目录
1,将全部数据分离成训练集和测试集(之前首先先将x和y分类出来才可以)
3、归一化----标准化---正则化----Python的实现
1,将全部数据分离成训练集和测试集(之前首先先将x和y分类出来才可以)
'''
分离数据集--
test_size :如果是整数则选出来两个测试集,如果是小数,则是选择测试集所占的百分比。
train_size :同理,都含有默认值0.25
shuffle :默认为True,表示 在分离之前是否将其打乱,如果不打乱就设为False
random_state:是随机数的种子。(感觉没什么用,因此每次都填1吧)
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。
比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。
但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
'''
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=4, random_state=42)
结果:
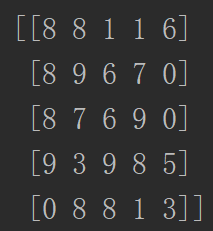
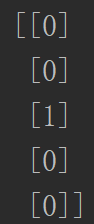
分离成train
[[8 8 1 1 6]] [[0]]
test
[[8 9 6 7 0]
[8 7 6 9 0]
[9 3 9 8 5]
[0 8 8 1 3]]
[[0]
[1]
[0]
[0]]
2,将训练集分离做交叉验证
就是将索引分离
from sklearn.cross_validation import KFold
kf = KFold(9, n_folds=3, random_state=2)
for train, test in kf:
print(train)
print(test)
'''
9:代表测试集的例子的个数
[3 4 5 6 7 8]
[0 1 2]
-----------------------
[0 1 2 6 7 8]
[3 4 5]
-----------------------
[0 1 2 3 4 5]
[6 7 8]
'''for train, test in kf:
# The predictors we're using the train the algorithm. Note how we only take the rows in the train folds.
train_predictors = (titanic[predictors].iloc[train,:])
# The target we're using to train the algorithm.
train_target = titanic["Survived"].iloc[train]
# Training the algorithm using the predictors and target.
alg.fit(train_predictors, train_target)
# We can now make predictions on the test fold
test_predictions = alg.predict(titanic[predictors].iloc[test,:])
predictions.append(test_predictions)3、归一化----标准化---正则化----Python的实现
1、实现归一化的Max-Min--(0,1)标准化:
from sklearn.preprocessing import MinMaxScaler
这是最简单也是最容易想到的方法,通过遍历feature vector里的每一个列数据,将Max和Min的记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理: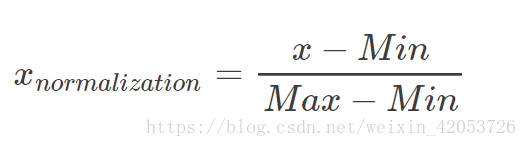
def MaxMinNormalization(x,Max,Min):
x = (x - Min) / (Max - Min);
return x;
'''
sklearn 包就是这么处理的,输入必须是二维数组,每个尺度是纵向分的,
举个例子X_train为(2,3)矩阵,Min为第一列的最小值,第二列的最小值,第三列的最小值
Max 为第一列的最大值,为第一列的最大值,第二列的最大值
下面的例子结果:temp
array([[0., 1., 0.],
[1., 0., 1.]])
scaler.scale_ 为 1/ (Max - Min)
array([0.5 , 0.5 , 0.33333333])
'''
import numpy as np
from sklearn.preprocessing import MinMaxScaler
X_train = np.array([[ 2., 4., 2.],
[4, 2, 5]
])
scaler = MinMaxScaler(feature_range=(0, 1))
X_scaled = scaler.fit_transform(X_train)
print(scaler.scale_)# array([0.5 , 0.5 , 0.33333333])
scaler.min_ # array([-1. , -1. , -0.66666667])
scaler.inverse_transform(X_train ) # 预测完成后你归一化 要保证和X_train 一个形状
还有一个函数fit_transform很像transform,这里就用fit_transform就可以,什么情况下都用fit_transform,就完事了
scaler.min_ 目前代表什么还不知道呢。
scaler.inverse_transform(X_train ) # 预测完成后你归一化 要保证和X_train 一个形状
回归预测一般来说是(n,1)数据预测(n,1)的数据(有一些预测结果是(n,)的数据,需要变成(n,1)的数据,其实(n,)经验证也可以,)
将预测结果传入inverse_transform API 中,即可。
找大小的方法直接用np.max()和np.min()就行了,尽量不要用python内建的max()和min(),除非你喜欢用List.可以试试np.argsort() 和 np.argmax()
2、实现中心化和正态分布的Z-Score---最大最小归一化--用于稀疏数据的MaxAbs--针对离群点的--可视化展示原始数据以及标准化后的数据
zscore_scaler = preprocessing.StandardScaler() # 建立StandardScaler对象
data_scale_1 = zscore_scaler.fit_transform(data) # StandardScaler标准化处理
data的结构可以是numpy.array类型 也可以是dateframe类型
# 标准化,让运营数据落入相同的区间
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
data = np.loadtxt('data6.txt', delimiter='\t') # 读取数据,n行2列的数据
# Z-Score标准化
zscore_scaler = preprocessing.StandardScaler() # 建立StandardScaler对象
data_scale_1 = zscore_scaler.fit_transform(data) # StandardScaler标准化处理
# Max-Min标准化
minmax_scaler = preprocessing.MinMaxScaler() # 建立MinMaxScaler模型对象
data_scale_2 = minmax_scaler.fit_transform(data) # MinMaxScaler标准化处理
# MaxAbsScaler标准化
maxabsscaler_scaler = preprocessing.MaxAbsScaler() # 建立MaxAbsScaler对象
data_scale_3 = maxabsscaler_scaler.fit_transform(data) # MaxAbsScaler标准化处理
# RobustScaler标准化
robustscalerr_scaler = preprocessing.RobustScaler() # 建立RobustScaler标准化对象
data_scale_4 = robustscalerr_scaler.fit_transform(data) # RobustScaler标准化标准化处理
# 展示多网格结果
data_list = [data, data_scale_1, data_scale_2, data_scale_3, data_scale_4] # 创建数据集列表
scalar_list = [15, 10, 15, 10, 15, 10] # 创建点尺寸列表
color_list = ['black', 'green', 'blue', 'yellow', 'red'] # 创建颜色列表
merker_list = ['o', ',', '+', 's', 'p'] # 创建样式列表
title_list = ['source data', 'zscore_scaler', 'minmax_scaler', 'maxabsscaler_scaler', 'robustscalerr_scaler'] # 创建标题列表
for i, data_single in enumerate(data_list): # 循环得到索引和每个数值
plt.subplot(2, 3, i + 1) # 确定子网格
plt.scatter(data_single[:, :-1], data_single[:, -1], s=scalar_list[i], marker=merker_list[i],
c=color_list[i]) # 子网格展示散点图
plt.title(title_list[i]) # 设置子网格标题
plt.suptitle("raw data and standardized data") # 设置总标题
plt.show() # 展示图形
4、Sigmoid函数
Sigmoid函数是一个具有S形曲线的函数,是良好的阈值函数,在(0, 0.5)处中心对称,在(0, 0.5)附近有比较大的斜率而当数据趋向于正无穷和负无穷的时候,映射出来的值就会无限趋向于1和0.
个人非常喜欢的“归一化方法”,之所以打引号是因为我觉得Sigmoid函数在阈值分割上也有很不错的表现,根据公式的改变,就可以改变分割阈值,这里作为归一化方法,我们只考虑(0, 0.5)作为分割阈值的点的情况:
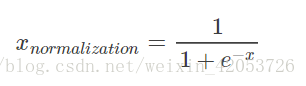
def sigmoid(X,useStatus): #这里useStatus管理是否使用sigmoid的状态,方便调试使用
if useStatus:
return 1.0 / (1 + np.exp(-float(X)))
else:
return float(X)4、sklearn数据特征重要程度的筛选
from sklearn.feature_selection import SelectKBest, f_classif
import matplotlib.pyplot as plt
selector = SelectKBest(f_classif,k='all') #或者k=3:特征的个数
'''
dateframtop1_name_x_train[predictors] 是一个dataframe结构predictors是列名的列表
dateframtop1_name_y_train 因为这里只有一列所以没有列名
'''
selector.fit(dateframtop1_name_x_train[predictors], dateframtop1_name_y_train) #核心函数
scores = -np.log10(selector.pvalues_)
#画图
plt.bar(range(len(predictors)), scores) #画柱状图,比如三个柱子
plt.xticks(range(len(predictors)), predictors, rotation='vertical') #这个是在每一柱子下说明名字
plt.show()#特征的平分如下
