算法-查找 & 排序
- ------------------------------ 二分查找 ------------------------------
- LeetCode:704. 二分查找
- ------------------------------ 哈希查找 ------------------------------
- LeetCode:1. 两数之和
- 剑指 Offer 03. 数组中重复的数字
- ------------------------------ LRU & LFU ------------------------------
- LeetCode: 460. LFU缓存
- LeetCode: 146. LRU缓存机制
- ------------------------------ 快速排序 ------------------------------
- ------------------------------ 归并排序 ------------------------------
- ------------------------------ 冒泡排序 ------------------------------
- LeetCode 912. 排序数组
------------------------------ 二分查找 ------------------------------
二分查找的八种写法必须掌握!!!
0. 二分查找框架
int binarySearch(int[] nums, int target) {
int left = 0, right = ...;
while(...) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
...
} else if (nums[mid] < target) {
left = ...
} else if (nums[mid] > target) {
right = ...
}
}
return ...;
}
分析二分查找的一个技巧是:不要出现 else,而是把所有情况用 else if 写清楚,这样可以清楚地展现所有细节。本文都会使用 else if,旨在讲清楚,读者理解后可自行简化。
其中…标记的部分,就是可能出现细节问题的地方,当你见到一个二分查找的代码时,首先注意这几个地方。后文用实例分析这些地方能有什么样的变化。
另外声明一下,计算 mid 时需要防止溢出,代码中left + (right - left) / 2就和(left + right) / 2的结果相同,但是有效防止了left和right太大直接相加导致溢出。
1. 基础二分搜索-查找一个数字
这个场景是最简单的,可能也是大家最熟悉的,即搜索一个数,如果存在,返回其索引,否则返回 -1。
/**
* 普通二分查找 <= && return -1;
*/
int binarySearch(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left <= right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target) return mid;
else if (nums[mid] < target) left = mid + 1; // 注意
else if (nums[mid] > target) right = mid - 1; // 注意
}
return -1;
}
// 基础二分查找及其变形
// 有界减1中加除2, 小于等于渐进-1
// 小于等于变小于, 左界比较再返-1
1. 为什么 while 循环的条件中是 <=,而不是 <?
因为初始化 right 的赋值是 nums.length - 1,即最后一个元素的索引,而不是 nums.length。
“<=” 和 “<” 可能出现在不同功能的二分查找中,区别是:前者相当于两端都为闭区间[left, right],后者相当于左闭右开区间[left, right)。我们这个算法中使用的是前者[left, right]两端都闭的区间,这个区间其实就是每次进行搜索的区间。
什么时候应该停止搜索呢?当然,找到了目标值的时候可以终止:
if(nums[mid] == target) return mid;
但如果没找到,就需要 while 循环终止,然后返回 -1。那 while 循环什么时候应该终止?搜索区间为空的时候应该终止,意味着你没得找了,就等于没找到嘛。
while(left <= right)的终止条件是left == right + 1,写成区间的形式就是[right + 1, right],或者带个具体的数字进去[3, 2],可见这时候区间为空,因为没有数字既大于等于 3 又小于等于 2 的吧。所以这时候 while 循环终止是正确的,直接返回 -1 即可。
while(left < right)的终止条件是left == right,写成区间的形式就是[left, right],或者带个具体的数字进去[2, 2],这时候区间非空,还有一个数 2,但此时 while 循环终止了。也就是说区间[2, 2]被漏掉了,索引 2 没有被搜索,如果这时候直接返回 -1 就是错误的。当然,如果你非要用while(left < right)也可以,我们已经知道了出错的原因,就打个补丁好了:
//...
while(left < right) {
// ...
}
// 搜索最后一个区间,判断并返回
return nums[left] == target ? left : -1;
改写为完整的二分查找时函数如下:
/**
* 普通二分查找 < && return -1;
*/
public int search(int[] nums, int target) {
int left = 0;
int right = nums.length - 1; // 注意
while(left < right) {
int mid = left + (right - left) / 2;
if(nums[mid] == target) return mid;
else if (nums[mid] < target) left = mid + 1; // 注意
else if (nums[mid] > target) right = mid - 1; // 注意
}
return nums[left] == target ? left : -1;
}
2. 为什么left = mid + 1,right = mid - 1?我看有的代码是right = mid或者left = mid,没有这些加加减减,到底怎么回事,怎么判断?
这也是二分查找的一个难点,不过只要你能理解前面的内容,就能够很容易判断。刚才明确了「搜索区间」这个概念,而且本算法的搜索区间是两端都闭的,即[left, right]。那么当我们发现索引mid不是要找的target时,下一步应该去搜索哪里呢?当然是去搜索[left, mid-1]或者[mid+1, right]对不对?因为mid已经搜索过,应该从搜索区间中去除。
3. 此算法有什么缺陷?
至此,你应该已经掌握了该算法的所有细节,以及这样处理的原因。但是,这个算法存在局限性。
比如说给你有序数组nums = [1,2,2,2,3],target为 2,此算法返回的索引是 2,没错。但是如果我想得到target的左侧边界,即索引 1,或者我想得到target的右侧边界,即索引 3,这样的话此算法是无法处理的。这样的需求很常见,你也许会说,找到一个 target,然后向左或向右线性搜索不行吗?可以,但是不好,因为这样难以保证二分查找"对数级"的复杂度了。
我们后续的算法就来讨论这两种二分查找的算法。
2. 寻找左侧边界的二分查找
以下是最常见的代码形式,其中的标记是需要注意的细节:
/**
* 搜索左边界的二分查找 < && 返回指定值索引或小于等于指定值的个数
*/
public int search(int[] nums, int target) {
int left = 0;
int right = nums.length; // 注意
while (left < right) { // 注意
int mid = (left + right) / 2;
if (nums[mid] == target) {
right = mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid; // 注意
}
}
return left;
}
// 左界二分查找及其变形
// 右界到底中除2, 小于中分再返做
1. 为什么 while 中是<而不是<=?
用相同的方法分析,因为right = nums.length而不是nums.length - 1。因此每次循环的「搜索区间」是[left, right)左闭右开。
while(left < right)终止的条件是left == right,此时搜索区间[left, left)为空,所以可以正确终止。
PS:这里先要说一个搜索左右边界和上面这个算法的一个区别,也是很多读者问的:刚才的right不是nums.length - 1吗,为啥这里非要写成nums.length使得「搜索区间」变成左闭右开呢?因为对于搜索左右侧边界的二分查找,这种写法比较普遍,我就拿这种写法举例了,保证你以后看到这类代码可以理解。其实你非要用两端都闭的写法反而更简单,我会在后面写相关的代码,把三种二分搜索都用一种两端都闭的写法统一起来,你耐心往后看就行了。
2. 为什么没有返回 -1 的操作?如果nums中不存在target这个值,怎么办?
因为要一步一步来,先理解一下这个「左侧边界」有什么特殊含义: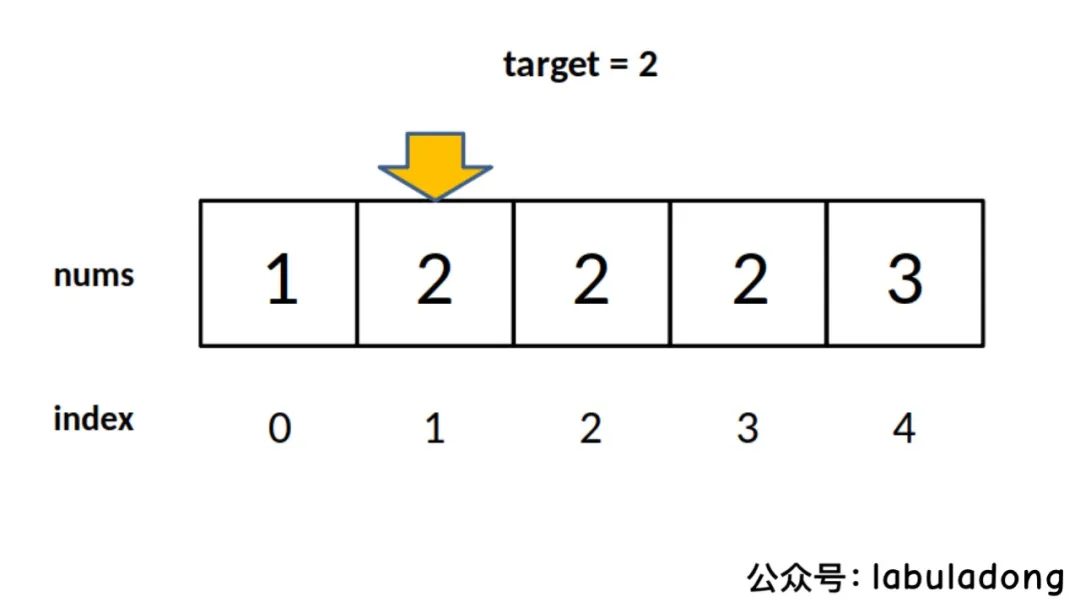
对于这个数组,算法会返回 1。这个 1 的含义可以这样解读:nums中小于 2 的元素有 1 个。
比如对于有序数组nums = [2,3,5,7],target = 1,算法会返回 0,含义是:nums中小于 1 的元素有 0 个。
再比如说nums = [2,3,5,7], target = 8,算法会返回 4,含义是:nums中小于 8 的元素有 4 个。
综上可以看出,函数的返回值(即left变量的值)取值区间是闭区间[0, nums.length],所以我们简单添加两行代码就能在正确的时候 return -1:
while (left < right) {
//...
}
// target 比所有数都大
if (left == nums.length) return -1;
// 类似之前算法的处理方式
return nums[left] == target ? left : -1;
改造完成后函数如下:
public int search(int[] nums, int target) {
int left = 0;
int right = nums.length; // 注意
while (left < right) { // 注意
int mid = (left + right) / 2;
if (nums[mid] == target) {
right = mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid; // 注意
}
}
if (left == nums.length) return -1;
return nums[left] == target ? left : -1;
}
3. 为什么left = mid + 1,right = mid?和之前的算法不一样?
这个很好解释,因为我们的「搜索区间」是[left, right)左闭右开,所以当nums[mid]被检测之后,下一步的搜索区间应该去掉mid分割成两个区间,即[left, mid)或[mid + 1, right)。
4. 为什么该算法能够搜索左侧边界?
关键在于对于nums[mid] == target这种情况的处理:
if (nums[mid] == target) right = mid;
5. 为什么返回left而不是right?
都是一样的,因为 while 终止的条件是left == right。
6. 能不能想办法把right变成nums.length - 1,也就是继续使用两边都闭的「搜索区间」?这样就可以和第一种二分搜索在某种程度上统一起来了。
答:当然可以,只要你明白了「搜索区间」这个概念,就能有效避免漏掉元素,随便你怎么改都行。下面我们严格根据逻辑来修改:
因为你非要让搜索区间两端都闭,所以right应该初始化为nums.length - 1,while 的终止条件应该是left == right + 1,也就是其中应该用<=:
int left_bound(int[] nums, int target) {
// 搜索区间为 [left, right]
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
// if else ...
}
}
因为搜索区间是两端都闭的,且现在是搜索左侧边界,所以left和right的更新逻辑如下:
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
} else if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
} else if (nums[mid] == target) {
// 收缩右侧边界
right = mid - 1;
}
由于 while 的退出条件是left == right + 1,所以当target比nums中所有元素都大时,会存在以下情况使得索引越界: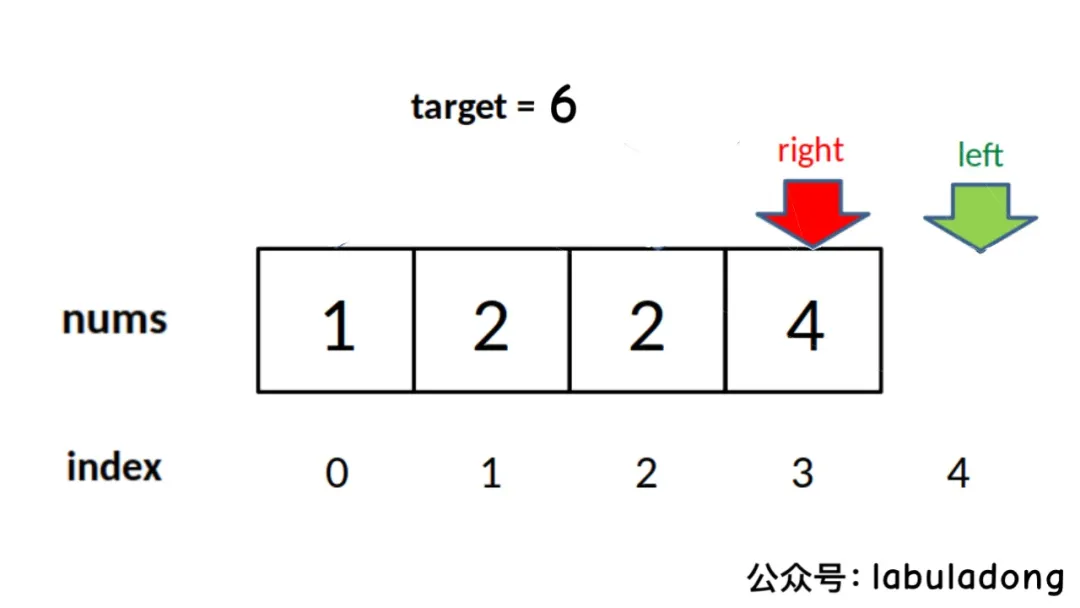
因此,最后返回结果的代码应该检查越界情况:
if (left >= nums.length || nums[left] != target) return -1;
return left;
至此,整个算法就写完了,完整代码如下:
public int search(int[] nums, int target) {
int left = 0, right = nums.length - 1;
// 搜索区间为 [left, right]
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
// 搜索区间变为 [mid+1, right]
left = mid + 1;
} else if (nums[mid] > target) {
// 搜索区间变为 [left, mid-1]
right = mid - 1;
} else if (nums[mid] == target) {
// 收缩右侧边界
right = mid - 1;
}
}
// 判断左指针是否越界
if (left >= nums.length || nums[left] != target) return -1;
return left;
}
这样就和第一种二分搜索算法统一了,都是两端都闭的「搜索区间」,而且最后返回的也是left变量的值。只要把住二分搜索的逻辑,两种形式大家看自己喜欢哪种记哪种吧。
3. 寻找右侧边界的二分查找
类似寻找左侧边界的算法,这里也会提供两种写法,还是先写常见的左闭右开的写法,只有两处和搜索左侧边界不同,已标注:
int right_bound(int[] nums, int target) {
if (nums.length == 0) return -1;
int left = 0, right = nums.length;
while (left < right) {
int mid = (left + right) / 2;
if (nums[mid] == target) {
left = mid + 1; // 注意
} else if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid;
}
}
return left - 1; // 注意
}
3.1 为什么这个算法能够找到右侧边界?
类似地,关键点还是这里:
if (nums[mid] == target) {
left = mid + 1;
}
当nums[mid] == target时,不要立即返回,而是增大「搜索区间」的下界left,使得区间不断向右收缩,达到锁定右侧边界的目的。
3.2 为什么最后返回left - 1而不像左侧边界的函数,返回left?而且我觉得这里既然是搜索右侧边界,应该返回right才对。
首先,while 循环的终止条件是left == right,所以left和right是一样的,你非要体现右侧边界的特点,返回 right - 1 好了。
至于为什么要减一,这是搜索右侧边界的一个特殊点,关键在这个条件判断:
if (nums[mid] == target) {
left = mid + 1;
// 这样想: mid = left - 1
}
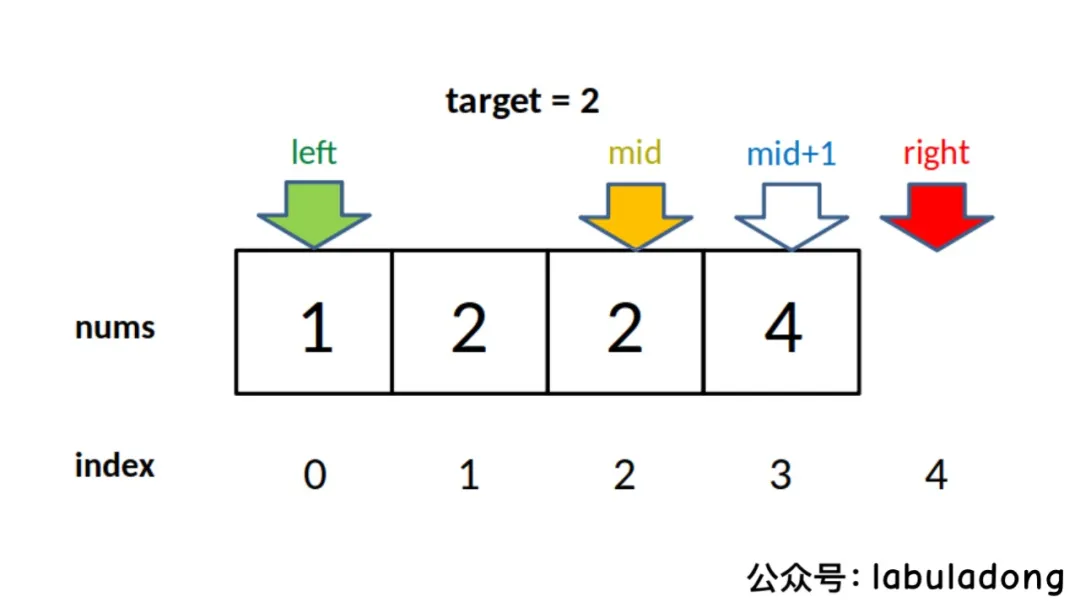
因为我们对left的更新必须是left = mid + 1,就是说 while 循环结束时,nums[left]一定不等于target了,而nums[left-1]可能是target。至于为什么left的更新必须是left = mid + 1,同左侧边界搜索,就不再赘述。
3.3 为什么没有返回 -1 的操作?如果nums中不存在target这个值,怎么办?
答:类似之前的左侧边界搜索,因为 while 的终止条件是left == right,就是说left的取值范围是[0, nums.length],所以可以添加两行代码,正确地返回 -1:
while (left < right) {
// ...
}
if (left == 0) return -1;
return nums[left-1] == target ? (left-1) : -1;
完整的右侧边界搜索函数如下:
public int search(int[] nums, int target) {
if (nums.length == 0) return -1;
int left = 0;
int right = nums.length;
while (left < right) {
int mid = (left + right) / 2;
if (nums[mid] == target) left = mid + 1;
else if (nums[mid] < target) left = mid + 1;
else if (nums[mid] > target) right = mid;
}
if (left == 0) return -1;
return nums[left - 1] == target ? left - 1 : -1;
}
3.4 是否也可以把这个算法的「搜索区间」也统一成两端都闭的形式呢?这样这三个写法就完全统一了,以后就可以闭着眼睛写出来了。
答:当然可以,类似搜索左侧边界的统一写法,其实只要改两个地方就行了:
int right_bound(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] < target) {
left = mid + 1;
} else if (nums[mid] > target) {
right = mid - 1;
} else if (nums[mid] == target) {
// 这里改成收缩左侧边界即可
left = mid + 1;
}
}
// 这里改为检查 right 越界的情况,见下图
if (right < 0 || nums[right] != target)
return -1;
return right;
}
当target比所有元素都小时,right会被减到 -1,所以需要在最后防止越界: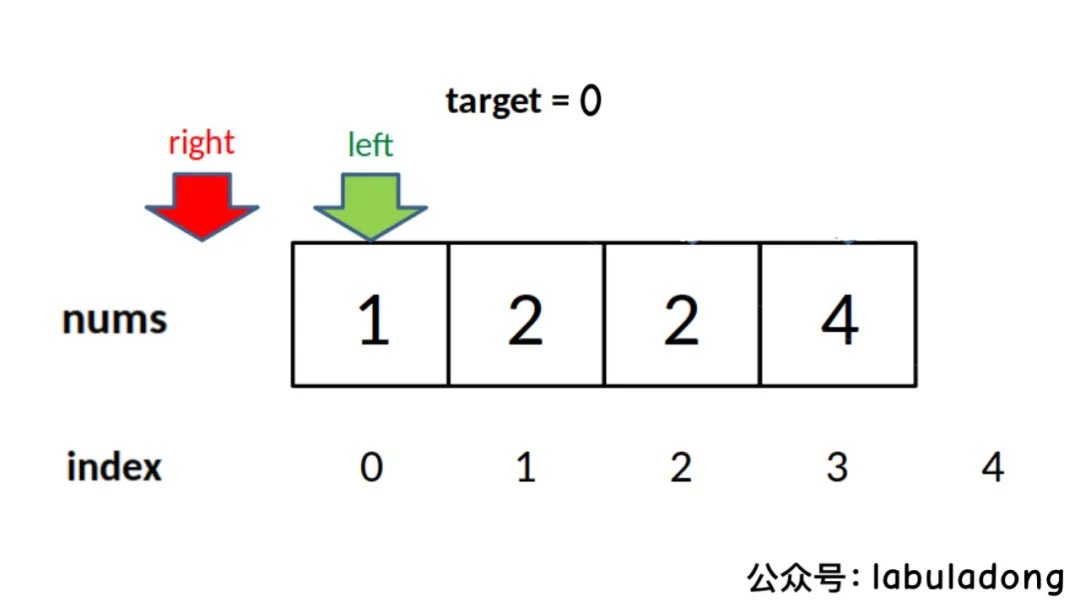
至此,搜索右侧边界的二分查找的两种写法也完成了,其实将「搜索区间」统一成两端都闭反而更容易记忆,你说是吧?
4. 逻辑统一
来梳理一下这些细节差异的因果逻辑:
第一个,最基本的二分查找算法:
因为我们初始化 right = nums.length - 1
所以决定了我们的「搜索区间」是 [left, right]
所以决定了 while (left <= right)
同时也决定了 left = mid+1 和 right = mid-1
因为我们只需找到一个 target 的索引即可
所以当 nums[mid] == target 时可以立即返回
第二个,寻找左侧边界的二分查找:
因为我们初始化 right = nums.length
所以决定了我们的「搜索区间」是 [left, right)
所以决定了 while (left < right)
同时也决定了 left = mid + 1 和 right = mid
因为我们需找到 target 的最左侧索引
所以当 nums[mid] == target 时不要立即返回
而要收紧右侧边界以锁定左侧边界
第三个,寻找右侧边界的二分查找:
因为我们初始化 right = nums.length
所以决定了我们的「搜索区间」是 [left, right)
所以决定了 while (left < right)
同时也决定了 left = mid + 1 和 right = mid
因为我们需找到 target 的最右侧索引
所以当 nums[mid] == target 时不要立即返回
而要收紧左侧边界以锁定右侧边界
又因为收紧左侧边界时必须 left = mid + 1
所以最后无论返回 left 还是 right,必须减一
如果以上内容你都能理解,那么恭喜你,二分查找算法的细节不过如此。
通过本文,你学会了:
1、分析二分查找代码时,不要出现 else,全部展开成 else if 方便理解。
2、注意「搜索区间」和 while 的终止条件,如果存在漏掉的元素,记得在最后检查。
3、如需定义左闭右开的「搜索区间」搜索左右边界,只要在nums[mid] == target时做修改即可,搜索右侧时需要减一。
4、如果将「搜索区间」全都统一成两端都闭,好记,只要稍改nums[mid] == target条件处的代码和返回的逻辑即可,推荐拿小本本记下,作为二分搜索模板。
二分查找-小于记忆口诀(左界小于、右界小于、左界小于越界、右界小于越界):
二分小于看边界,右界到底中二除。
左界查找右逼近,右界查找左逼近。
小于右界须取中,等于右界须减一。
若取边界则返回,不取边界看越界。
左无越界再返回,有无越界再返回。
返回还需分左右,左界原值右减一。
二分查找-小于等于记忆口诀(包括普通小于等于、左界小于等于及其越界、右界小于等于及其越界):
小于等于看边界,右界减1中加除2。
普通查找用渐进,边界查找分左右。
左界查找右逼近,右界查找左逼近。
左无越界再返回,右无越界再返回。
5. 参考资料
LeetCode:704. 二分查找
相关题目
------------------------------ 哈希查找 ------------------------------
LeetCode:1. 两数之和
解法一:一遍哈希表
记忆口诀:遍历数组取减值,数组Map互颠倒
遍历数组nums,将数组中的各个元素放入map(以数组值nums[i]为map的key,以数组下标i为map的value);
在向map中添加元素之前,先检查map中是否包含(target-nums[i])的值;
若包含(target-nums[i])的值,说明查找到对应的两个数,返回其下标;
若未包含(target-nums[i])的值,则将数组对应元素nums[i]放入map中;
若遍历完数组,map中都不含对应两个元素,说明数组中不存在这样的两个元素,返回为空;
- 时间复杂度:O(n)
遍历包含n个元素的数组,所以时间复杂度为O(n);map中的查找由于是hash的过程,所以查找时间复杂度为O(1) - 空间复杂度:O(n)
创建了大小为n的map,所以空间复杂度为O(n)
Golang: one-hash
解法二:两遍哈希表
遍历数组nums,将数组中的各个元素放入map(以数组值nums[i]为key,以数组下标为value);
遍历数组nums,以数组nums为基准,判定(target-nums[i])的值是否包含在map中;
若(target-nums[i])的值包含在map中,则说明数组中包含对应的两个元素,返回其下标;
若遍历完数组nums,都不包含对应的两个元素,则返回为空;
- 时间复杂度:O(n)
时间复杂度主要消耗在数组的遍历过程,数组长度为n,所以遍历数组的时间复杂度为O(n); - 空间复杂度:O(n)
空间复杂度主要消耗在map中,map的长度为数组的长度,所以空间复杂度为O(n);
Golang: two-hash
剑指 Offer 03. 数组中重复的数字
------------------------------ LRU & LFU ------------------------------
LeetCode: 460. LFU缓存
LFU算法的定义
LFU: Least Frequently Used, 最近最少使用算法。它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。
注意LRU和LFU算法的不同之处,LRU的淘汰规则是基于访问时间,而LFU是基于访问次数,举个简单的例子:
假设缓存大小为3,数据访问序列为set(2,2),set(1,1),get(2),get(1),get(2),set(3,3),set(4,4),
则在set(4,4)时对于LFU算法应该淘汰(3,3),而LRU应该淘汰(1,1)。
那么LFU Cache应该支持的操作为:
get(key):如果Cache中存在该key,则返回对应的value值;否则,返回-1;
set(key,value):如果Cache中存在该key,则重置value值;如果不存在该key,则将该key插入到到Cache中;若Cache已满,则淘汰最少访问的数据;若最少访问的数据有多个,则淘汰访问时间最久的数据;
关于LFU算法更详细的定义,可参考如下文档:
缓存算法(页面置换算法)-FIFO、LFU、LRU
FIFO/LRU/LFU三种缓存算法
LFU
LFU算法的实现
关于LFU算法更多的实现策略,可参考如下文档:
LFU缓存
FIFO/LRU/LFU三种缓存算法
方法一:使用LinkedHashSet实现LFUCache
为了能够淘汰最少使用的数据,因此LFU算法最简单的一种设计思路就是 利用一个数组存储 数据项,用hashmap存储每个数据项在数组中对应的位置,然后为每个数据项设计一个访问频次,当数据项被命中时,访问频次自增,在淘汰的时候淘汰访问频次最少的数据。这样一来的话,在插入数据和访问数据的时候都能达到O(1)的时间复杂度,在淘汰数据的时候,通过选择算法得到应该淘汰的数据项在数组中的索引,并将该索引位置的内容替换为新来的数据内容即可,这样的话,淘汰数据的操作时间复杂度为O(n)。
方法二:使用LinkedHashMap实现LFUCache
方法三:最佳复杂度
LeetCode: 146. LRU缓存机制
LRU算法的定义
LRU:Least Recently Used),最近最久使用算法。在向缓存中添加数据时,若缓存已满,则选择最近最少使用的数据淘汰,并添加新数据到该位置;
此处以内存访问为例说明缓存的工作原理: 对于大小固定的缓存,初始状态为空;
每发生一次读取操作,便从缓存中查找是否包含对应的数据;若缓存中包含对应的数据,则缓存命中并返回;否则缓存未命中,则从内存中读取数据,然后将该数据添加到缓存中,并返回该数据;
在向缓存中添加数据时,若缓存未满,则直接按照hash算法添加该数据;若缓存已满,则从缓存中找出访问时间最长的那条数据并删除,然后添加新数据到该位置
LRU算法的实现
LRU算法的难点在于: 在O(1)的时间复杂度内,实现对缓存的读写操作。
对于读操作,可以使用HashMap达到O(1)时间复杂度的性能要求
对于写操作,可以使用HashMap+双向链表达到O(1)时间复杂度的性能要求,因此可以使用HashMap+双向链表来实现LRU Cache;同时Java API中LinkedHashMap采用HashMap+双向链表的方式实现,因此也可以使用LinkedHashMap来实现LRU Cache。
所以,对于LRU算法的实现方式,可以总结如下:
- HashMap + 双向链表
- LinkedHashMap = HashMap + 双向链表
1. HashMap + 双向链表实现LRUCache
Java
相关要点
- 读缓存时从HashMap中查找key,再根据key查找对应数据节点;更新缓存时同时更新HashMap和双向链表,双向链表始终按照访问时间的先后顺序排列,访问时间越早的数据节点排在双向链表的越前面
- 双向链表的头结点指向访问时间较早的数据节点,双向链表的尾节点指向访问时间较晚的数据节点
- 读缓存时,若缓存命中,则将命中的数据节点移动到双向链表的尾部,然后返回该数据节点的值;否则返回-1;
- 写缓存且缓存命中时,更新缓存值,并将该数据节点移动到双向链表的尾部
- 写缓存且缓存未命中时,若缓存已满,则删除双向链表头部的数据节点(最近最少使用),然后将新添加的数据节点插入到双向链表的尾部
- 写缓存且缓存未命中时,若缓存未满,则直接将新插入的数据节点添加到双向链表的尾部
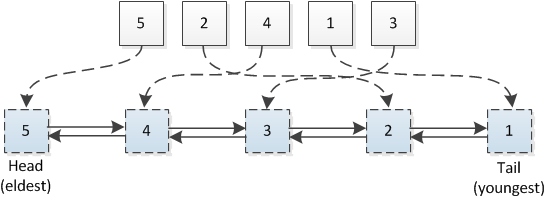
参考代码: LRUCache_HashMap_LinkList.java
Go
相关要点
- 读缓存时从HashMap中查找key,再根据key查找对应数据节点;更新缓存时同时更新HashMap和双向链表;双向链表始终按照访问时间的先后顺序排列,访问时间越晚的数据节点排在双向链表的越前面
- 链表头部存放访问时间最晚的数据节点,链表尾部存放访问时间最早的数据节点
- 读缓存,若缓存命中, 则将命中元素移动到链表头部, 并返回该元素; 否则返回-1
- 写缓存,若缓存命中, 则更新链表头部元素
- 写缓存,若缓存未命中且缓存已满, 则发生LRU替换, 删除最近最久未被访问元素(链表尾部),然后添加数据节点到链表头部
- 写缓存,若缓存未命中且缓存未满,则直接插入新数据节点到链表头部
参考代码: lru-cache.go
2. LinkedHashMap实现LRUCache
参考代码: LRUCache_LinkedHashMap.java
LRU算法的应用
- Redis中缓存淘汰策略
面试相关
Go相关面试题
- 实现一个固定大小的元素为string的LRU队列
参考文档
LRU缓存算法
如何设计实现一个LRU Cache?
[LeetCode]146.LRU缓存机制
------------------------------ 快速排序 ------------------------------
记忆口诀:
快排也需看边界,右界减一中二除。
左右指针逼近中,左右也要用快排。
指针相遇要调整,交换之后再逼近。
------------------------------ 归并排序 ------------------------------
算法思想
归并排序利用分治思想和二分思想,在数据的分割上利用二分思想,在数据的合并及排序上利用分治思想
归并排序基于分治思想,将多个已排好序的数组合并成一个有序的数组.
归并排序的分类
二路归并排序
具体做法为:遍历两个数组,比较它们的值。谁比较小,谁先放入大数组中,直到数组遍历完成
多路归并排序
算法复杂度
平均时间复杂度:O(nlogn)
参考代码
Java参考代码: MergeSort.java
Go参考代码: merge_sort_test.go
参考文档
归并排序就这么简单
归并排序及优化(Java实现)
Go数据结构与算法-归并排序
------------------------------ 冒泡排序 ------------------------------
记忆口诀:双层比较并交换,内层-i-1外层-1
public static void bubbleSort(int[] arrays) {
int temp;
//外层循环是排序的趟数
for (int i = 0; i < arrays.length - 1 ; i++) {
//内层循环是当前趟数需要比较的次数
for (int j = 0; j < arrays.length - i - 1; j++) {
//前一位与后一位比较,如果前一位比后一位要大,那么交换
if (arrays[j] > arrays[j + 1]) {
temp = arrays[j];
arrays[j] = arrays[j + 1];
arrays[j + 1] = temp;
}
}
}
}
冒泡排序就这么简单
如何理解算法时间复杂度的表示法,例如 O(n²)、O(n)、O(1)、O(nlogn) 等?
(数据结构)十分钟搞定时间复杂度(算法的时间复杂度)