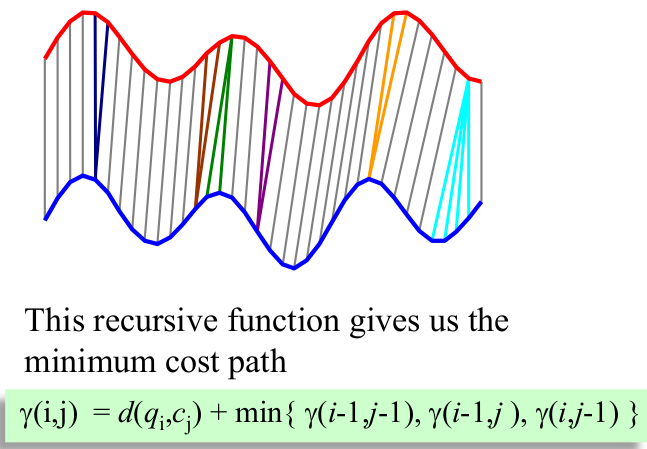
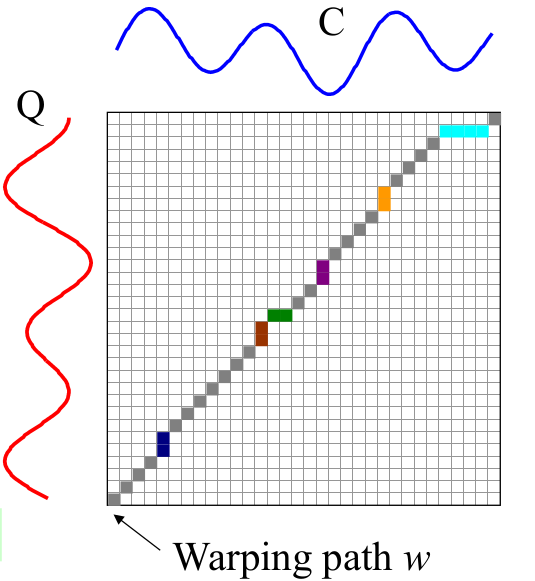
2.4.3 DTW的改进
根据前面所学,我们知道DTW法具有以下特点:
- DTW度量法在绝大多数情况下比欧氏距离度量法效果好;
- DTW度量法的缺点是计算时间非常长,是欧氏距离法的几百倍;
于是我们接下来对其改进,尽量在保证精度的前提下,提升程序的计算速度。
- 改进一:DTW距离的快速近似(fast approximations)
通过下采样或者压缩算法来表示原始的矩阵,效果如下:
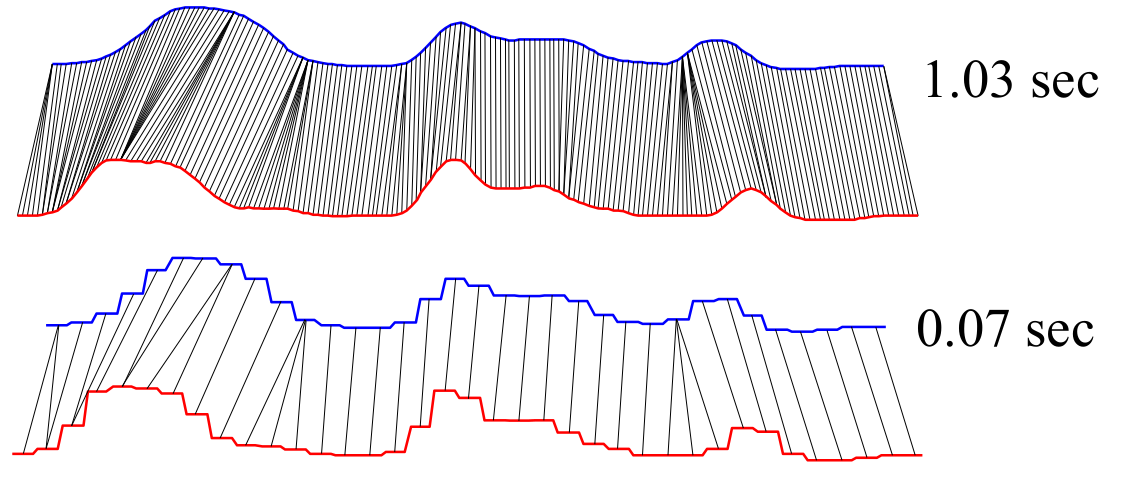
可以看到下采样之后,DTW仍表现出不错的效果,时间也缩短了很多倍,这个方法在聚类和分类等问题中,经过实验的证实的确有用。
- 改进二:全局约束
- 轻微加快计算速度
- 防止病态的扭曲
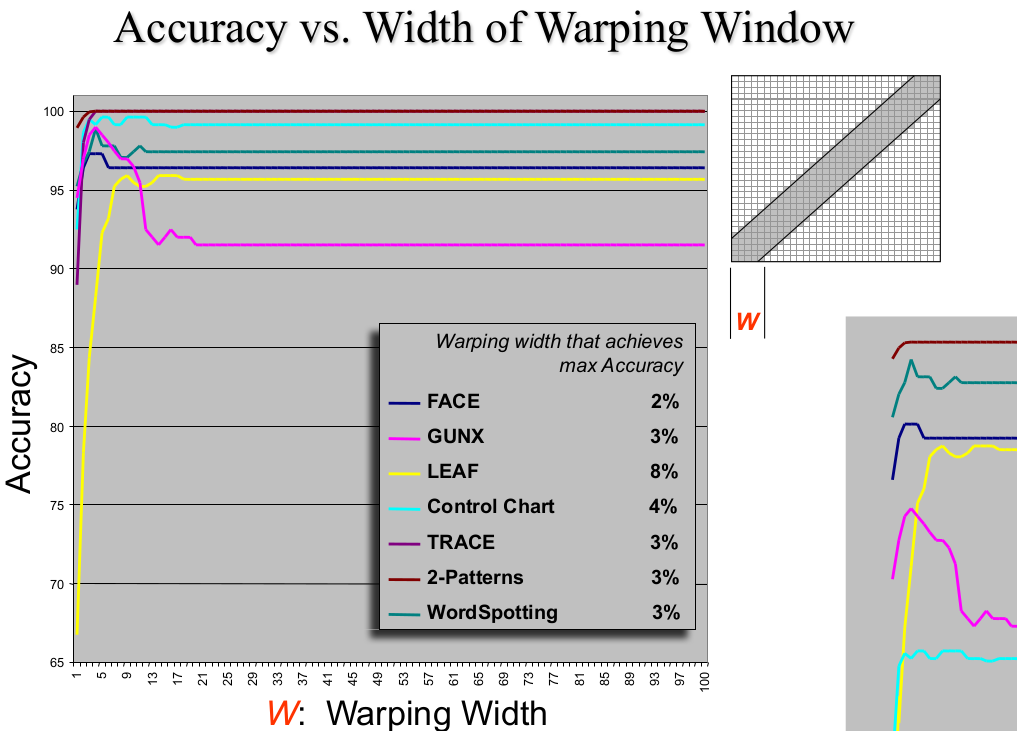
一般有两种全局约束的方式,全局约束体现在,约束 规整路径(warping path) 中的元素,下标 i , j i,ji,j 满足 j − r ≤ i ≤ j + r j-r \leq i \leq j+rj−r≤i≤j+r;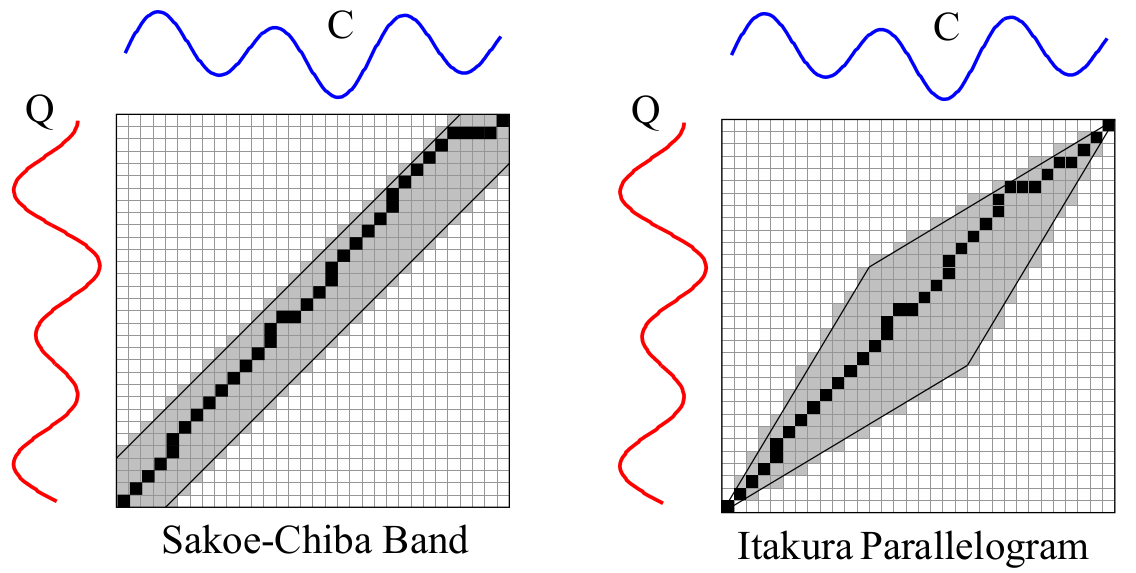
- 规整窗口的大小与精度的关系变化趋势
2.4.4 lowerbounding (下界)
 根据定义,对于所有的时间序列A和B,都有:
根据定义,对于所有的时间序列A和B,都有:l o w e r _ b o u n d _ d i s t a n c e ( A , B ) ≤ D T W ( A , B ) lower\_bound\_distance(A,B) \leq DTW(A,B)lower_bound_distance(A,B)≤DTW(A,B)
Lower_Bounding_Sequential_Scan(Q)算法如下:

主要特点是:减少了计算DTW这种耗时操作的次数,仅在L B _ d i s t < b e s t _ s o _ f a r LB\_dist < best\_so\_farLB_dist<best_so_far的时候才会进行DTW的计算,大多数时候,用不太耗时的lower_bound_distance()进行代替。
- Lower Bound of Yi,简称LB_Yi,由Yi,B,Jagadish等人于Efficient retrieval of similar time sequences under time warping提出:
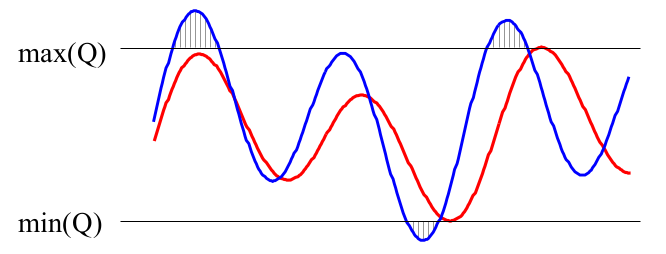
灰色线的平方和代表相应点对整个DTW距离的最小贡献,因此可以作为下界返回。 - Lower Bound of Kim,简称LB_Kim,由Kim,S,Park等人于An index-based approach for similarity search supporting time warping in large sequence databases提出:
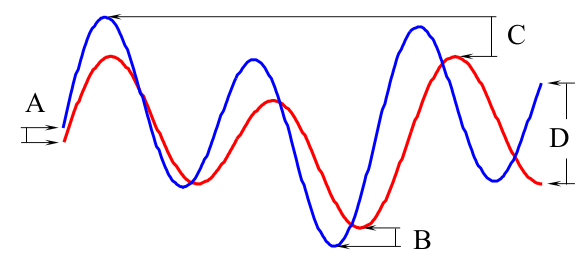
两个序列的第一(A)、最后(D)、最小(B)和最大点(C)之间的平方差作为下界返回。 - Lower Bound of Keogh,简称LB_Keogh
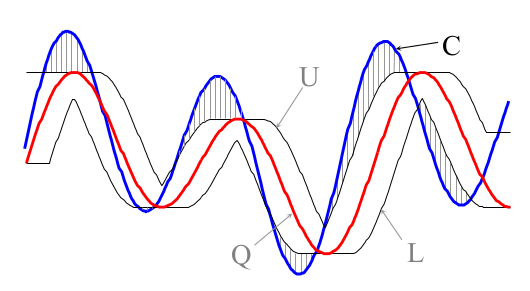
2.5 基于模型或结构层面的相似度
前面所学习的,是在时间序列的 shape 层面上,计算它们的相似度,但是针对于比较长的时间序列,这种方法的效果不太好。接下来我们来讨论,在时间序列的 structure 层面上,计算二者的相似度。
基本思想是:抽取时间序列的全局特征,组成一个特征向量,然后计算这些特征向量之间的相似度。
接下来我们分析几种应用场景,核心是确定两点,features和distance measure/learning algorithm.
- 1.基于特征的时间序列数据分类

这里的特征全是时间序列的数值特征,如均值、方差、偏度、以及它们的一阶导等; - 2.识别时间序列 ------- 将ARMA模型和基于记忆的学习结合起来

- 3.基于压缩的不相似性
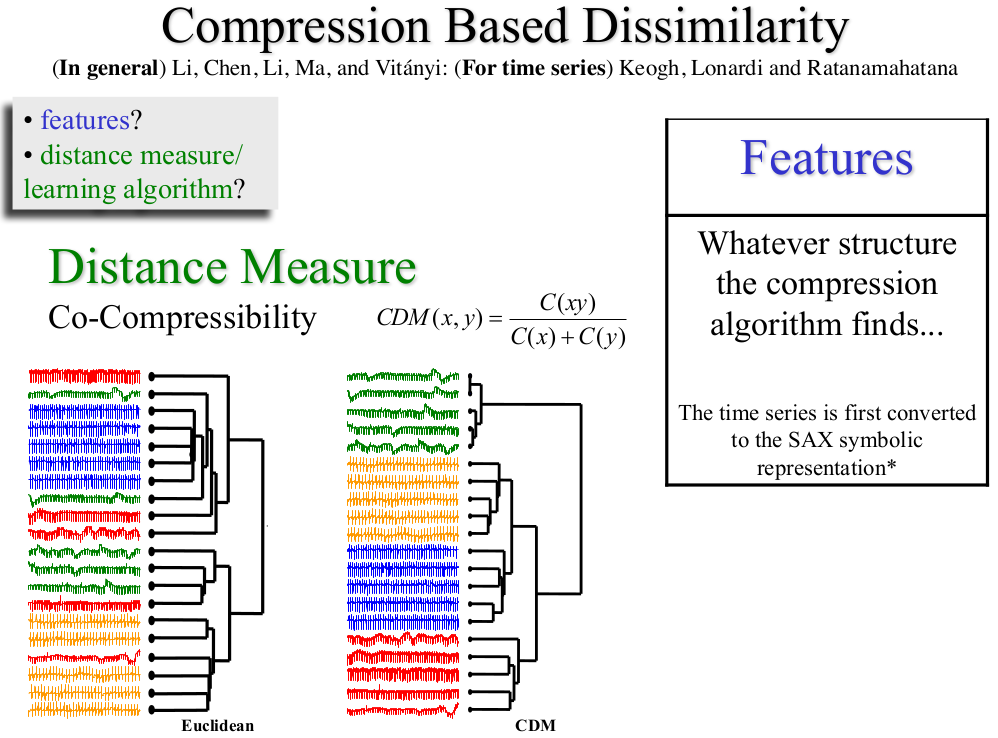
2.6 时间序列相似度总结
- 如果时间序列较短,在搜寻得到合适的 w a r p i n g    w i n d o w    s i z e warping \;window \;sizewarpingwindowsize 之后,使用 DTW 作为相似度度量标准,然后使用基于 e n v e l o p e envelopeenvelope 的下界来加快 DTW 的计算速度;
- 如果时间序列较长,而且你对数据也了解不多,可以尝试基于压缩的不相似性度量;
- 如果时间序列较长,但是你对数据有一定的了解,那么可以利用相关知识来手动抽取特征;