Optimizing Video Object Detection via a Scale-Time Lattice Kai Chen1 Jiaqi Wang1 Shuo Yang1 CVPR2018
视频类目标检测相关工作:在VID挑战引入ImageNet之前,很少研究视频目标检测。后来Han等人提出Seq-NMS建立高置信度边界框序列并且将框重新评分为平均或者最大置信度。这个方阿飞你属于后期处理,所以需要在每一帧的检测外再额外的运行时间。Kang等人提出了整合每一帧的proposal 生成,边界框跟踪还有tubelet重评分。成本比较高。Zhu等人提出了DFF在固定的关键帧上用深度网络提取特征,然后用光流传播到其他帧。这个方法比在每一帧上检测提高了10倍速度,mAP也降低了4.4%(73.9%-69.5%),基于先前的方法,Zhu等人又提出了FGFA,沿着运动路径将附近的特征进行融合,以此提高特征质量,但是由于密集的检测和Flow的计算,导致运行速度较慢,在1fps左右。Feichtenhofe等人提出学习多任务的目标检测和跨帧跟踪,并将帧级检测和tubes连接起来,他们不研究时间传播,只在帧之间执行插值。
由粗到细方法:应用在人脸对齐,光流估计,语义分割,超分辨率等问题上,都是采用级联结构从低分辨率到高分辨率进行细化结果。本文的方法是采用2维的coarse-to-fine 习惯,包括时间和空间。
技术设计:
Propagation and Refinement Unit(PRU)
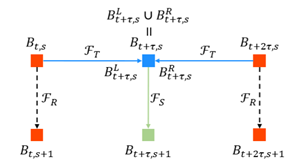

时间传播:这个理念在之前的视频检测结构中就提出来了,但是这些方法很多都依赖于光流去传播检测结果,尽管性能很好,这种方法对于实时系统来说是昂贵的,而且不适合长时间内对运动信息进行编码。本文采用的是历史运动图像(MHI)作为运动表示。

关键帧选择和路径计划:之前的关键帧选择是通过均匀采样的方法,但是却忽略了不是所有帧对检测和传播有效,所以非均匀采样可能更有效。本文提出了一个自适应选择方法,观察可得一些小的运动快的对象,时间传播的结果不如单帧检测,因此关键帧的密集程度取决于传播的难易程度,关键帧应该选择在出现小或者运动快的对象的帧上。首先在均匀采样的一些稀疏帧上运行检测器,然后基于对象尺度和运动评估结果传播是否
训练集:ImageNet VID 3862
training,555validation,30个类别,在ImageNet DET和VID数据集上训练检测器。
训练细节:Faster R-CNN作为基础检测器,ResNet-101时主干网络,RPN选取15个anchors,5个尺寸3个比例。在8个GPU上进行200k次迭代SGD,batch size为64,每次迭代一个GPU处理8个图片,前90个epochs学习率为0.02,后30个epochs学习率为0.002.最后的管道重评分主干网络是resnet-101,K=6
结果:mAP79.6 at 20fps,很好的权衡了计算成本和性能