背景
在项目中,自定义数据采集以及为下游sink提供结构化的数据的需求,目前主要采用dataframe和JSON互相转换从而便于数据的分析。
1、JSON字符串转dataframe
首先需要了解json对应于dataframe的数据类型:
| json | dataframe |
| int | long |
| array | array |
| object | struct |
测试json:
val testrdd = spark.sparkContext.parallelize(Array("{\"name\":\"张三\",\"age\":18,\"grade\":{\"gname\":\"chinese\",\"score\":\"88\"},\"array\":[11,12,13]}"))转换后的数据类型:

完整代码:
//创建sparksession
val spark = SparkSession.builder().master("local[*]").appName(RegexTest.getClass.getName).getOrCreate()
val sc = spark.sparkContext
val testrdd = spark.sparkContext.parallelize(Array("{\"name\":\"张三\",\"age\":18,\"grade\":{\"gname\":\"chinese\",\"score\":\"88\"},\"array\":[11,12,13]}"))
import spark.implicits._
//将rdd转换为dataset
val testds = spark.createDataset(testrdd)
//将dataset转换为dataframe
val df = spark.read.json(testds)
//输出dataframe的字段结构
df.printSchema()
//输出数据
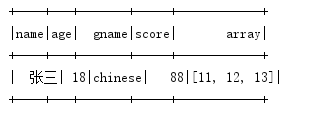
df.select("name","age","grade.gname","grade.score","array").show()
spark.stop()结果:
2、dataframe转JSONrdd
转rdd比较简单代码如下:
val spark = SparkSession.builder().master("local[*]").appName(RegexTest.getClass.getName).getOrCreate()
val sc = spark.sparkContext
val testrdd = spark.sparkContext.parallelize(Array("{\"name\":\"张三\",\"age\":18,\"grade\":{\"gname\":\"chinese\",\"score\":\"88\"},\"array\":[11,12,13]}"))
import spark.implicits._
val testds = spark.createDataset(testrdd)
val df = spark.read.json(testds)
df.printSchema()
df.toJSON.foreach(println(_))结果如下:
![]()
版权声明:本文为qq_24674131原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。