概述
在计算机科学中,Trie \text{Trie}Trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
Trie \text{Trie}Trie这个术语来自于retrieval \text{retrieval}retrieval。
在图示中,键标注在节点中,值标注在节点之下。每一个完整的英文单词对应一个特定的整数。Trie \text{Trie}Trie可以看作是一个确定有限状态自动机,尽管边上的符号一般是隐含在分支的顺序中的。
键不需要被显式地保存在节点中。图示中标注出完整的单词,只是为了演示Trie \text{Trie}Trie的原理。
Trie \text{Trie}Trie中的键通常是字符串,但也可以是其它的结构。Trie \text{Trie}Trie的算法可以很容易地修改为处理其它结构的有序序列,比如一串数字或者形状的排列。比如,Bitwise Trie \text{Bitwise Trie}Bitwise Trie中的键是一串比特,可以用于表示整数或者内存地址。
(来源:[WikiPedia \text{WikiPedia}WikiPedia]
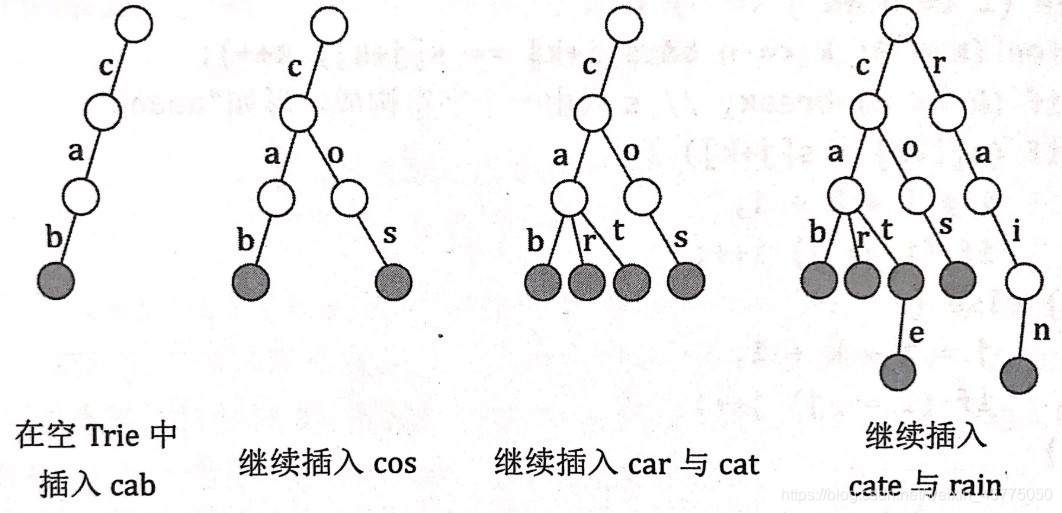
字符型字典树
在字典树上插入字符串。
字典树的结构与表示法

可以看到,这棵字典树用边来代表字母,而从根结点到树上某一结点的路径就代表了一个字符串,树的节点上视情况需要进行其他额外的标记。举个例子, 1 → 2 → 6 → 11 1\to2\to6\to111→2→6→11表示的就是字符串“aba” \text{“aba”}“aba”。
我们用数组 t r i e [ u ] [ c ] trie[u][c]trie[u][c] 表示结点 u uu 的 c cc 字符指向的下一个结点,或着说是结点 u uu 代表的字符串后面添加一个字符 c cc 形成的字符串的结点。比如,在上图中 t r i e [ 4 ] [ ′ b ′ ] = 9 trie[4]['b']=9trie[4][′b′]=9,在实际代码中,要将字母映射为数字。
字典树上每一条根节点到其余节点的路径都表示一个完整单词的前缀,如果某一个节点正好代表单词的结尾,我们要将其打上结尾的标记,表示根节点到该点的路径为一个完整单词。 如果在上图将节点 12 1212 打上标记,那么路径 1 → 4 → 8 → 12 1\to4\to8\to 121→4→8→12就代表一个完整的单词 “caa” \text{“caa”}“caa”。
字典树的节点个数一般设置为N × L e n ( t ) N\times Len(t)N×Len(t)(N NN 为字符串个数,L e n ( t ) Len(t)Len(t) 为字符串长度)。
插入
当需要在树上插入字符串 S SS 时,我们定义一个指向树上节点的指针 p pp ,初始化将其指向根节点。
O ( n ) O(n)O(n) 扫描字符串中的字符 c cc ,若存在一条边使得 p pp 能指向下一个节点,即t r i e [ p ] [ c ] ≠ 0 trie[p][c]\ne 0trie[p][c]=0(初始化时令 t r i e trietrie 上所有节点标记为 0 00),那么直接操作p = t r i e [ p ] [ c ] p=trie[p][c]p=trie[p][c],将 p pp 指向下一个节点。如果 t r i e [ p ] [ c ] trie[p][c]trie[p][c] 为空,则新建一个节点 t r i e [ p ] [ c ] trie[p][c]trie[p][c],然后令 p = t r i e [ p ] [ c ] p=trie[p][c]p=trie[p][c]。当 S SS 中的字符扫描完毕时,在当前节点 p pp 上标记它是一个字符串的末尾。

int trie[SIZE][26],tot=1;//初始化,假设字符串由小写字母构成,根节点编号为0
void insert(char s[])//插入一个字符串
{
int len=strlen(s),p=1;
int i;
for(i=0;i<len;i++)
{
int ch=str[i]-'a';//映射为数字
if(trie[p][ch]==0) trie[p][ch]=++tot;//增加节点
p=trie[p][ch];
}
end_sign[p]=true;//单词结尾标记
}
查询
当需要检索一个字符串 S SS 在树上是否存在时,我们令一个指针 P PP 初始化指向根节点,然后依次扫描 S SS 中的每个字符 c cc。若 t r i e [ p ] [ c ] trie[p][c]trie[p][c] 指向空,则说明 S SS 没有被插入过 Trie \text{Trie}Trie,结束检索,返回 false \text{false}false;否则移动 P PP 至 t r i e [ p ] [ c ] trie[p][c]trie[p][c]。
当 S SS 中的字符扫描完毕时,若当前节点 p pp 被标记为一个字符串的末尾,则说明 S SS 在字典树中存在,否则说明 S SS 没有被插入过字典树。
bool query(char s[])//检索字符串是否存在
{
int len=strlen(s),p=1;
int i;
for(i=0;i<len;i++)
{
p=trie[p][s[i]-'a'];
if(!p) return false;//指向空
}
return end_sign[p];//返回该节点的标记
}
洛谷 P2580 于是他错误的点名开始了 ↬ \looparrowright↬
题目背景
XS \text{XS}XS中学化学竞赛组教练是一个酷爱炉石的人。
他会一边搓炉石一边点名以至于有一天他连续点到了某个同学两次,然后正好被路过的校长发现了然后就是一顿欧拉欧拉欧拉(详情请见已结束比赛CON900 \text{CON900}CON900)。
题目描述
这之后校长任命你为特派探员,每天记录他的点名。校长会提供化学竞赛学生的人数和名单,而你需要告诉校长他有没有点错名。
输入格式
第一行一个整数 n nn,表示班上人数。接下来 n nn 行,每行一个字符串表示其名字(互不相同,且只含小写字母,长度不超过 50 5050)。第 n + 2 n+2n+2 行一个整数 m mm,表示教练报的名字。接下来 m mm 行,每行一个字符串表示教练报的名字(只含小写字母,且长度不超过 50 5050)。
输出格式
对于每个教练报的名字,输出一行。如果该名字正确且是第一次出现,输出“OK”,如果该名字错误,输出“WRONG”,如果该名字正确但不是第一次出现,输出“REPEAT”。(均不加引号)
输入输出样例
输入 #1
5
a
b
c
ad
acd
3
a
a
e
输出 #1
OK
REPEAT
WRONG
说明/提示
对于 40 % 40\%40% 的数据,n ≤ 1000 , m ≤ 2000 n≤1000,m≤2000n≤1000,m≤2000;
对于 70 % 70\%70% 的数据,n ≤ 10000 , m ≤ 20000 n≤10000,m≤20000n≤10000,m≤20000;
对于 100 % 100\%100% 的数据, n ≤ 10000 , m ≤ 100000 n≤10000,m≤100000n≤10000,m≤100000。
分析
在字典树上进行插入查找操作,记录每个单词被访问的次数。
代码
#include<iostream>
#include<cstring>
#define N 52*10009
using namespace std;
int trie[N][26];
int tot=1;
char name[56];
int n;
int vis[N];
/*------------插入-----------*/
void insert(char s[])
{
int len=strlen(s);
int i;
int p=1;
for(i=0;i<len;i++)
{
int ch=s[i]-'a';
if(!trie[p][ch]) trie[p][ch]=++tot;
p=trie[p][ch];
}
vis[p]++;//标记单词末尾
}
/*----------查询------------*/
int search(char s[])
{
int len=strlen(s);
int i,p=1;
for(i=0;i<len;i++)
{
int ch=s[i]-'a';
p=trie[p][ch];
if(!p) return 0;
}
return ++vis[p];//记录访问,第一次访问标记为2。
}
int main()
{
scanf("%d",&n);
int i;
for(i=1;i<=n;i++)
{
scanf("%s",name);
insert(name);
}
int m;
scanf("%d",&m);
while(m--)//m次询问
{
scanf("%s",name);
switch(search(name))
{
case 0:
puts("WRONG");
break;
case 1:
puts("WRONG");
break;
case 2:
puts("OK");
break;
default:
puts("REPEAT");
break;
}
}
return 0;
}
后记
其实直接用map映射就行,貌似一些简单的字典树问题都可以用map实现。
HDU 1251 统计难题 ↬ \looparrowright↬
Problem Description
Ignatius最近遇到一个难题,老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计出以某个字符串为前缀的单词数量(单词本身也是自己的前缀)。
Input
输入数据的第一部分是一张单词表,每行一个单词,单词的长度不超过 10 1010,它们代表的是老师交给Ignatius \text{Ignatius}Ignatius 统计的单词,一个空行代表单词表的结束.第二部分是一连串的提问,每行一个提问,每个提问都是一个字符串。
注意:本题只有一组测试数据,处理到文件结束。
Output
对于每个提问,给出以该字符串为前缀的单词的数量。
Sample Input
banana
band
bee
absolute
acm
ba
b
band
abc
Sample Output
2
3
1
0
Idea
统计每个前缀出现的次数即可,每次都是查询前缀。
Code
#include<iostream>
#include<cstring>
#define N 100001*11
using namespace std;
int trie[N][26];
int tot=1;
char word[12];
int n;
int end_cnt[N];
/*------------插入-----------*/
void insert(char s[])
{
int len=strlen(s);
int i;
int p=1;
for(i=0;i<len;i++)
{
int ch=s[i]-'a';
if(!trie[p][ch]) trie[p][ch]=++tot;
p=trie[p][ch];
end_cnt[p]++;//统计每个前缀出现的次数
}
}
/*----------查询------------*/
int query(char s[])
{
int len=strlen(s);
int i,p=1;
for(i=0;i<len;i++)
{
int ch=s[i]-'a';
p=trie[p][ch];
if(!p) return 0;
}
return end_cnt[p];
}
int main()
{
while(gets(word))
{
if(word[0]=='\0') break;
else insert(word);
}
while(~scanf("%s",word)) printf("%d\n",query(word));
return 0;
}
01 0101字典树
将数的二进制表示看做一个字符串,就可以建出字符集为 { 0 , 1 } \{0,1\}{0,1} 的字典树。01 0101字典树是在处理一些异或问题时非常高效的数据结构。
01 0101字典树的结构
01 0101字典树上每个节点这多有两个子节点,每条边上的字符只可能为 0 00 或 1 11。
我们用数组 t r i e [ u ] [ n u m ] trie[u][num]trie[u][num] 表示结点 u uu 的 数字n u m numnum 指向的下一个结点,或着说是结点 u uu 代表的二进制位后面添加一个数字 n u m numnum 形成的新数字的结点。
上图的树上表示有二进制数 111 , 101 , 001 111,101,001111,101,001,即十进制数 7 , 5 , 1 7,5,17,5,1。
插入与查询
与插入和查询字符串过程相似,定义指针 p pp,初始化指向根节点,利用 p pp 的移动遍历字典树。
洛谷 P4551 最长异或路径 ↬ \looparrowright↬
题目描述
给定一棵 n nn 个点的带权树,结点下标从 1 11 开始到 n nn。寻找树中找两个结点,求最长的异或路径。
异或路径指的是指两个结点之间唯一路径上的所有边权的异或。
输入格式
第一行一个整数 n nn ,表示点数。
接下来 n − 1 n-1n−1 行,给出 u , v , w u,v,wu,v,w ,分别表示树上的 u uu 点和 v vv 点有连边,边的权值是 w ww。
输出格式
一行,一个整数表示答案。
输入输出样例
输入 #1
4
1 2 3
2 3 4
2 4 6
输出 #1
7
说明/提示
最长异或序列是1 → 2 → 3 1\to2\to31→2→3,答案是 3 ⊕ 4 = 7 3 ⊕ 4=73⊕4=7
数据范围
1 ≤ n ≤ 100000 1\le n \le 1000001≤n≤100000;0 < u , v ≤ n 0 < u,v \le n0<u,v≤n;0 ≤ w < 2 31 0 \le w < 2^{31}0≤w<231
分析
记 d [ i ] d[i]d[i] 表示根节点到节点 i ii 的路径上所有边权的异或和,对于任意两点 p , q p,qp,q,两点间路径的异或和显然是 d [ p ] ⊕ d [ q ] d[p]⊕d[q]d[p]⊕d[q]。我们可以通过一次 DFS \text{DFS}DFS 得到数组 d dd,问题转化为:从数组 d dd 中找出两个数 ,使两数的异或和最大。暴力枚举的时间复杂度为 O ( n 2 ) O(n^2)O(n2),我们可以用 01 0101 字典树将复杂度降至 O ( 30 × n ) O(30\times n)O(30×n)。
将 d dd 中所有元素插入 01 0101字典树,每次取一个 d [ i ] d[i]d[i] 在树上进行匹配,匹配时从高位到低位采取贪心的策略。匹配 d [ i ] d[i]d[i] 实际是要在字典树上取一条最优路径,使得经过的路径上数字异或 d [ i ] d[i]d[i] 的值最大。我们将 d [ i ] d[i]d[i] 的每一个二进制位取出,既然要让异或的值最大,那肯定要按该位数字的反方向走。因为异或的运算法则就是:相同为 0 00,不同为 1 11。
每次匹配时,我们依次取出 d [ i ] d[i]d[i] 的最高位、次高位…… 定义 d [ i ] d[i]d[i] 某一位的数字为 n u m numnum ,如果t r i e [ p ] [ n u m ⊕ 1 ] trie[p][num⊕1]trie[p][num⊕1]存在,我们要将 p pp 移动至 t r i e [ p ] [ n u m ⊕ 1 ] trie[p][num⊕1]trie[p][num⊕1],这样异或才会产生贡献,否则相同数字异或为 0 00 则不产生贡献。由于01 0101字典树上自顶向下依次存储数字二进制的最高位、次高位……因此这样的贪心策略是可行的,因为高位的贡献必定大于低位的贡献。
代码
#include<iostream>
#include<cstdio>
#include<cstring>
#define N 100005
using namespace std;
int n;
int edge_num,head[N];
int d[N];
struct E//链式前向星
{
int to;
int w;
int Next;
}edge[N<<1];
inline void add_edge(int from,int to,int w)//加边
{
edge_num++;
edge[edge_num].to=to;
edge[edge_num].w=w;
edge[edge_num].Next=head[from];
head[from]=edge_num;
}
void dfs(int x,int father)//dfs预处理得各点到根节点的异或和
{
int i;
for(i=head[x];~i;i=edge[i].Next)
{
int y=edge[i].to;
if(y!=father)
{
d[y]=d[x]^edge[i].w;
dfs(y,x);
}
}
}
int trie[N*32][2];
int tot=1;
/*----------插入----------*/
void insert(int x)
{
int p=1,i;
for(i=30;i>=0;i--)//按位取出
{
int num=x>>i&1;
if(!trie[p][num]) trie[p][num]=++tot;
p=trie[p][num];
}
}
/*----------查询-----------*/
int query(int x)
{
int i;
int p=1,res=0;
for(i=30;i>=0;i--)//按位取出
{
int num=x>>i&1;
if(trie[p][num^1])//尽量往反方向走
{
res=res+(1<<i);//产生贡献
p=trie[p][num^1];
}
else p=trie[p][num];
}
return res;
}
int main()
{
memset(head,-1,sizeof(head));
memset(trie,0,sizeof(trie));
scanf("%d",&n);
int i;
for(i=1;i<=n-1;i++)
{
int u,v,w;
scanf("%d%d%d",&u,&v,&w);
add_edge(u,v,w);
add_edge(v,u,w);
}
dfs(1,0);
for(i=1;i<=n;i++) insert(d[i]);
int ans=0;
for(i=1;i<=n;i++) ans=max(ans,query(d[i]));
printf("%d\n",ans);
return 0;
}