一、ElasticSearch文档批量操作实现
(这里只是批量操作文档,查询文档的操作在后面会补充)
1.批量获取文档数据
批量获取文档数据是通过_mget的API来实现的
(1)在URL中不指定index和type
功能说明 : 可以通过ID批量获取不同index和type的数据
请求方式:GET
请求地址:_mget
请求参数:
docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
GET _mget
{
"docs": [
{
"_index": "es_db",
"_type": "_doc",
"_id": 1
},
{
"_index": "es_db",
"_type": "_doc",
"_id": 2
}
]
}操作结果:
{
"docs" : [
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "1",
"_version" : 3,
"_seq_no" : 7,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "张三666",
"sex" : 1,
"age" : 25,
"address" : "广州天河公园",
"remark" : "java developer"
}
},
{
"_index" : "es_db",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "李四",
"sex" : 1,
"age" : 28,
"address" : "广州荔湾大厦",
"remark" : "java assistant"
}
}
]
}(2)在URL中指定index
功能说明 : 可以通过ID批量获取不同index和type的数据
请求方式:GET
请求地址:/{{indexName}}/_mget
请求参数:
docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
GET /es_db/_mget
{
"docs": [
{
"_type":"_doc",
"_id": 3
},
{
"_type":"_doc",
"_id": 4
}
]
}(3)在URL中指定index和type
功能说明 : 可以通过ID批量获取不同index和type的数据
请求方式:GET
请求地址:/{{indexName}}/{{typeName}}/_mget
请求参数:
docs : 文档数组参数
_index : 指定index
_type : 指定type
_id : 指定id
_source : 指定要查询的字段
GET /es_db/_doc/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 2
}
]
}
# 通过上之前的文章得知,我们还可以
GET /es_db/_doc/_mget
{ "ids":["1","2"] }2.批量操作文档数据
批量对文档进行写操作是通过_bulk的API来实现的
- 请求方式:POST
- 请求地址:_bulk
- 请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
第一行参数为指定操作的类型及操作的对象(index,type和id)
第二行参数才是操作的数据
actionName:表示操作类型,主要有create,index,delete和update
参数类似于:
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}
{"field1":"value1", "field2":"value2"}(1)批量创建文档create
POST _bulk
{"create":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"白起老师1","content":"白起老师666","tags":["java", "面向对象"],"create_time":1554015482530}
{"create":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"白起老师2","content":"白起老师NB","tags":["java", "面向对象"],"create_time":1554015482530}(2)普通创建或全量替换index
如果原文档不存在,则是创建
如果原文档存在,则是替换(全量修改原文档)
POST _bulk
{"index":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"图灵徐庶老师(一)","content":"图灵学院徐庶老师666","tags":["java", "面向对象"],"create_time":1554015482530}
{"index":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"图灵诸葛老师(二)","content":"图灵学院诸葛老师NB","tags":["java", "面向对象"],"create_time":1554015482530}(3)批量删除delete
POST _bulk
{"delete":{"_index":"article", "_type":"_doc", "_id":3}}
{"delete":{"_index":"article", "_type":"_doc", "_id":4}}(4)批量修改update
POST _bulk
{"update":{"_index":"article", "_type":"_doc", "_id":3}}
{"doc":{"title":"ES大法必修内功"}}
{"update":{"_index":"article", "_type":"_doc", "_id":4}}
{"doc":{"create_time":1554018421008}}二、DSL语言高级查询
详情见另一篇文章
https://blog.csdn.net/m0_60162373/article/details/123817163 https://blog.csdn.net/m0_60162373/article/details/123817163
https://blog.csdn.net/m0_60162373/article/details/123817163
三、映射Mapping
1.ES中映射可以分为动态映射和静态映射
(1)动态映射:
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
动态映射规则如下:
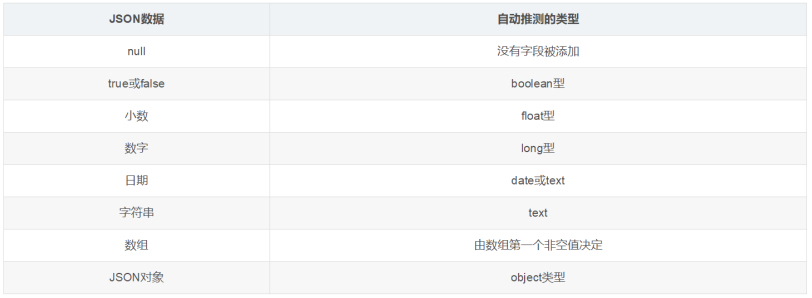
(2)静态映射:
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
2.动态映射
PUT /es_db/_doc/1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "java入门至精通",
"address": "广州小蛮腰"
}这样直接添加数据,自动创建索引库的方式就相当于动态映射,这个时候就可以查看这个索引库的映射信息了(mapping信息)。
获取文档映射:
GET /es_db/_mapping 3.静态映射
步骤:
1)创建索引:
PUT /es_db创建静态映射的索引库时,7.x版本和之前的版本会有细微的差别,7.x版本不需要指定type,而之前的版本可能还要指定type,并且在下面的配置中还会有type相关的配置,碰到的时候注意一下,要知道,活学活用。
2)设置文档映射
PUT /es_db
{
"mappings":{
"properties":{
"name":{"type":"keyword","index":true,"store":true},
"sex":{"type":"integer","index":true,"store":true},
"age":{"type":"integer","index":true,"store":true},
"book":{"type":"text","index":true,"store":true},
"address":{"type":"text","index":true,"store":true,"analyzer":"ik_smart","search_analyzer":"ik_smart"}
}
}
}- index属性:代表要不要建立索引,true要建立索引,false不建立索引。如果分词了,那基于倒排索引生成的索引表就会有相关信息(关键词对应index的那张表),如果不建立索引,那就没有相关信息。这个属性决定了是否建立相关的索引。如果不建立索引,那就代表没法根据这个字段进行查询,索引表都没有数据,那怎么查。
store属性:是否存储。有两张表,一个是上面提到的索引表,还有一个是原始数据表,搜索的是索引表,然后根据相应的id去匹配原始数据表,如果说store是true,那新建数据的时候就会把这个字段的数据存在原始数据表中,如果是false,则不会把数据存起来,原始数据表的对应位置就是空,获取到的内容就是空。
index 为true,store为false 这种操作的意义:我搜索的时候可能需要利用这个字段,但是不一定要展示出来。比如京东商城:我搜索一个商品,在搜索到的商品列表中不会把每个商品的所有内容展示出来,但是我们需要根据商品的相关内容进行搜索。
四、核心数据类型(Core Datetype)
字符串:string,string类型包含 text 和 keyword。
1)text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,但text类型不能用来排序和聚合,所以使用的时候需要结合业务稍稍斟酌一下
2)keyword:该类型不能分词,可以被用来检索过滤、排序和聚合,keyword类型不可用text进行分词模糊检索。
3)数值型:long、integer、short、byte、double、float
4)日期型:date
5)布尔型:boolean
Keyword和text区别:
keyword不会被分词,如果index为true,那就会把整个内容放到索引表中(如果index为true,那就还是会建立索引的);而text类型会被分词放到索引表中。比如姓名我就感觉不需要分词了,但是地址就需要分词,那就可以指定姓名类型为keyword,而地址类型为text。
遗留问题:

这里match可以查到,说是因为这句话可能是个整体,那么为什么之前类型为text的时候,使用iterm查不到呢,按理来说如果拆词的时候整体也是个词的话那么就算类型为text,那存索引的时候整句话也会存在于索引中啊?
解答:使用match查询keyword类型的字段时,因为keyword类型的字段在存入时就不会分词,所以如果使用match查询内容的话,那么被搜索的内容肯定会分词,一旦分词就不会匹配到keyword类型字段的内容,如果match的整体内容和keyword的索引全匹配也会被搜到。如图中keywork类型的字段book中的内容为“elastic...”,而match中的内容也是“elastic...”,则就会被搜到。如果match内容为“elastic...”中的某个词语,那肯定就不会被搜到了。
五、对已存在的mapping映射进行修改
正常情况下已经创建好的mapping是不能被修改的。
具体思路:如果想要修改,则需要建一个全新的索引库,然后设置你的期望的mapping,将原索引库的数据导入到新的索引库中来。
具体方法:
1)如果要推倒现有的映射, 你得重新建立一个静态映射索引
2)然后把之前索引里的数据导入到新的索引里
_reindex时,会把source的索引库中的数据导入到dest的索引库中,如果source索引库和dest索引库的有相同的id,则会覆盖dest相同id的数据。
3)删除原创建的索引
4)为新索引起个别名, 为原索引名
POST _reindex
{
"source": {
# 原索引库
"index": "db_index"
},
"dest": {
# 目标索引库
"index": "db_index_2"
}
}
# 删除原索引库
DELETE /db_index
# 别名指向
PUT /db_index_2/_alias/db_index因为是先建立索引,并制定mapping,属于静态映射,注意相同字段的类型要兼容,如果你原数据name字段是字符串,而你新的索引库的name字段变成了long类型,这样是不被允许的,会报错。我测试了一下,好像如果能强转成功的话,是允许的,比如字符串中存在都是数字类型的字符串“333”,“34”。
如果是全新的索引,没有提前设置mapping等信息,只是单纯的想复制数据,那就相当于动态映射,你就算原数据有的name是String,有的文档的name是long(这种情况的话那原索引库也是动态映射),那都没有问题,那没有什么需要考虑的,但是这样好像没有业务会这样用,毕竟我们要服务于业务。
别名什么时候都可以指向,也可以将多个索引库指向相同的别名,如果查询的时候使用别名查询,会同时去两个索引库中查询数据,并返回两个索引库命中的数据。指向相同别名的索引库互不影响。一般也不会这么干,只有在想变更mapping映射信息的时候为了无缝切换、零停机才会这样做。
别名相关操作:
1)添加别名
POST _aliases
{
"actions" : [
{"add" : {"index" : "school" , "alias" : "in1"}}
]
}
POST _aliases
{
"actions" : [
{"add" : {"index" : "student" , "alias" : "in1"}}
]
}2)查询别名
GET school/_alias/*返回结果:

3)删除别名
POST /_aliases
{
"actions": [
{"remove": {"index": "school", "alias": "in1"}}
]
}4)修改别名
es没有修改别名的操作,只能先删除后添加
POST _aliases
{
"actions" : [{"remove" : {"index" : "student" , "alias" : "in1"}}],
"actions" : [{"add" : {"index" : "student" , "alias" : "in2"}}]
}六、Elasticsearch乐观并发控制
在数据库领域中,有两种方法来确保并发更新,不会丢失数据:
1、悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
2、乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。(mysql乐观锁:加版本)
(es新老版本适用乐观锁的方式不一样)
老版本(7.x之前的版本):通过version来控制
PUT /db_index/_doc/1?version=1
{
"name": "Jack",
"sex": 1,
"age": 25,
"book": "Spring Boot 入门到精通",
"remark": "hello world"
}ES新版本(7.x)不使用version进行并发版本控制 if_seq_no=版本值&if_primary_term=文档位置
1)_seq_no:文档版本号,作用同_version,但是他们意义不同。version属于某个文档,而seq_no属于整个index。如果操作一个文档,他的version和seq_no都会变化,如果操作另一个文档,则另个文档的seq_no会紧接着上一次的变化进行变化,递增,无论上一次的操作是否是当前文档,类似于数据库的id。
2)_primary_term:文档所在位置,和_seq_no一样是一个整数,每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。
_primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,比如当一个shard宕机了,replica需要用到最新的数据,就会根据_primary_term和_seq_no这两个值来拿到最新的document。
POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1
{
"doc": {
"name": "test1"
}
}
#如果上面执行完了,紧接着执行下面的命令会修改失败,因为数据的版本(seq_no)已经变更了
POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1
{
"doc": {
"name": "test2"
}
}七、集群搭建:
1.集群搭建
把单机步骤搬过来即可,只需要稍微修改即可。
只需要修改elasticSearch.yml中的:
cluster.name 集群名称要保持一样
node.name 节点名称要修改
# discovery.seed_hosts 这样才会相互发现
discovery.seed_hosts: ["IP1","IP2","IP3"]
cluster.initial_master_nodes: ["节点1名称","节点2名称","节点3名称"]
查看集群状态:
GET _cat/nodes?v
GET _cat/health?v注意:
1.如果是直接拷贝的node1的elasticsearch安装文件夹的话,在启动之前,先删除每个拷贝节点的es安装目录下data文件夹下的nodes文件夹
2.可能有时需要开通各个节点内网端口号:9200,否则可能三个节点互相访问不了。本人是使用的阿里云的服务器,按理来说在内网中应该是互通的。
2.集群状态
1)如何快速了解集群的健康状况?green、yellow、red?
如果使用Elasticsearch-head插件,集群状态会有green(健康)、yellow(警告)、red(异常)三种颜色。
- green:每个索引的primaryshard和replicashard都是active状态的
- yellow:每个索引的primaryshard都是active状态的,但是部分replicashard不是active状态,处于不可用的状态
- red:不是所有索引的primaryshard都是active状态的,部分索引有数据丢失了
2)集群什么情况会处于一个yellow(警告)状态?
假设现在就一台linux服务器,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配1个primary shard和1个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
测试:启动第二个es进程,就会在es集群中有2个node,然后那1个replica shard就会自动分配过去,然后cluster status就会变成green状态。
八.Elasticsearch-head插件
由于es服务启动之后,访问界面比较丑陋,为了更好的查看索引库当中的信息(像navicat一样可以看到有哪些库,库中有哪些数据),我们可以通过安装elasticsearch-head这个插件来实现,这个插件可以更方便快捷的看到es的管理界面。
elasticsearch-head这个插件是es提供的一个用于图形化界面查看的一个插件工具,可以安装上这个插件之后,通过这个插件来实现我们通过浏览器查看es当中的数据
安装elasticsearch-head这个插件需要下载源码包进行编译,耗时比较长,网络较差的情况下,基本上不可能安装成功。要安装elasticsearch-head插件,需要先安装Node.js。
安装后访问elasticsearch-head界面 http://ip:port/,这里不在赘述安装步骤,可以自行去网上搜索,只需要知道这个插件即可。
PS:仅供学习使用,不对的地方请指教,勿喷