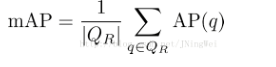对象的定位与识别
这一章节主要讲解两个算法,Faster-RCNN 和SSD,在这之前把卷积神经网络的其他小细节做一个总结。
Back Propagation
BP网络能学习和存储大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程,他的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小:
BP算法的公式:



Batch Normalization
在神经网络中,数据的分布会对训练产生影响,当我们在隐藏层中用激活函数进行激活是,就会产生另外一个问题:不会对x比较大的特征范围敏感了,相当于人的感官系统失效。
Batch normalization 的 batch 是批数据, 把数据分成小批小批进行 stochastic gradient descent(随机梯度下降). 而且在每批数据进行前向传递 forward propagation 的时候, 对每一层都进行 normalization 的处理。
希望激励后的结果是高斯分布的,那么我们手动修一下,另:
BN通常在全连接层后,激励层前做,我们希望CNN学习出来这么一个规则,对输出的结构限制。
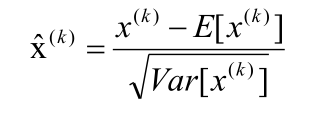
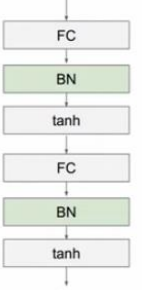

关于Batch Normalization的好处
- 梯度传递(计算)更为流畅
- 学习率设高一点也没关系
- 对于初始值的依赖变少
- 说起来,其实这里可以看成一种正则化,减少了对output的需求
下面看一下使用BN的结果与不使用有什么差别:
很明显,在不使用的情况下,输出的值往两个极端聚拢,在有BN的条件下,我们可以控制输出的范围。

Dropout
神经网络的正则化方式:别一次打开所有的学习单元
randomly set some neurons to zero int the forward pass

Dropout如何预测
实际上在训练的时候是可以这样做的,但是在预测的时候会很麻烦。
所以在做预测的时候会把所有的x乘以一个概率p ,因此在做预测的时候,不会去中途把这个开关打开或关上 ,而是把所有的x 都乘以一个概率p ,这是实际上做的工作。
还有另外一个更好的办法是在训练时把所有的x 都除以p ,实际上在做真的predict时候,什么事情都不用干,因为刚才还要乘以p ,现在把乘以p 的过程,在训练的过程中除以P已经完成了,我已经完成系数的缩放了,因此在做预测的过程中,是多少x 就输入多少x ,直接算就好了,是什么样的权重w 就用什么样的权重,就可以得到标准的结果。
Dropout为什么能防止过拟合
因为这个神经网络没有记住那么多的东西,只是挑了重要的记住,有很好的泛化能力,比如说下面的一幅图,猫有耳朵,但是狗也有耳朵,猫的皮毛毛茸茸,狗也是很毛茸茸,所以,网络不用记下这么多的共同信息,只需要记住其中某些特征。
另外的理解方式:
每次都关掉一些感知器,得到一个模型,最后做融合,不至于听一
家之言

Dropout可以用于卷积层吗?BN可以用于全连接层吗?
应该仅在全连接层上使用Dropout操作,并在卷积层之间使用批量标准化。
首先,在对卷积层进行正则化时,Dropout通常不太有效;原因在于卷积层具有很少的参数,因此初始时他们需要较少的正则化操作,卷积层参数较少,加入dropout作用甚微。此外,由于特征映射的空间关系,激活值可以变得高度相关,这使得Dropout无效。
实验证明使用Dropout的模型性能往往比不使用任何操作的模型性能更差。
应该在卷积层之间插入Batch Normalization(批量标准化),这项技术将使得模型正则化化,进而使得模型在训练期间更加地稳定。
two stage 经典算法:Faster R-CNN
two stage 经典算法是先由算法生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类。
这篇文章是和何凯明大神在2016年出的一篇paper
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- 基本思想:RPN + CNN + ROI
- 引入Region Proposal Network(RPN)替代 Selective Search(SS),引入anchor box应对目标形状的变化。
- 这篇论文中提到了一系列目标边框,该文在生成目标选框中做了一些改进。RPN 通过一个较大范围的尺寸与比例系数来高效的预测候选区域。以前的方法是使用图像金字塔,和不同大小的卷积核进行处理,本文提出了不同尺寸与比例系数组合得到的多个 anchor 用于生成 proposal 作为参考,提高了测试的速度。
RPN 网络主要用于生成 region proposals,首先生成一堆 Anchor box,对其进行裁剪过滤后通过 softmax 判断 anchors 属于前景(foreground)或者后景(background),即是物体 or 不是物体,所以这是一个二分类;同时,另一分支 bounding box regression 修正 anchor box,形成较精确的 proposal
首先通过 Conv layers 得到 feature map,然后进入 RPN 层,先经过一次 3*3 的卷积,逐像素对其 9 个 Anchor box 进行二分类, 逐像素得到其 9 个 Anchor box 四个坐标信息.
特征图 60乘40 上的每个像素生成 9 个 Anchor box,并且对生成的 Anchor box 进行过滤和标记
针对 RPN 的训练,对每个 anchor 进行两类标记,前景/背景(二分类)。
如果 anchor box 与 ground truth 的 IoU 值最大,标记为正样本,label=1
如果 anchor box 与 ground truth 的 IoU>0.7,标记为正样本,label=1
如果 anchor box 与 ground truth 的 IoU<0.3,标记为负样本,label=0
剩下的既不是正样本也不是负样本,不用于最终训练,label=-1
除了对 anchor box 进行标记外,另一件事情就是计算 anchor box 与 ground truth 之间的偏移量



ANCHOR(锚点)
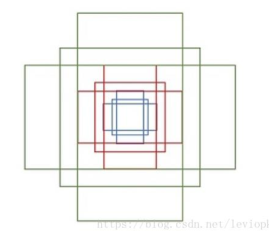
在 feature maps 上进行滑窗操作(sliding window). 滑窗尺寸为 n×n, 如 3×3. 对于每个滑窗, 会生成 9 个锚框,这些锚框具有相同的中心 center=(x ? , ? ? ) ,且具有3种不同的长宽比(aspect ratios) 和 3 种不同的尺度(scales), 如图
以每个点为中心生成9个大小不一的框,那么一定有跟ground truth很接近的框。

RPN结构图(头部)
classification 分支输出一个概率值, 表示bounding-box 中是否包含 object (classid = 1),或者是 background (classid = 0), no object.
regression 分支输出预测的边界框参数: (x, y, w, h).

Bounding box regression
红色框A是原始anchor box,绿色框G代表目标的GroundTruth。
我们的目标是寻找一种关系,使得输入的A经过映射得到一个跟真实窗口G更接近的回归窗口G’。对A的调整,就是Bounding Box回归。
对于边界框一般使用四维向量(x, y, w, h)表示,分别表示边界框的中心点坐标和宽高。给定A=(Ax, Ay, Aw, Ah),寻找一种映射f,使得f(Ax, Ay, Aw, Ah)=(G’x, G’y, G’w, G’h),其中(G’x, G’y, G’w, G’h)≈(Gx, Gy, Gw, Gh)。核心思想:通过平移和缩放方法对物体边框进行调整和修正。

- 原始的anchor box与预测的ground truth之间的偏移量(? ? ,? ? )原始的anchor box与预测的ground truth之间的偏移量(? ? ,? ? )
- ?,?,?和ℎ表示边界框的中心坐标及其宽和高。变量?,? ? 和? ∗ 分别
表示预测边界框、锚框和实际边界框横坐标,其他符号同理。
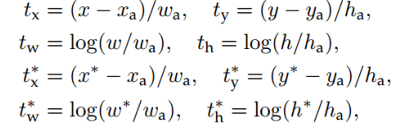
具体分析

损失函数
正样本:IoU(anchor,ground truth)>0.7;
负样本:IoU(anchor,ground truth)<0.3。
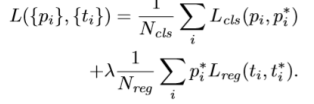
?:每个mini-batch中锚点的序号;
? ? :锚点i是目标的概率, ? ? ∗ :标签(只能是0或1);
? ? :预测边界框的4个参数化坐标的向量;
? ∗ :与正锚点相关的标定框的参数向量;
? ??? :分类损失函数, ? re? :回归损失函数;
? ? ∗ ? re? 表示回归只对正样本进行(负样本? ? ∗ =0)。
这两部分由? ??? (mini-batch的大小决定,这里是256)和? ??? (锚点位置数决定,这里约等于2400)进行规范化,并通过一个平衡参数λ进行加权。默认情况下,设λ=10 。
原图为1000∗600,卷积后feature map为原图的1/16,即约60*40。
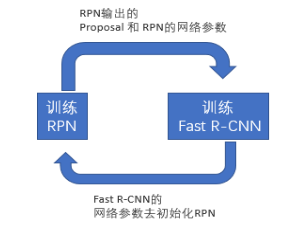
交替训练
- RPN与Fast R-CNN共享特征提取的卷积网络,为了精调这个网络,对RPN和Fast R-CNN交替训练:先训练 RPN,用RPN提取的候选区域训练Fast R-CNN,接着在Fast R-CNN的参数基础上训练RPN,重复交替迭代。
ROI pooling( ROI: Region of interest )
• 输入特征图尺寸不固定,但是输出特征图尺寸固定;
• ROI pooling具体操作如下:
• (1)根据输入image,将ROI映射到feature map对应位置;
• (2)将映射后的区域划分为相似或相同大小的sections
(sections数量与输出的维度相同);
• (3)对每个sections进行max pooling操作;这样我们就可以从
不同大小的方框得到固定大小的相应的feature maps。
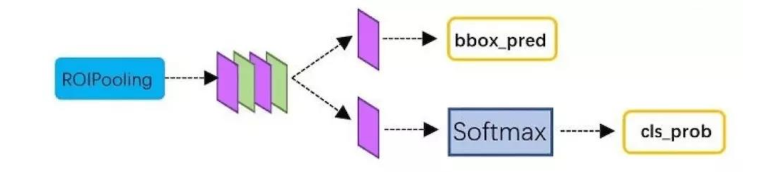
分类层
通过全连接层与softmax,就可以计算属于哪个具体类别,比如人,狗,飞机,并
可以得到cls_prob概率向量。同时再次利用bounding box regression精细调整proposal位置,得到bbox_pred,用于回归更加精确的目标检测框。
实验结果序: mAP的定义
- True positives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
- False positives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
- False negatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
- True negatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
- 精确率、准确率:Accuracy=(TP+TN)/(TP+TN+FN+FP)
- 精准率、查准率: P = TP/ (TP+FP),即预测样本中实际正样本数占所有正样本数的比例
- 召回率、查全率: R = TP/ (TP+FN),即预测样本中实际正样本数占所有预测的样本的比例
- 真正例率(同召回率、查全率):TPR = TP/ (TP+FN)
在目标检测中,每一类都可以根据recall和precision绘制P-R曲线,AP( Average Precision,平均精确度)就是该曲线下的面积。
mAP值
Mean Average Precision,即均值平均精度,是 object detection 中衡量检测精度的指标。是对多个验证集个体求平均AP值 。
计算公式为:
mAP = 所有类别的平均精度求和除以所有类别
下一章将讲述SSD