为了进一步巩固R语言的基本用法及实践场景,这里尝试利用R做一些在关联规则上的挖掘实践,这里首要感谢博主gjwang1983的文章,这里仅记录下学习的一些基本应用命令:
1.工具包的选取
规则挖掘包arules
规则可视化包arulesViz2.数据源选取加载
源数据:groceries 数据集,每一行代表一笔交易所购买的产品(item),形如:citrus fruit,semi-finished bread,margarine,ready soups tropical fruit,yogurt,coffee whole milk pip fruit,yogurt,cream cheese,meat spreads other vegetables,whole milk,condensed milk,long life bakery product whole milk,butter,yogurt,rice,abrasive cleaner rolls/buns other vegetables,UHT-milk,rolls/buns,bottled beer,liquor (appetizer) potted plants whole milk,cereals tropical fruit,other vegetables,white bread,bottled water,chocolate ......数据转换:创建稀疏矩阵,每个Item一列,每一行代表一个transaction。1表示该transaction购买了该item,0表示没有购买。当然,data frame是比较直观的一种数据结构,但是一旦item比较多的时候,这个data frame的大多数单元格的值为0,大量浪费内存。所以,R引入了特殊设计的稀疏矩阵,仅存1,节省内存。arules包的函数read.transactions可以读入源数据并创建稀疏矩阵。
groceries <- read.transactions(“groceries.csv”, format=”basket”, sep=”,”)
3.数据查看与筛选
R语言中自带一些函数如summary,size,dim,colnames等可以大概查看交易数据集groceries的基本概况,若想进一步查看统计分析Item的占比,可以使用itemFrequency函数,若要计算support的次数,则需要利用公式转化:basketSize<-size(groceries)
itemCount <- (itemFreq/sum(itemFreq))*sum(basketSize)
orderedItem <- sort(itemCount, decreasing = T)
orderedItem[1:10]若想查看每条购物记录中item大于指定次数的记录,可采用如下方式过滤筛选:
groceries_use <- groceries[basketSize > 2]
这里可以采用直观的图像展示界面显示item的support值,函数如下,topN表示取占比前10的item,horiz表示图表条形是否水平展示,support表示展示大于0.1的item:
itemFrequencyPlot(groceries, topN=10, horiz=T,support=0.1)
有时候为了查看具体的数据细节问题,可以采用arules自带的inspect函数,或者image函数:
inspect(groceries[1:5])
image(sample(groceries,100))4.关联规则挖掘
直接上硬货,利用apriori算法挖掘关联规则:groceryrules <- apriori(groceries, parameter = list(support = 0.006, confidence = 0.25, minlen = 2))
注:对于minlen,maxlen这里指规则的LHS+RHS的并集的元素个数利用inspect查看规则记录时如下所示:
>inspect(groceryrules[1:10]) lhs rhs support confidence lift 1 {potted plants} => {whole milk} 0.006914082 0.4000000 1.565460 2 {pasta} => {whole milk} 0.006100661 0.4054054 1.586614 3 {herbs} => {root vegetables} 0.007015760 0.4312500 3.956477 4 {herbs} => {other vegetables} 0.007727504 0.4750000 2.454874 5 {herbs} => {whole milk} 0.007727504 0.4750000 1.858983 6 {processed cheese} => {whole milk} 0.007015760 0.4233129 1.656698 7 {semi-finished bread} => {whole milk} 0.007117438 0.4022989 1.574457 8 {beverages} => {whole milk} 0.006812405 0.2617188 1.024275 9 {detergent} => {other vegetables} 0.006405694 0.3333333 1.722719 10 {detergent} => {whole milk} 0.008947636 0.4656085 1.8222285.规则评估
规则排序ordered_groceryrules <- sort(groceryrules, by=”lift”)
搜索规则
yogurtrules <- subset(groceryrules, items %in% c(“yogurt”))
注:%in%是精确匹配;
%pin%是部分匹配,也就是说只要item like ‘%A%’ or item like ‘%B%’;
%ain%是完全匹配,也就是说itemset has ‘B’ and itemset has ‘B’;
如果仅仅想搜索lhs或者rhs,那么用lhs或rhs替换items即可。规则校验(类似测试集)
qualityMeasures<-interestMeasure(groceryrules,c(“coverage”,”fishersExactTest”,”conviction”, “chiSquared”), transactions=groceries)
规则保存
直接写入外部文件:write(groceryrules, file=”groceryrules.csv”, sep=”,”, quote=TRUE, row.names=FALSE)
转化data.frame分析:
groceryrules_df <- as(groceryrules, “data.frame”)
str(groceryrules_df)规则可视化展示
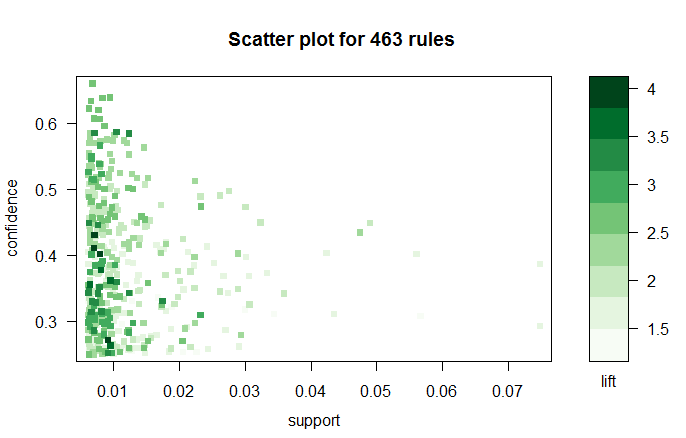
这里使用arulesViz自带的plot函数绘制scatter,groupd或graph等图形,形象表示规则间的联系:plot(groceryrules, method=”scatterplot”,control=list(jitter=2, col = rev(brewer.pal(9, “Greens”))), shading = “lift”)
如下图所示:
其余的图形展示可以利用?plot查看具体参数,通过修改method参数来改变可视化的展现方式,可取值有 “scatterplot”, “two-key plot”, “matrix”, “matrix3D”, “mosaic”, “doubledecker”, “graph”, “paracoord” or “grouped”, “iplots” 。
plot(groceryrules, control=list(jitter=2, col = rev(brewer.pal(9, “Greens”))), shading = “lift”,method = ‘grouped’)
注,该矩阵展示图采用聚类的方式将rhs进行聚集,然后以矩阵方式加以表现,rhs的items可使用RHS<-unique(arules::rhs(groceryrules))查看