什么是渲染管线
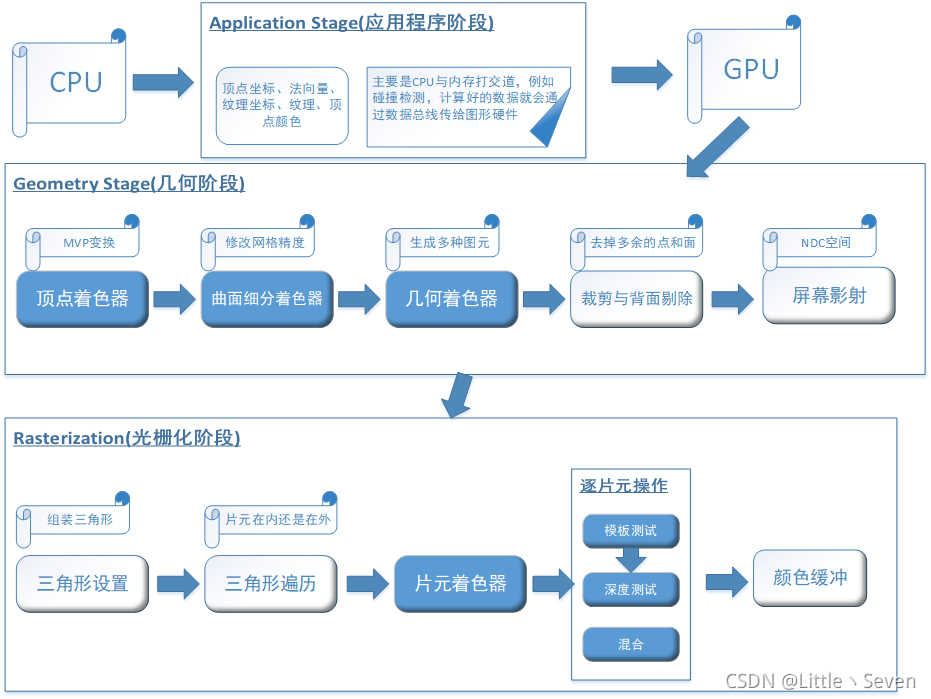
它是由CPU发起,把准备好的渲染数据传入GPU后,在GPU中进行的一整套处理顶点数据和纹理程序,渲染管线含多个步骤,其最终结果是逐像素输出颜色并形成一张图像信息。如何理解逐像素呢,想象一张图片是1080*1920像素,那么把这张图横着切1080份,竖着切1920份,那每个格子就是1个像素。
渲染管线分三个阶段
- 应用程序阶段
- 几何阶段
- 光栅化阶段
1应用程序阶段
以前看其他的渲染管线教程,都会简单的描述一下该过程,例如CPU准备场景数据,传给GPU显存,这段描述过于简陋,里面需要学习的知识点也不少。
应用程序阶段一般分为三部分,1是准备渲染相关数据,2是设置渲染状态,3是DrawCall
1-1准备渲染相关数据
罗列一下渲染需要的所有东西,相机参数(位置、投影参数)、模型顶点、纹理、shader、光源信息,准备渲染物体时还会进行一个粗粒度剔除,也就是说在视锥体外的东西压根就不在准备之列。
应用程序首先要调用OpenGL、Direct3D等图形接口将渲染所需数据如顶点数据、纹理数据等加载到显卡的显存VRAM
1-2设置渲染状态(SetPass)
设置渲染状态干了啥呢,简单来说就是当前渲染材质球切换时,会设置渲染状态,下文我将通过两个小实验来说明,
实验1:8个cube,其中上面4个除了位置不同其他完全相同,下面四个也是除了位置不同其他相同,按理来说SetPassCall应该是3,相机背景占1,黑白组占1,白色组占1,但观察gif图里的setpasscall值发现,当移动白色cube组时,SetPass Call数值莫名其妙的多加了1,目标值应该是3,移动后变为了4。
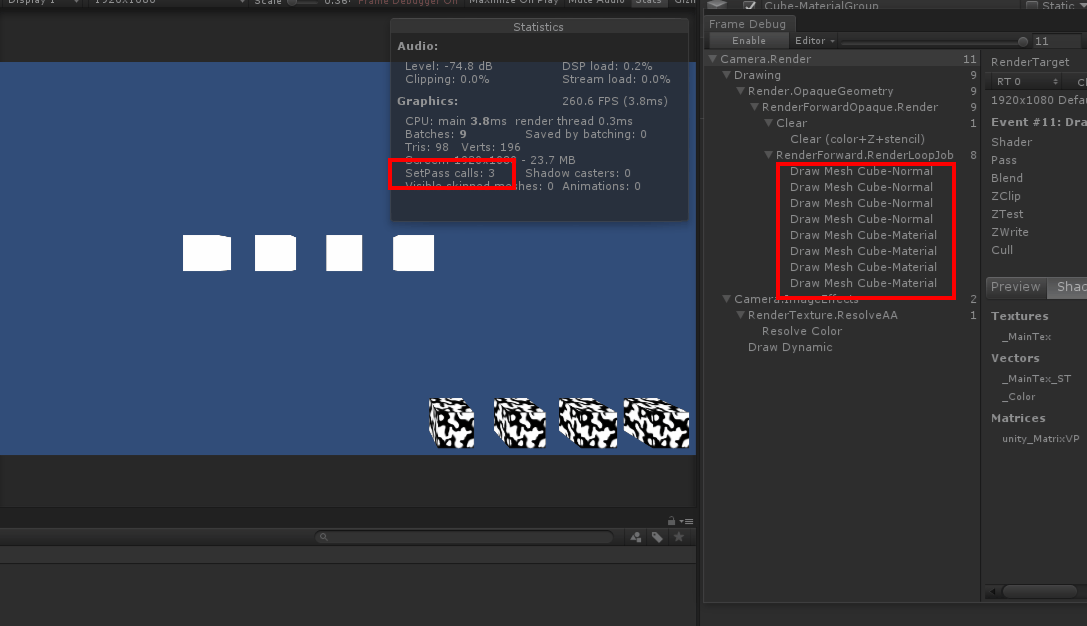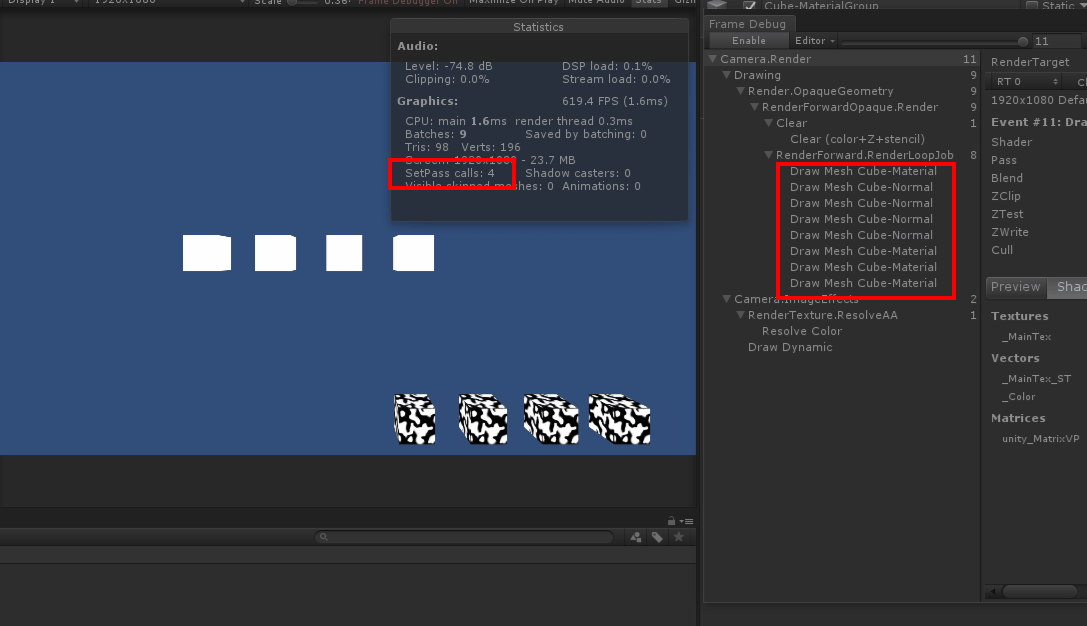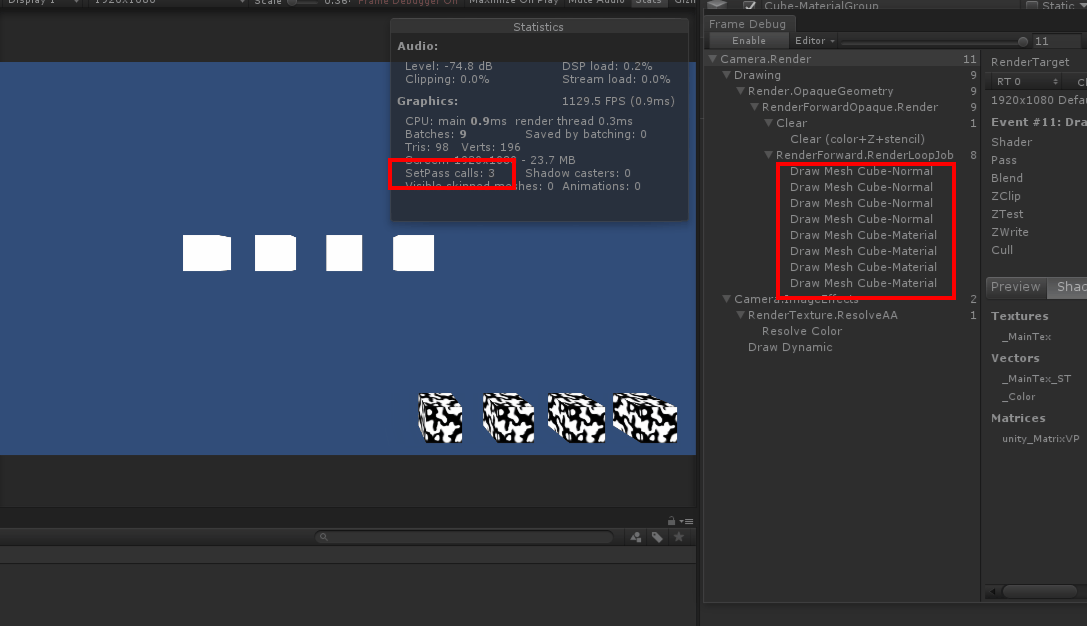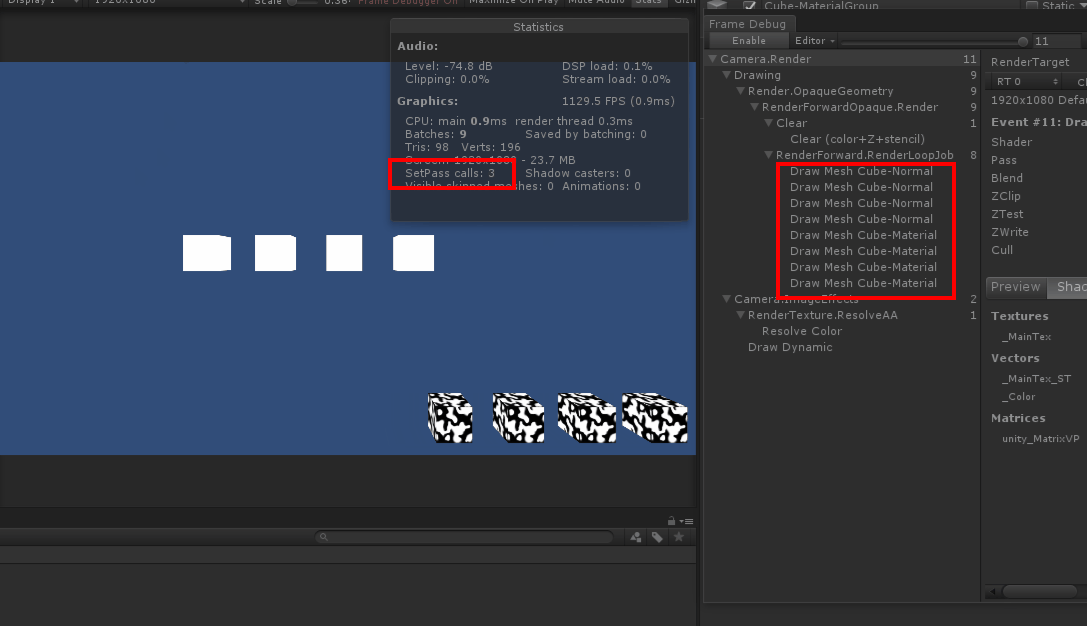 看右边的FrameDebugger,当我移动黑白组时,渲染顺序发生了穿插,也就是说本来的渲染顺序是11112222,一但渲染顺序变成21111222时,由于渲染的material多切换了一次,所以SetPassCall也加了一次。回到正题,通过这个例子可以很直观的理解,当切换渲染material时(第一次渲染也是切换渲染)会发生一次SetPassCall,如果两组物体用12121212的渲染方式很显然会更加的浪费性能,这样会发生8次SetPassCall
看右边的FrameDebugger,当我移动黑白组时,渲染顺序发生了穿插,也就是说本来的渲染顺序是11112222,一但渲染顺序变成21111222时,由于渲染的material多切换了一次,所以SetPassCall也加了一次。回到正题,通过这个例子可以很直观的理解,当切换渲染material时(第一次渲染也是切换渲染)会发生一次SetPassCall,如果两组物体用12121212的渲染方式很显然会更加的浪费性能,这样会发生8次SetPassCall
实验2
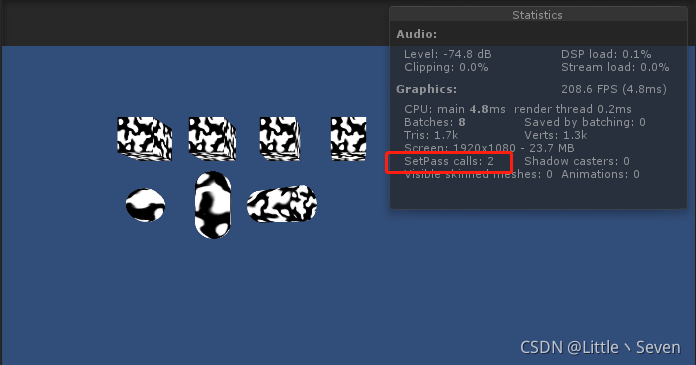
场景中有4种网格的物体,分别是4个相同的Cube,1个Sphere,1个Cylinder,1个Capsule,7个物体都使用了同一个材质球。当前SetPassCall总数量是2,其中摄像机SetPassCall发生1次,其他的7个物体发生了1次,也就是说,按顺序渲染物体时,只要Material没发生变化,那么SetPassCall就不会发生。
总结一下:
当渲染切换渲染材质球时,会发生SetPassCall,不同网格的物体引用材质相同则不会发生SetPass。
1-3DrawCall
什么是DrawCall?
这个词直白点的中文翻译就是绘制呼叫,CPU呼叫GPU开始干活啦。实际上发生的事情是:CPU调用图像编程接口命令,如OpenGL 中的glDrawElements 命令或者DirectX 中的DrawlndexedPrimitive命令,通过硬件总线把渲染数据传输到GPU后命令GPU 进行渲染的操作。
DrawCall是项目优化的重点之一,DC过高很可能引起帧率卡顿。先简单介绍一下CPU和GPU的硬件区别
| 主要功能 | 运算空间 | 内存空间 | 微分积分计算速度 | 简单公式计算速度 | |
| CPU | 复杂计算 | 小 | 大 | 较快 | 较慢 |
| GPU | 简单数学计算 | 大 | 小 | 较慢 | 极快 |
由于渲染相关的数学计算较为简单,且GPU使用的是人海战术,数据处理通道和处理单元极多,运算效率异常之快。当出现渲染物体非常多的时候,在GPU开始忙碌之前,CPU也要有很多工作,而且当发生SetPass时CPU也没闲着,因此就会出现一个很糟糕的情况,CPU处理慢,GPU处理快,这个时候会出现掉帧的情况,也就是说输出到屏幕的画面变少了,这个锅GPU不背,是因为CPU忙不过来。
为了解决上述问题,出现了批处理操作,相信Unity开发者对这个名词并不陌生。
批处理优化技术
在Unity中批处理分为两种,动态合批(Dynamic Batching)与静态合批(Static Batching)
什么是批处理:将渲染数据合并后发给GPU渲染,减少DrawCall次数,从而解决上述卡帧问题。
Unity批处理开关位置:Project Settings -> Player -> Other Settings 下的 Static Batching 和 Dynamic Batching
静态合批具体干了啥:静态合批就是把标记为静态物体的mesh合并到一起,常驻一份内存保存这个大的mesh,典型的以空间换时间,合并后渲染多个静态物体只会发生一次drawcall,优势是静态合批只会合批一次,所以该方案值得采用。
动态合批具体干了啥:前面讲了静态合批,动态合批区别不大,就是把满足合批条件的物体合并mesh形成大网格,一次渲染多个物体,但是!动态合批是每帧都要合并一次,如果合批物体很多CPU开销很大,得不偿失。官方也注意到了这一点所以开发了新的SRP Batcher系统,SRP Batcher的思想在于放弃对模型的合并,转而利用现代API“提交渲染请求不昂贵,提交渲染所需数据和改变渲染状态更昂贵”这样的特性,提供了SRP Batcher:
分享一个官方SRP Batcher的译文博客
[译]SRP Batcher:提升您的渲染性能_专栏-CSDN博客
总结:
批处理是一种以空间换时间的优化手段,如果使用不当则不如不用,很有可能造成负优化,动态合批的限制条件颇多。
动态合批条件
合批条件 1顶点要求:
- Meshes小于900顶点的物体进行Dynamic Batching
- Shader里使用了顶点位置,法线,UV值,则仅支持300顶点以内
- 如果使用顶点位置,法线,UV0,UV1和Tangent向量,则仅支持180顶点以内
合批条件2:如果两个物体的scale刚好是呈镜像的,如scale分别为(-1,-1,-1)或(1,1,1),他们不会被Dynamic Batching。
合批条件3:引用材质实例不同的物体不会被Dynamic Batching,即使两个物体的材质本质上没有任何不同。这句话的理解有点绕,简单举例就是说,相同的材质实例化了两份,分别被A和B引用了,那么A和B是不会被Dynamic Batching的,因为他们引用的是两个不同的实例。
合批条件4:拥用lightmaps的物体将不会被Dynamic Batching,除非他们指向了lightmap的同一部分。
合批条件5:拥有多Pass通道的Shader的物体不会被Dynamic batching。
合批条件6:合批之后的单个mesh的顶点数不能超过64K
注意:
1.不同材质的阴影会动态合批,只要绘制阴影的 pass是相同的,因为阴影跟其他贴图等数据无关
2.目前,只有 Mesh Renderers, Trail Renderers, Line Renderers, Particle Systems和Sprite Renderers支持合批处理,而skinned Meshes,Cloth和其他类型的渲染组件不支持合批处理。
3.渲染器仅与其他相同类型的渲染器进行合批处理。
4.对于半透明的GameObject,按照从前到后的顺序绘制,Unity首先按这个顺序对GameObjects进行排序,然后尝试对它们进行批处理,但由于必须严格满足顺序,这通常意味着对于半透明的材质更少使用合批处理。
5.手动的合并GameObject是代替合批处理的好办法,比如使用Mesh.CombineMeshes,或者直接在建模时将多个网格合并成单个网格。