斯坦福大学自然语言处理第一课“引言(introduction)”
1.课程介绍
斯坦福大学于2012年3月在Coursera启动了在线自然语言处理课程,由NLP领域大牛Dan Jurafsky 和 Chirs Manning教授授课:
https://class.coursera.org/nlp/
以下为个人的一些学习笔记或归纳。
2.自然语言处理(NLP)相关技术及应用
- 自动问答(Question Answering,QA)
- 信息抽取(Information Extraction,IE)
- 情感分析(Sentiment Analysis,SA)
- 机器翻译(Machine Translation,MT)
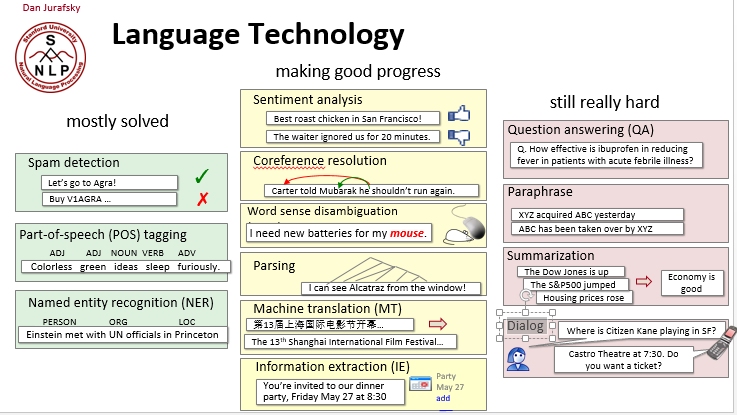
3.自然语言处理(NLP)的发展现状
- 基本解决(mostly solved):
- 垃圾邮件检测 spam detection
- 词性标注 Part-of-speech (POS) tagging
- 命名实体标注 Named entity recognition (NER)
取得长足进步(making good progress)
- 情感分析 Sentiment analysis
- 指代消解 Coreference resolution
- 词义消歧 Word sense disambiguation
- 语法分析 Parsing
- 机器翻译 Machine translation (MT)
- 信息抽取 Information extraction (IE)
尚需努力 (still really hard)
- 自动问答 Question answering (QA)
- 释义 Paraphrase
- 文摘 Summarization
- 会话机器人 Dialog
4.自然语言难点
- 最主要难点:歧义
- 简写( see u…),口语等非标准化词语 non-standard English
- 分词切词问题 segmentation issues
- 方言 idioms
- 多样的实体词 tricky entity names
。。。

5.本课关键理论及方法
主要运用概率模型(probabilistic model)或称为统计模型(statistical model)进行建模,其基于大规模的真实预料库
- Viterbi
- 贝叶斯和最大熵分类器 Naïve Bayes, Maxent classifiers
- N-gram语言模型 N-gram language modeling
- 统计分析 Statistical Parsing
- Inverted index, tf-idf, vector models of meaning
用于解决信息提取(Information extraction),信息检索(Information retrieval),拼写矫正(Spelling correction),情感分析(Sentiment analysis)等问实际问题
版权声明:本文为IOThouzhuo原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。