Poster: Detection of Cyberbullying in a Mobile Social Network: Systems Issues
在移动社交网络中检测网络欺凌:系统问题
学习使用,如有侵权联系删除~
ABSTRACT
Cyberbullying is a major problem affecting more than half of all American teens, and has been attributed to suicidal behavior among teens. Instagram, a media-based mobile social network, is one of the most popular social networks used for cyberbullying. In this paper, we describe the development of classifiers to detect cyberbullying in Instagram. We identify systems issues that need to be considered in the design of a cyberbullying detection system.
网络欺凌是影响一半以上美国青少年的主要问题,并被归因于青少年的自杀行为。 Instagram 是一个基于媒体的移动社交网络,是用于网络欺凌的最流行的社交网络之一。在本文中,我们描述了检测 Instagram 中网络欺凌的分类器的发展。我们确定了在设计网络欺凌检测系统时需要考虑的系统问题。
1、INTRODUCTION
Cyberbullying has been defined as intentionally aggressive behavior that is repeatedly carried out in an online context against a person who cannot easily defend him or herself [1]. It is important to this definition of cyberbullying that both the frequency of negativity and the imbalance of power between the victim and perpetrator be taken into account. Prior work has either largely ignored this proper definition, labeling data according to a looser definition of cyberaggression that ignores frequency and imbalance of power, or simply analyzed negative word usage without labeling [2].
网络欺凌被定义为在网络环境中针对无法轻易为自己辩护的人反复进行的故意攻击性行为 [1]。对于这种网络欺凌的定义,重要的是要考虑负面的频率以及受害者和施暴者之间的权力不平衡。先前的工作要么在很大程度上忽略了这个正确的定义,而是根据网络攻击的更宽松的定义来标记数据,这种定义忽略了频率和权力的不平衡,或者只是在没有标记的情况下分析了负面词的使用 [2]。
We applied this stricter definition of cyberbullying to labeling of Instagram data collected from 25K Instagram users. These public profiles were collected using a snowball sampling method, resulting in 697K media sessions (images plus associated comments). We chose a subset of the media sessions with the highest percentage of negativity, i.e. those with more than 40% of comments with at least one negative word (and a minimum of 15 comments total), since such highly negative media sessions should give us a higher likelihood of identifying cyberbullying. This gave us about 1000 media sessions, which were labeled by workers on CrowdFlower according to our stricter definition of cyberbullying.
我们将这一更严格的网络欺凌定义应用于从 25,000 个 Instagram 用户收集的 Instagram 数据的标签。这些公开资料是使用滚雪球抽样方法收集的,产生了 697K 媒体会话(图像和相关评论)。我们选择了负面百分比最高的媒体会话子集,即那些有超过 40% 的评论至少有一个负面词(总共至少 15 条评论)的媒体会话,因为这种高度负面的媒体会话应该给我们一个识别网络欺凌的可能性更高。这给了我们大约 1000 个媒体会话,这些会话由 CrowdFlower 上的工作人员根据我们对网络欺凌的更严格定义进行标记。
To design and train the classifier, our ground truth criterion was that if a media session was labeled by three out of five workers as cyberbullying, then the media session was seen as cyberbullying. This resulted in 52% of media sessions being labeled as cyberbullying. Three types of features were evaluated, namely those features obtained from the content of comments, images and graph properties based on the pro-file owner. Unigrams and lower case 3-grams were used asinput features for SVM while image features and the num-ber of followers, followed by’s and likes were inputs for theNa¨ıve Bayes classifier. The Table shows that the SVM classi-fier achieves high accuracy, precision and recall above 80%.
为了设计和训练分类器,我们的基本事实标准是,如果一个媒体会话被五分之三的工作人员标记为网络欺凌,那么该媒体会话被视为网络欺凌。这导致 52% 的媒体会话被标记为网络欺凌。三种类型的特征是评估,即根据配置文件所有者从评论、图像和图形属性的内容中获得的那些特征。 Unigrams 和小写 3-grams 被用作 SVM 的输入特征,而图像特征和追随者的数量,其次是和喜欢是朴素贝叶斯分类器的输入。该表显示,SVM 分类器实现了 80% 以上的高准确率、准确率和召回率。
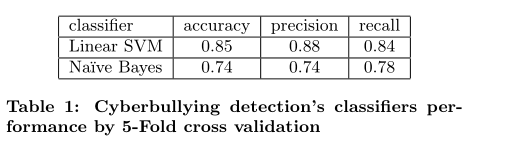
Our performance evaluation of the classifiers found that Na¨ıve Bayes is about 32K times faster than SVM in the training phase, and is about 4K times faster than SVM in the prediction phase, the latter of which is what would be experienced when running the classifiers online. However, these values don’t consider feature extraction time. Na¨ıve Bayes is currently trained on images manually labeled as people, car, tattoo, etc. We would need to develop automated image processing algorithms that can extract these image categories, which is compute-intensive. A typical N-gram is also compute-intensive, with dimensionality of ˜300K.
我们对分类器的性能评估发现,朴素贝叶斯在训练阶段比 SVM 快约 32K 倍,在预测阶段比 SVM 快约 4K 倍,后者是运行分类器时所经历的在线的。但是,这些值没有考虑特征提取时间。朴素贝叶斯目前正在对手动标记为人、汽车、纹身等的图像进行训练。我们需要开发能够提取这些图像类别的自动图像处理算法,这是计算密集型的。典型的 N-gram 也是计算密集型的,维数约为 300K。
To build a scalable system for cyberbullying detection in Instagram, which has over 300 million active users, we propose a distributed mobile cloud architecture that enables scaling while avoiding overloading of cloud servers with too much classification. First, users’ mobile devices will prefilter all user media sessions that have insufficient negativity, e.g. in our sample, this drastically cuts the number of media sessions to be processed by the cloud server from 700K down to the 1000 most negative media sessions. Next, for these sessions, image and/or text feature extraction is also performed on the mobile. Finally, only these features are sent to the cloud server for classification. This hybrid mobile+cloud architecture better enables the server to scale to meet the demands of near real-time cyberbullying detection.
为了在拥有超过 3 亿活跃用户的 Instagram 中构建一个可扩展的网络欺凌检测系统,我们提出了一种分布式移动云架构,该架构能够在避免分类过多的云服务器过载的同时实现扩展。首先,用户的移动设备会预先过滤所有负面性不足的用户媒体会话,例如在我们的示例中,这将云服务器要处理的媒体会话数量从 700K 大幅减少到 1000 个最负面的媒体会话。接下来,对于这些会话,图像和/或文本特征提取也在移动设备上执行。最后,只有这些特征被发送到云服务器进行分类。这种混合移动+云架构更好地使服务器能够扩展以满足近实时网络欺凌检测的需求。
2、References
[1] Kowalski, R. M.; Limber, S.; Limber, S. P.; and Agatston,P. W. 2012. Cyberbullying: Bullying in the digital age. John
Wiley and Sons.
[2] H. Hosseinmardi, R. Rafiq, S. Li, Z. Yang, R. Han, Q. Lv and S. Mishra, ”A Comparison of Common Users across Instagram
and Ask.fm to Better Understand Cyberbullying”. The 7th IEEE Intl. Conf. on Social Computing and Networking (SocialCom),
Dec. 2014.