- Seq2Seq
Seq2Seq模型是输出的长度不确定时采用的模型。
seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码。decoder则负责根据语义向量生成指定的序列,这个过程也称为解码。

获取语义向量的一种方式是直接将最后一个输入的隐藏状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
一种decoder的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列,上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关;另外一种是语义向量C参与了序列所有时刻的运算,上一时刻的输出作为当前时刻的输入,且语义向量C会参与所有时刻的运算。
所以模型的关键在于向量C能否很好的表达encode过程中序列的信息。
- Attention+ Seq2Seq
当输入句子很长的时候,encoder的效果会很差,利用隐状态(context向量)来编码输入句子的语义实际上是很困难的。为了解决这个问题,Bahdanau等人提出了注意力机制(attention mechanism)。于是在Decoder进行t时刻计算的时候,除了t-1时刻的隐状态,当前时刻的输入,注意力机制还可以参考Encoder所有时刻的输入。


其中α01![]() 是h01
是h01![]() 对应的权重,对所有权重α0
对应的权重,对所有权重α0![]() 进行softmax后得到α0
进行softmax后得到α0![]() ,α0
,α0![]() 和h0
和h0![]() 加权求和,得到c0
加权求和,得到c0![]() 。
。
α![]() 的计算:αts= score(ht,hs)
的计算:αts= score(ht,hs)![]()
α![]() 的计算:αts=exp(score(ht,hs))s'=1Sexp(score(ht,hs'))
的计算:αts=exp(score(ht,hs))s'=1Sexp(score(ht,hs'))![]()
c![]() 的计算:Ct=sαtshs
的计算:Ct=sαtshs![]()
可以看到Encoding和decoding阶段仍然是rnn,但是decoding阶段使用attention的输出结果段c0![]() ,c0
,c0![]() 作为rnn的输入。
作为rnn的输入。
Attention函数的本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射,如下图。
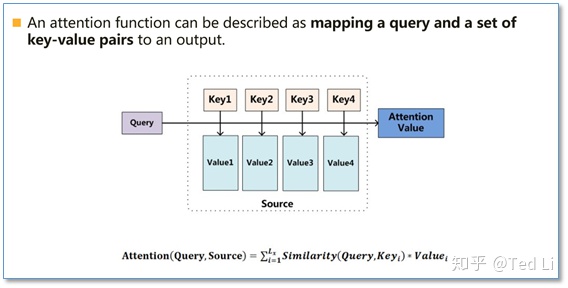
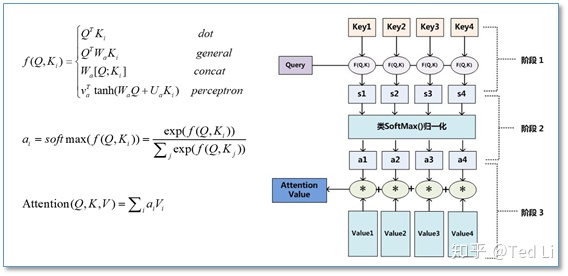
在计算attention时主要分为三步,第一步是将query和每个key进行相似度计算得到权重,即:score函数。常用的score函数有点积,拼接,感知机等;然后第二步一般是使用一个softmax函数对这些权重进行归一化;最后将权重和相应的键值value进行加权求和得到最后的attention。
(Attention模型使用①输出当前位置的隐状态与②输入所有位置的隐状态计算匹配程度,并根据匹配程度对③输入所有位置的隐状态进行加权求和得到context vector。)
上面所说的score函数中,dot就是简单的hidden*encoder outputs,注意这里是用的dot点乘,就是对应位置元素相乘再求和,所以两个向量点乘的结果是一个数。general将encoder output用一个全连接编码后再和hidden点乘。concat是将hidden和outputs连接后再点乘一个随机生成的向量。
简而言之,attention实际上就是一种取权重求和的过程。结果是使得 跟 当前词 有关的 前文的 部分词 具有较强的权重。
- Transformer
transformer的核心组件self-attention。
说起self-attention的提出,是因为rnn存在无法并行计算的问题,而cnn存在无法捕获长距离特征的问题,因为既要又要的需求,当看到attention的巨大优势,《Attention is all you need》的作者决定用attention机制代替rnn搭建整个模型,于是Multi-headed attention,横空出世。
Self-attention的意思就是自己和自己做attention,即K=V=Q,例如输入一个句子,那么里面的每个词都要和该句子中的所有词进行attention计算。目的是学习句子内部的词依赖关系,捕获句子的内部结构。
而Multi-head Attention其实就是多个Self-Attention结构的结合,每个head学习到在不同表示空间中的特征。
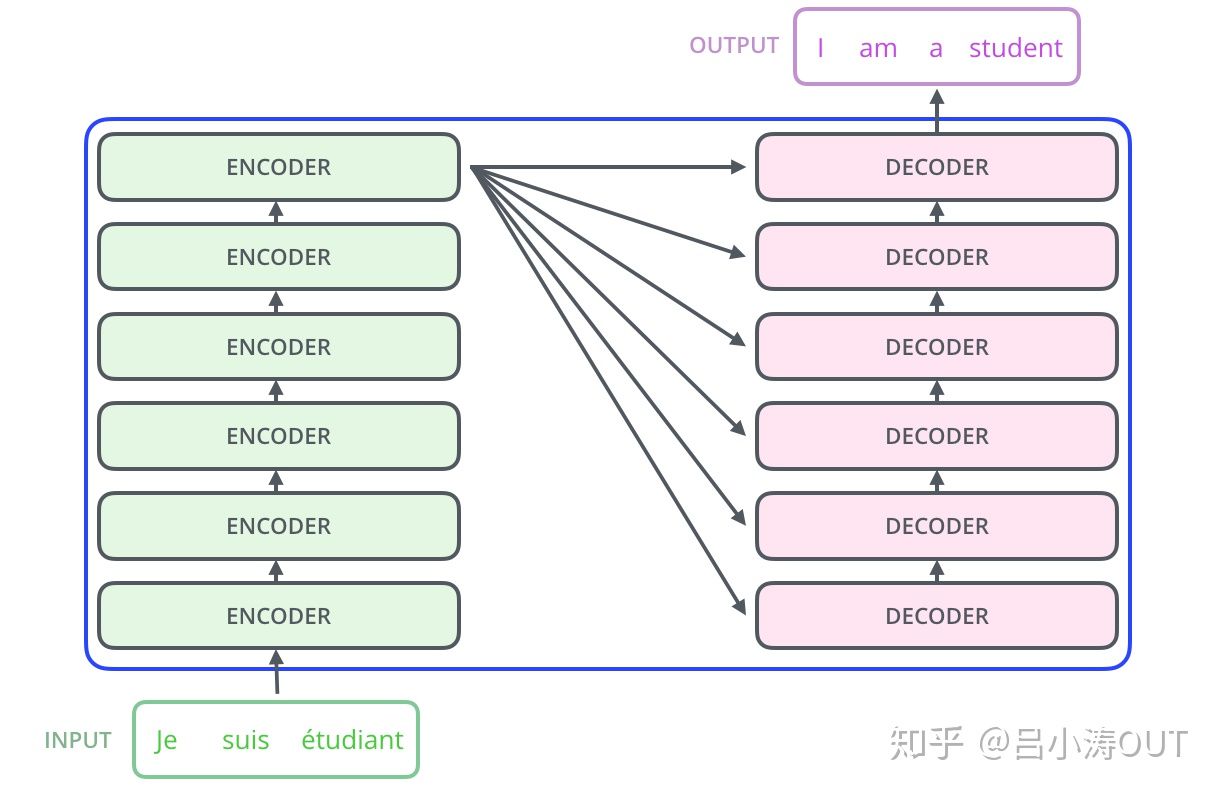
直接上transformer的结构图。
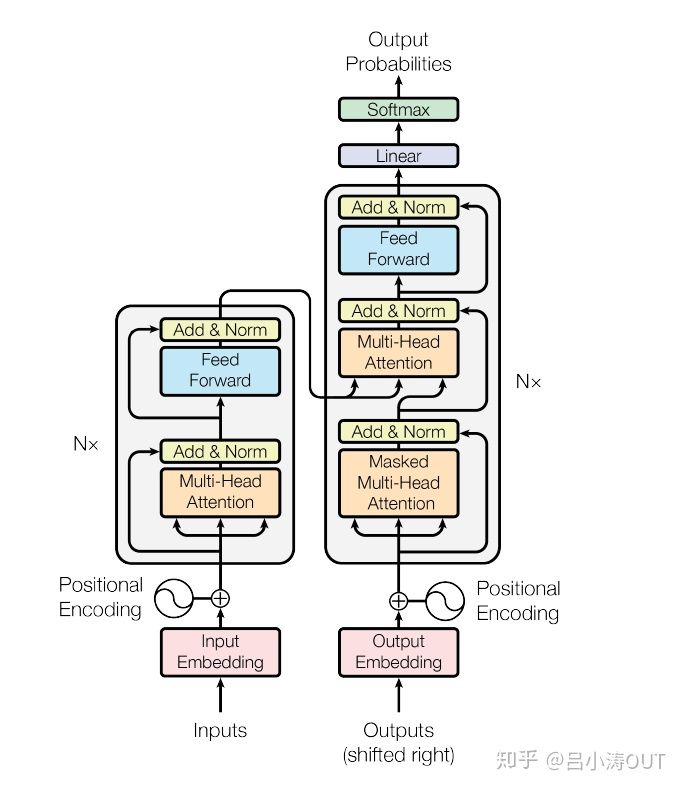
编码组件部分由一堆编码器(encoder)构成(论文中是将6个编码器叠在一起——数字6没有什么神奇之处,你也可以尝试其他数字)。解码组件部分也是由相同数量(与编码器对应)的解码器(decoder)组成的。
所有的ENCODER结构是相同的,但是不共享权重。每个编码器都可以分解成两个子层。
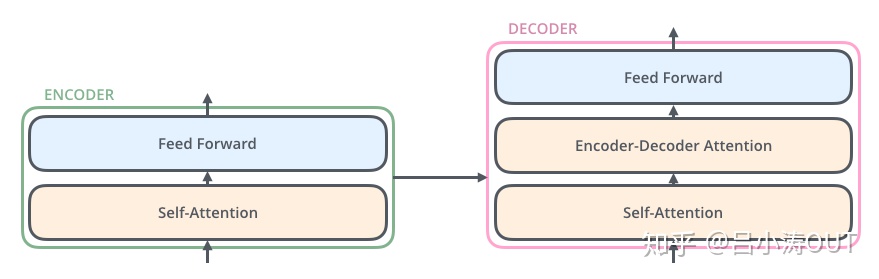

从编码器输入的句子首先会经过一个自注意力(self-attention)层,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。我们将在稍后的文章中更深入地研究自注意力。
自注意力层的输出会传递到前馈(feed-forward)神经网络中。每个位置的单词对应的前馈神经网络都完全一样(译注:另一种解读就是一层窗口为一个单词的一维卷积神经网络)。
解码器中也有编码器的自注意力(self-attention)层和前馈(feed-forward)层。除此之外,这两个层之间还有一个注意力层,用来关注输入句子的相关部分(和seq2seq模型的注意力作用相似)。
将张量引入图景
我们已经了解了模型的主要部分,接下来我们看一下各种向量或张量(译注:张量概念是矢量概念的推广,可以简单理解矢量是一阶张量、矩阵是二阶张量。)是怎样在模型的不同部分中,将输入转化为输出的。
像大部分NLP应用一样,我们首先将每个输入单词通过词嵌入算法转换为词向量。
每个单词都被嵌入为512维的向量,我们用这些简单的方框来表示这些向量。

词嵌入过程只发生在最底层的编码器中。所有的编码器都有一个相同的特点,即它们接收一个向量列表,列表中的每个向量大小为512维。在底层(最开始)编码器中它就是词向量,但是在其他编码器中,它就是下一层编码器的输出(也是一个向量列表)。向量列表大小是我们可以设置的超参数——一般是我们训练集中最长句子的长度。
将输入序列进行词嵌入之后,每个单词都会流经编码器中的两个子层。

接下来我们看看Transformer的一个核心特性,在这里输入序列中每个位置的单词都有自己独特的路径流入编码器。在自注意力层中,这些路径之间存在依赖关系。而前馈(feed-forward)层没有这些依赖关系。因此在前馈(feed-forward)层时可以并行执行各种路径。
然后我们将以一个更短的句子为例,看看编码器的每个子层中发生了什么。
现在我们开始“编码”
如上述已经提到的,一个编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一个编码器中。
输入序列的每个单词都经过自编码过程。然后,他们各自通过前向传播神经网络——完全相同的网络,而每个向量都分别通过它。

从宏观视角看自注意力机制
不要被我用自注意力这个词弄迷糊了,好像每个人都应该熟悉这个概念。其实我之也没有见过这个概念,直到读到Attention is All You Need这篇论文时才恍然大悟。让我们精炼一下它的工作原理。
例如,下列句子是我们想要翻译的输入句子:
The animal didn’t cross the street because it was too tired
这个“it”在这个句子是指什么呢?它指的是street还是这个animal呢?这对于人类来说是一个简单的问题,但是对于算法则不是。
当模型处理这个单词“it”的时候,自注意力机制会允许“it”与“animal”建立联系。
随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。
如果你熟悉RNN(循环神经网络),回忆一下它是如何维持隐藏层的。RNN会将它已经处理过的前面的所有单词/向量的表示与它正在处理的当前单词/向量结合起来。而自注意力机制会将所有相关单词的理解融入到我们正在处理的单词中。

请务必检查Tensor2Tensor notebook,在里面你可以下载一个Transformer模型,并用交互式可视化的方式来检验。
从微观视角看自注意力机制
首先我们了解一下如何使用向量来计算自注意力,然后来看它实怎样用矩阵来实现。
计算自注意力的第一步就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
可以发现这些新向量在维度上比词嵌入向量更低。他们的维度是64,而词嵌入和编码器的输入/输出向量的维度是512.但实际上不强求维度更小,这只是一种基于架构上的选择,它可以使多头注意力(multiheaded attention)的大部分计算保持不变。
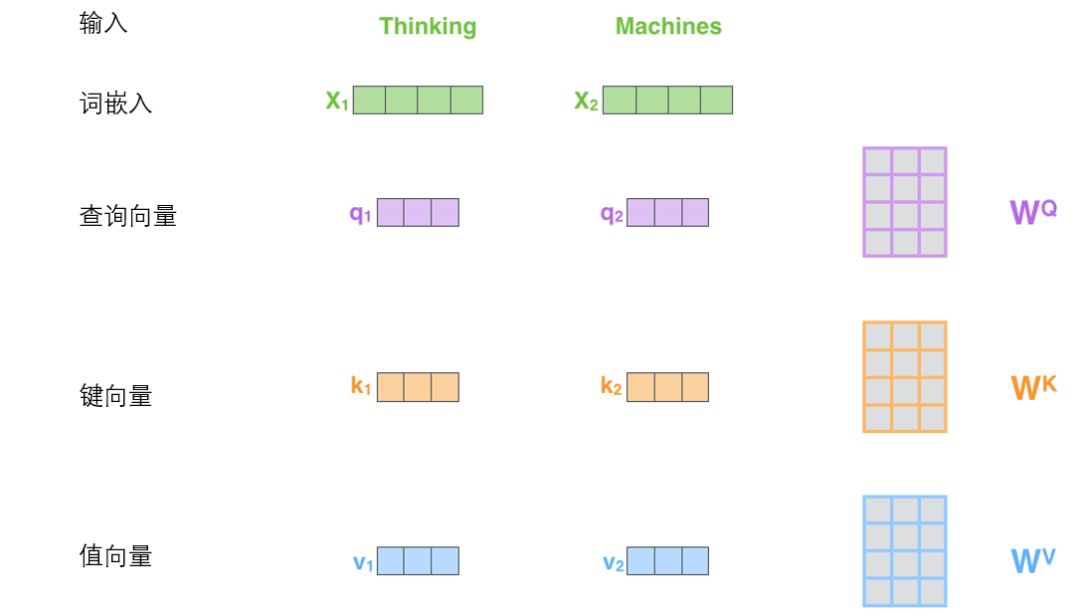
X1与WQ权重矩阵相乘得到q1,就是与这个单词相关的查询向量。最终使得输入序列的每个单词创建一个查询向量、一个键向量和一个值向量。
什么是查询向量、键向量和值向量向量?
它们都是有助于计算和理解注意力机制的抽象概念。请继续阅读下文的内容,你就会知道每个向量在计算注意力机制中到底扮演什么样的角色。
计算自注意力的第二步是计算得分。假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。
这些分数是通过打分单词(所有输入句子的单词)的键向量与“Thinking”的查询向量相点积来计算的。所以如果我们是处理位置最靠前的词的自注意力的话,第一个分数是q1和k1的点积,第二个分数是q1和k2的点积。

第三步和第四步是将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。
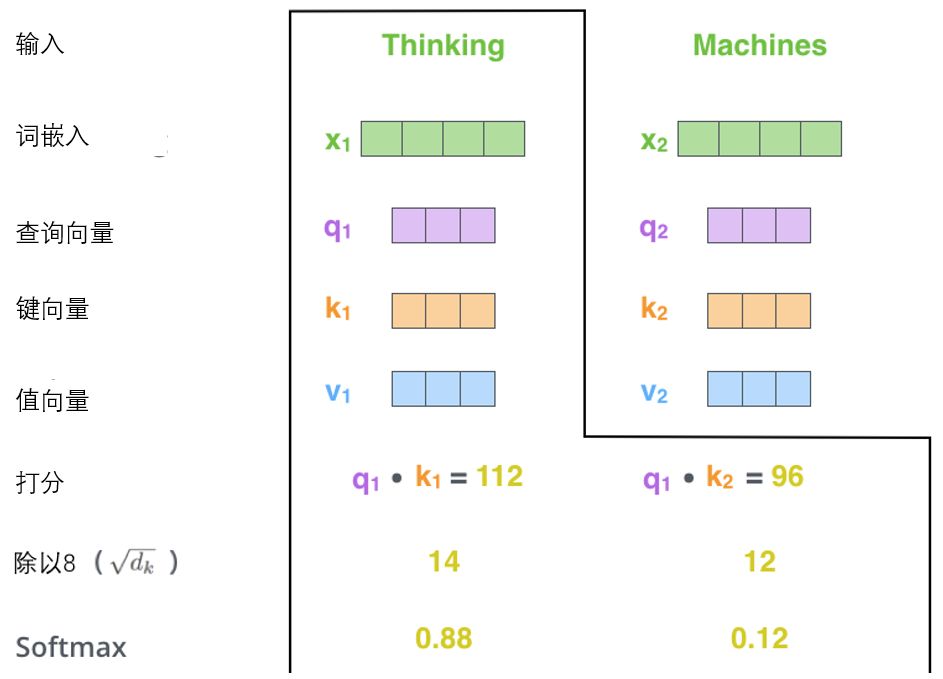
这个softmax分数决定了每个单词对编码当下位置(“Thinking”)的贡献。显然,已经在这个位置上的单词将获得最高的softmax分数,但有时关注另一个与当前单词相关的单词也会有帮助。
第五步是将每个值向量乘以softmax分数(softmax分数看做对应值向量的权重)。这样,相关性高的单词占比大,弱化不相关的单词。
第六步是对加权值向量求和(译注:自注意力的另一种解释就是在编码某个单词时,就是将所有单词的表示(值向量)进行加权求和,而权重是通过该词的表示(键向量)与被编码词表示(查询向量)的点积并通过softmax得到。),然后即得到自注意力层在该位置的输出(在我们的例子中是对于第一个单词)。

这样自自注意力的计算就完成了。得到的向量就可以传给前馈神经网络。然而实际中,这些计算是以矩阵形式完成的,以便算得更快。那我们接下来就看看如何用矩阵实现的。
通过矩阵运算实现自注意力机制
第一步是计算查询矩阵、键矩阵和值矩阵。为此,我们将将输入句子的词嵌入装进矩阵X中,将其乘以我们训练的权重矩阵(WQ,WK,WV)。

x矩阵中的每一行对应于输入句子中的一个单词。我们再次看到词嵌入向量(512,或图中的4个格子)和q/k/v向量(64,或图中的3个格子)的大小差异。
最后,由于我们处理的是矩阵,我们可以将步骤2到步骤6合并为一个公式来计算自注意力层的输出。
自注意力的矩阵运算形式:

“大战多头怪”
通过增加一种叫做“多头”注意力(“multi-headed” attention)的机制,论文进一步完善了自注意力层,并在两方面提高了注意力层的性能:
1.它扩展了模型专注于不同位置的能力。在上面的例子中,虽然每个编码都在z1中有或多或少的体现,但是它可能被实际的单词本身所支配。如果我们翻译一个句子,比如“The animal didn’t cross the street because it was too tired”,我们会想知道“it”指的是哪个词,这时模型的“多头”注意机制会起到作用。
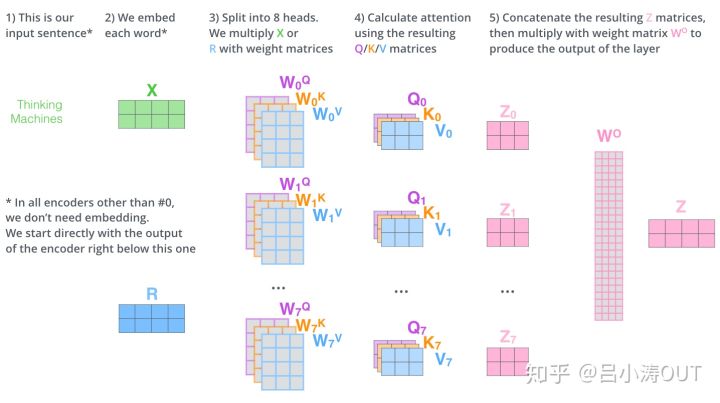
2.它给出了注意力层的多个“表示子空间”(representation subspaces)。接下来我们将看到,对于“多头”注意机制,我们有多个查询/键/值权重矩阵集(Transformer使用八个注意力头,因此我们对于每个编码器/解码器有八个矩阵集合)。这些集合中的每一个都是随机初始化的,在训练之后,每个集合都被用来将输入词嵌入(或来自较低编码器/解码器的向量)投影到不同的表示子空间中。

在“多头”注意机制下,我们为每个头保持独立的查询/键/值权重矩阵,从而产生不同的查询/键/值矩阵。和之前一样,我们拿X乘以WQ/WK/WV矩阵来产生查询/键/值矩阵。
如果我们做与上述相同的自注意力计算,只需八次不同的权重矩阵运算,我们就会得到八个不同的Z矩阵。

这给我们带来了一点挑战。前馈层不需要8个矩阵,它只需要一个矩阵(由每一个单词的表示向量组成)。所以我们需要一种方法把这八个矩阵压缩成一个矩阵。那该怎么做?其实可以直接把这些矩阵拼接在一起,然后用一个附加的权重矩阵WO与它们相乘。
这里使用图像的方式讲解一下self-attention的矩阵的操作。k,v,q![]() 构成了基本单元。这里说明一下,x的向量是由词向量与位置向量共同构成的。
构成了基本单元。这里说明一下,x的向量是由词向量与位置向量共同构成的。
接下来是transformer的主体结构。
Encoder
- Embedding-Layer:词向量 & 位置向量
- SubLayer_1: Multi-Head Attention:编码的self-attention
- SubLayer_2: FeedForward Networks:简单的神经网络
Decoder
- Embedding-Layer:词向量 & 位置信息
- SubLayer_1: Masked Multi-Head Attention:编码的masked self-attention。(only permit current state's paying attention to the previous state, not future state)
- SubLayer_2: Multi-Head Attention:
Q:之前的解码的向量
K, V: 编码的输出 - SubLayer_2: FeedForward Networks:简单的神经网络
- Linear & Softmax: Softmax到分类