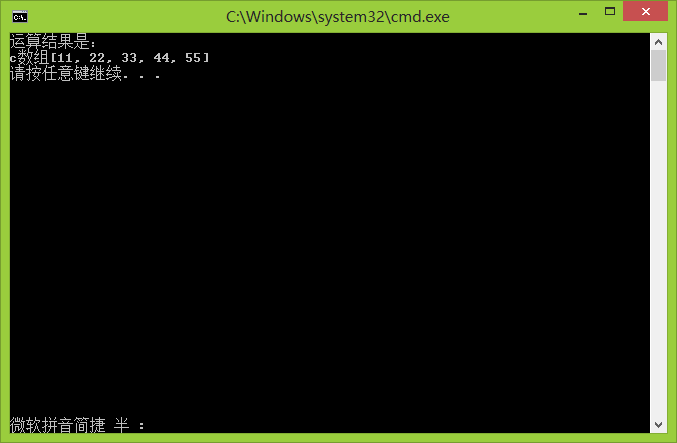
一个简单的CUDA程序
上一篇博客中讲到了如何下载并且搭建CUDA的开发环境,这次我将我第一次学到的CUDA程序记录下来,供自己和同行们日后查阅。
如果在安装CUDA之前安装了VisualStudio 2008和Visual Studio 2010的话,那么CUDA会自动检测到开发环境并且配置相关项目模板。这里以Visual Studio 2010为例,我们新建项目的时候它已经显示出了现成的CUDA项目模板。
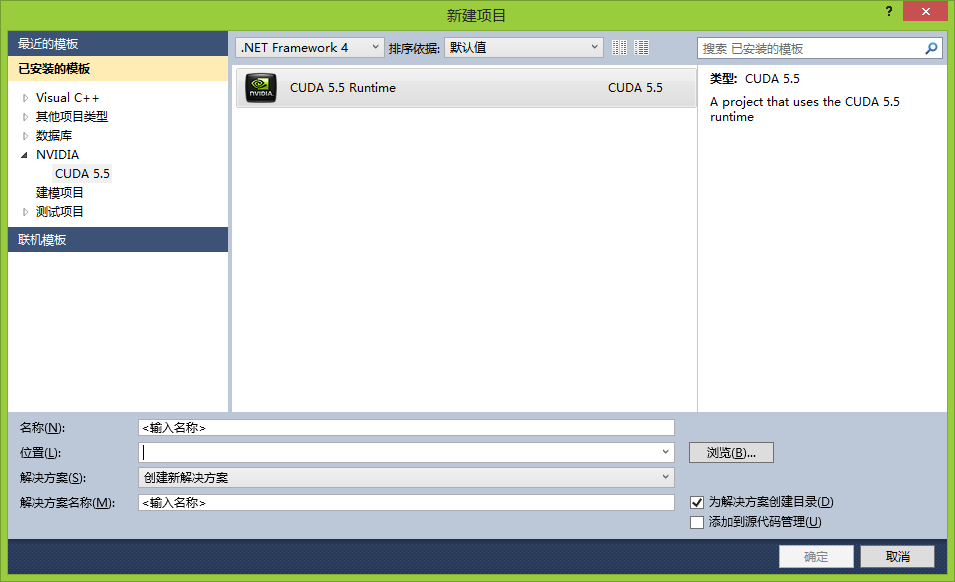
项目创建完毕后就会根据项目模板创建相关的工程文件以及一部分源代码。源代码是cuda专用的格式.cu。在Visual Studio 2008和Visual Studio 2010中,如果你想对cu这种文件格式进行语法加亮,那么在”工具➡选项➡文本编辑器➡文件扩展名”中设定cu扩展名被Microsoft Visual C++所识别。然后重新启动Visual Studio即可。

CUDA为我们创建的项目模板只有CUDARuntime,但是开发CUDA与其相关的应应用程序,除了CUDA Runtime还不知这些。CUDA中支持从底层到高层的一系列开发。CUDA Driver API是较为偏底层的,不容易学习;Runtime API是一些以cuda开头的函数,这点很像OpenGL、OpenAL和OpenCL,较前者高级一些;还有更高级的封装库,比如说开发高级CUDA程序将要用到的thrust。
通过自己的学习,我了解到使用CUDA一般有几个步骤:
1、设置设备
2、分配显存空间
3、将宿主程序数据复制到显存中
4、执行程序,宿主程序等待显卡执行完毕
5、与内核同步等待执行完毕
6、获取数据
接下来我将我修改的例子代码贴出来,这段代码和例子代码所需要完成的功能完全一致,是通过CUDA技术用GPU计算两个向量的和。
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void addKernel( int* c, constint* a, const int* b )
{
inti = threadIdx.x;
c[i]= a[i] + b[i];
}
cudaError_t CUDA_Add( const int* a, constint* b, int* out, int size )
{
int*dev_a;
int*dev_b;
int*dev_c;
//1、设置设备
cudaError_tcudaStatus = cudaSetDevice( 0 );
switch( true )
{
default:
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "调用cudaSetDevice()函数失败!" );
returncudaStatus;
}
//2、分配显存空间
cudaStatus= cudaMalloc( (void**)&dev_a, size * sizeof(int) );
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "调用cudaMalloc()函数初始化显卡中a数组时失败!" );
break;
}
cudaStatus= cudaMalloc( (void**)&dev_b, size * sizeof(int) );
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "调用cudaMalloc()函数初始化显卡中b数组时失败!" );
break;
}
cudaStatus= cudaMalloc( (void**)&dev_c, size * sizeof(int) );
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "调用cudaMalloc()函数初始化显卡中c数组时失败!" );
break;
}
//3、将宿主程序数据复制到显存中
cudaStatus= cudaMemcpy( dev_a, a, size * sizeof( int ), cudaMemcpyHostToDevice );
if( cudaStatus != cudaSuccess )
{
fprintf( stderr, "调用cudaMemcpy()函数初始化宿主程序数据a数组到显卡时失败!");
break;
}
cudaStatus= cudaMemcpy( dev_b, b, size * sizeof( int ), cudaMemcpyHostToDevice );
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "调用cudaMemcpy()函数初始化宿主程序数据b数组到显卡时失败!" );
break;
}
//4、执行程序,宿主程序等待显卡执行完毕
addKernel<<<1,size>>>( dev_c, dev_a, dev_b );
//5、查询内核初始化的时候是否出错
cudaStatus= cudaGetLastError( );
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "显卡执行程序时失败!" );
break;
}
//6、与内核同步等待执行完毕
cudaStatus= cudaDeviceSynchronize( );
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "在与内核同步的过程中发生问题!" );
break;
}
//7、获取数据
cudaStatus= cudaMemcpy( out, dev_c, size * sizeof( int ), cudaMemcpyDeviceToHost );
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "在将结果数据从显卡复制到宿主程序中失败!" );
break;
}
}
cudaFree(dev_c );
cudaFree(dev_a );
cudaFree(dev_b );
returncudaStatus;
}
int main( int argc, char** argv )
{
constint arraySize = 5;
constint a[arraySize] = { 1, 2, 3, 4, 5 };
constint b[arraySize] = { 10, 20, 30, 40, 50 };
intc[arraySize] = { 0 };
cudaError_tcudaStatus;
cudaStatus= CUDA_Add( a, b, c, arraySize );
printf("运算结果是:\nc数组[%d, %d, %d, %d, %d]\n",
c[0],c[1], c[2], c[3], c[4] );
cudaStatus= cudaDeviceReset( );
if( cudaStatus != cudaSuccess )
{
fprintf(stderr, "调用cudaDeviceReset()函数失败!" );
return1;
}
return0;
}