p1 学习大纲

p02数据分析

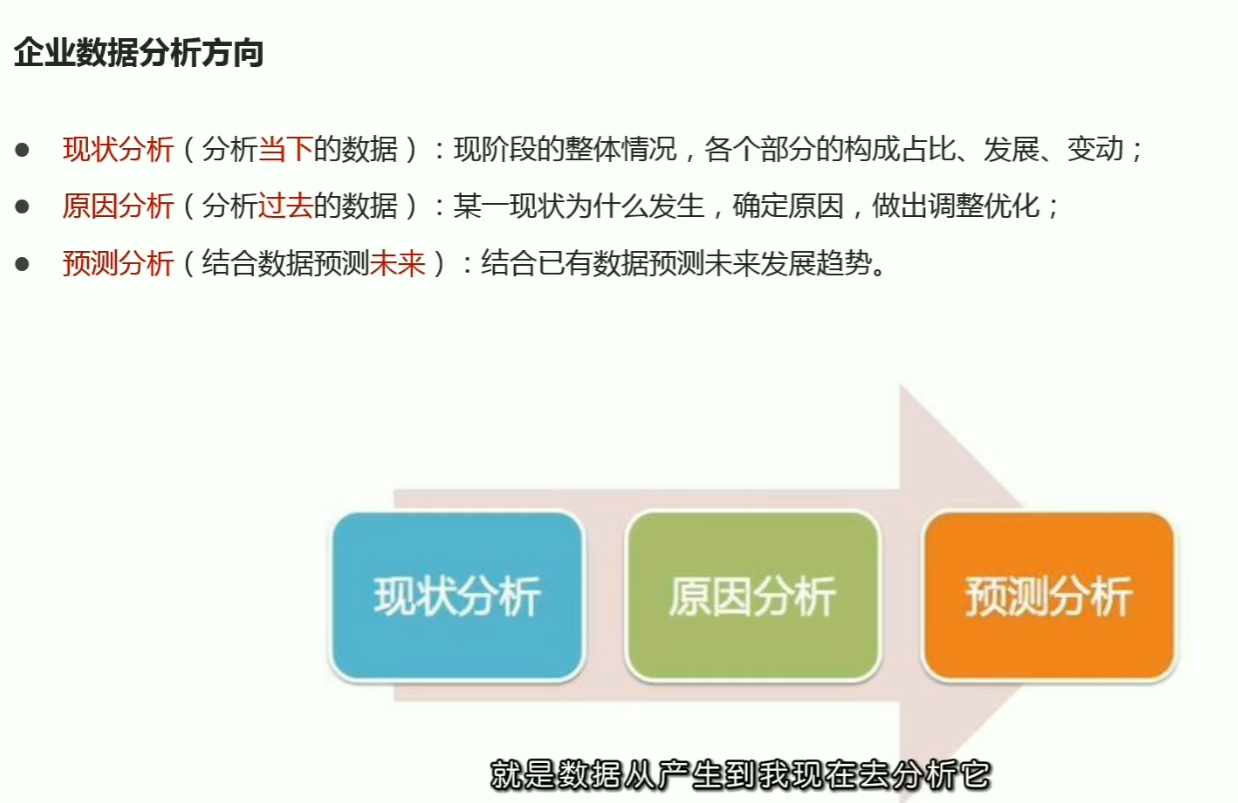
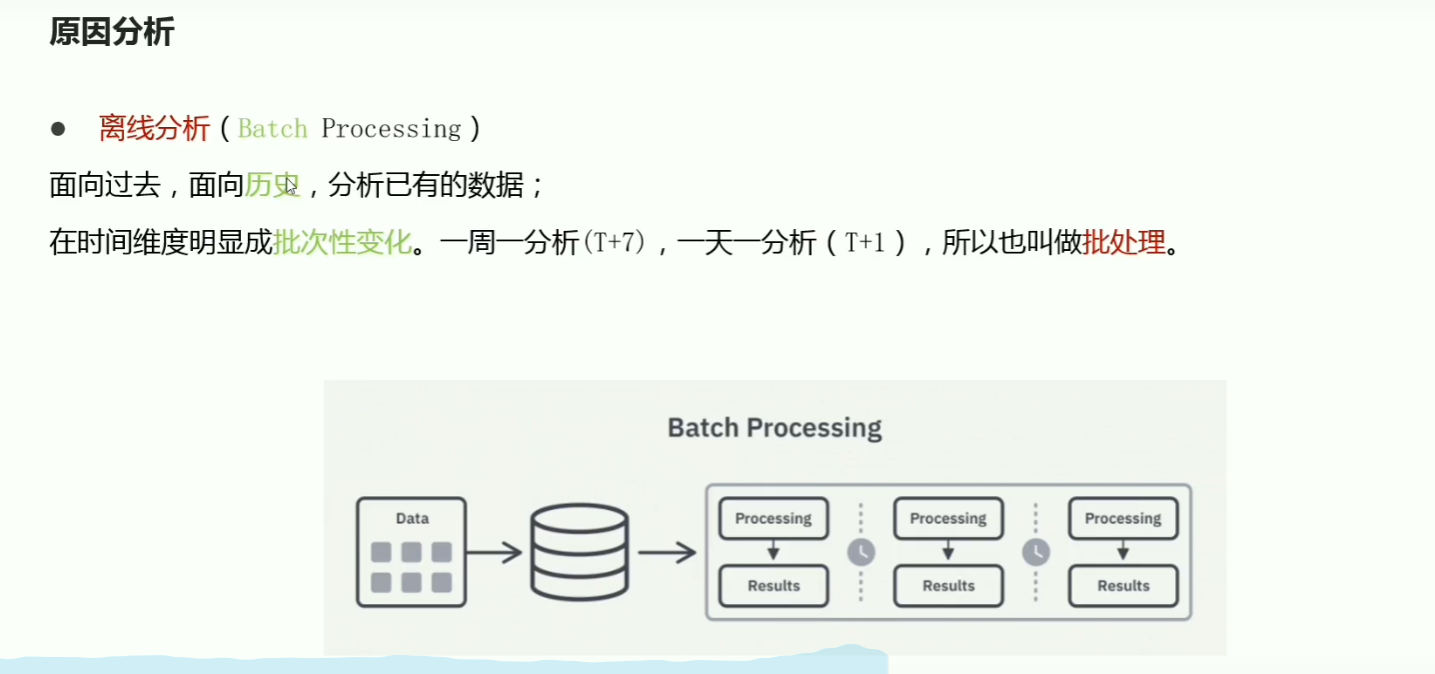
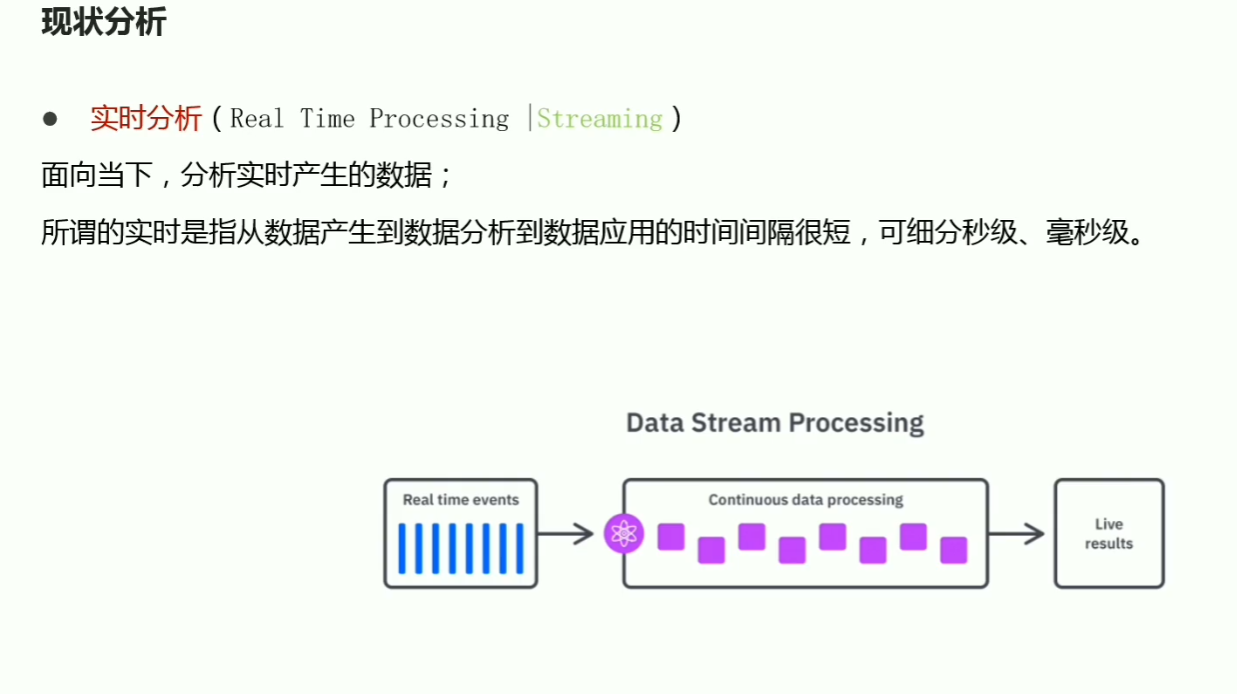
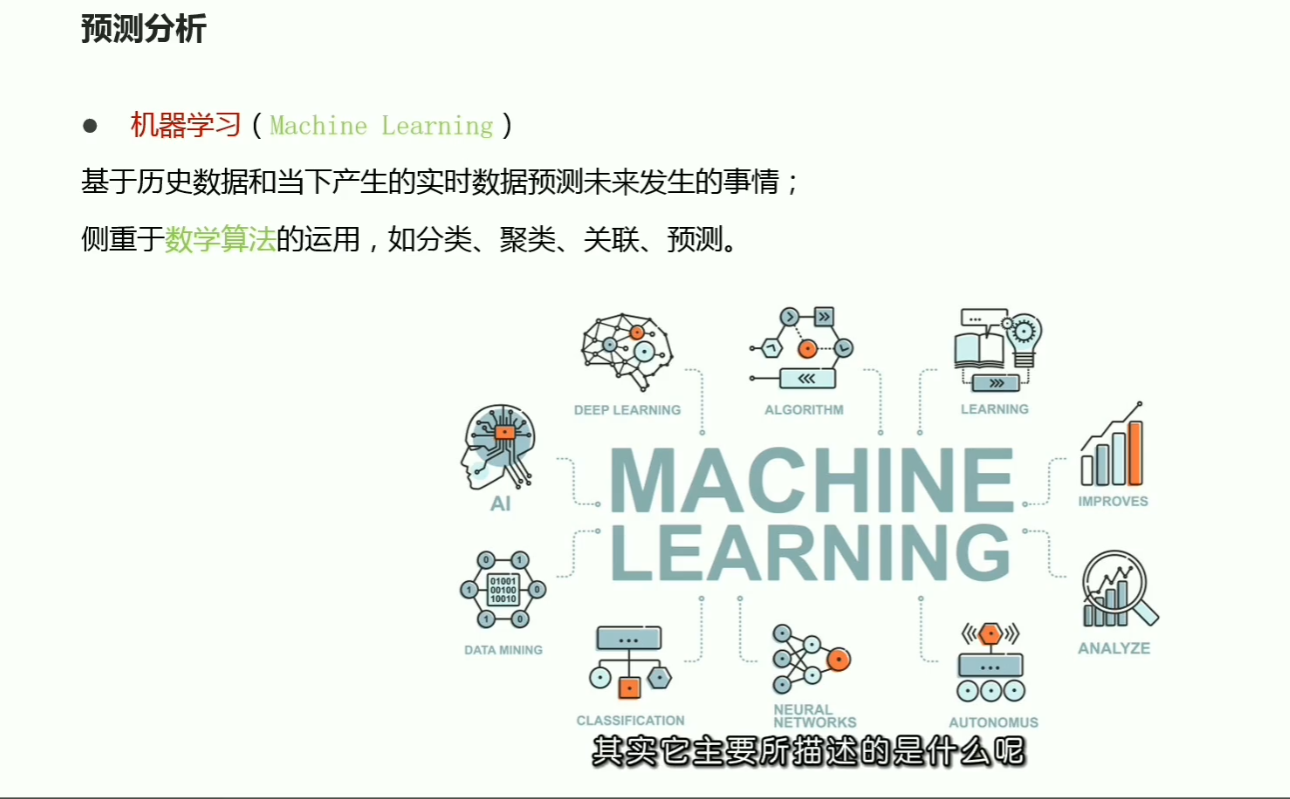
p03数据分析基本流程
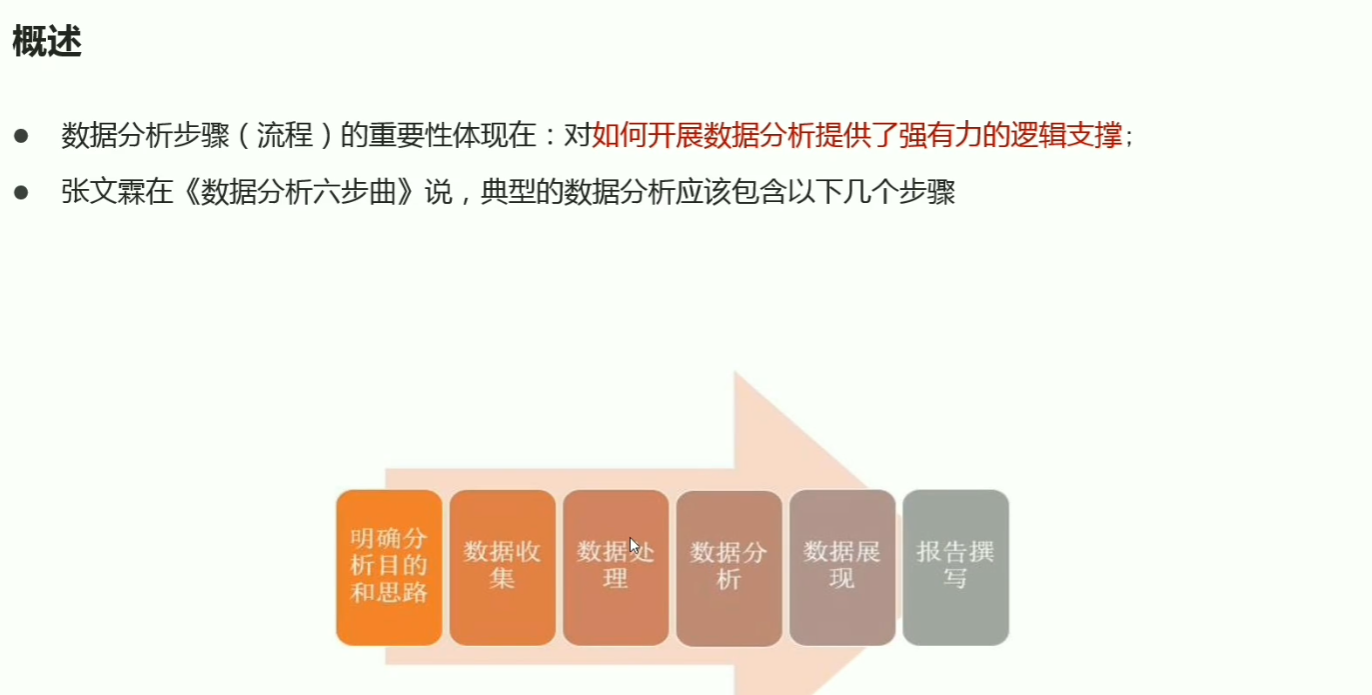






p04大数据时代
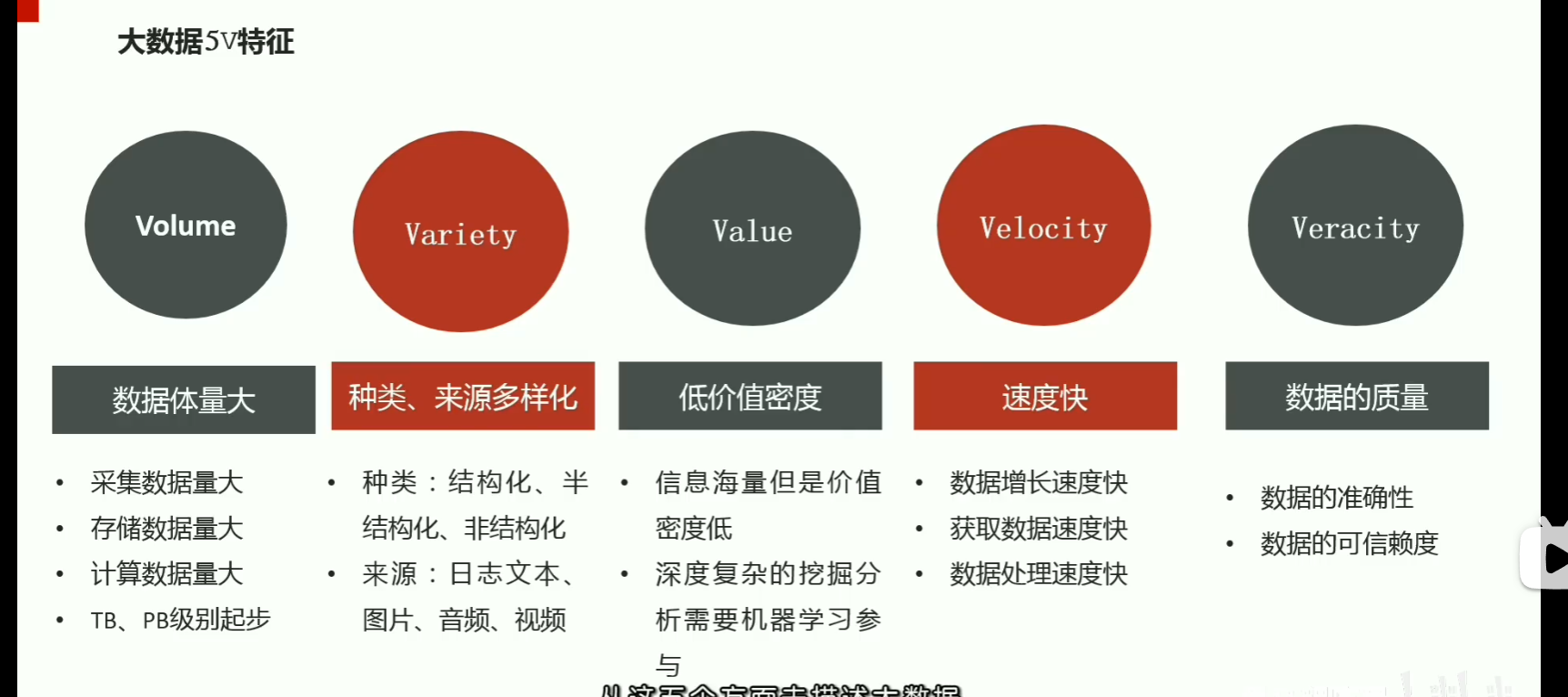
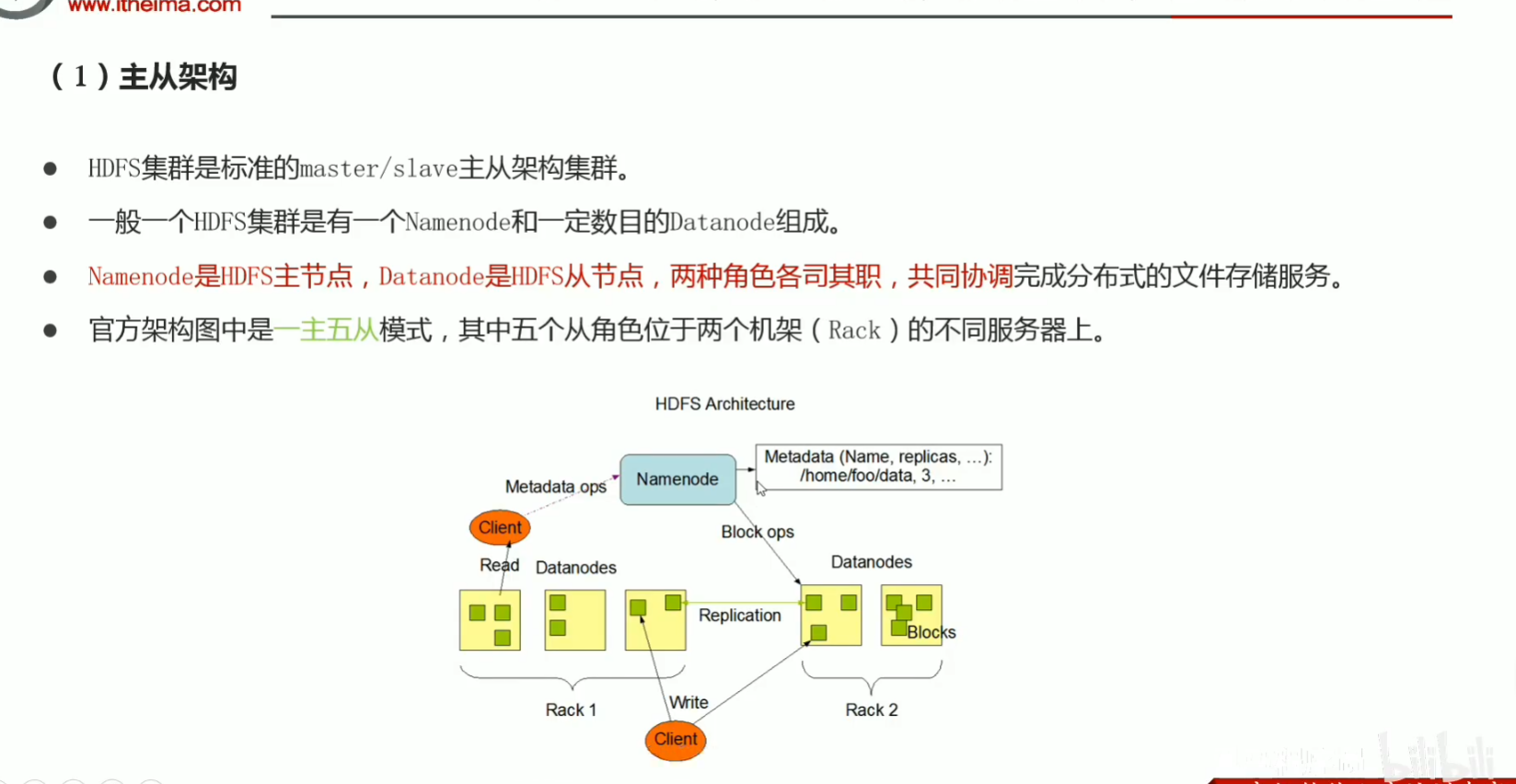
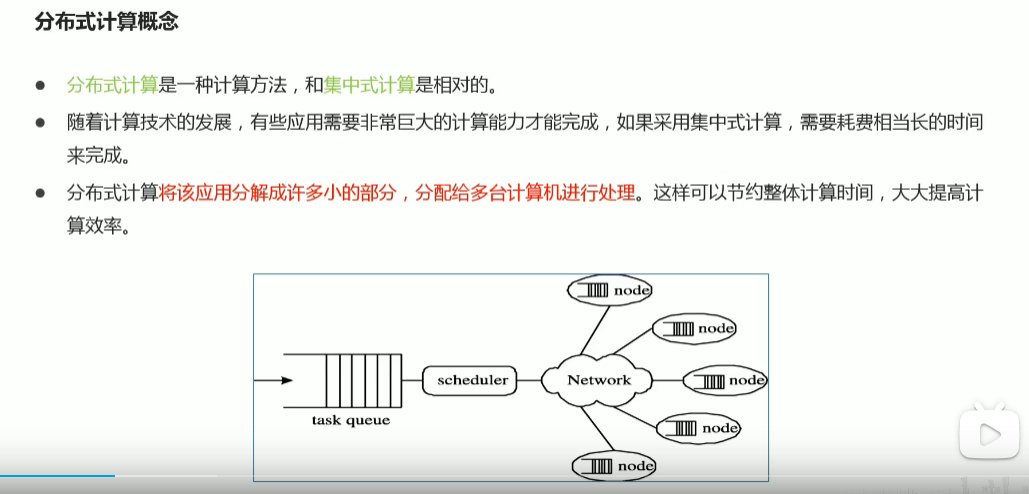
p05分布式和集群概念
p06-14 略
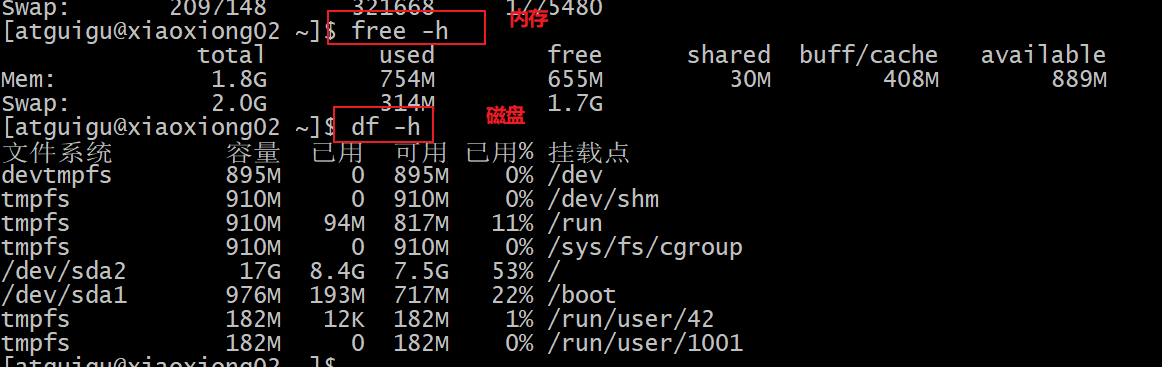
p15 linux命令 时间 内存 磁盘 进程
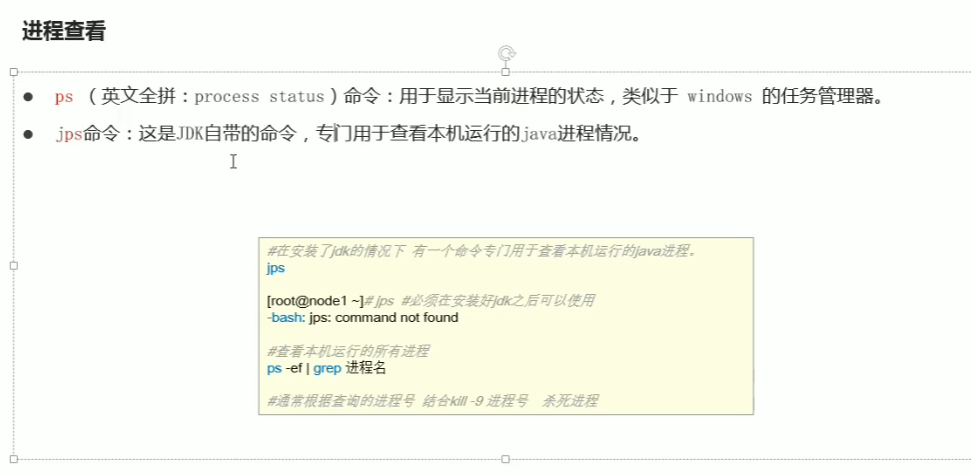
p16略
p17 vim基本操作命令



p18 学习目标


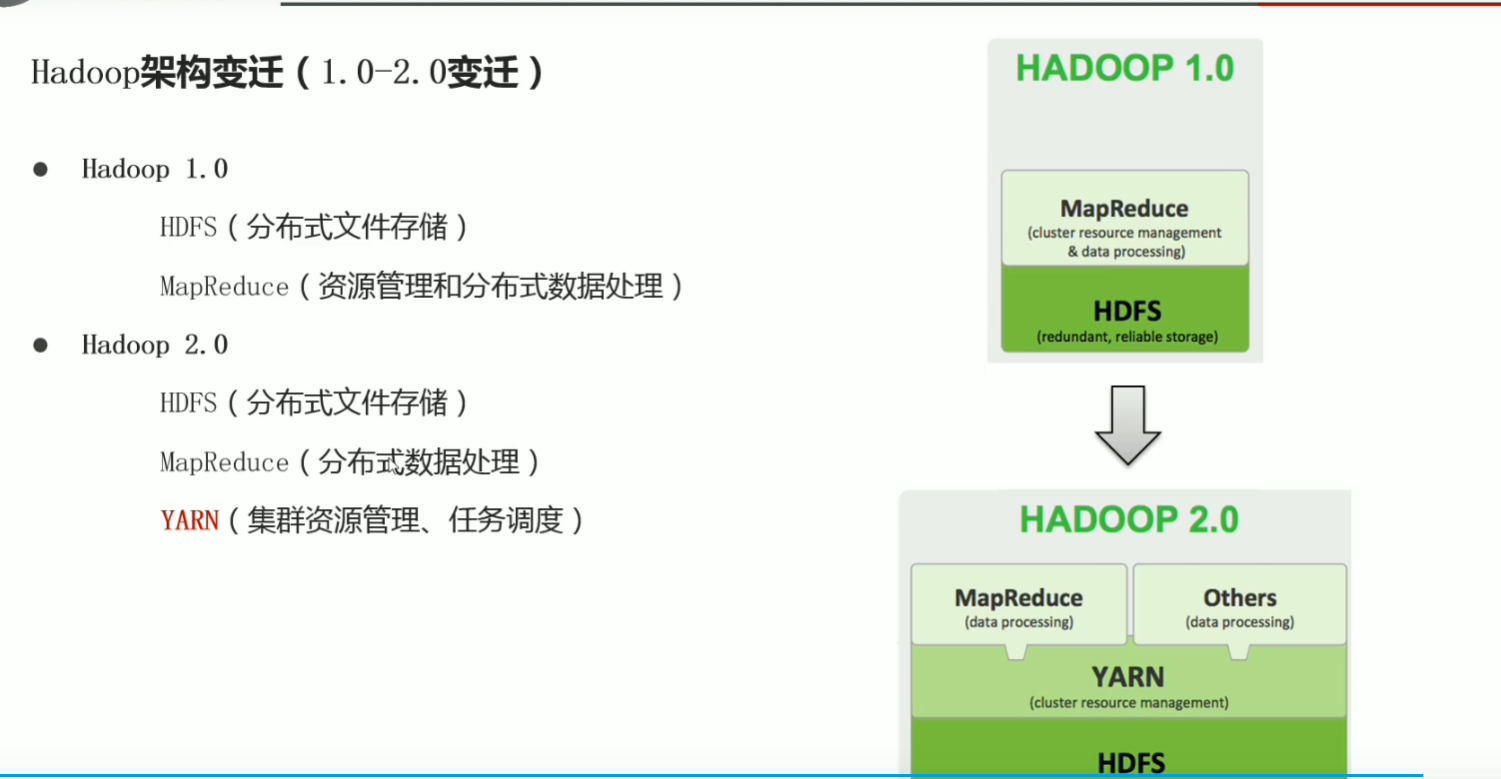
p19hadoop介绍

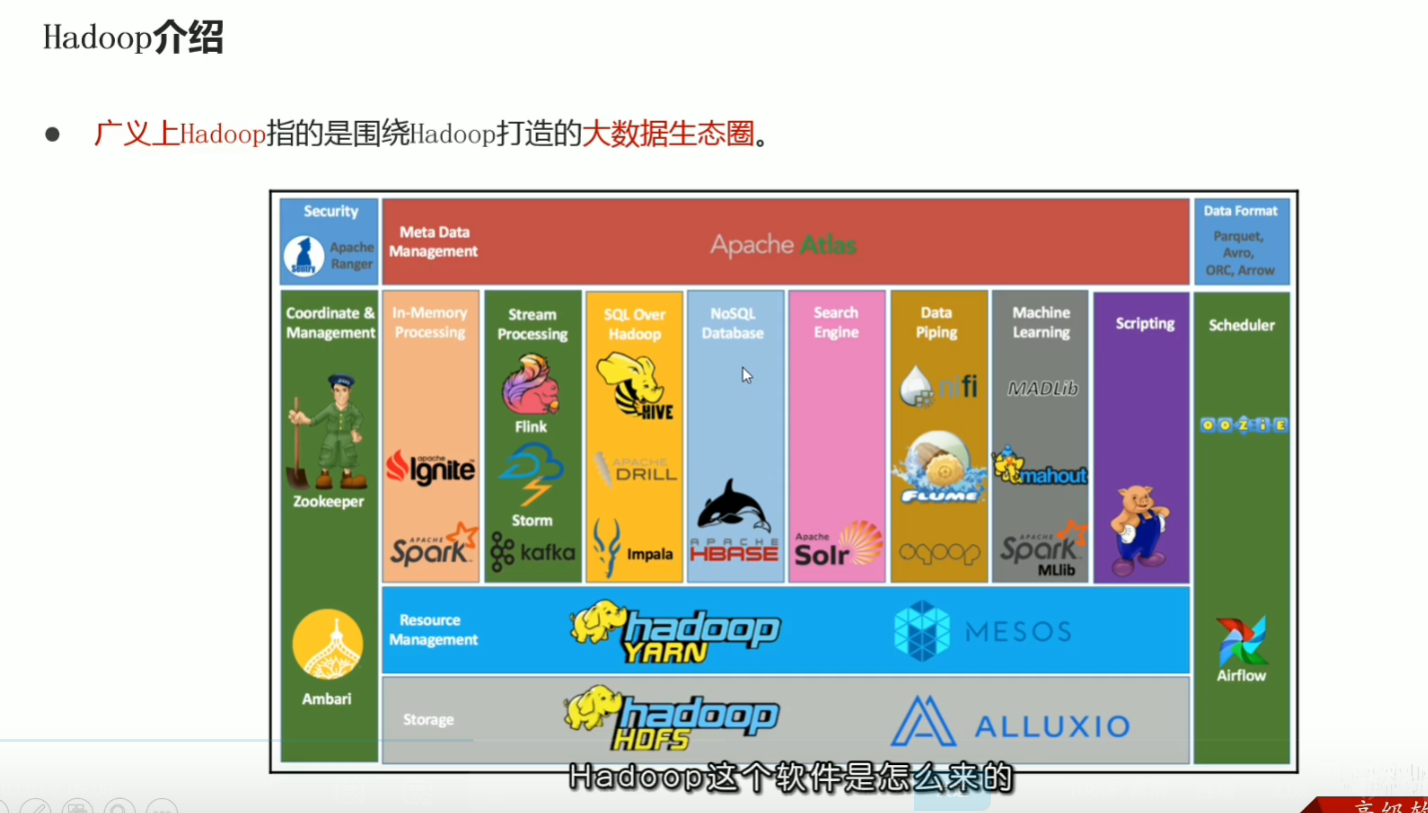
p20 hadoop特性优点
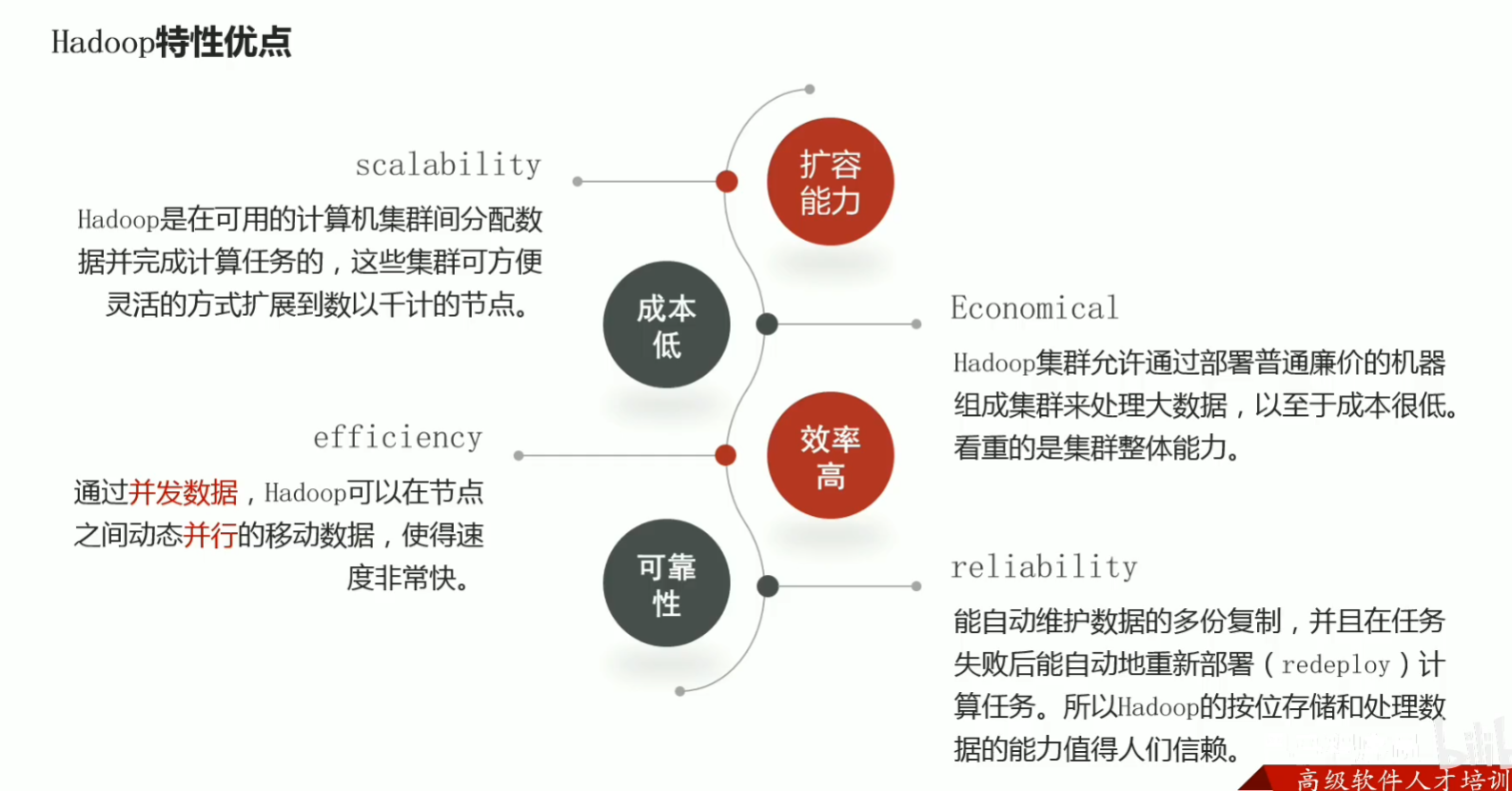
p21 hadoop发行版本

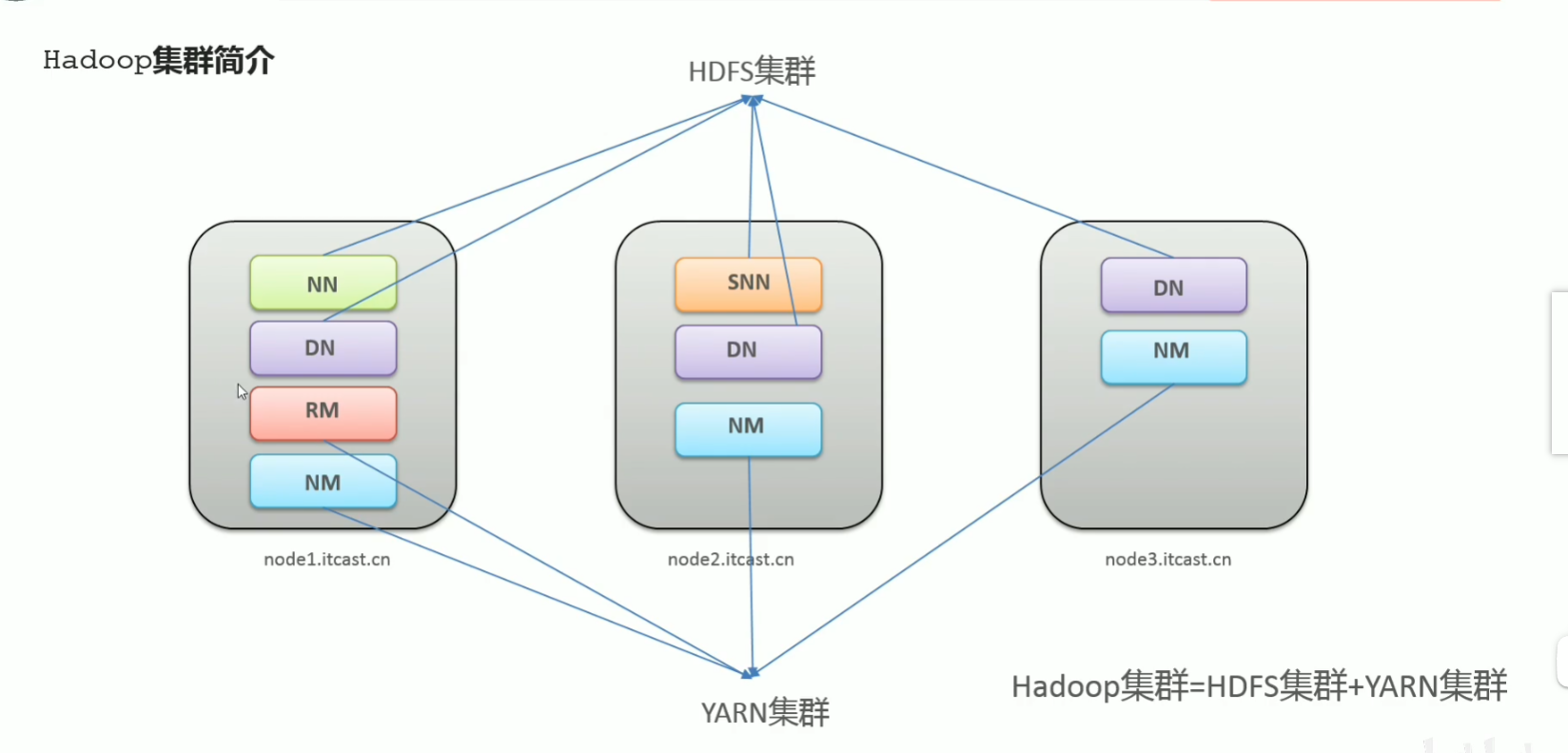
p22 hadoop安装部署 集群组成介绍


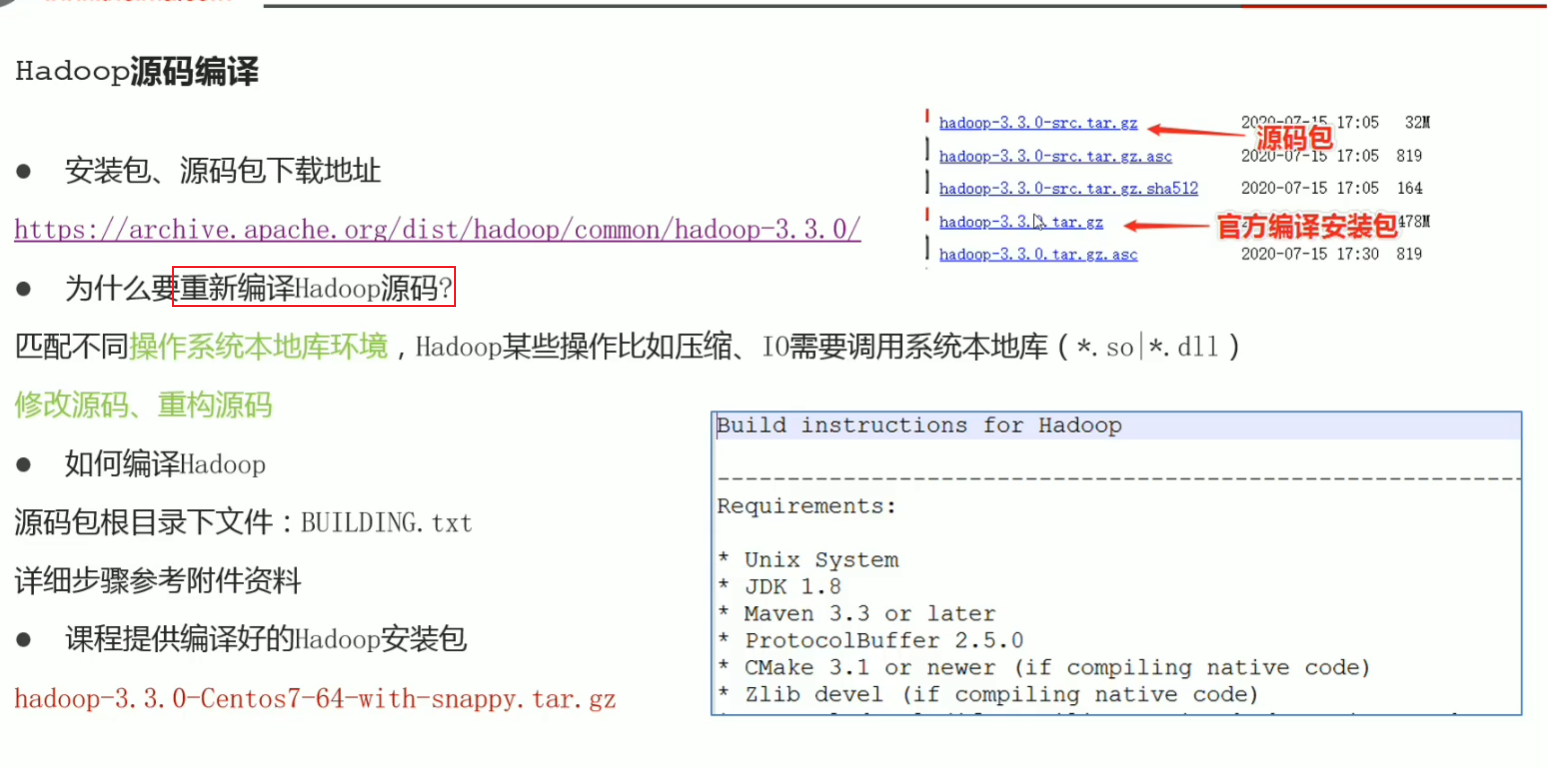
p23 hadoop安装部署-服务器基础环境设置

p28 hadoop安装部署-初体验

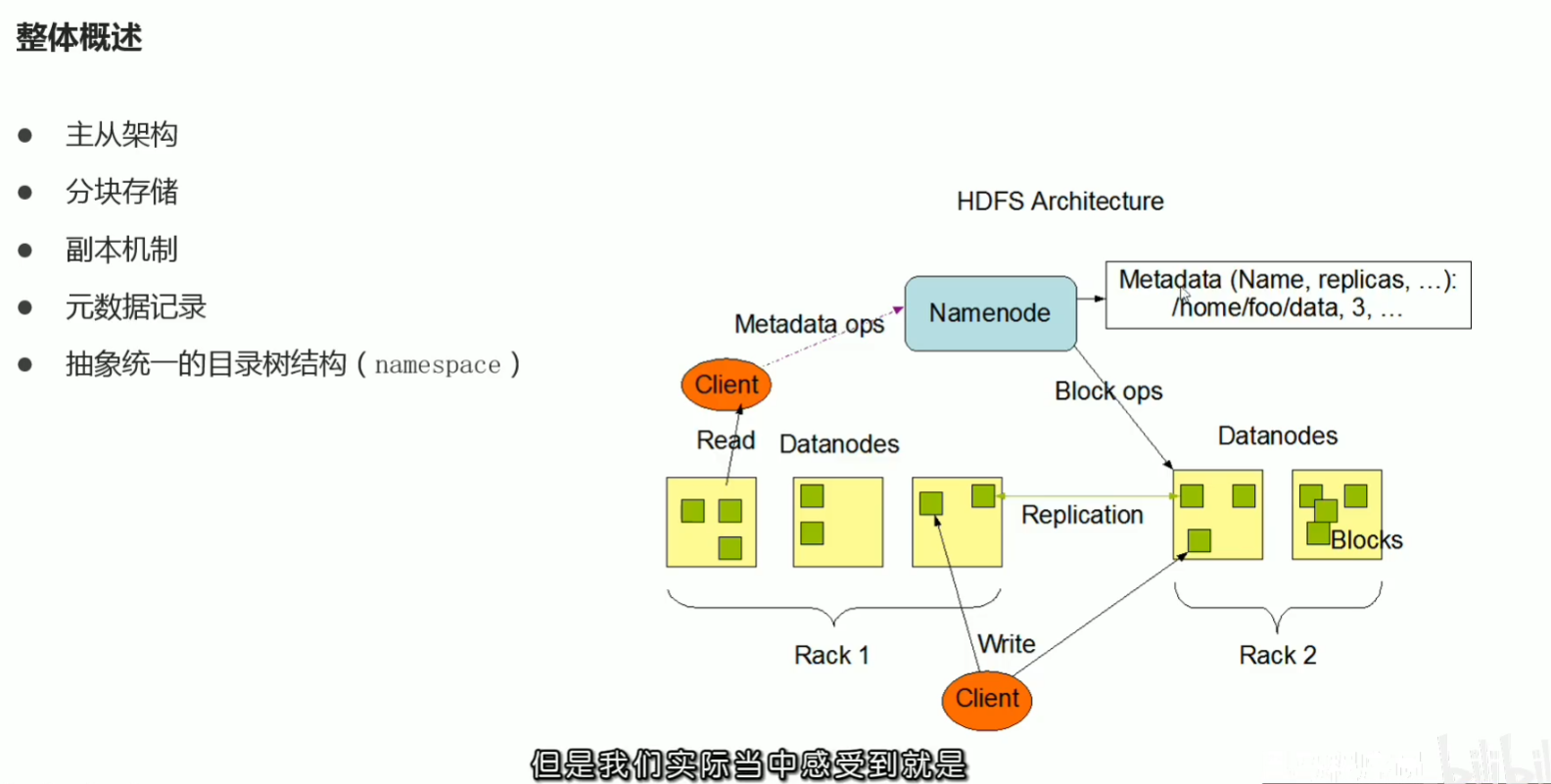
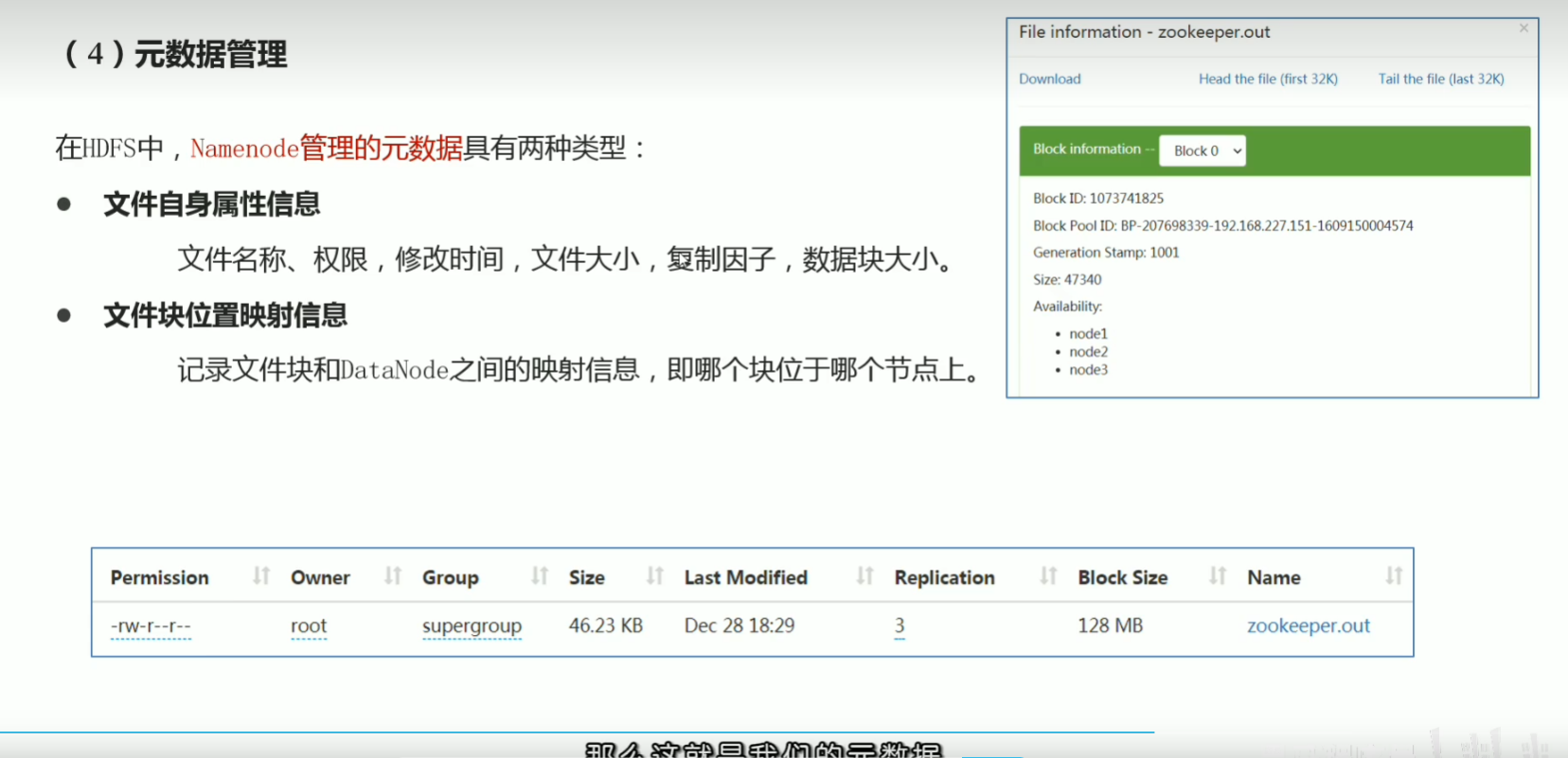
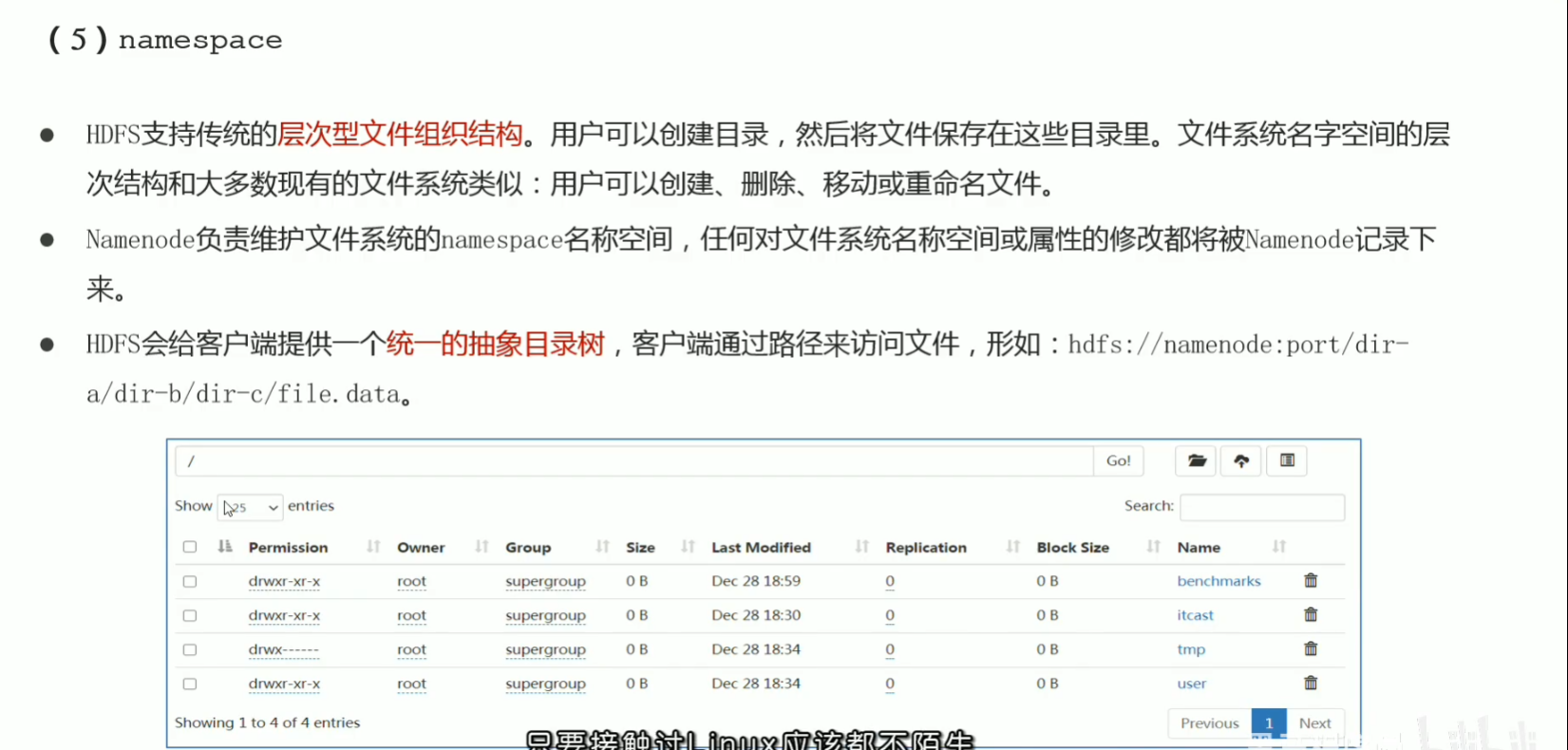
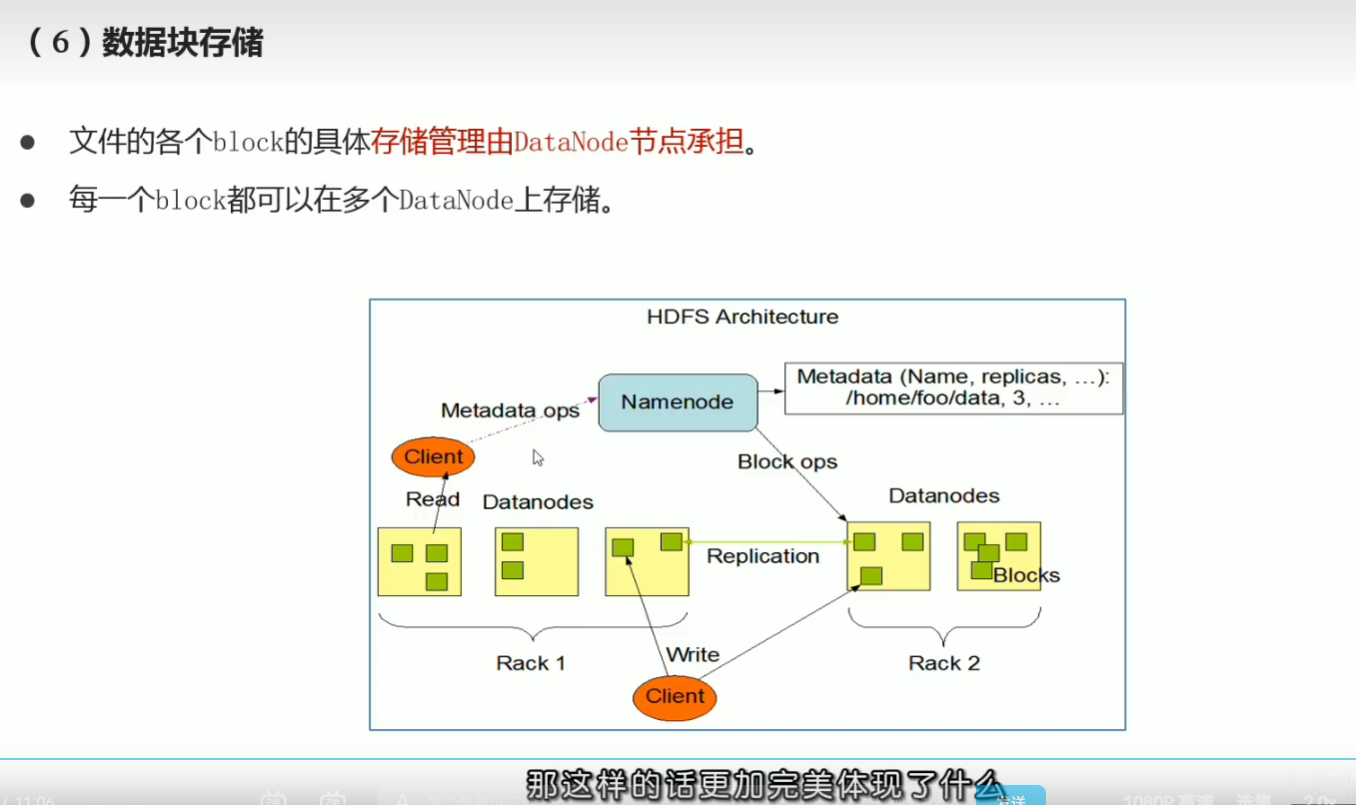
P32 hdfs重要特性解读


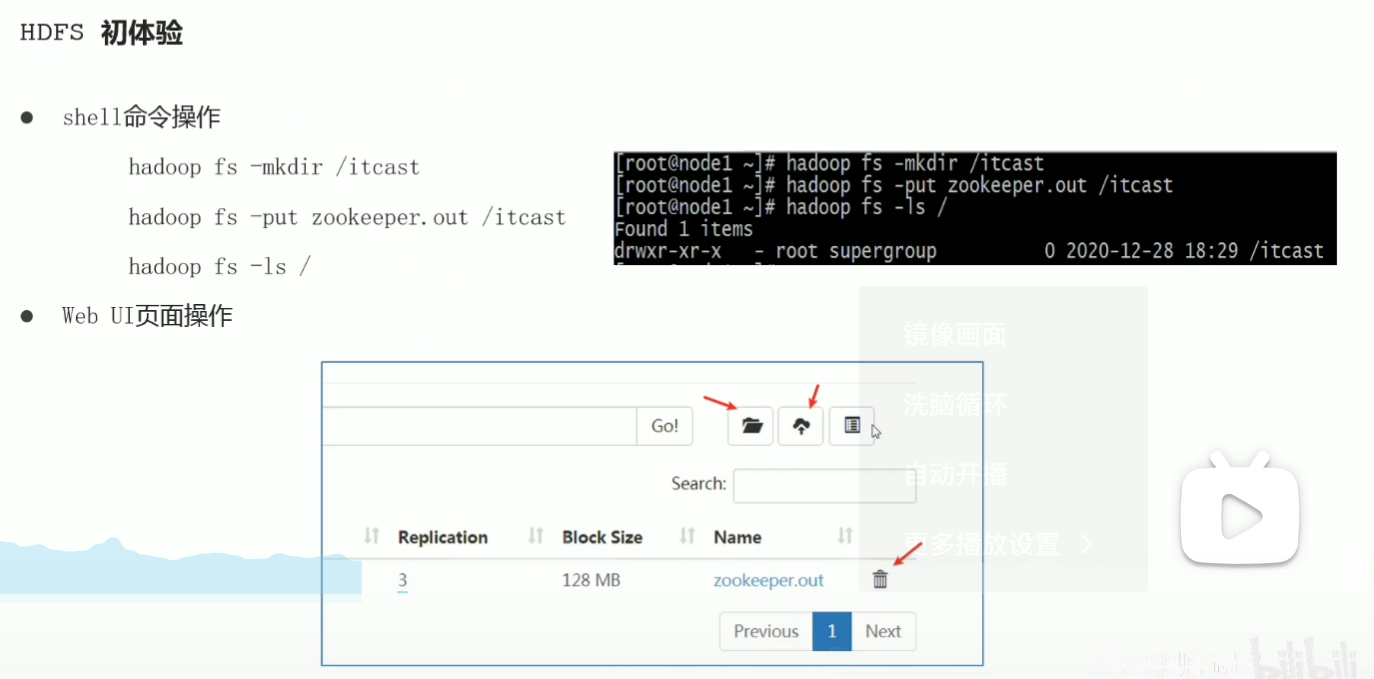
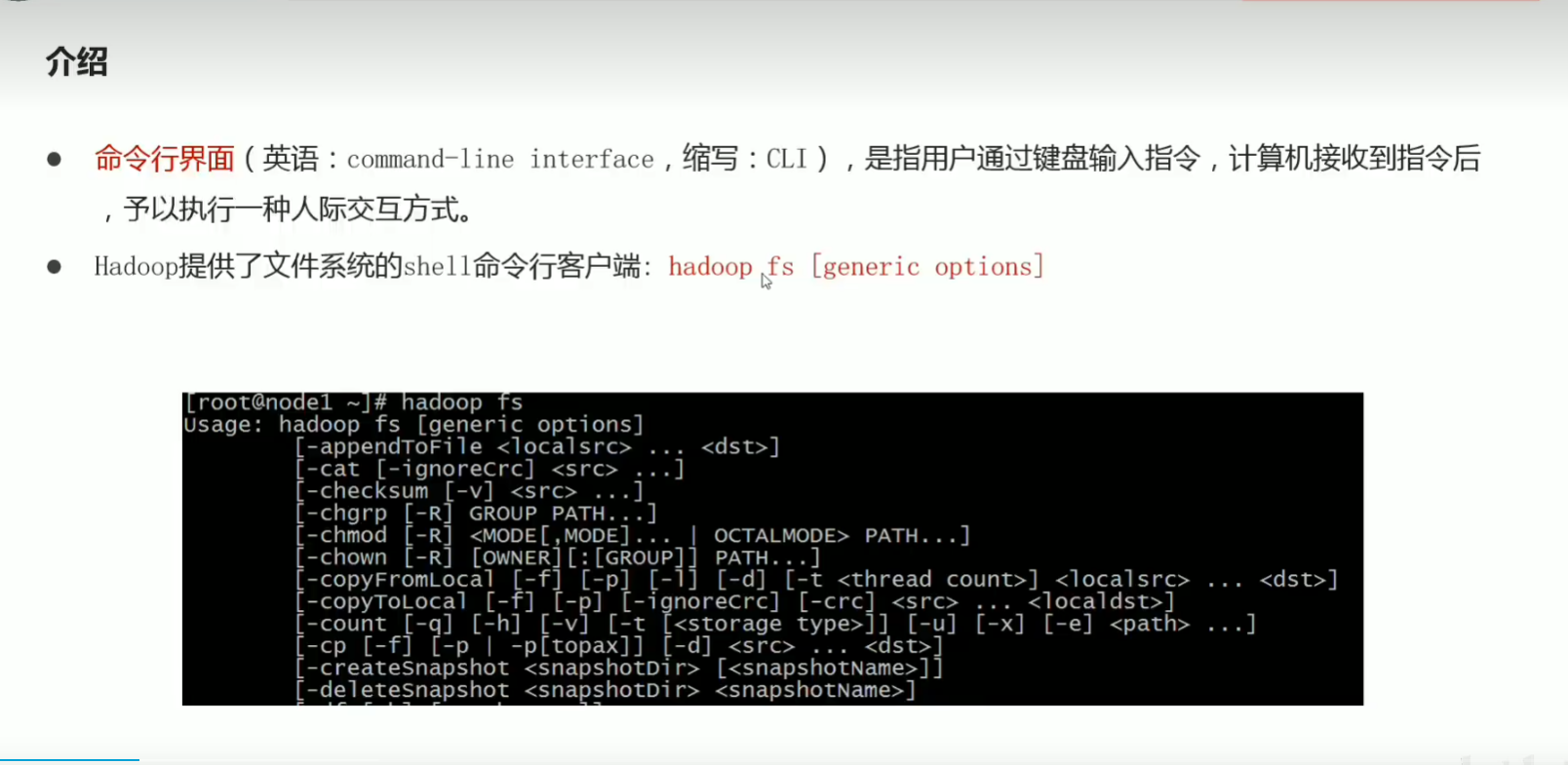
p33 shell命令行解释说明


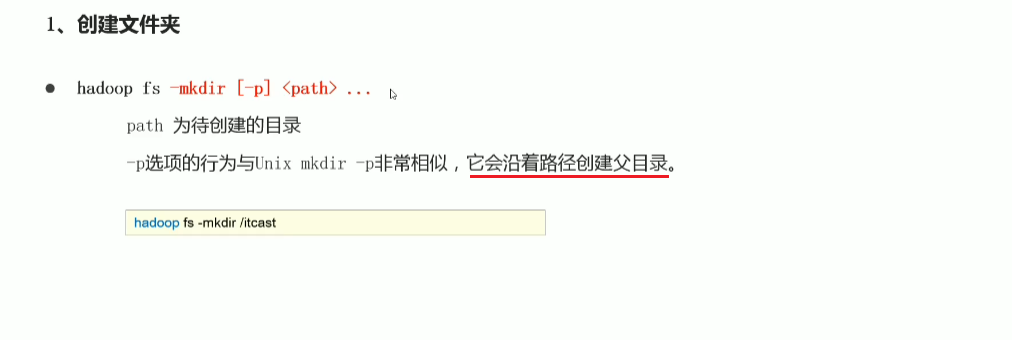
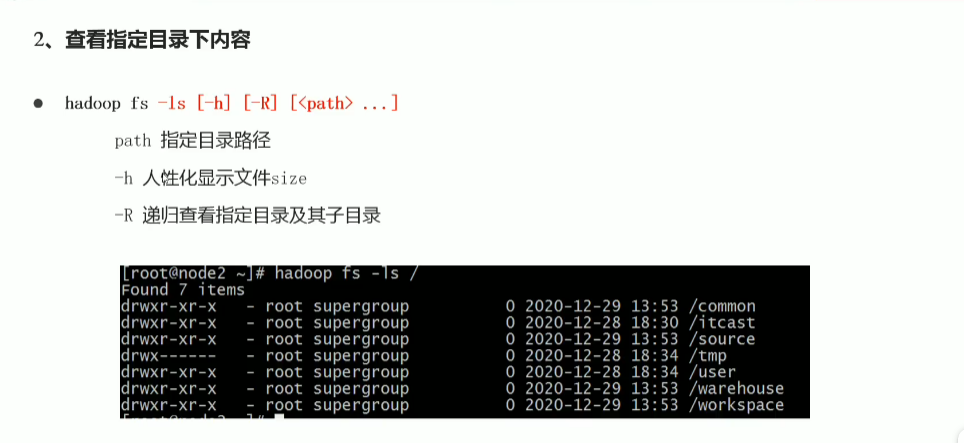
p34 shell命令行常见操作
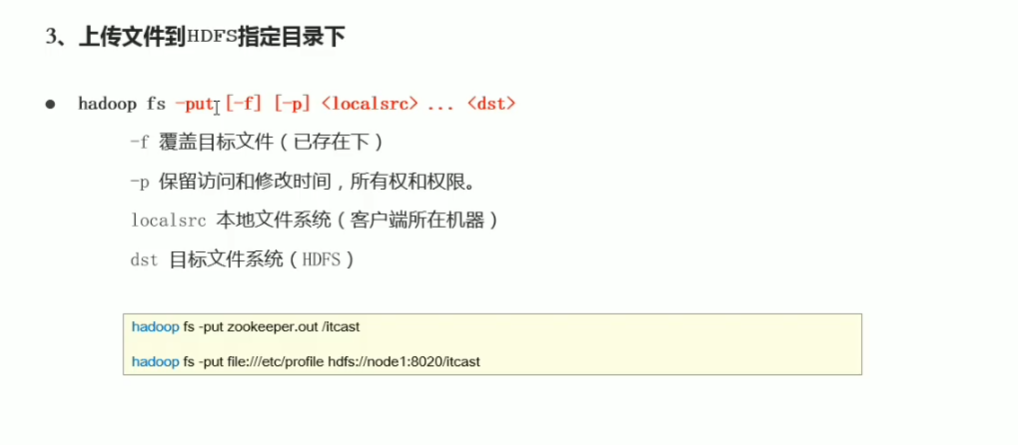

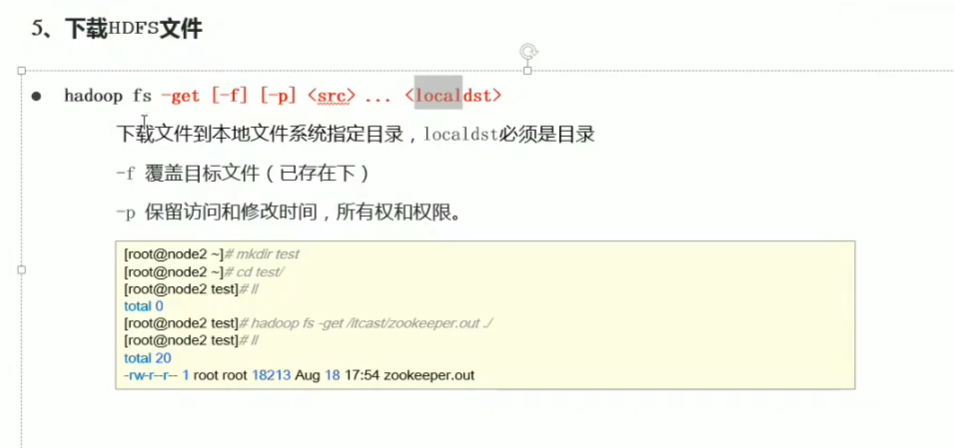
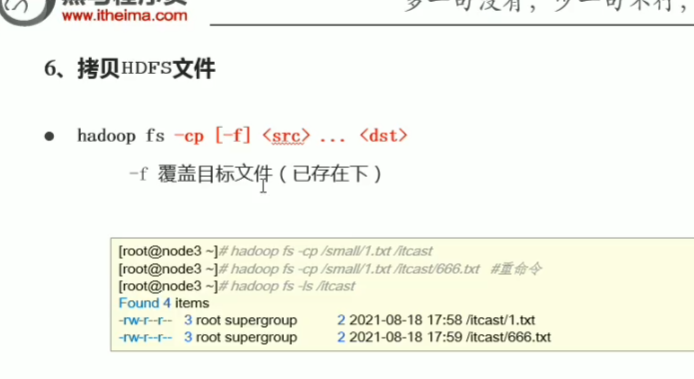
追加文件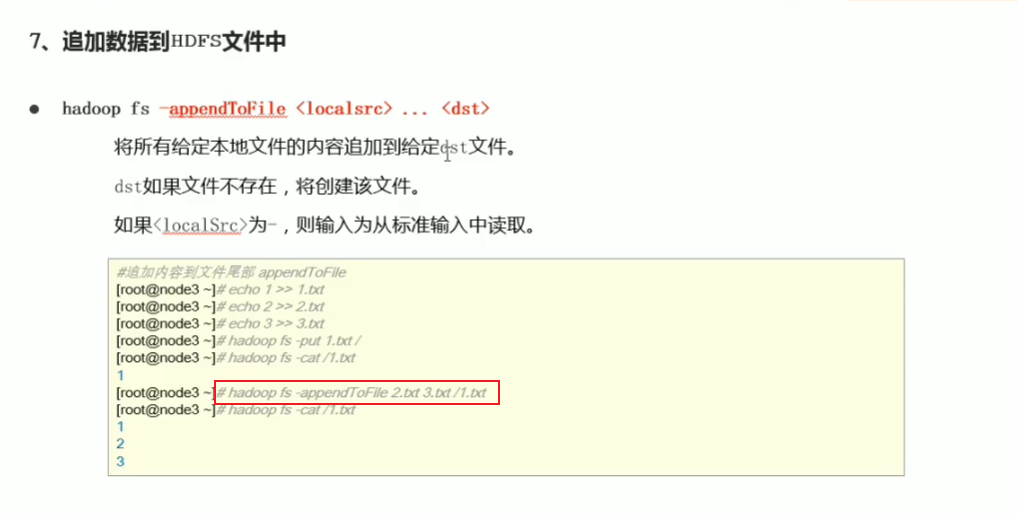

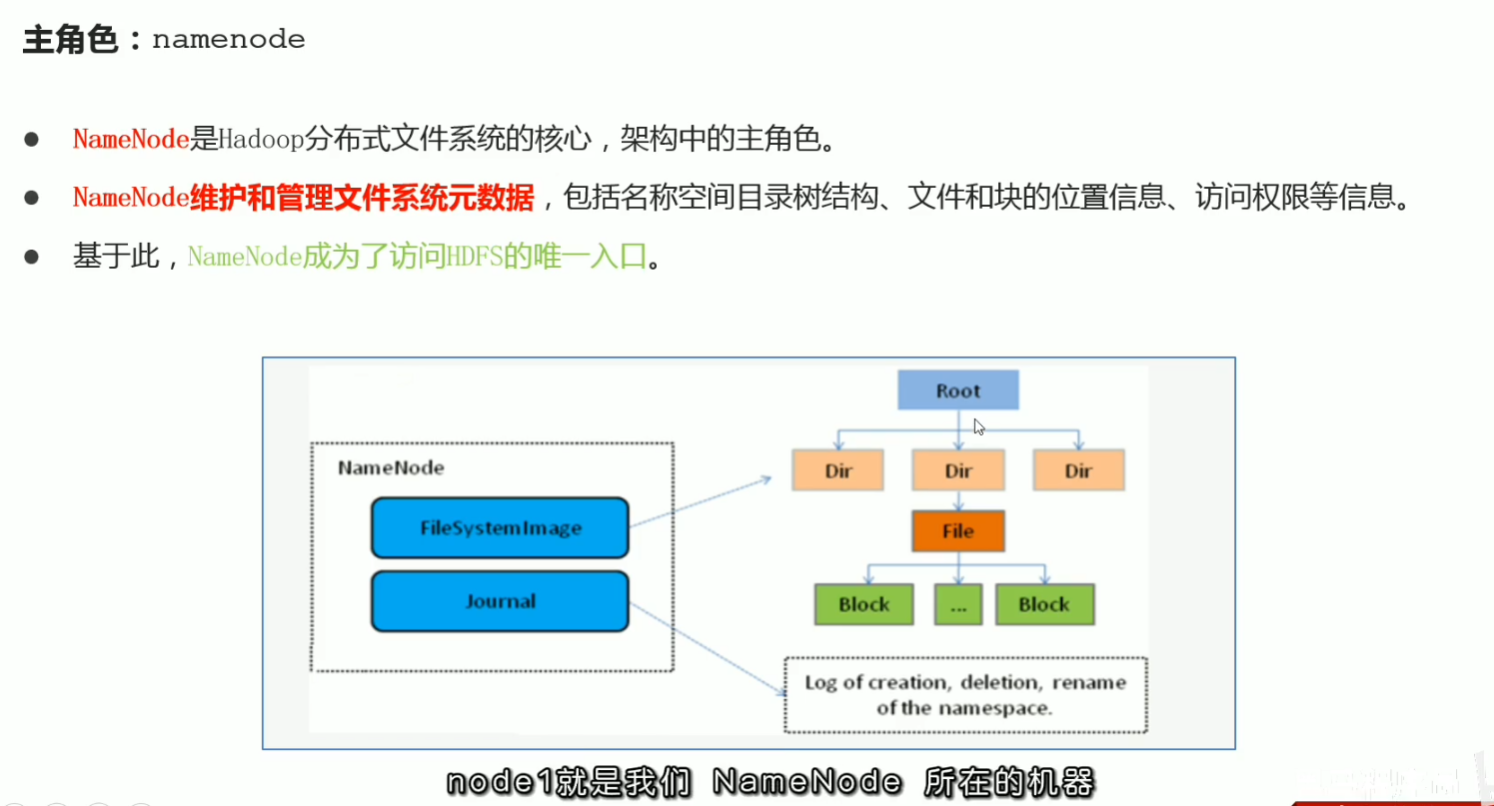
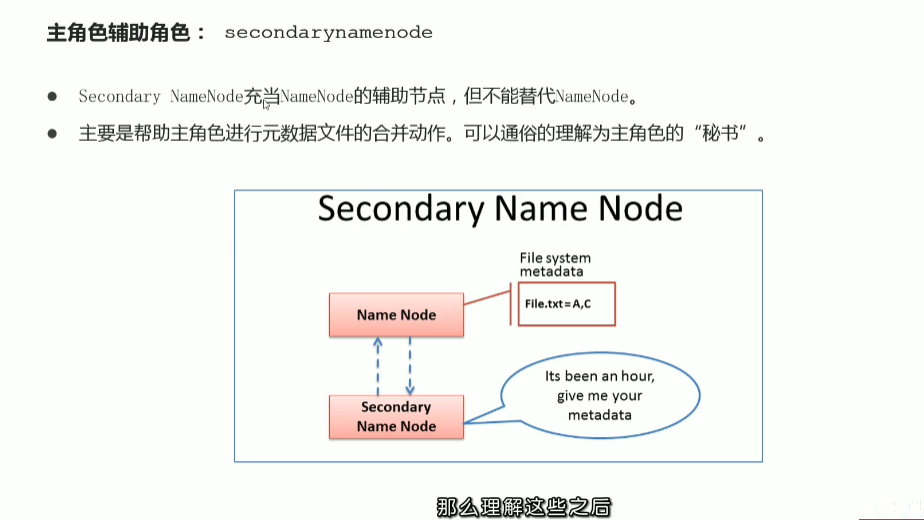
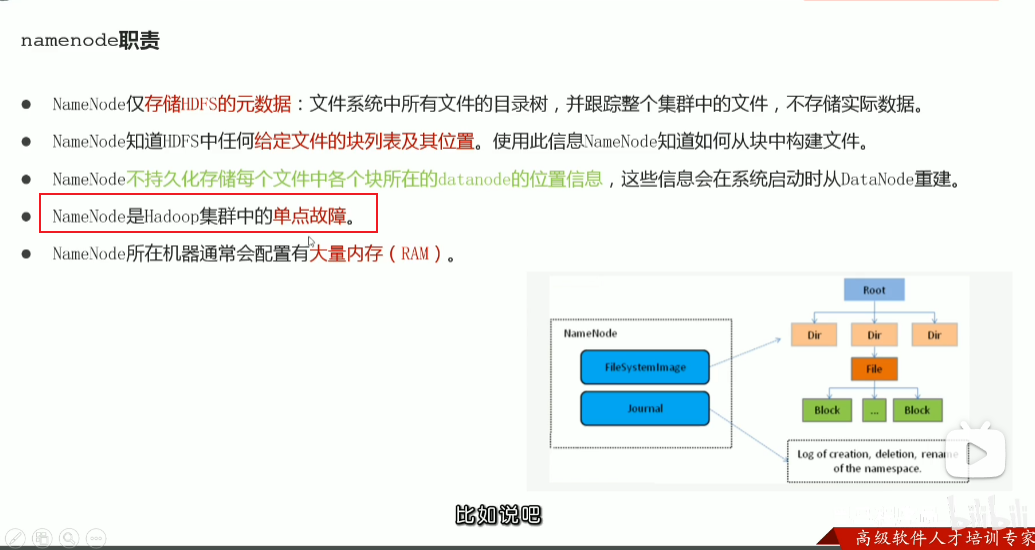
p35 hdfs工作流程与机制–各角色职责介绍与梳理


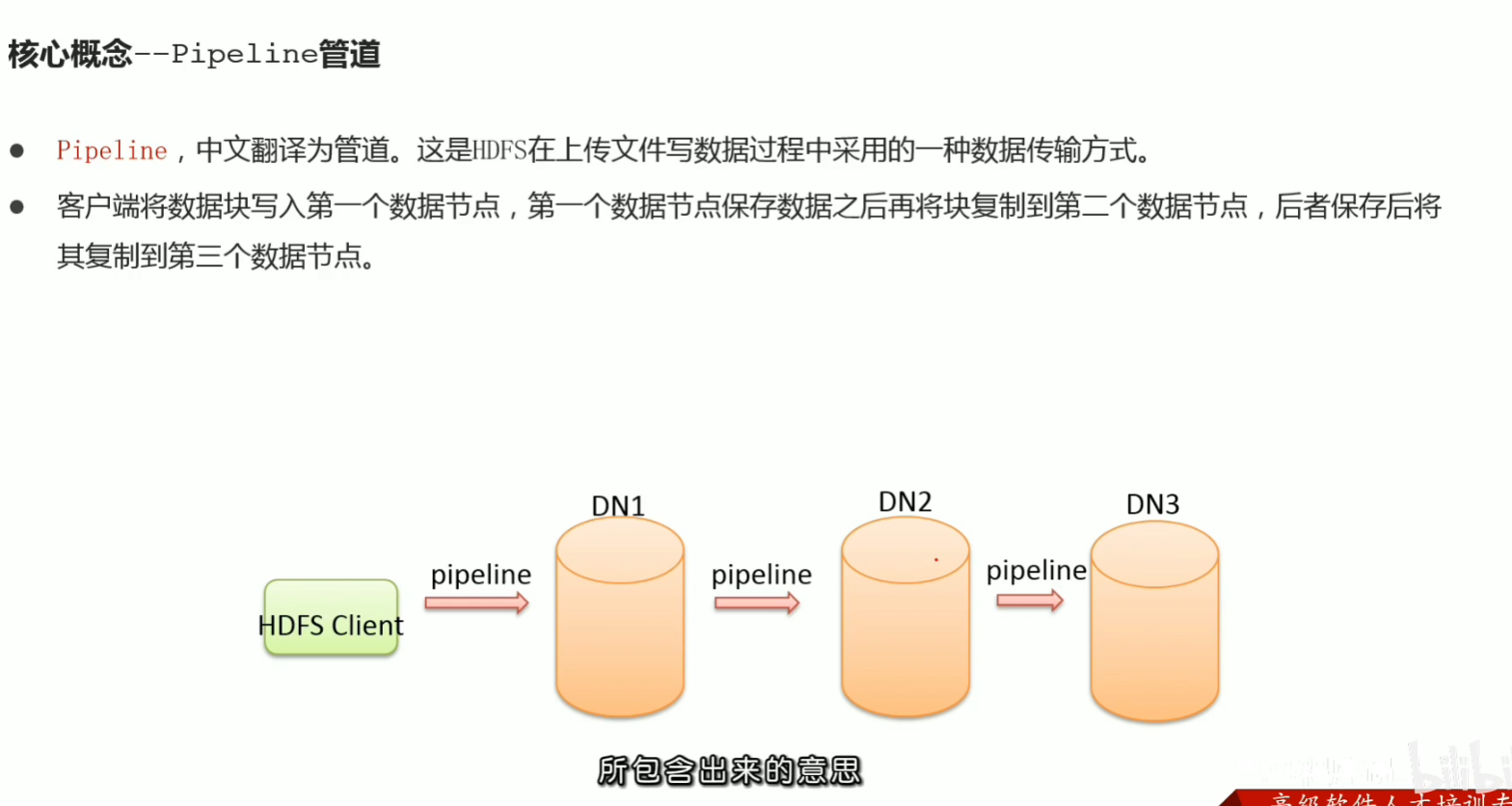
36 写数据流程 pipeline ack 副本机制
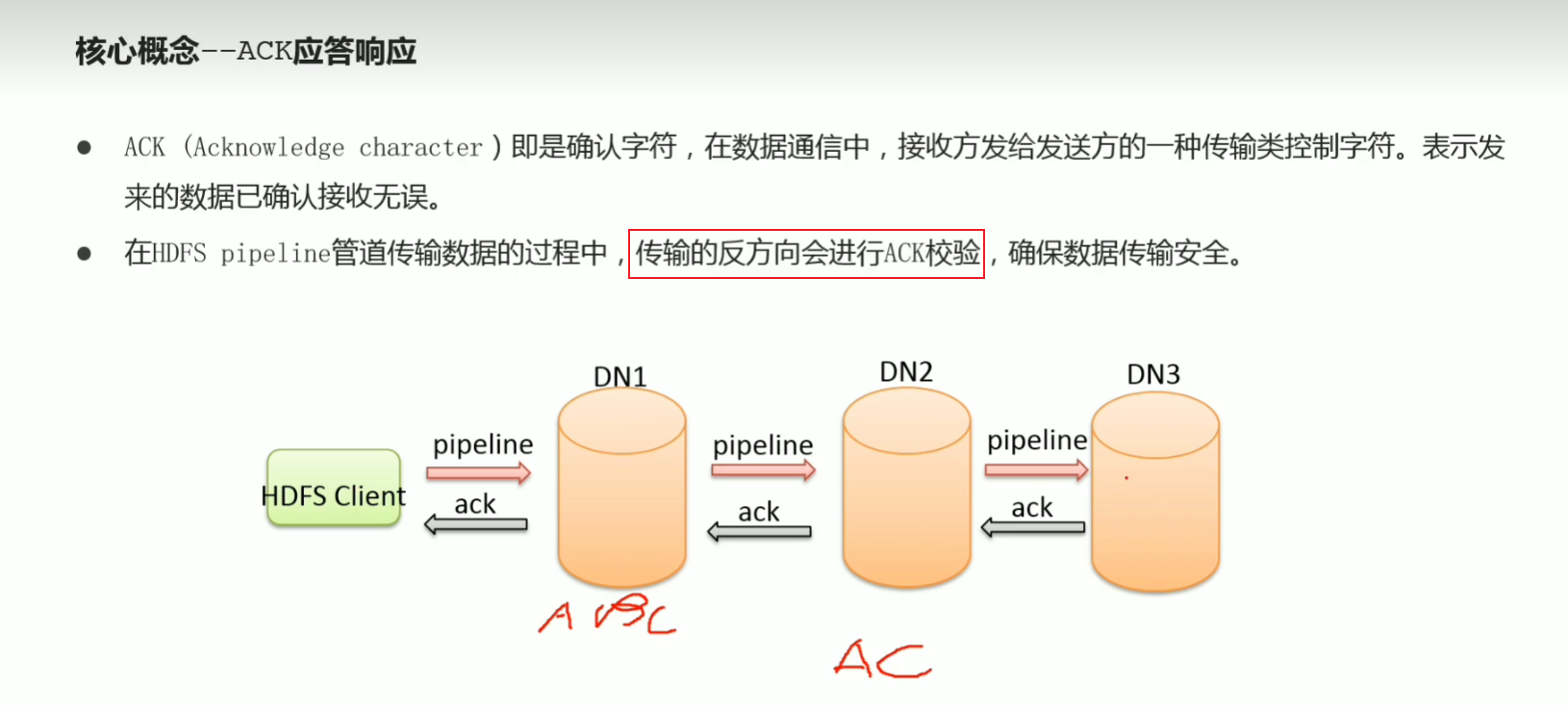


37 hads工作流程–写数据流程–梳理




p38 学习目标


p39 理解 先分再合 分而治之的思想

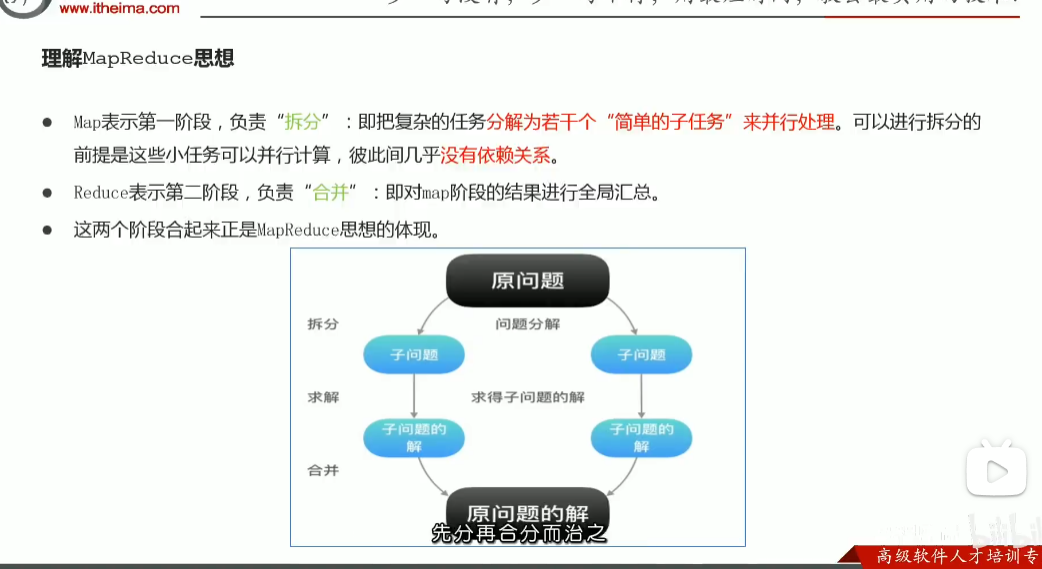

p40 hadoop团队针对mapreduce的设计构思
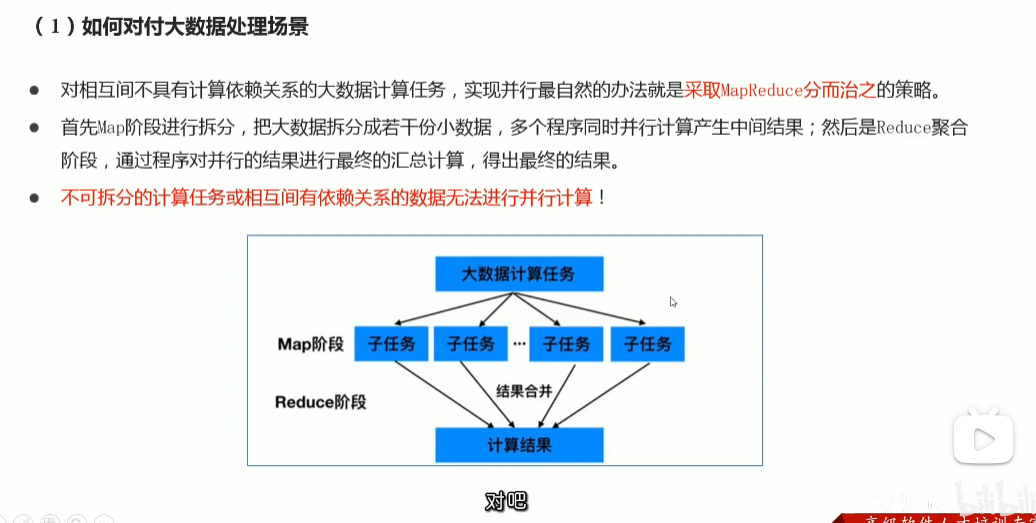
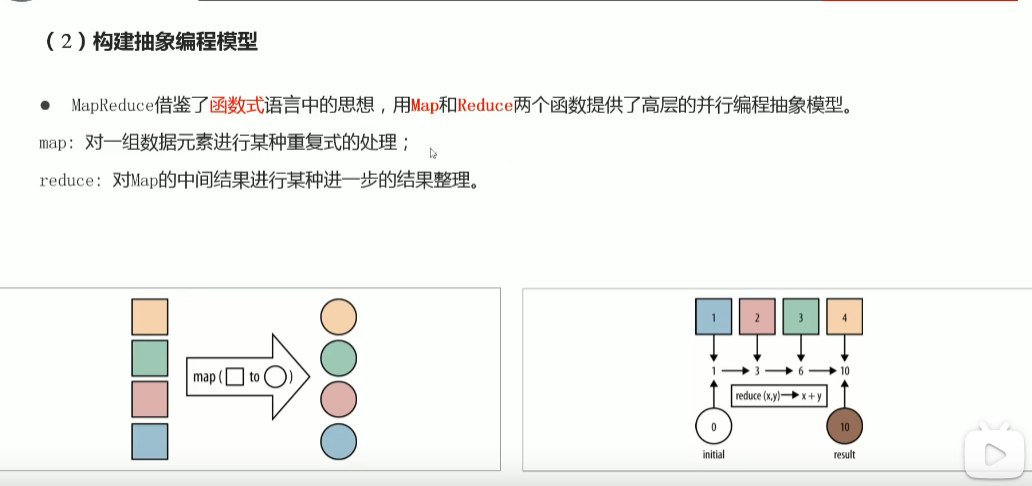


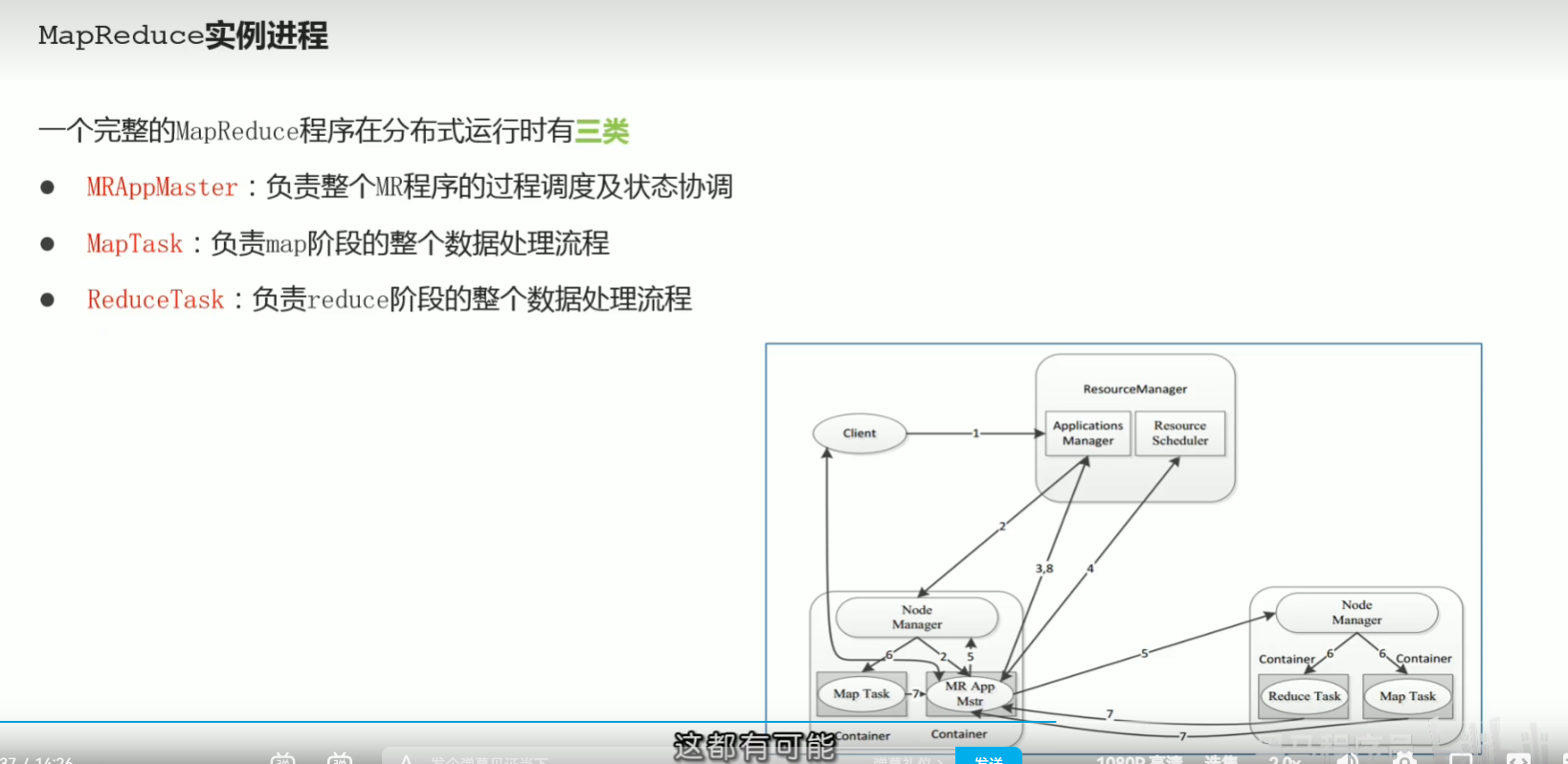
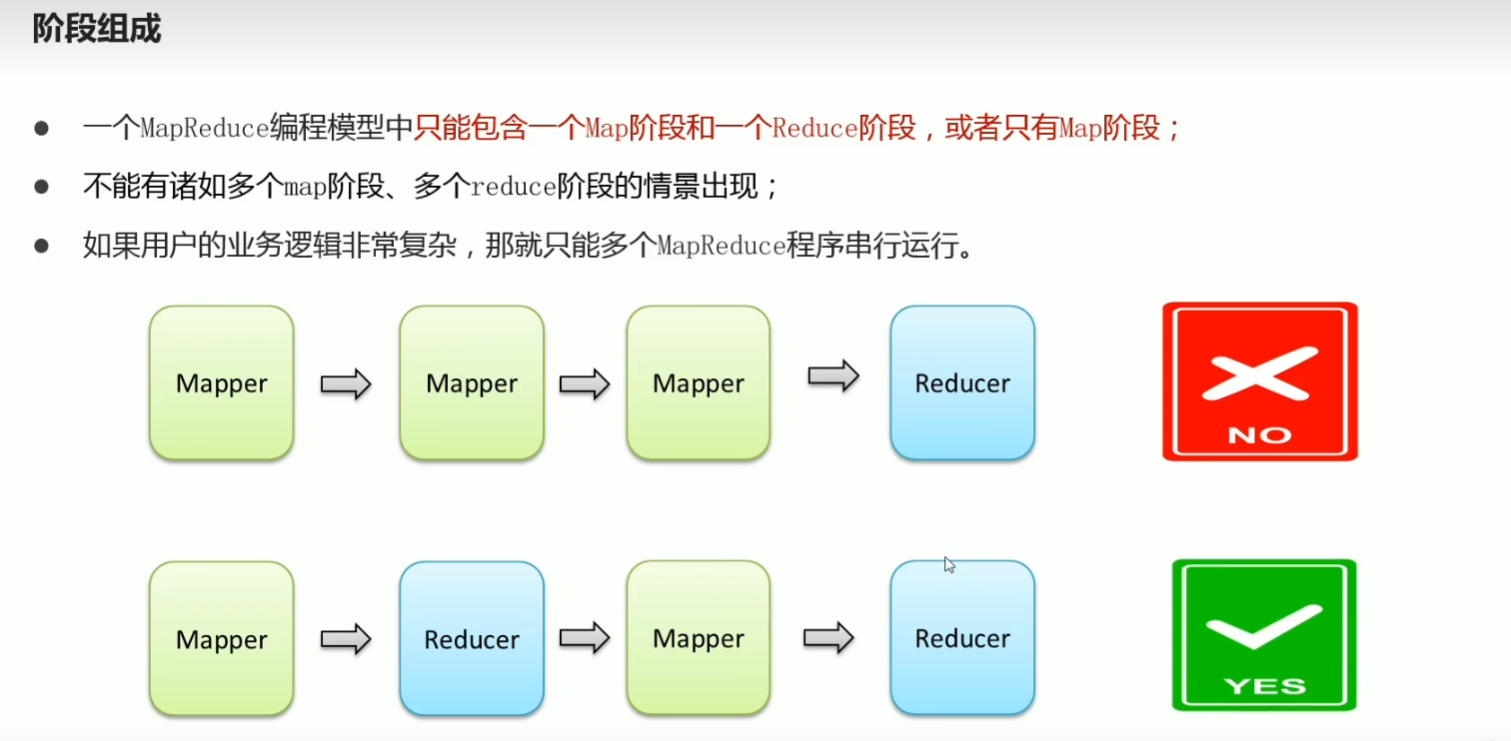
p41 MapReduce介绍 阶段划分与进程组成




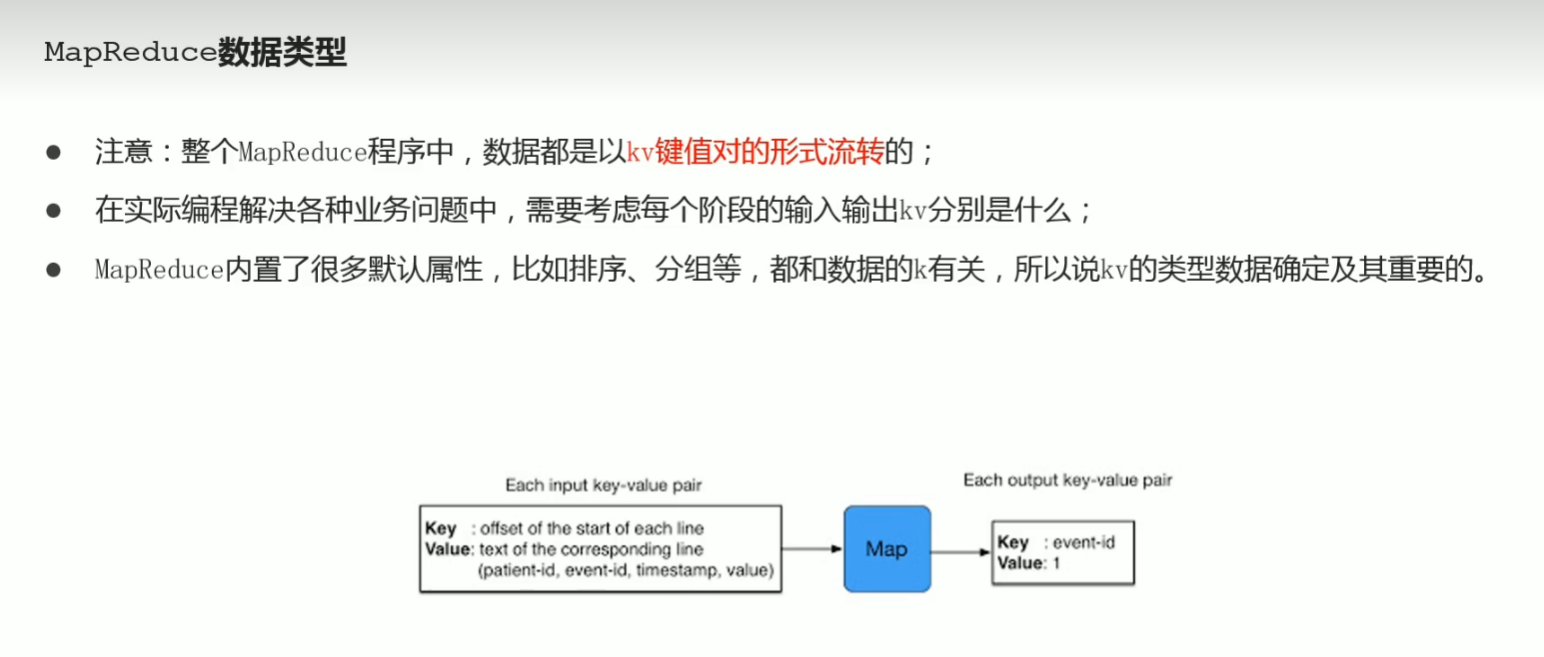
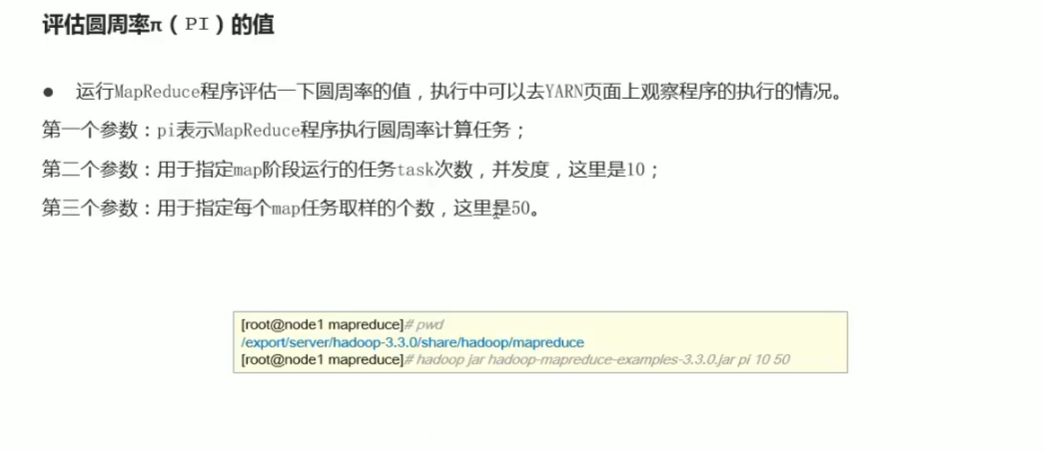
p42 MapReduce官方案例 圆周率评估


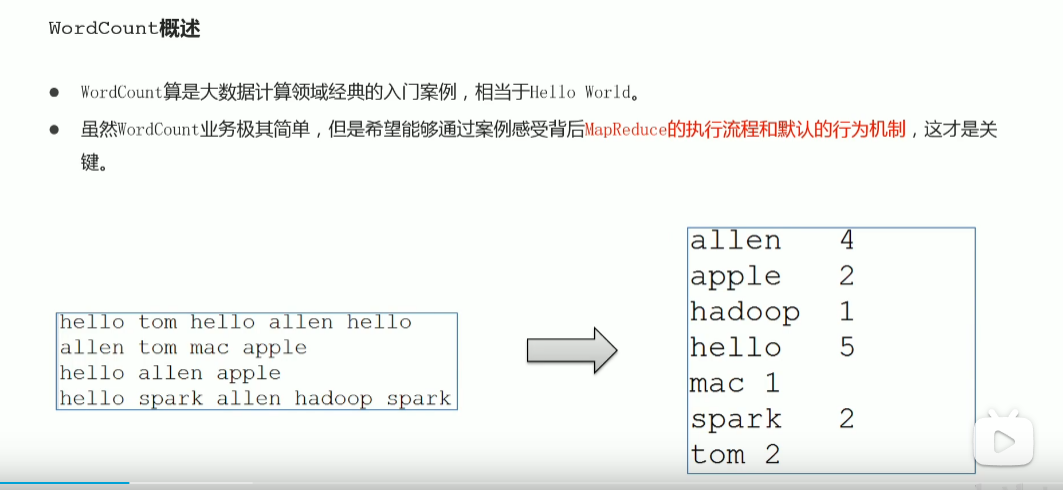
p43 wordcount单词统计
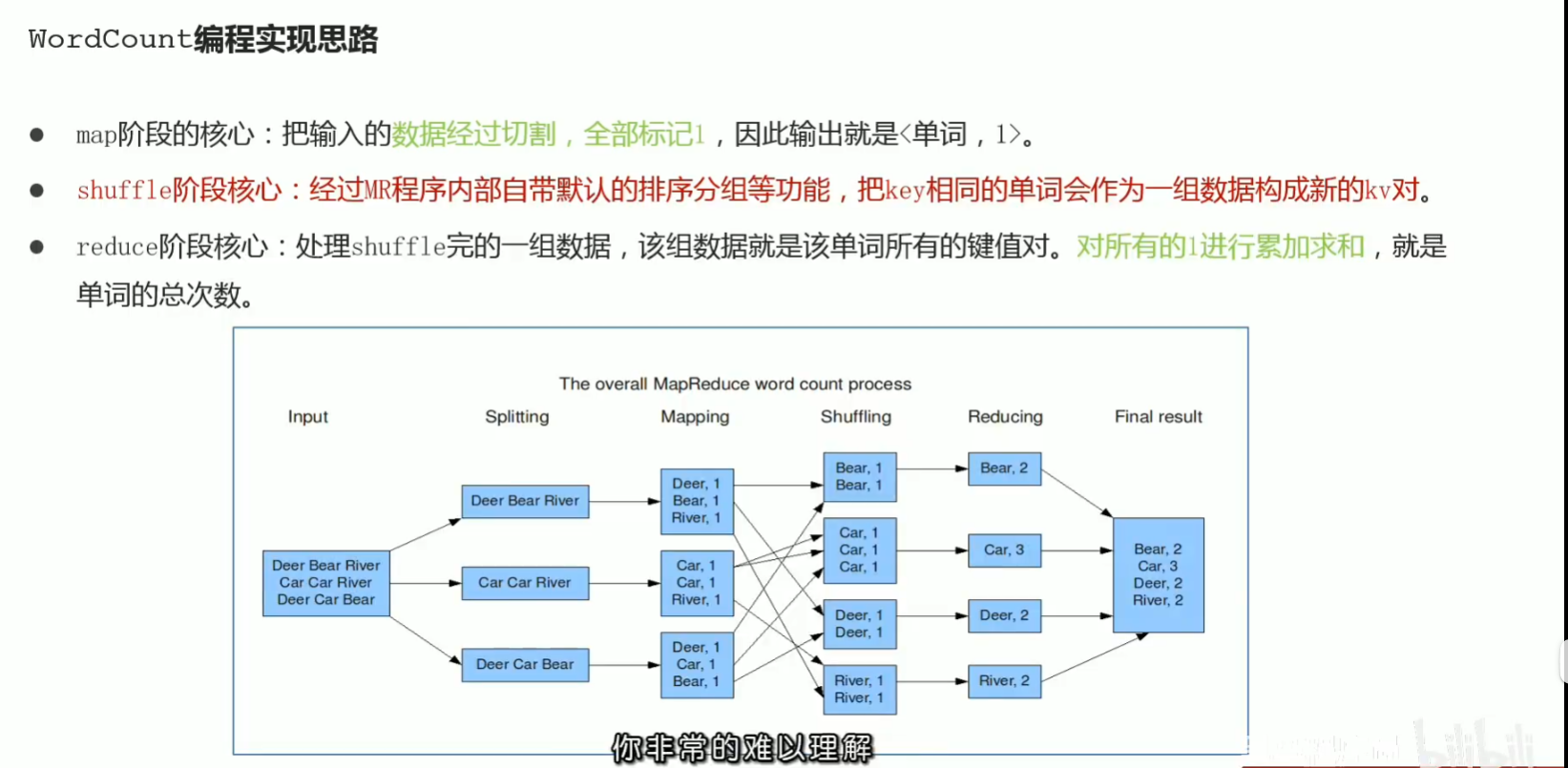
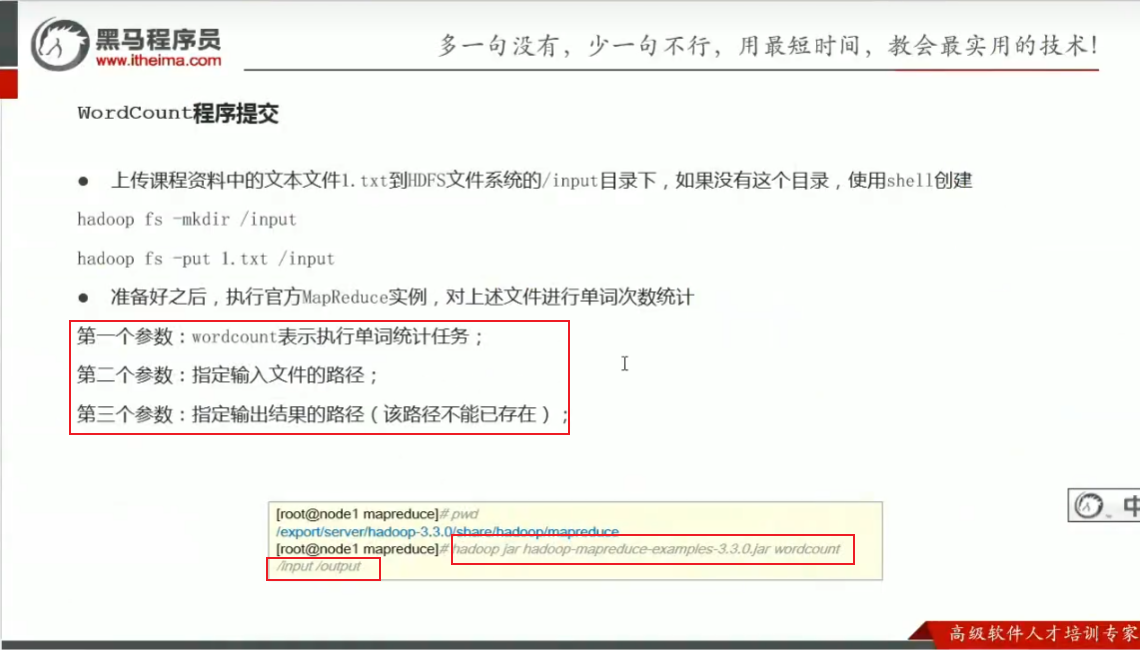
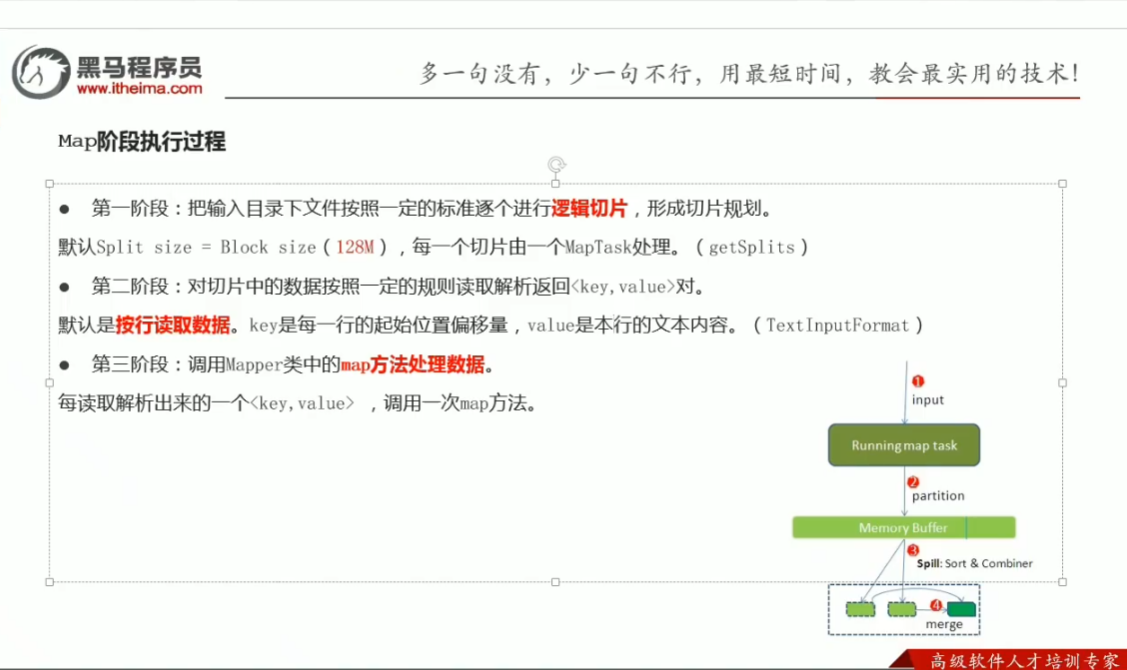
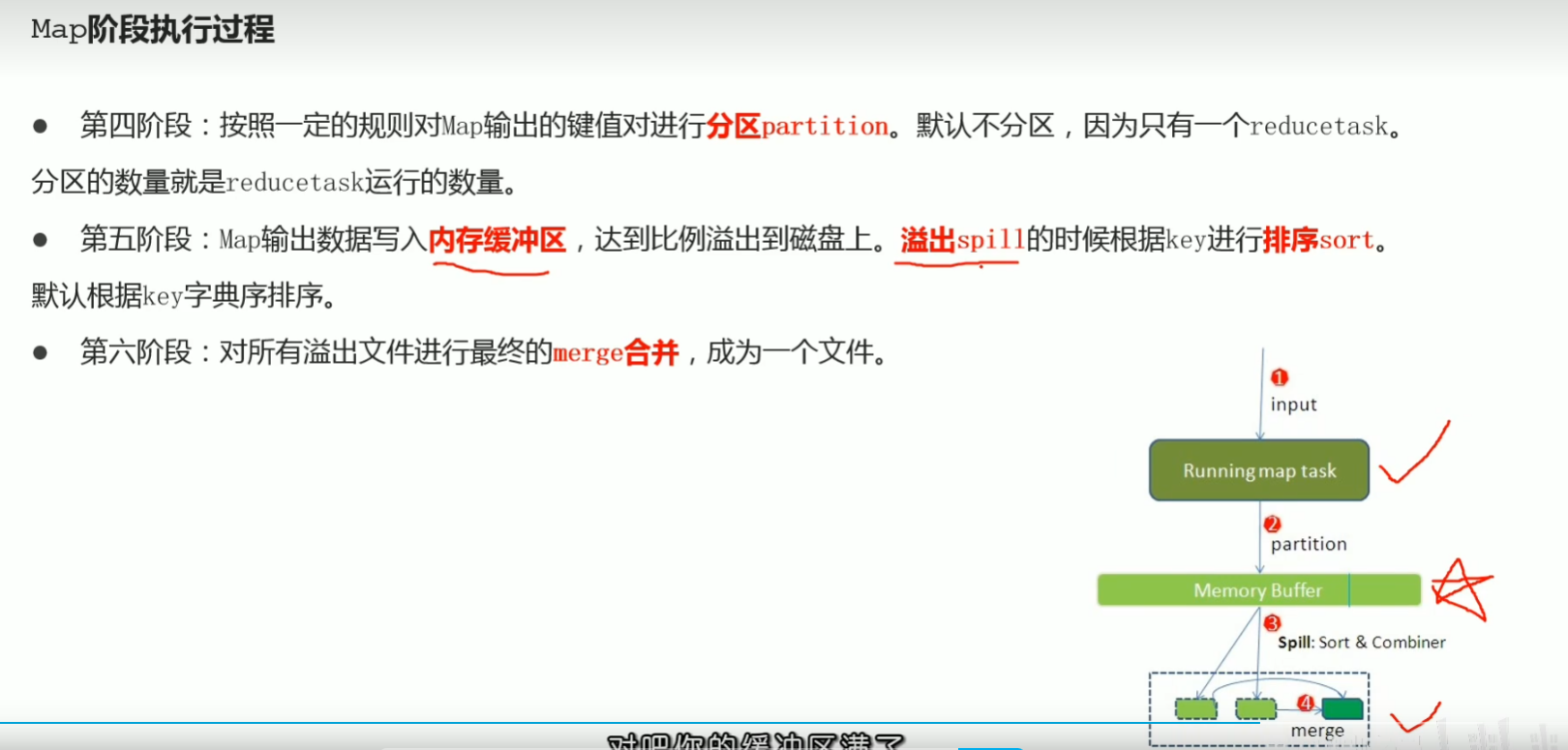
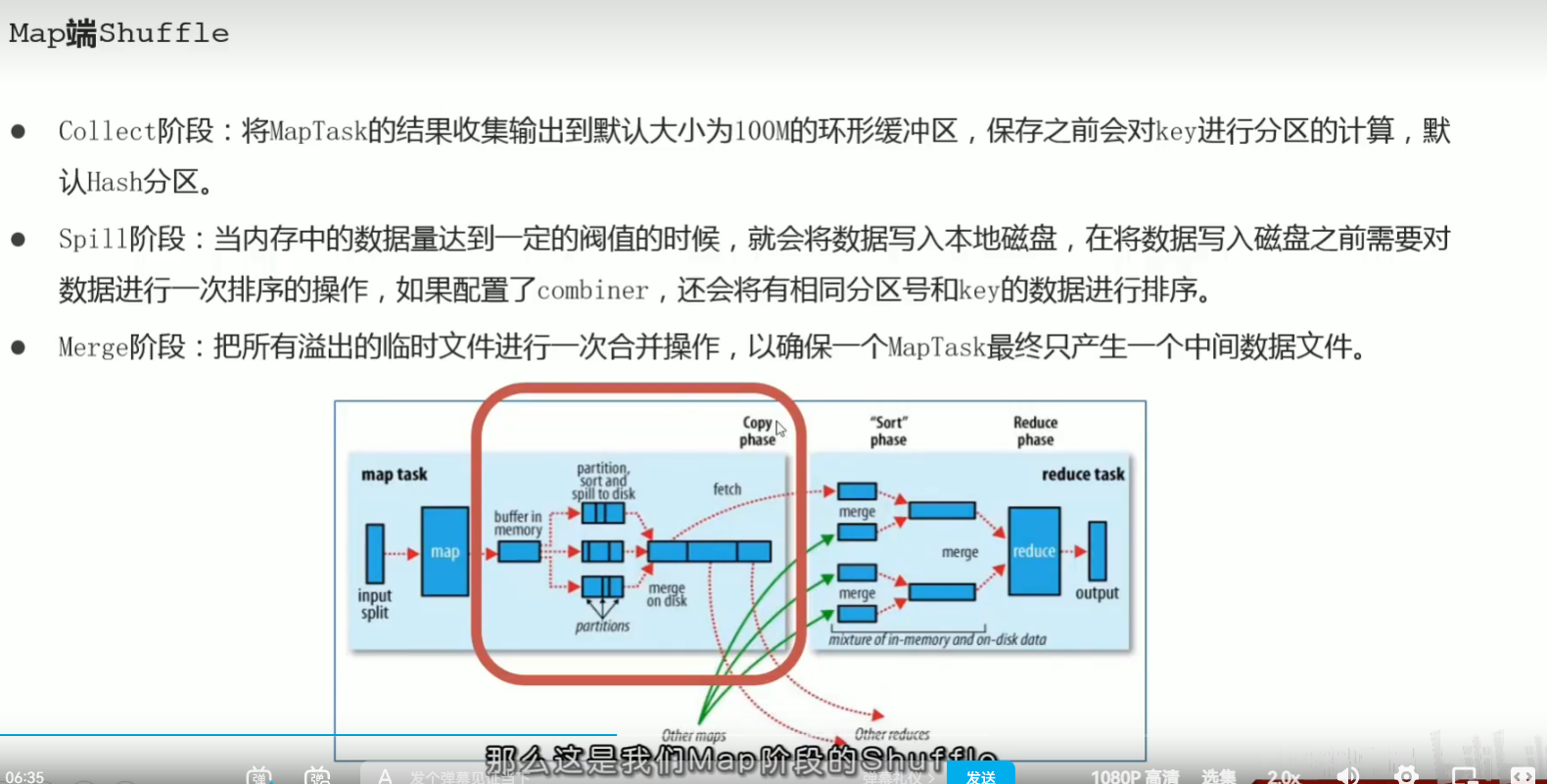
p44 map阶段执行过程
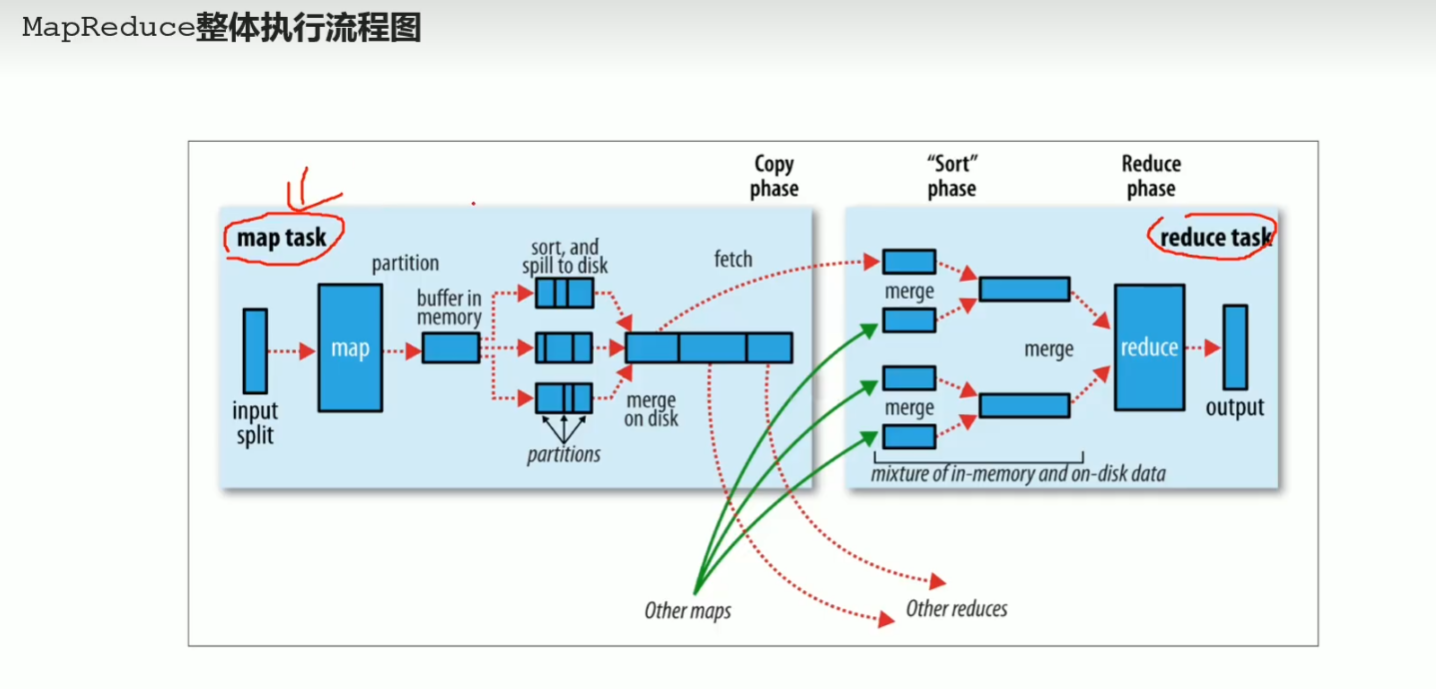
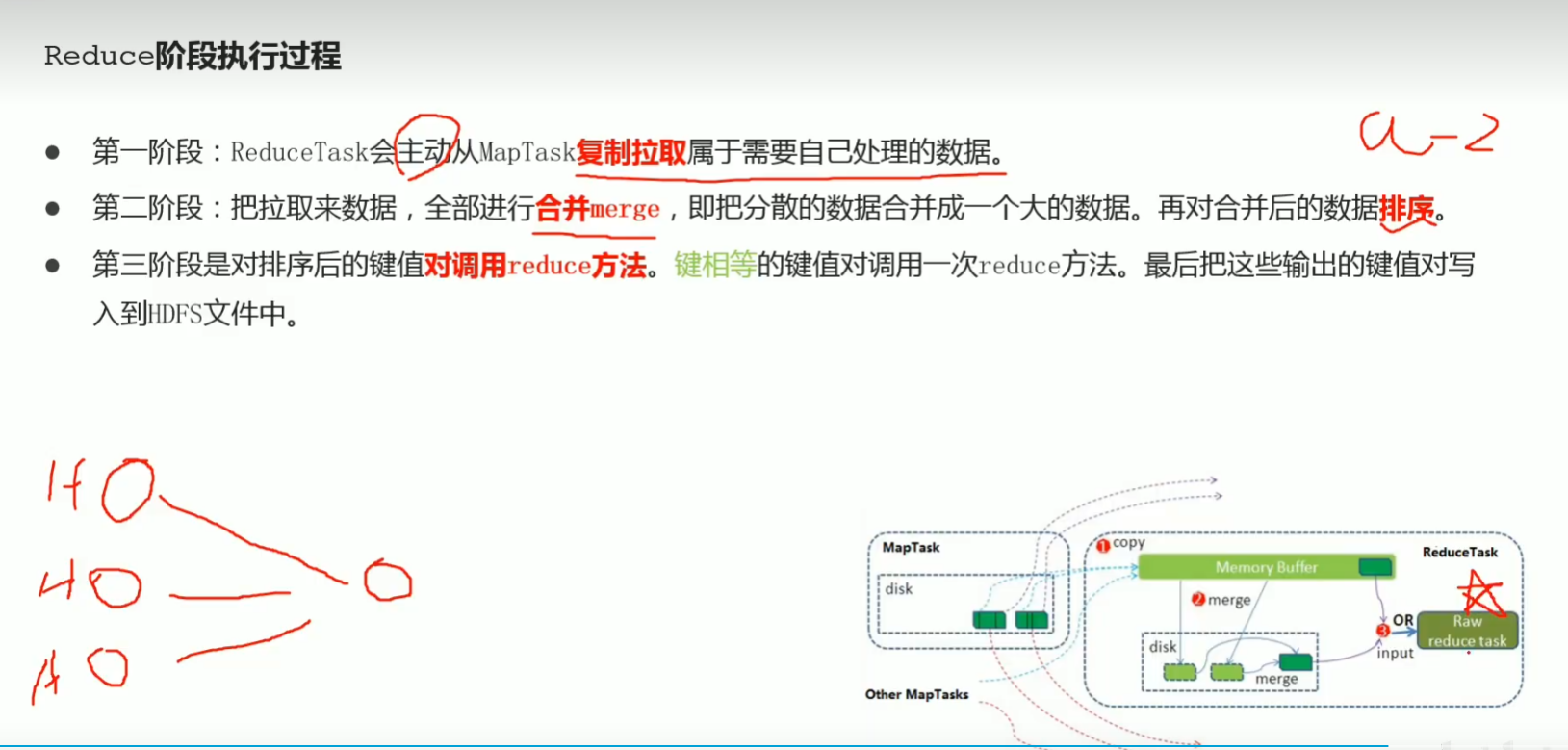
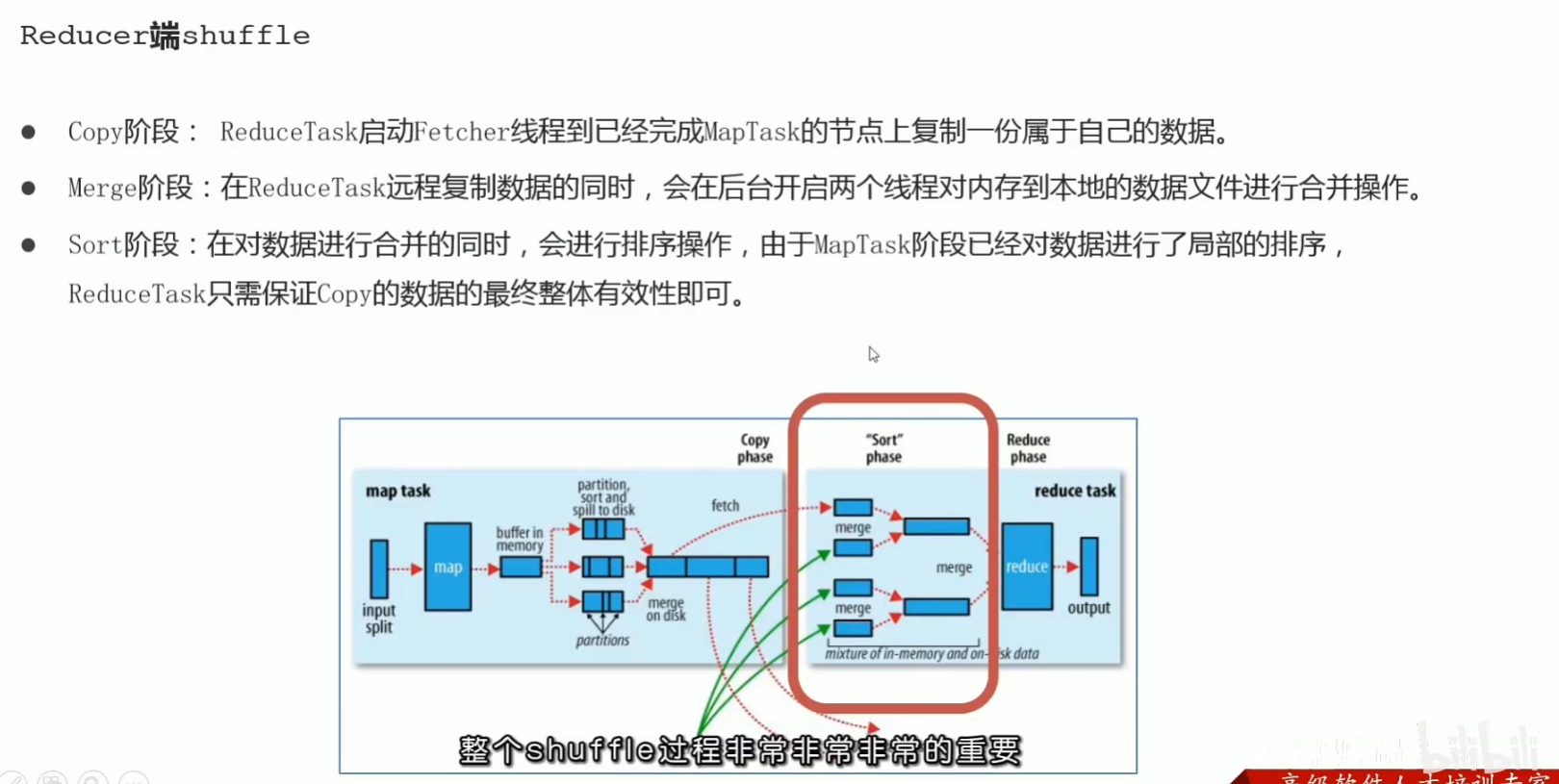
p45 reduce阶段执行过程
p46 mapreduce–shuffle机制
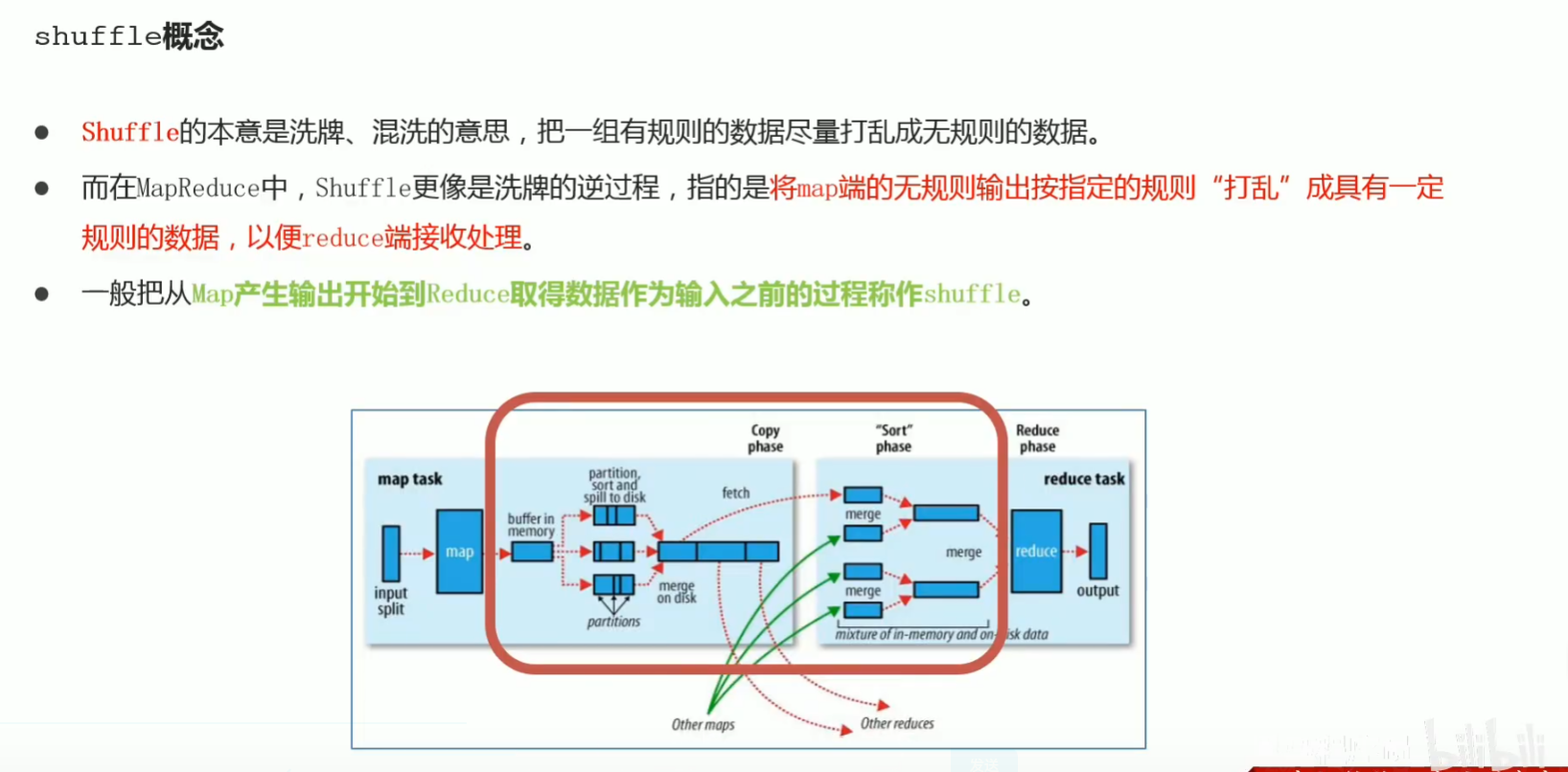

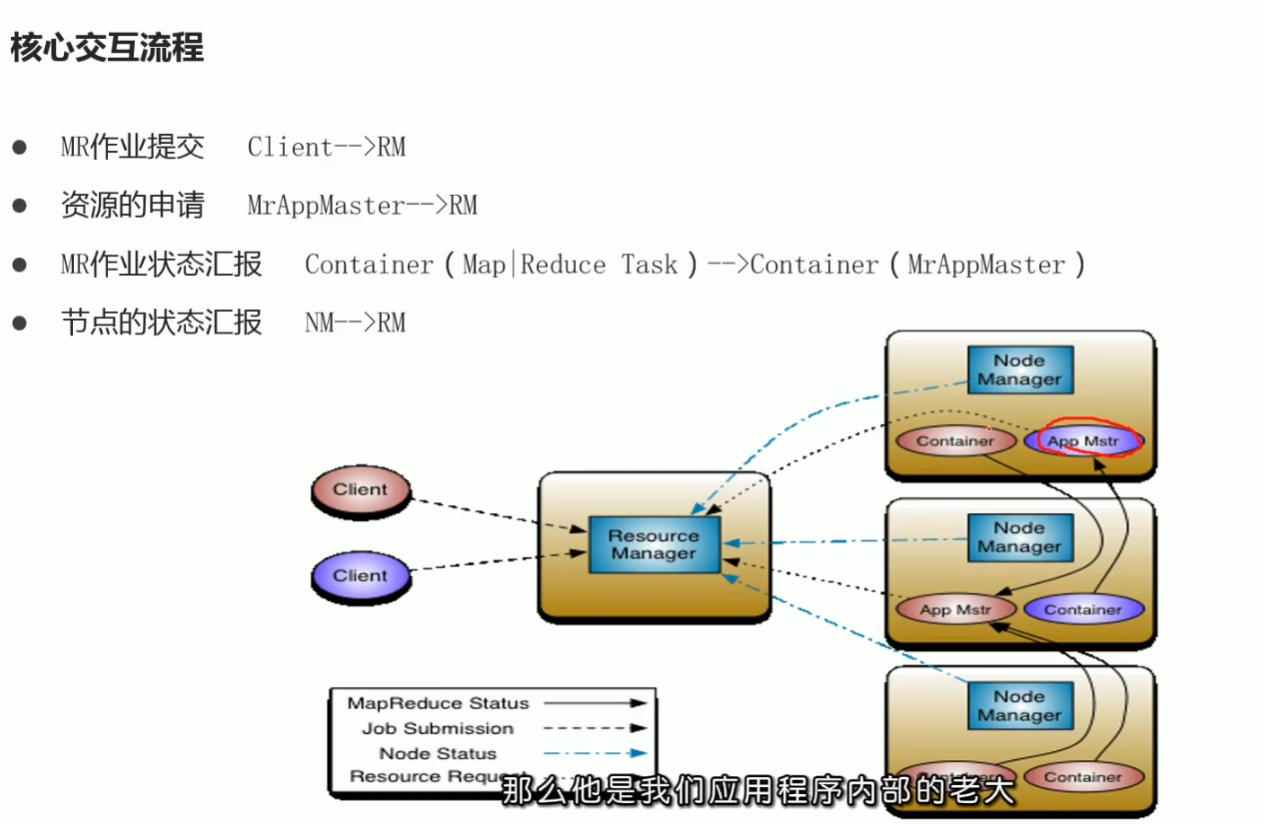
p47 yarn功能介绍 资源管理 任务调度
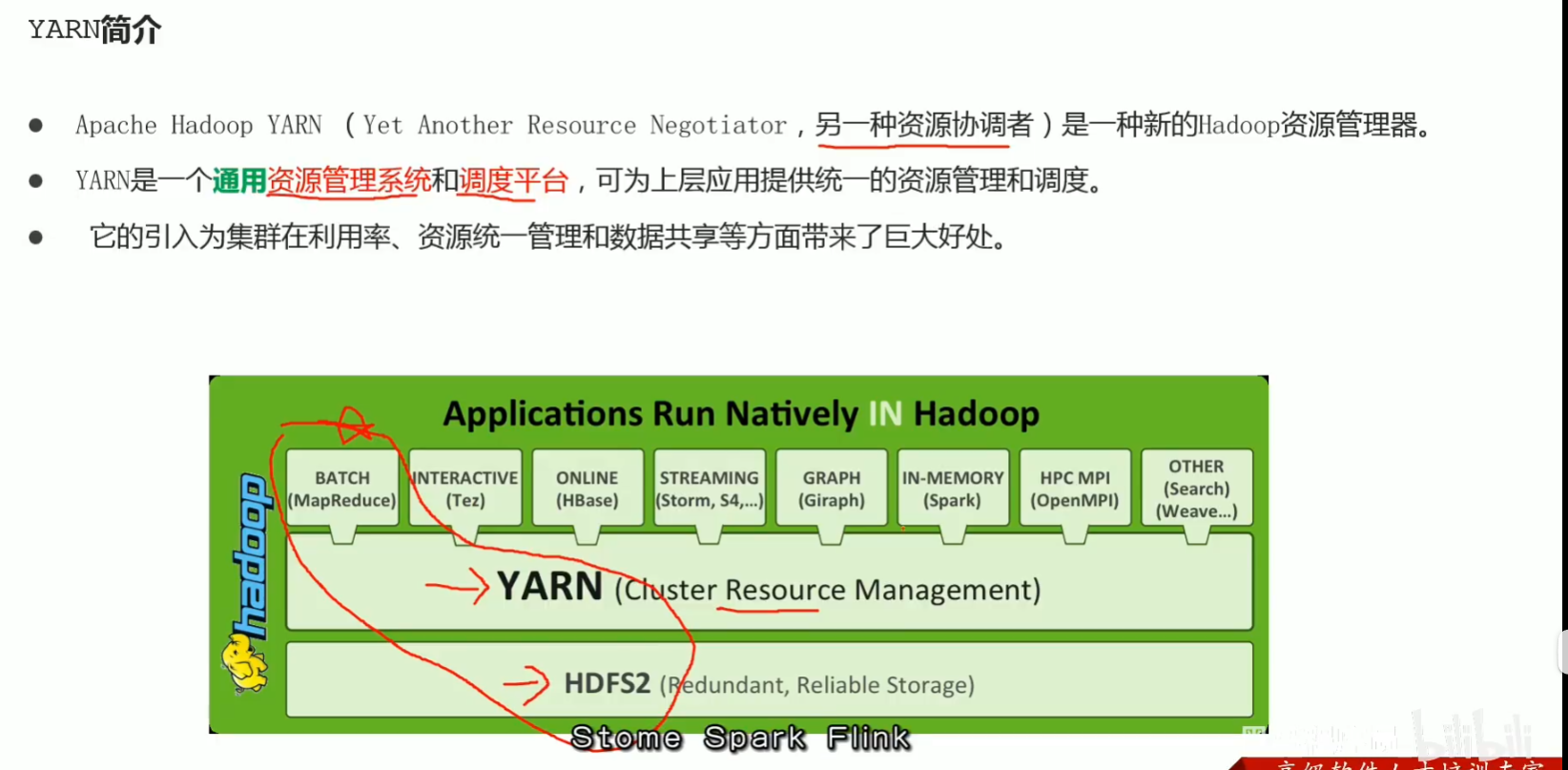
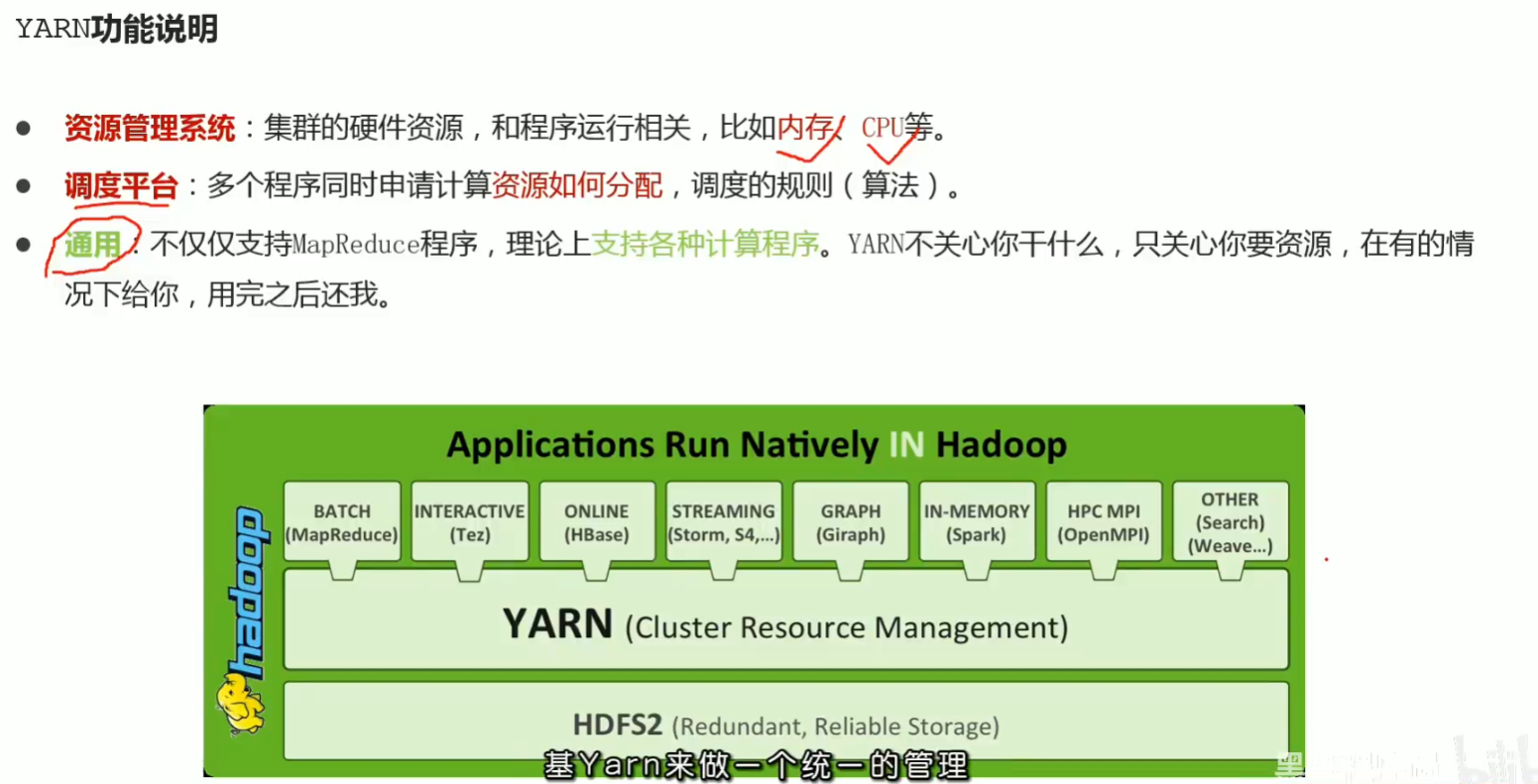
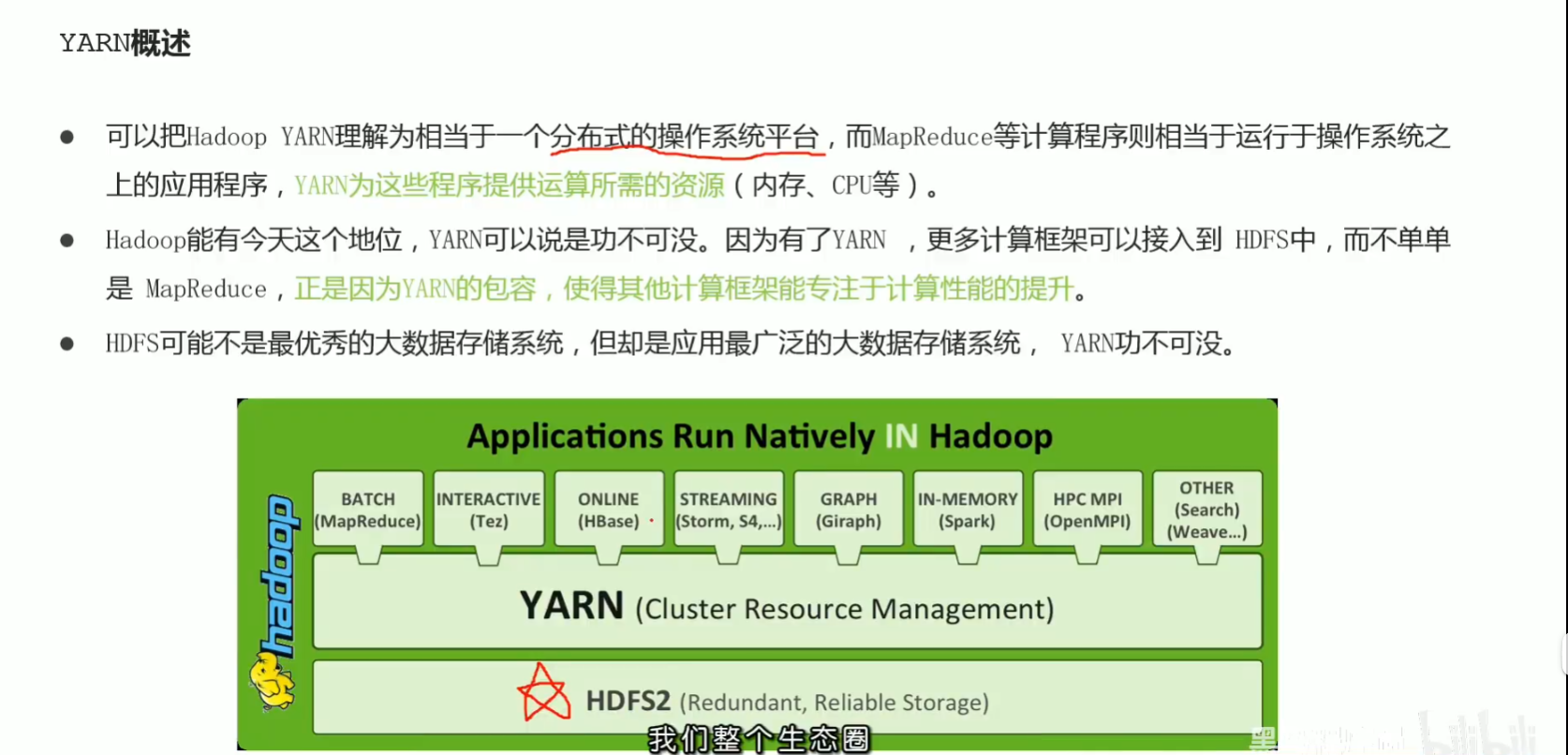
p48 yarn架构图 3大组件介绍
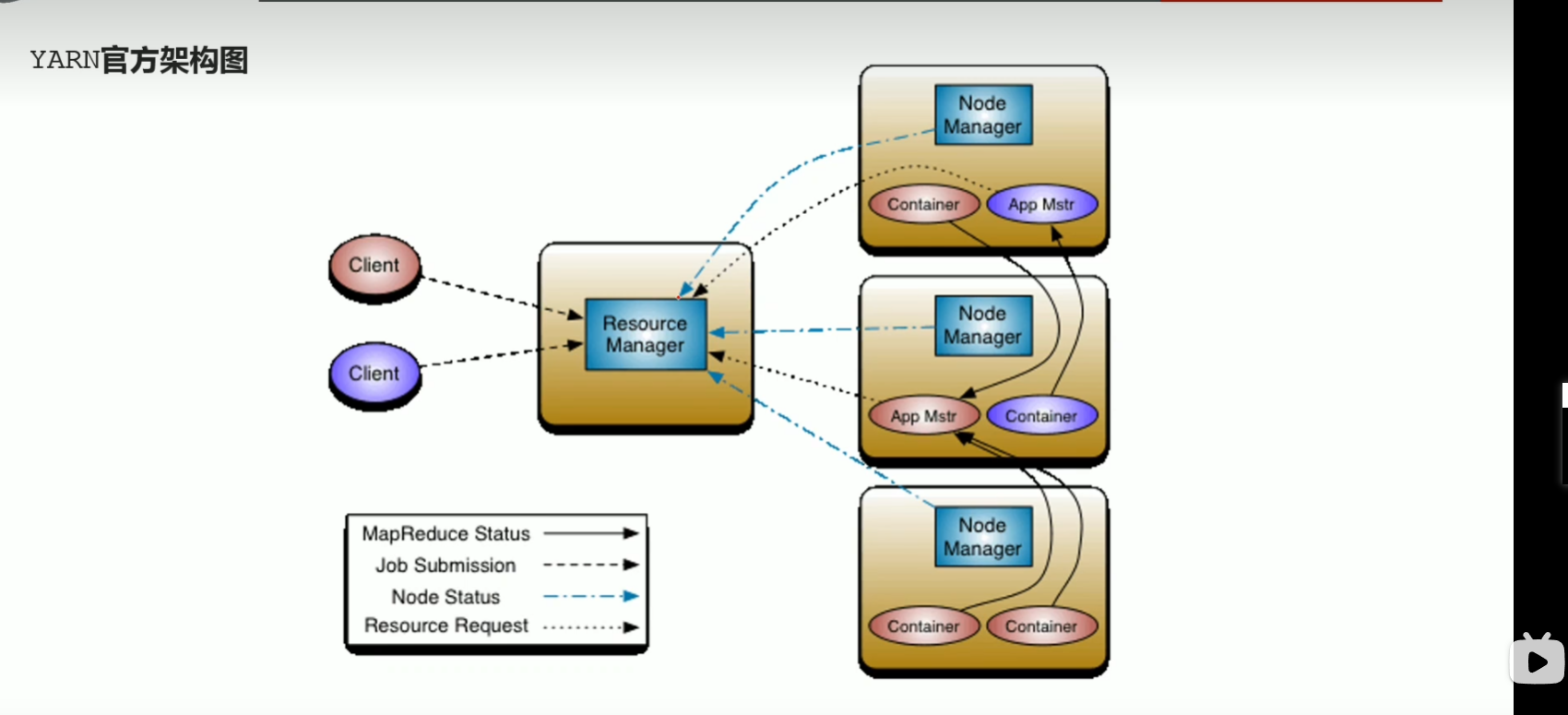
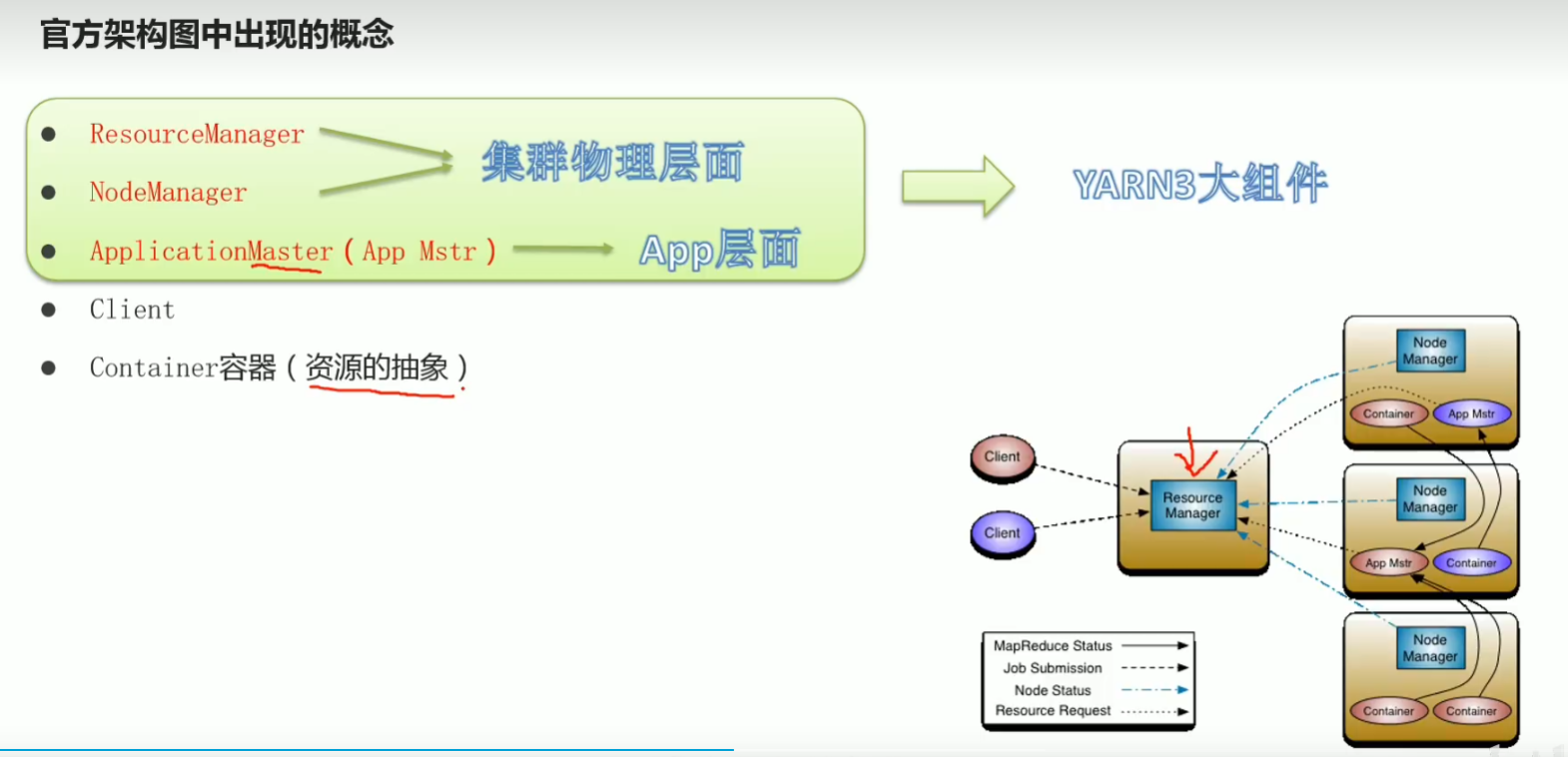

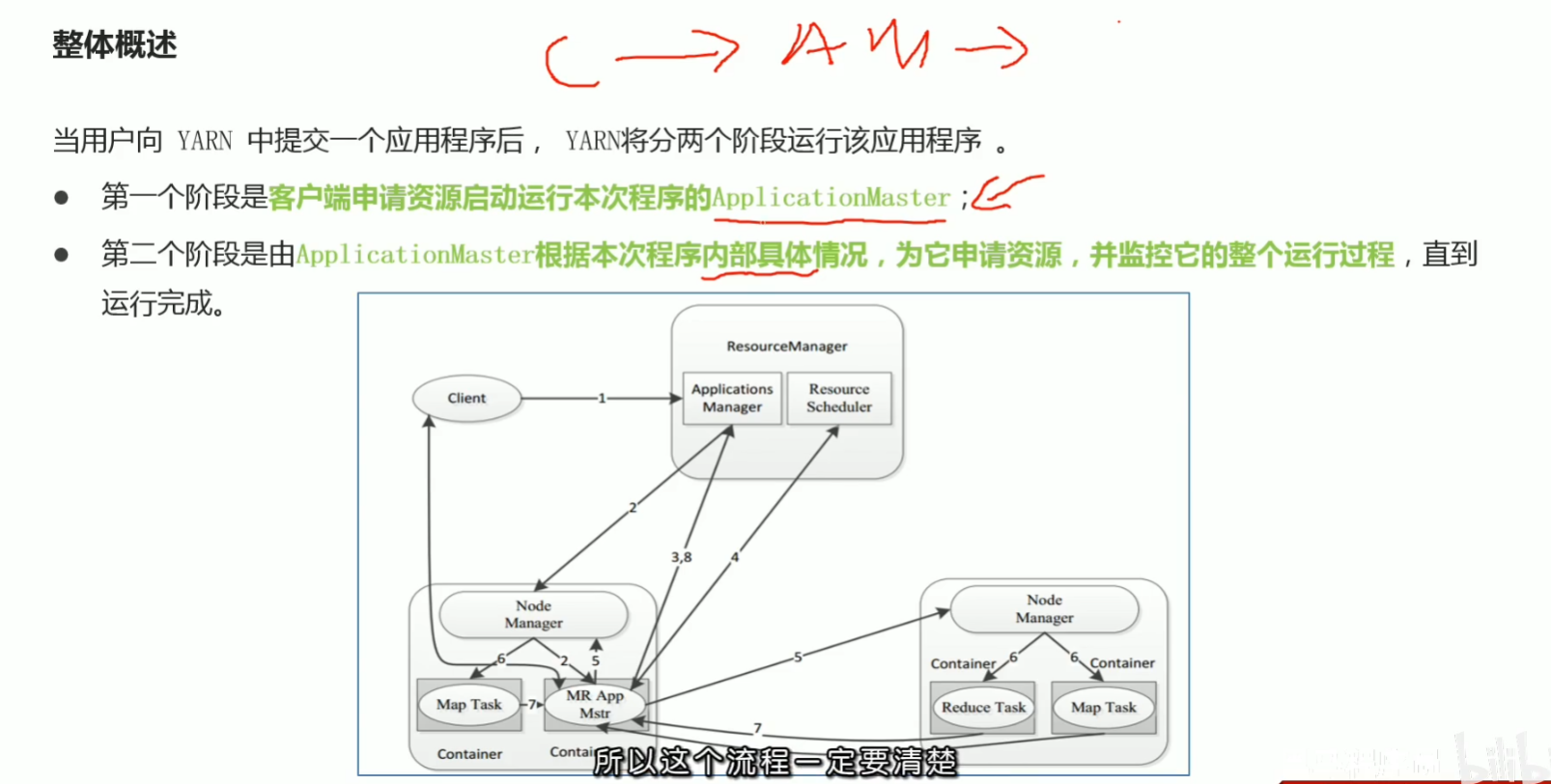
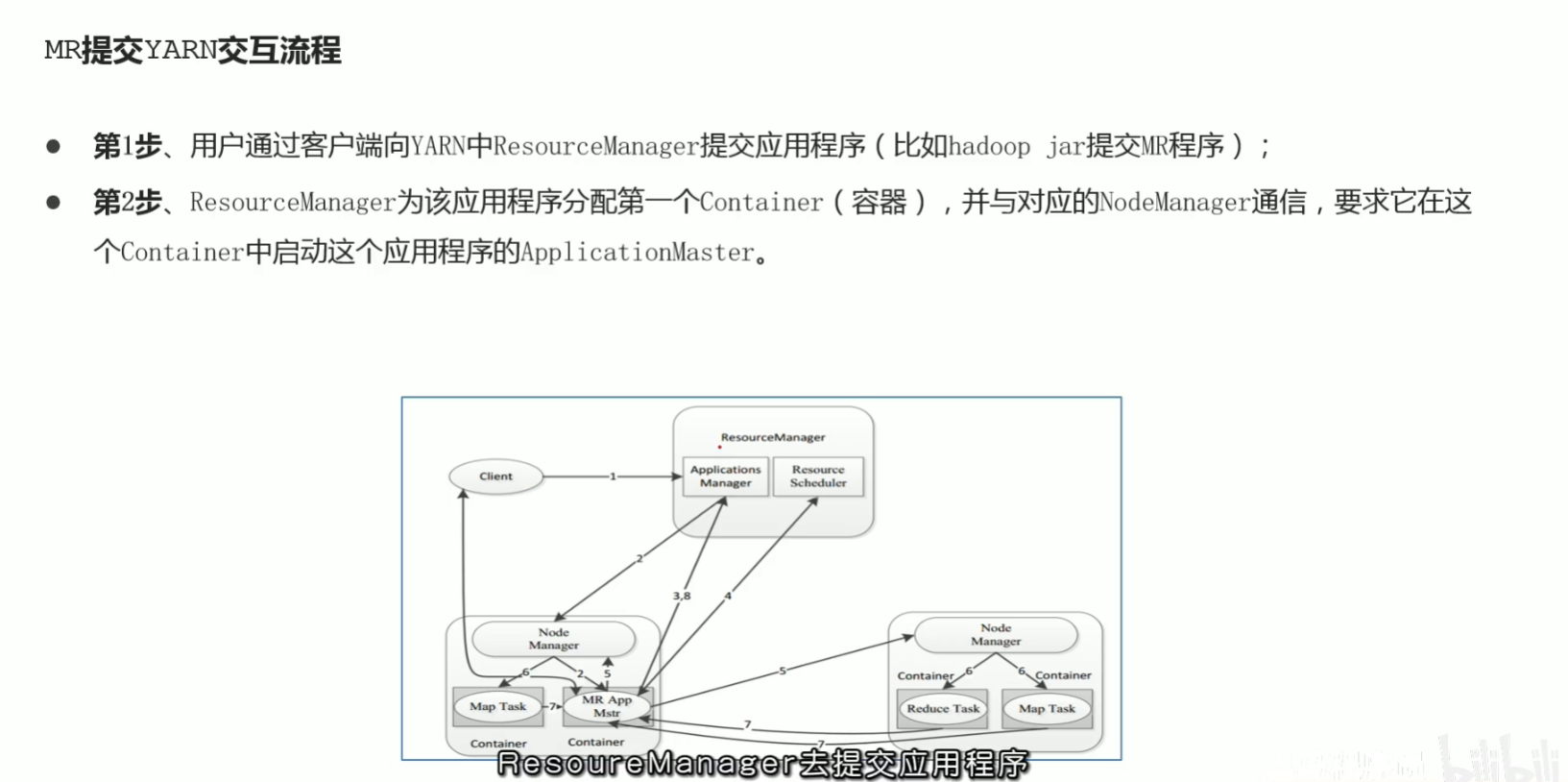
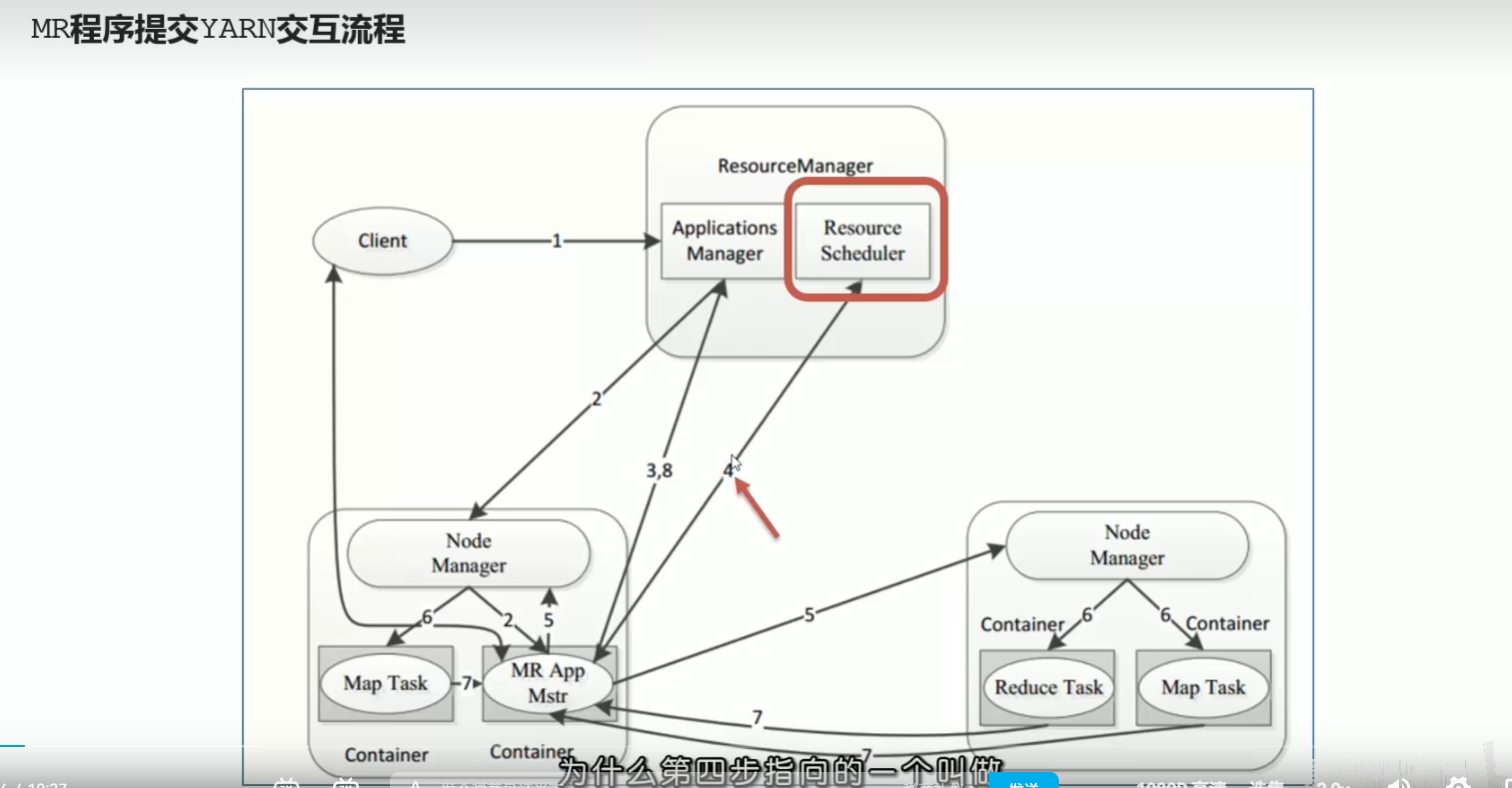
p49 程序提交yarn集群交互流程



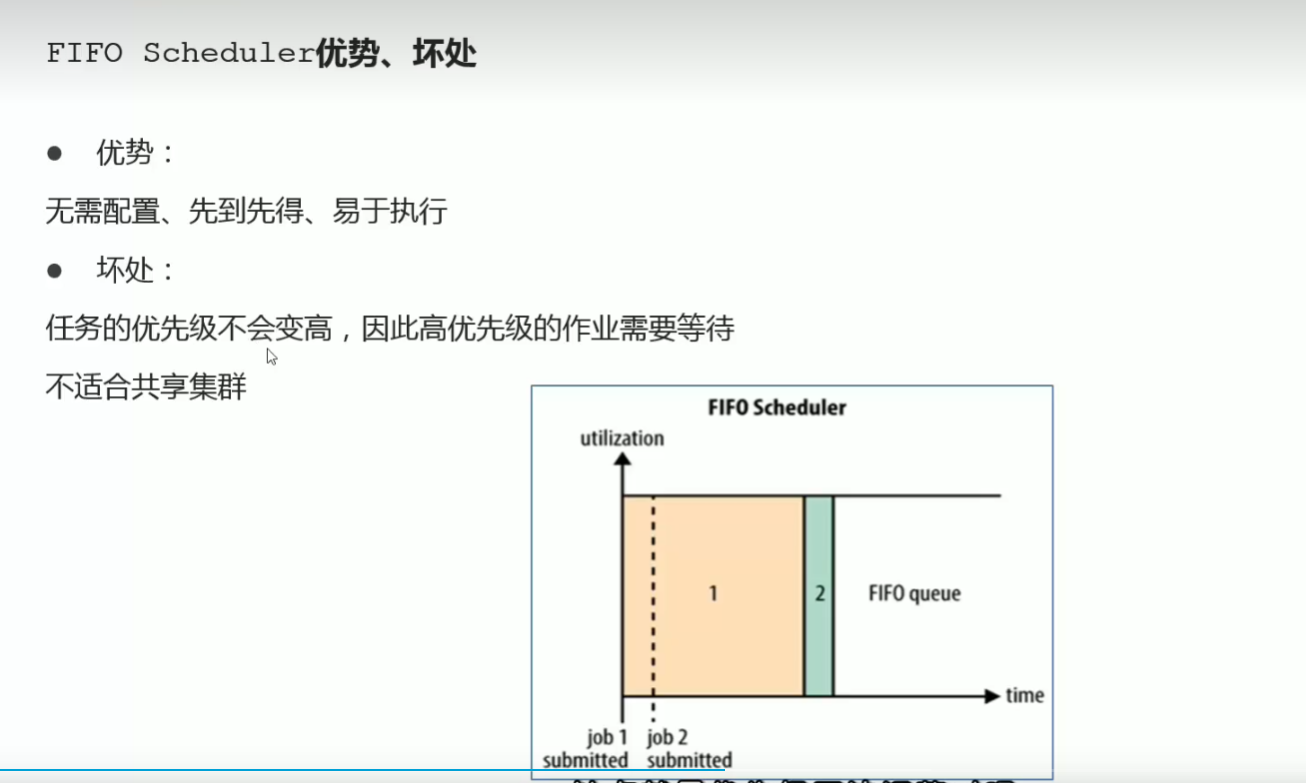
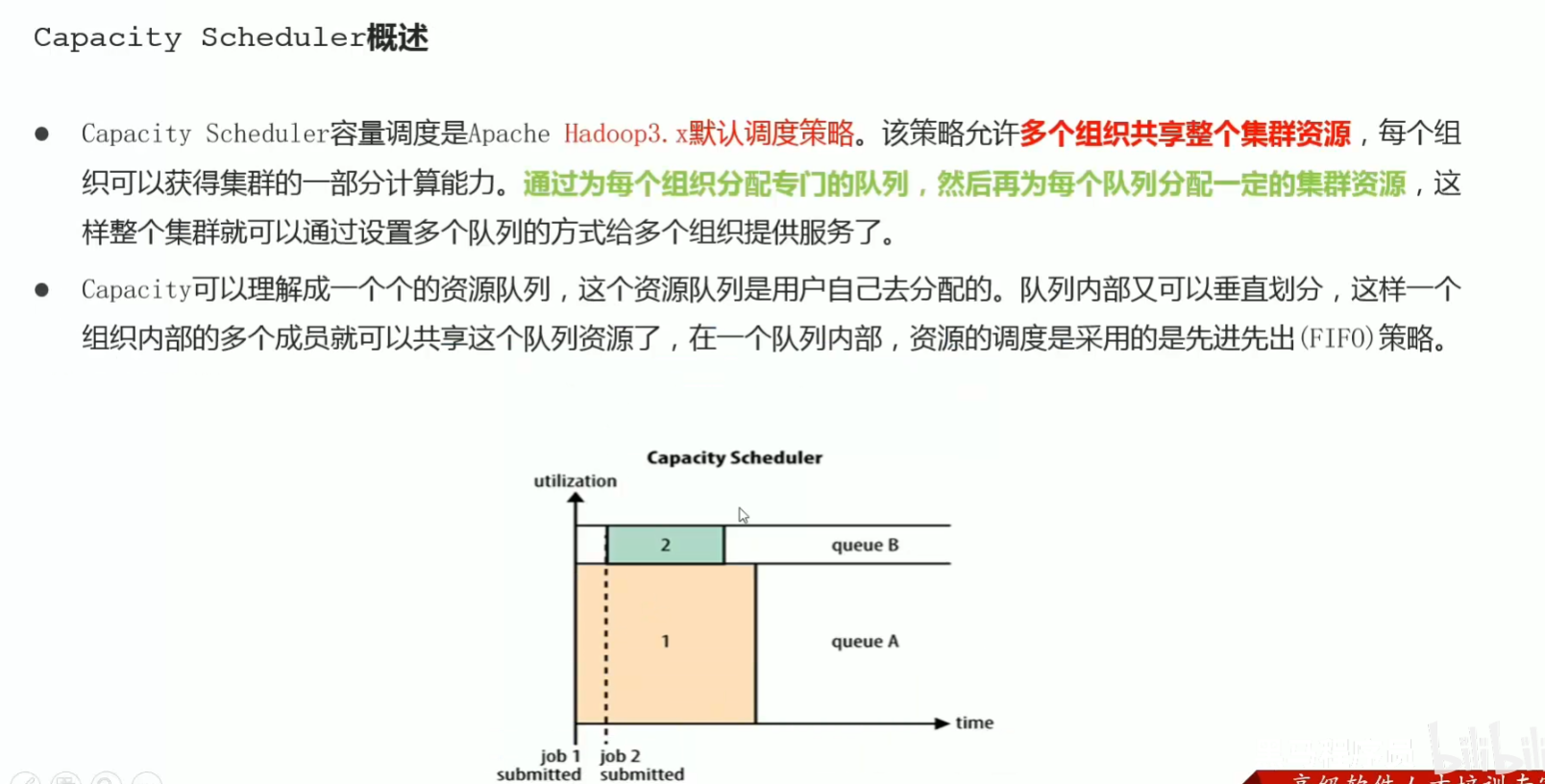
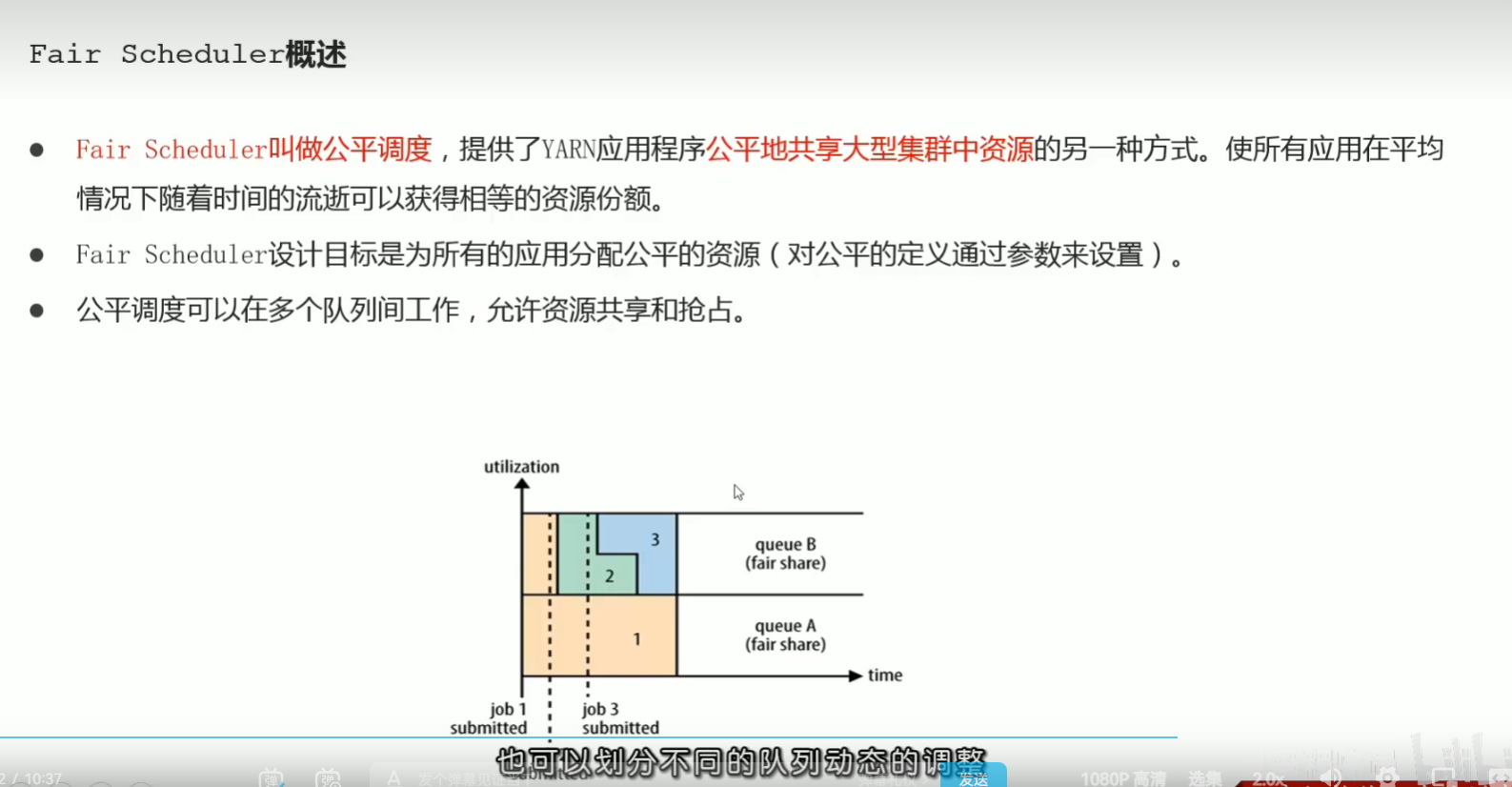
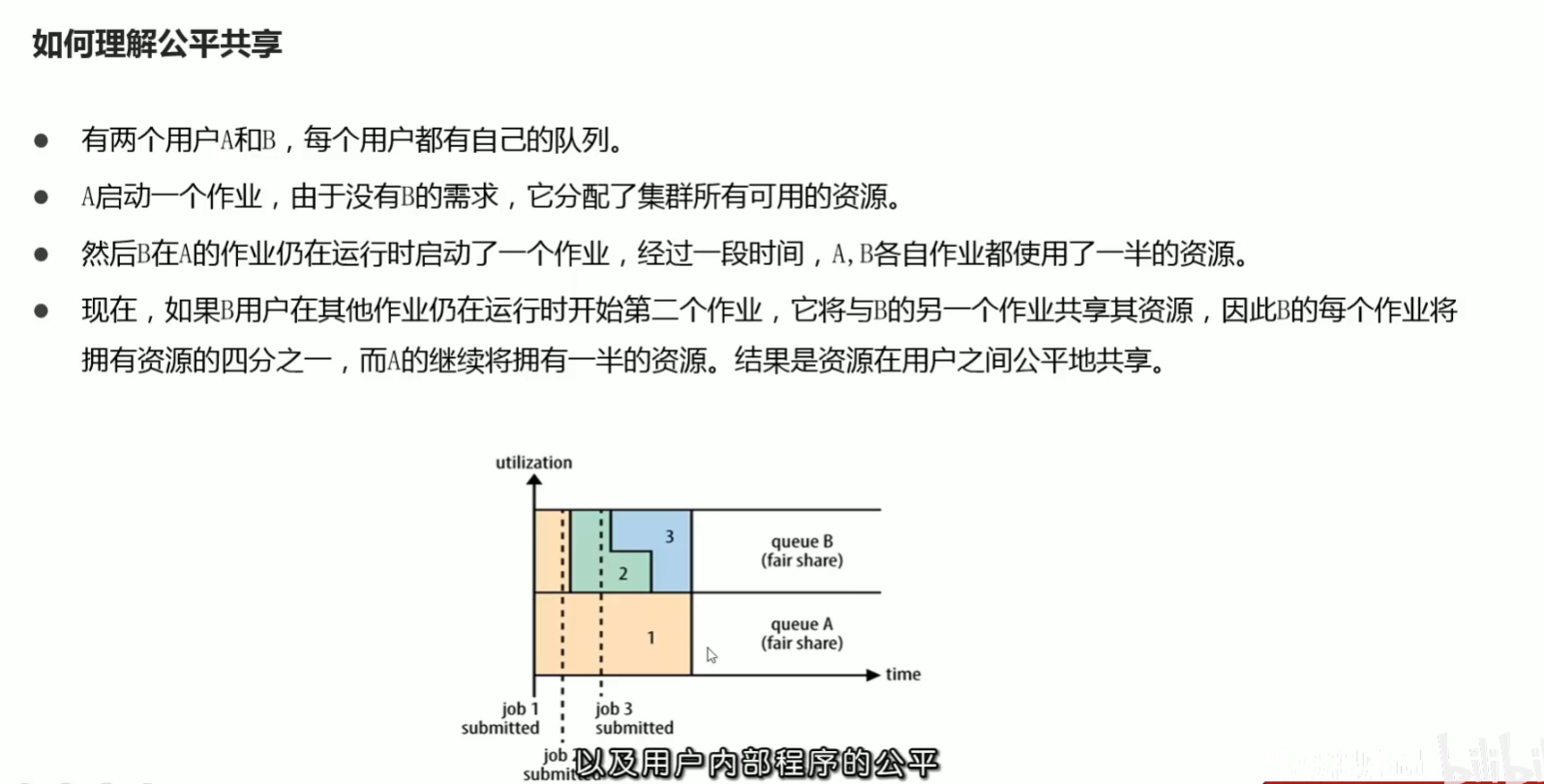
p50 资源调度器scheduler和调度策略




p51 课程内容学习大纲

p52数据仓库概念与起源发展由来

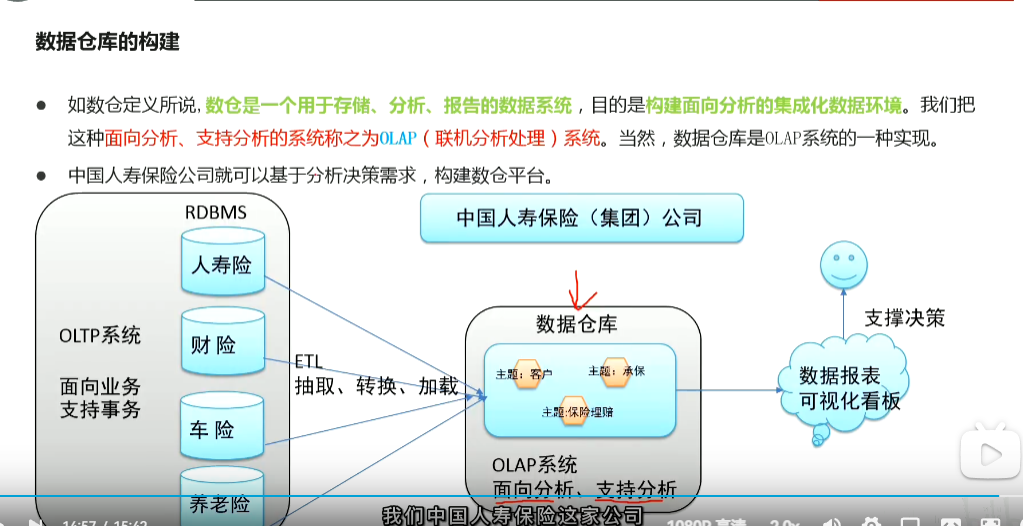
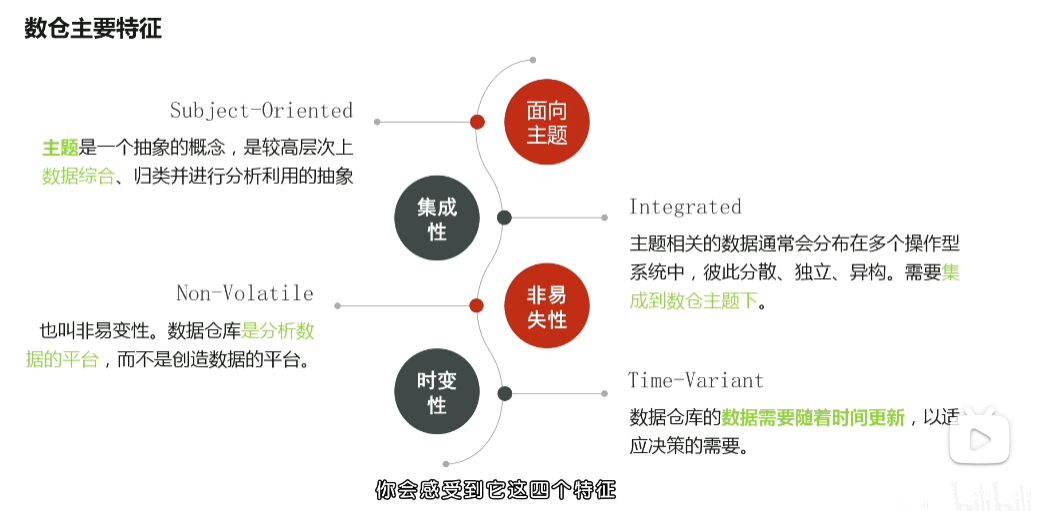
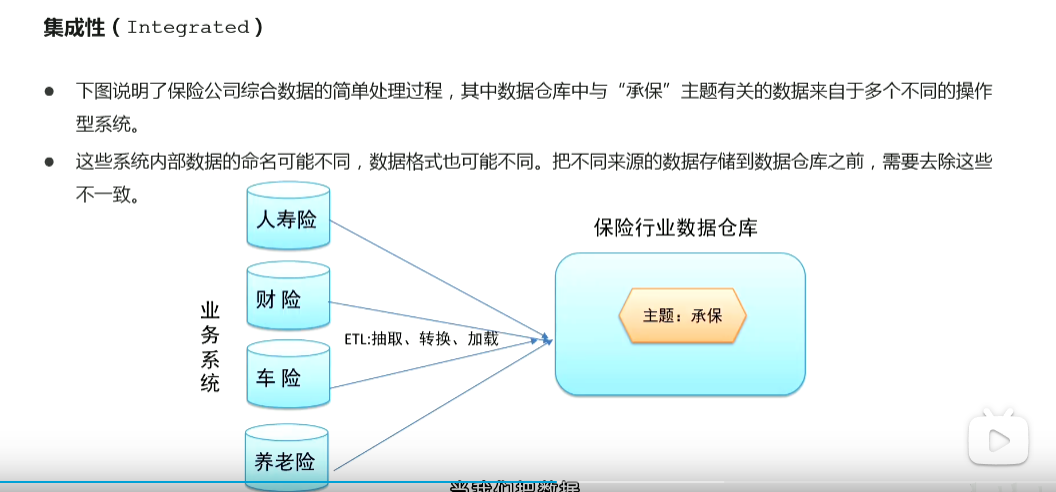
p53 数据仓库主要特征 面向主题 集成 非易失 时变


p54 sql介绍
p55 hive和hadoop之间的关系


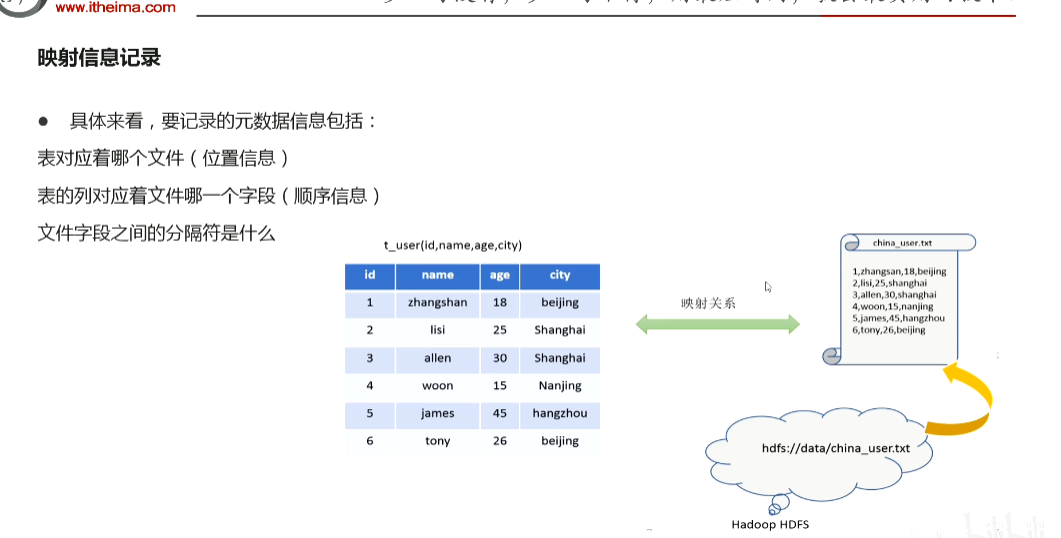
p56 hive功能模拟实现底层猜想




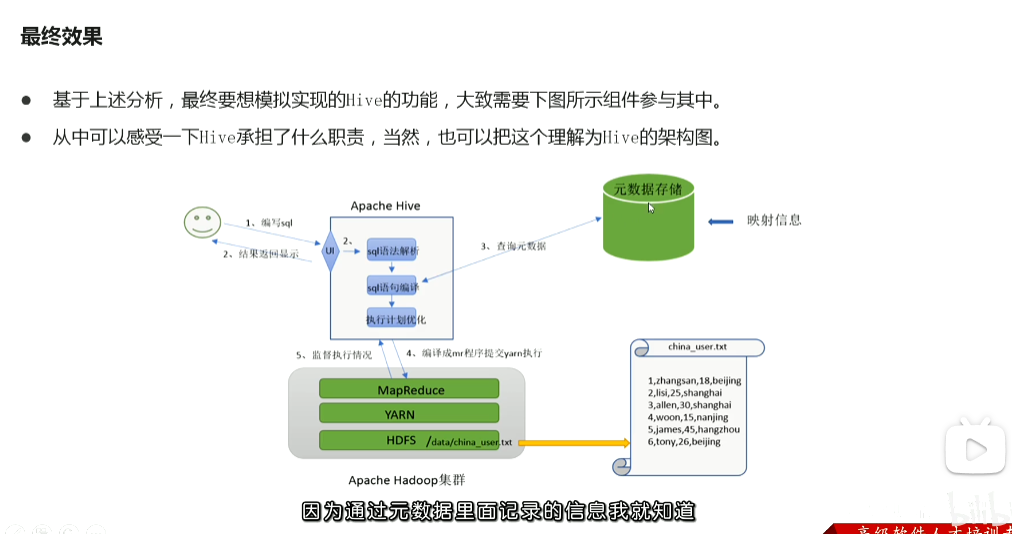
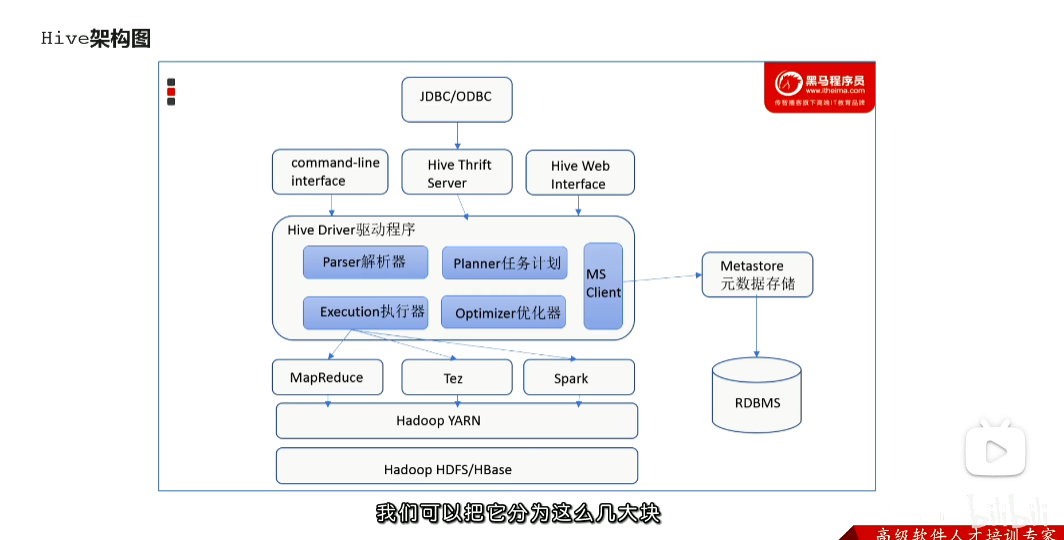
p57 hive架构图 各组件功能
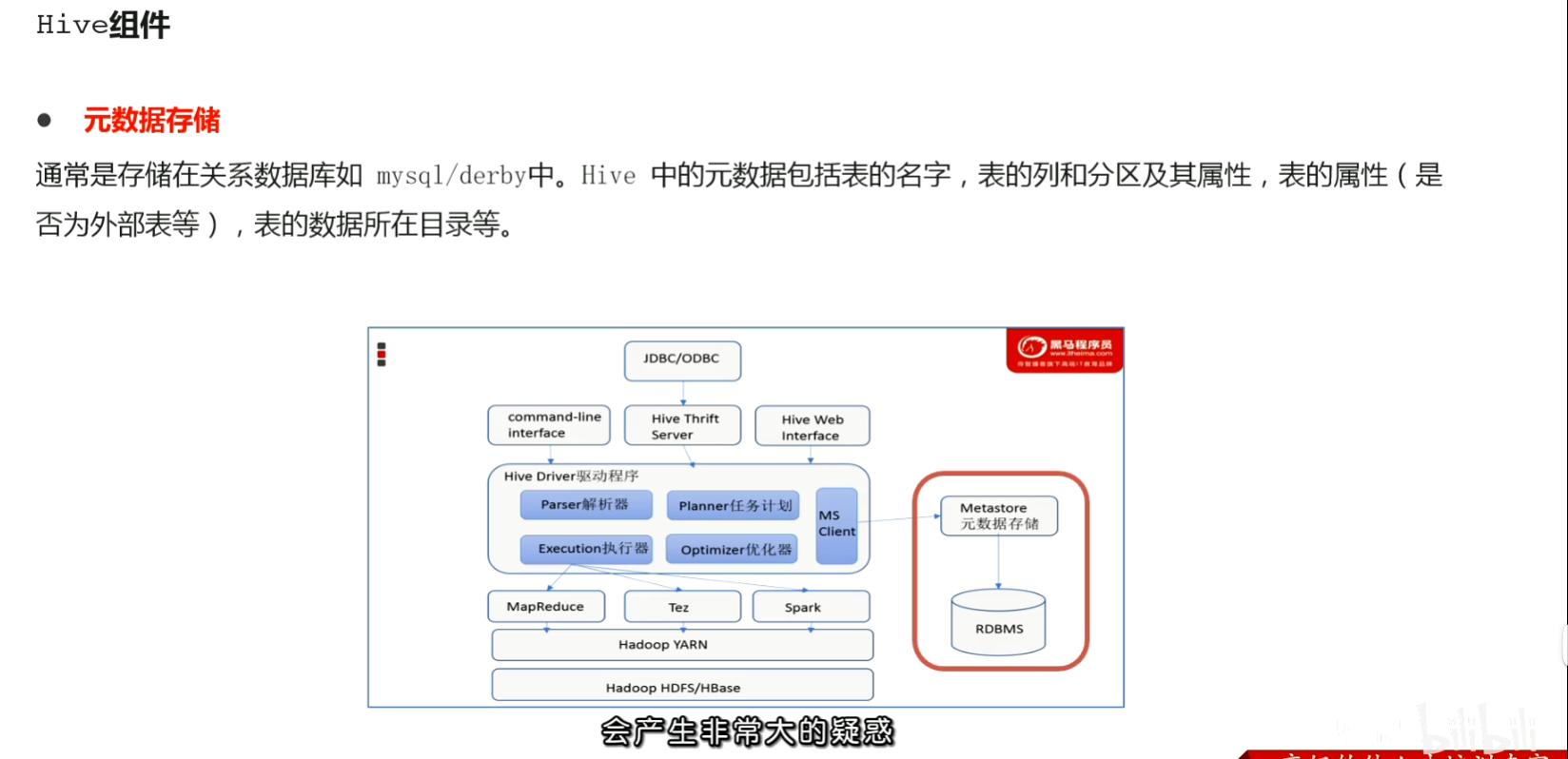


p58 hive安装部署 metadata与metastore 远程模式介绍

版权声明:本文为weixin_44229645原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。