文章目录
引言
HMM算法的知识体系如下: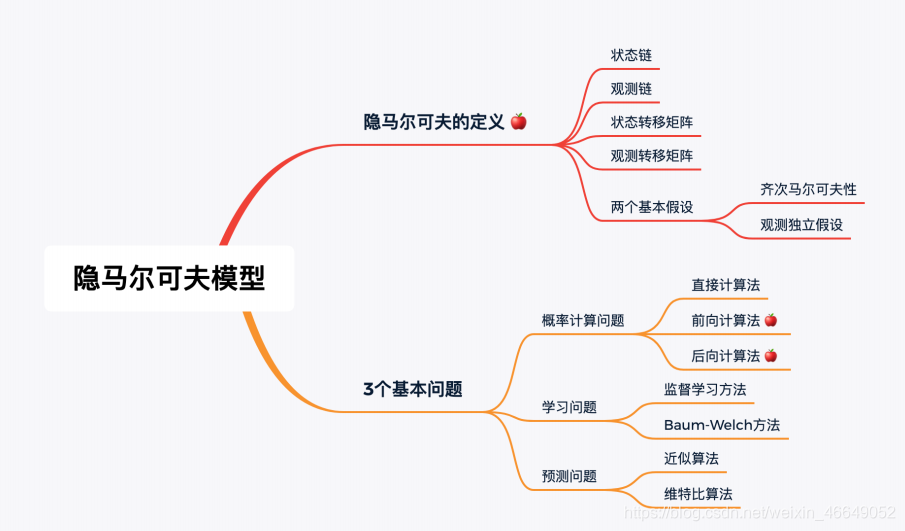
可以总结为两个基本假设,两个集合(序列),三个参数,三个基本问题。
一、隐马尔可夫模型的定义
隐马尔科夫模型是关于时序的概率模型,描述由一个隐藏的马尔科夫链随机生成不
可观测的随机状态序列,再由各个状态生成一个观测从而产生观测随机序列的过程。隐藏的马尔科夫链随机生成的状态序列,称为状态序列(state sequence);每个状态生成一个观测,而由此产生的观测的随机序列,称为观测序列(observationsequence)。序列的每一个位置又可以看做是一个时刻。
1. 两个集合(序列)
设Q是所有可能的状态的集合,V是所有可能的观测集合;状态集合、观测集合定义如下:
Q = { q 1 , q 2 , . . . , q N } Q=\{q_1,q_2,...,q_N\}Q={q1,q2,...,qN}
V = { v 1 , v 2 , . . . , v N } V=\{v_1,v_2,...,v_N\}V={v1,v2,...,vN}
设I是长度为T的状态序列,O是长度为T的观测序列:
I = ( i 1 , i 2 , . . . , i T ) I=(i_1,i_2,...,i_T)I=(i1,i2,...,iT)
O = ( o 1 , o 2 , . . . , o T ) O=(o_1,o_2,...,o_T)O=(o1,o2,...,oT)
2. 两个基本假设
- 齐次马尔科夫性假设
假设隐藏的马尔科夫链在任意时刻t的状态只依赖于其前一时刻的状态,与其他时刻的状态及观测无关,也与时刻t无关
P ( i t ∣ i t − 1 , o t − 1 , . . . , i 1 , o 1 ) = P ( i t ∣ i t − 1 ) , t = 1 , 2 , . . . , T P(i_t|i_{t-1},o_{t-1},...,i_1,o_1) = P(i_t|i_{t-1}),\\t=1,2,...,TP(it∣it−1,ot−1,...,i1,o1)=P(it∣it−1),t=1,2,...,T - 观测独立性假设
假设任意时刻的观测只依赖于该时刻的马尔科夫链的状态,与其他观测及状态无关
P ( o t ∣ i T , o T , i T − 1 , o T − 1 , . . . , i t + 1 , o t + 1 , i t , i t − 1 , o t − 1 , i 1 , o 1 ) = P ( o t ∣ i t ) P(o_t|i_T,o_T,i_{T-1},o_{T-1},...,i_{t+1},o_{t+1},i_t,i_{t-1},o_{t-1},i_1,o_1)=P(o_t|i_t)P(ot∣iT,oT,iT−1,oT−1,...,it+1,ot+1,it,it−1,ot−1,i1,o1)=P(ot∣it)
3. 三个参数
隐马尔科夫模型由初始状态概率向量π ππ、状态转移概率矩阵A AA以及观测概率矩阵B BB决定。π ππ和A AA决定状态序列,B BB决定观测序列。因此,隐马尔可夫模型λ \lambdaλ可以用三元符号
λ = ( A , B , π ) \lambda=(A,B,π)λ=(A,B,π)表示。
- A AA是状态转移概率矩阵
A = [ a i j ] N × N A=[a_{ij}]_{N×N}A=[aij]N×N
其中,
a i j = P ( i t + 1 = q j ∣ i t = q i ) i = 1 , 2 , . . . , N j = 1 , 2 , . . . , N a_{ij}=P(i_{t+1}=q_j|i_t=q_i)\\i=1,2,...,N\\j=1,2,...,Naij=P(it+1=qj∣it=qi)i=1,2,...,Nj=1,2,...,N
a i j a_{ij}aij是在时刻t tt处于状态q i q_iqi的条件下在时刻t + 1 t+1t+1转移到状态q j q_jqj的概率。
- B BB是观测概率矩阵
B = [ b j ( k ) ] N × M B=[b_j(k)]_{N×M}B=[bj(k)]N×M
其中,
b j ( k ) = P ( o t = v k ∣ i t = q j ) k = 1 , 2 , . . . , M j = 1 , 2 , . . . , N b_j(k)=P(o_t=v_k|i_t=q_j)\\k=1,2,...,M\\j=1,2,...,Nbj(k)=P(ot=vk∣it=qj)k=1,2,...,Mj=1,2,...,N
b j ( k ) b_j(k)bj(k)是在时刻t tt处于状态q j q_jqj的条件下生成观测v k v_kvk的概率。
- π ππ是初始状态概率向量
π = ( π i ) π=(π_i)π=(πi)
其中,
π i = P ( i 1 = q i ) i = 1 , 2 , . . . , N π_i=P(i_1=q_i)\\i=1,2,...,Nπi=P(i1=qi)i=1,2,...,N
π i π_iπi是时刻t = 1 t=1t=1处于状态q i q_iqi的概率。
初始状态概率向量π ππ、状态转移概率矩阵A AA确定了隐藏的马尔科夫链,生成不可观测的状态序列。观测概率矩阵B BB确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。隐马尔科夫模型可以用于标注,这时状态对应着标记,标注问题是给定观测的序列预测其对应的标记序列。可以假设标注问题的数据是由隐马尔科夫模型生成的。这样我们可以利用隐马尔可夫模型的学习与预测算法进行标注。
二、隐马尔科夫模型的三个基本问题
1. 概率计算问题
已知信息:模型λ = [ A , B , π ] \lambda=[A,B,π ]λ=[A,B,π],观测序列O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, . . . , o_T)O=(o1,o2,...,oT);
求解目标:计算在给定模型λ \lambdaλ下,已知观测序列О ОО出现的概率:P ( O ∣ λ ) P(O|\lambda)P(O∣λ)。也就是说,给定观测序列,求它和评估模型之间的匹配度。
1.1 直接计算法
直接计算法是按概率公式直接计算。通过列举所有可能的长度为T TT的状态序列I = ( i 1 , i 2 , . . . , i t ) I=(i_1,i_2,...,i_t)I=(i1,i2,...,it),求各个状态序列I II与观测序列O = ( o 1 , o 2 , . . . , o T ) O=(o_1,o_2,...,o_T)O=(o1,o2,...,oT)的联合概率P ( O , I ∣ λ ) P(O,I|\lambda)P(O,I∣λ),然后对所有可能的状态序列求和,得到P ( O ∣ λ ) P(O|\lambda)P(O∣λ)。
状态序列I = ( i 1 , i 2 , . . . , i t ) I=(i_1,i_2,...,i_t)I=(i1,i2,...,it)的概率是:
P ( I ∣ λ ) = π i 1 a i 1 i 2 a i 2 i 3 . . . a i T − 1 i T P(I|\lambda)=π_{i_1}a_{i_1i_2}a_{i_2i_3}...a_{i_{T-1}i_T}P(I∣λ)=πi1ai1i2ai2i3...aiT−1iT
对固定的状态序列I = ( i 1 , i 2 , . . . , i t ) I=(i_1,i_2,...,i_t)I=(i1,i2,...,it),观测序列O = ( o 1 , o 2 , . . . , o T ) O=(o_1,o_2,...,o_T)O=(o1,o2,...,oT)的概率是
P ( O ∣ I , λ ) = b i 1 ( o 1 ) b i 2 ( o 2 ) . . . b i T ( o T ) P(O|I,\lambda)=b_{i_1}(o_1)b_{i_2}(o_2)...b_{i_T}(o_T)P(O∣I,λ)=bi1(o1)bi2(o2)...biT(oT)
对联合概率求和,得到观测序列O OO的概率P ( O ∣ λ ) P(O|\lambda)P(O∣λ),即
P ( O ∣ λ ) = ∑ I P ( O ∣ I , λ ) P ( I ∣ λ ) = ∑ i 1 , i 2 , . . . , i t π i 1 b i 1 ( o 1 ) a i 1 i 2 b i 2 ( o 2 ) . . . a i T − 1 i T b i T ( o T ) P(O|\lambda)=\sum_IP(O|I,\lambda)P(I|\lambda)\\=\sum_{i_1,i_2,...,i_t}π_{i_1}b_{i_1}(o_1)a_{i_1i_2}b_{i_2}(o_2)...a_{i_{T-1}i_T}b_{i_T}(o_T)P(O∣λ)=I∑P(O∣I,λ)P(I∣λ)=i1,i2,...,it∑πi1bi1(o1)ai1i2bi2(o2)...aiT−1iTbiT(oT)
直接计算法的计算量非常大,是O ( T N T ) O(TN^T)O(TNT)阶的,时间复杂度过高,这种算法不可行。
1.2 前向算法
定义前向概率:给定隐马尔可夫模型λ \lambdaλ,定义到时刻t tt部分观测序列为o 1 , o 2 , . . . , o t , o_1,o_2,...,o_t,o1,o2,...,ot,且状态为q i q_iqi的概率为前向概率,记做:
α t ( i ) = P ( o 1 , o 2 , . . . , o t , i t = q i ∣ λ ) \alpha_t(i)=P(o_1,o_2,...,o_t,i_t=q_i|\lambda)αt(i)=P(o1,o2,...,ot,it=qi∣λ)可以递推地求得前向概率α t ( i ) \alpha_t(i)αt(i)及观测序列概率P ( O ∣ λ ) P(O|\lambda)P(O∣λ)。
观测序列概率的前向算法如下:
输入:隐马尔可夫模型λ \lambdaλ,观测序列O OO;
输出:观测序列概率P ( O ∣ λ ) P(O|\lambda)P(O∣λ)
- 步骤1是初始化前向概率,是初始时刻的状态i 1 = q i i_1=q_ii1=qi,和观测o 1 o_1o1的联合概率。
- 计算到时刻t + 1 t+1t+1部分观测序列为o 1 , o 2 , . . . , o t − 1 , o_1,o_2,...,o_{t-1},o1,o2,...,ot−1,且在时刻t + 1 t+1t+1处于状态q i q_iqi的前向概率。
前向算法相比于直接计算法来说,大大减小了计算量。减少计算量的原因在于每一次计算直接引用前一个时刻的计算结果,避免重复计算。利用前向概率计算P ( O ∣ λ ) P(O|\lambda)P(O∣λ)的计算量是O ( N 2 T ) O(N^2T)O(N2T)阶的。
1.3 后向算法

- 步骤1初始化后向概率,对最终时刻的所有状态q i q_iqi规定β T ( i ) = 1 \beta_T(i)=1βT(i)=1
- 步骤2:为了计算在时刻t tt状态为q i q_iqi条件下时刻t + 1 t+1t+1之后的观测序列为o t + 1 , o t + 2 , . . . , o T o_{t+1},o_{t+2},...,o_{T}ot+1,ot+2,...,oT的后向概率β t ( i ) \beta_t(i)βt(i),只需考虑在时刻t+1所有可能的N NN个状态q j q_jqj的转移概率,以及在此状态下的观测o t + 1 o_{t+1}ot+1的观测概率,然后考虑状态q j q_jqj之后的观测序列的后向概率即β T + 1 ( j ) \beta_{T+1}(j)βT+1(j)

2. HMM的学习问题
已知信息:观测序列O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, . . . , o_T)O=(o1,o2,...,oT),
或许也会给定与之对应的状态序列: S = ( s 1 , s 2 , . . . , s T ) S = (s_1, s_2,... , s_T)S=(s1,s2,...,sT)
求解目标︰估计模型λ = [ A , B , π ] \lambda=[A,B,π ]λ=[A,B,π]参数,使得该模型下观测序列概率P ( O ∣ λ ) P(O|\lambda)P(O∣λ)最大。也就是训练模型,使其最好地描述观测数据。
隐马尔科夫模型的学习,根据训练数据是包括观测序列和对应的状态序列还是只有观测序列,可以分为由监督学习与无监督学习实现。
2.1 监督学习算法
假设已给训练数据包含S SS个长度相同的观测序列和对应的状态序列( O 1 , I 1 ) , ( O 2 , I 2 ) , . . . , ( O S , I S ) {(O_1,I_1),(O_2,I_2),...,(O_S,I_S)}(O1,I1),(O2,I2),...,(OS,IS)

用的最多的还是监督学习的方法。
2.2 非监督学习算法—Baum-Welch算法
假设给定训练数据只包含S SS个长度为T TT的观测序列O 1 , O 2 , . . . , O s {O_1,O_2,...,O_s}O1,O2,...,Os而没有对应的状态序列,目标是学习隐马尔科夫模型λ = ( A , B , π ) \lambda=(A,B,π)λ=(A,B,π)的参数。隐马尔科夫模型是一个含有隐变量的概率模型,
P ( O ∣ λ ) = ∑ I P ( O ∣ I , λ ) P ( I ∣ λ ) P(O|\lambda)=\sum_IP(O|I,\lambda)P(I|\lambda)P(O∣λ)=I∑P(O∣I,λ)P(I∣λ)它的参数学习完全可以由EM算法实现。
Baum-Welch算法如下:

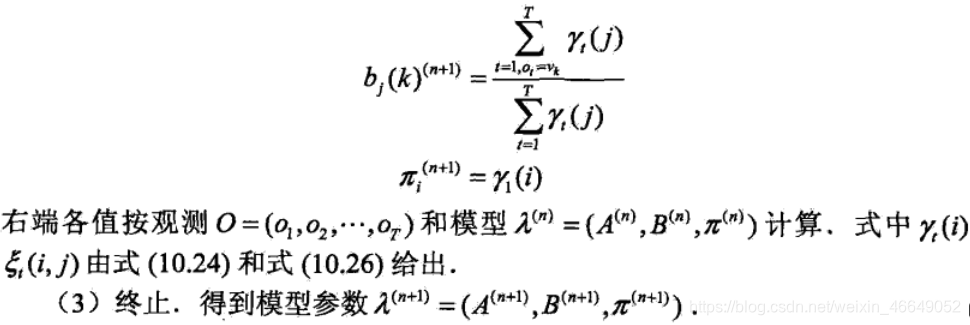
3. HMM的预测问题
已知信息:模型λ = [ A , B , π ] \lambda=[A,B,π ]λ=[A,B,π],观测序列O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, . . . , o_T)O=(o1,o2,...,oT)
求解目标:计算在给定模型λ \lambdaλ下,使已知观测序列О ОО的条件概率P ( O ∣ S ) P(O|S)P(O∣S)最大的状态序列S = ( s 1 , s 2 . . . , s T ) S=(s_1,s_2 ..., s_T )S=(s1,s2...,sT)。即给定观测序列,求最有可能与之对应的状态序列。
这个算法是在分词过程中实际使用的算法。
3.1 近似算法
近似算法的想法是:在每个时刻t tt选择在该时刻最有可能出现的状态i t ∗ i_t^*it∗,从而得到一个状态序列I ∗ = ( i 1 ∗ , i 2 ∗ , . . . , i T ∗ ) I^*=(i_1^*,i_2^*,...,i_T^*)I∗=(i1∗,i2∗,...,iT∗),将它作为预测的结果。
给定隐马尔可夫模型λ \lambdaλ和观测序列O OO,在时刻t tt处于状态q i q_iqi的概率为γ t ( i ) \gamma_t(i)γt(i)是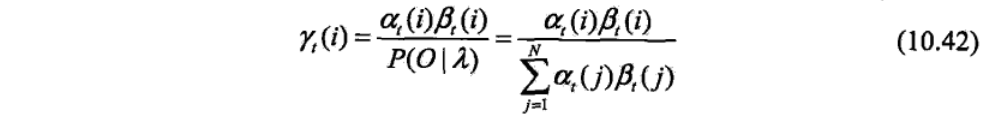
在每一个时刻t tt最有可能的状态i t ∗ i_t^*it∗是
i t ∗ = a r g m a x 1 < = i < = N [ γ t ( i ) ] t = 1 , 2 , . . . , T i_t^*=argmax_{1<=i<=N}[\gamma_t(i)]\\t=1,2,...,Tit∗=argmax1<=i<=N[γt(i)]t=1,2,...,T从而得到状态序列I ∗ = ( i 1 ∗ , i 2 ∗ , . . . , i T ∗ ) I^*=(i_1^*,i_2^*,...,i_T^*)I∗=(i1∗,i2∗,...,iT∗)。
近似算法的优点是计算简单,缺点是不能保证预测的状态序列整体上是最有可能的状态序列,因为预测的状态序列可能有实际不发生的部分。
3.2 维特比算法
维特比算法实际上是用动态规划解隐马尔科夫模型预测问题,即用动态规划求概率最大路径。这时一条路径对应着一个状态序列。依据这一原理,我们只需从时刻t = 1 t=1t=1开始,递推地计算在时刻t tt状态为i ii的各条部分路径的最大概率,直至得到时刻t = T t=Tt=T状态为i ii的各条路径的最大概率。时刻t = T t=Tt=T的最大概率即为最优路径的概率P ∗ P^*P∗,最优路径的终结点i T ∗ i_T^*iT∗也同时得到。之后,为了找出最优路径的各个结点,从终结点i T ∗ i_T^*iT∗开始,由后向前逐步求得结点i T − 1 ∗ , . . . , i 1 ∗ i_{T-1}^*,...,i_1^*iT−1∗,...,i1∗,得到最优路径I ∗ = ( i 1 ∗ , i 2 ∗ , . . . , i T ∗ ) I^*=(i_1^*,i_2^*,...,i_T^*)I∗=(i1∗,i2∗,...,iT∗)。
下面给出两个变量δ \deltaδ和Ψ \PsiΨ的定义:
定义在时刻t tt状态为i ii的所有单个路径( i 1 , i 2 , . . , i t ) (i_1,i_2,..,i_t)(i1,i2,..,it)中概率的最大值为
δ t ( i ) = m a x i 1 , i 2 , . . , i t − 1 P ( i t = i , i t − 1 , . . . , i 1 , o t , . . . , o 1 ∣ λ ) i = 1 , 2 , . . , N \delta_t(i) = max_{i_1,i_2,..,i_{t-1}}P(i_t=i,i_{t-1},...,i_1,o_t,...,o_1|\lambda)\\i=1,2,..,Nδt(i)=maxi1,i2,..,it−1P(it=i,it−1,...,i1,ot,...,o1∣λ)i=1,2,..,N
由定义可得δ \deltaδ的递推公式:
δ t + 1 ( i ) = m a x i 1 , i 2 , . . , i t P ( i t + 1 = i , i t , i t − 1 , . . . , i 1 , o t + 1 o t , . . . , o 1 ∣ λ ) = m a x 1 < = j < = N [ δ t ( j ) a j i ] b i ( o t + 1 ) t = 1 , 2 , . . . , T − 1 i = 1 , 2 , . . , N \delta_{t+1}(i) = max_{i_1,i_2,..,i_{t}}P(i_{t+1}=i,i_t,i_{t-1},...,i_1,o_{t+1}o_t,...,o_1|\lambda)\\=max_{1<=j<=N}[\delta_t(j)a_{ji}]b_i(o_{t+1})\\t=1,2,...,T-1\\i=1,2,..,Nδt+1(i)=maxi1,i2,..,itP(it+1=i,it,it−1,...,i1,ot+1ot,...,o1∣λ)=max1<=j<=N[δt(j)aji]bi(ot+1)t=1,2,...,T−1i=1,2,..,N
定义在时刻t tt状态为i ii的所有单个路径( i 1 , i 2 , . . , i t − 1 , i ) (i_1,i_2,..,i_{t-1},i)(i1,i2,..,it−1,i)中概率最大的路径的第t − 1 t-1t−1个节点为
Ψ t ( i ) = a r g m a x 1 < = j < = N [ δ t − 1 ( j ) a j i ] , i = 1 , 2 , . . . , N \Psi_t(i)=arg max_{1<=j<=N}[\delta_{t-1}(j)a_{ji}],\\i=1,2,...,NΨt(i)=argmax1<=j<=N[δt−1(j)aji],i=1,2,...,N用于存储路径。
下面介绍维特比算法
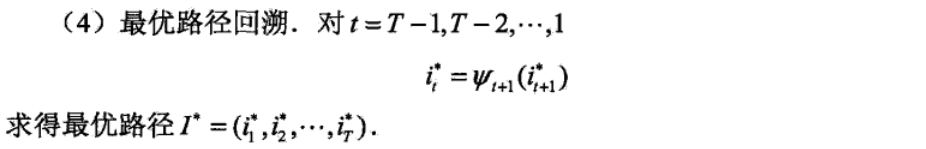
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论或者私信!