CNN入门
CNN常用操作
convolution(卷积)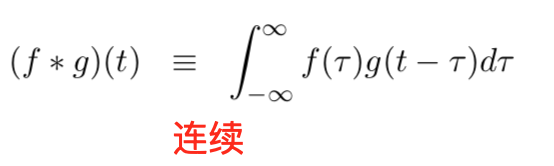
pool:stride(池化)
padding(填充)
CNN常用网络模型简介
VggNet:整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。

{kind=link}
resnet:深度残差网络,当验证准确率已经很高的时候,可以保证参数不变。因此有很多跳变的选择,相当于不同的神经网络。
densenet:feature reuse,各个卷积层之间互相决定。
wide-resnet:在resnet的基础上增加卷积和的个数。
resnext:ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量。采用 VGG 堆叠的思想和 Inception 的 split-transform-merge 思想。
SENet:feature map经过非线性变换,得到的新的feature map,在不同channel上设置了全值。
PNASNet:自动最优模型决定 AutoML
CNN用处
- 人脸识别
下面这个网络模型优缺点:一个是softmax结果过多。另外没有足够的数据集。
FaceNet,a convolutoinal network to transform images into a low-dimensional (i.e., 128) feature space in which face images of same identity are closer than images of different identities,解决了上面模型的问题。
Tripe Loss:任意一个三元组满足同一个人不同照片的距离小于到达不同人的任意照片距离。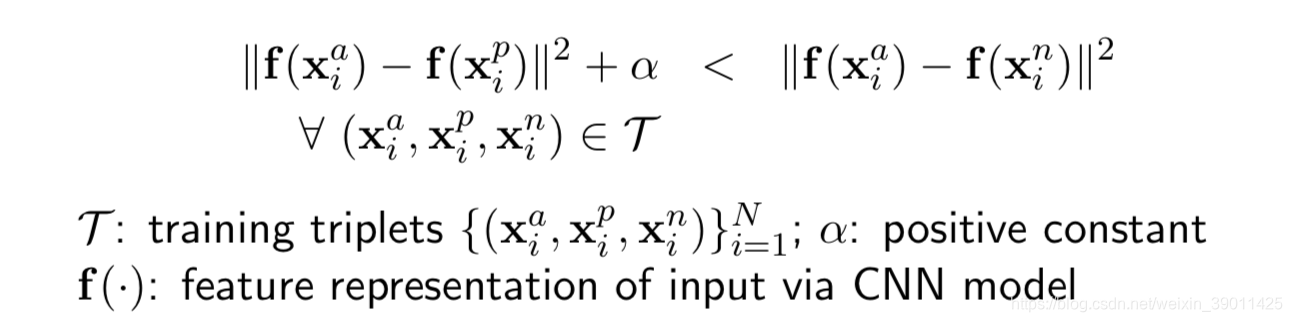
+的意思是,如果是括号里的大于0,那么就是本身,否则就是0。
- 目标检测
目标检测(Object Detection)的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置,是计算机视觉领域的核心问题之一。由于各类物体有不同的外观,形状,姿态,加上成像时光照,遮挡等因素的干扰,目标检测一直是计算机视觉领域最具有挑战性的问题。
引用自:https://blog.csdn.net/happy990/article/details/88807747
- 风格转移
a图像能够获得b图像的风格。
其大体损失函数:x为训练结果图像,p为内容图像,a为风格图像。
训练过程:x,p,a依次输进去。比较feature map,而且x和a的feature map的纹理信息应该相似。
纹理信息如何获取?先sqeeze,然后任意两行相乘。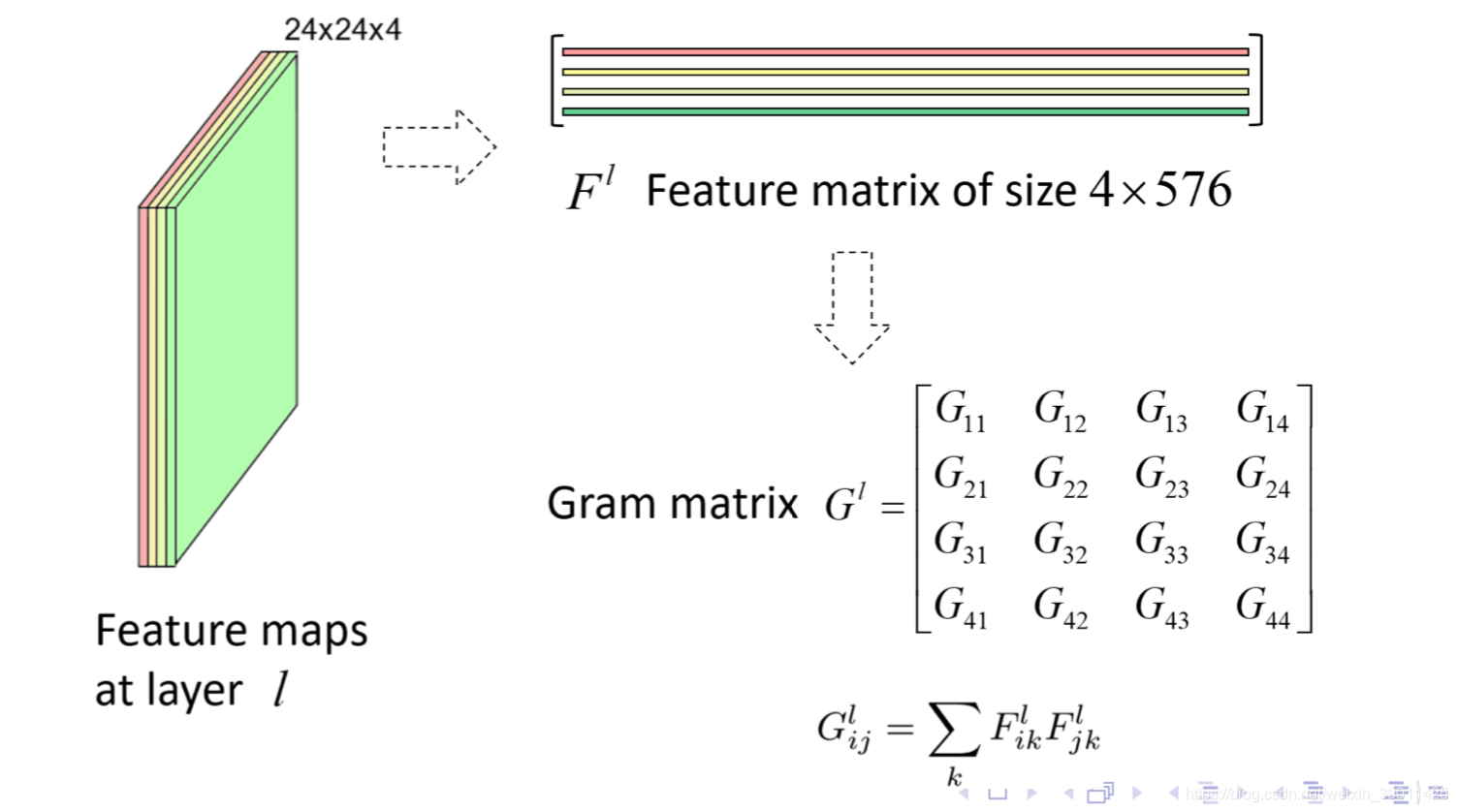
具体损失函数:
- 文本分类
4.1 sentiment analysis 情感分析
4.2 news categorization 新闻类别
杂项
Group Normalization:思想并不复杂,简单讲就是要使归一化操作的计算不依赖batch size的大小。(batch normalization依赖)