2、将Mysql数据导入到HDFS
再Hdfs上创建目录
hadoop fs -mkdir -p /data/base #用于存放数据
我们cd到sqoop目录下执行命令
\ 用于换行
bin/sqoop import
–connect jdbc:mysql://172.18.96.151:3306/zhilian \ #连接数据库
–username root \ #用户名
–password 123456 \ #密码
–query ‘select id, jobname, salarylevel from zhaopin where $CONDITIONS LIMIT 100’ \ #选取表的字段信息
–target-dir /data/base \ #上传到Hdfs的目录
–delete-target-dir \ #如果指定文件目录存在则先删除掉
–num-mappers 1 \ #使用1个map并行任务
–compress \ #启动压缩
–compression-codec org.apache.hadoop.io.compress.SnappyCodec \ #指定hadoop的codec方式 默认为gzip
–direct \ #使用直接导入方式,优化导入速度
–fields-terminated-by ‘\t’ #字段之间通过空格分隔
3、使用Sqoop导入mysql数据到Hive中 首先在Hive中创建一张表以\t为分隔符。
create table default.hive_zhaopin_jingji(
id int,
jobname string,
salarylevel string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’ ;
然后cd到sqoop目录下,执行命令
bin/sqoop import
–connect jdbc:mysql://172.18.96.151:3306/zhilian \ #连接mysql必备
–username root
–password 123456
–table zhaopin \ #要连接的表
–fields-terminated-by ‘\t’ \ #字段通过空格分隔
–delete-target-dir \ #如果目录存在就删除
–num-mappers 1 \ #启动一个Map并行任务
–hive-import \ #执行导入Hive
–hive-database default \ #导入到默认的default库
–hive-table hive_zhaopin_jingji #导入到hive_zhaopin_jingji表中
5、使用Sqoop导入Oracle数据到HDFS中
./sqoop import --connect jdbc:oracle:thin:@192.168.1.22:1521:orcl --username zhaoxiaoqi --password 123456 --table emp --columns ‘empno,ename,job,sal,deptno’ -m 1 --target-dir ‘HDFS目录路径’
6、使用Sqoop导入Oracle数据到Hive中
./sqoop import --hive-import --connect jdbc:oracle:thin:192.168.1.22:1521:orcl --username zhaoxiaoqi --password 123456 --table emp -m 1 --columns ‘EMPON,ENAME,JOB,SAL,DEPTNO’
参数解释:
-hive-import: 执行导入为Hive
–connect jdbc:oracle:链接数据库为oracle
192.168.1.22:IP地址
1521:端口号
orcl:数据库
–username:用户名
–password: 密码
–table:表名
-m:导入时使用的进程数
–columns :指定导入的列
–target-dir :指定导入命令
7、使用Sqoop导入Oracle数据到Hive中,并且指定表名
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.22:1251:orcl --username zhaoxiaoqi --password 123456 --table emp -m 1 --columns ‘EMPNO,ENAME,JOB,SAL,DEPTNO’ --hive-table emp1
参数解释:
–hive-table:指定表名
8、使用Sqoop导入Oracle数据到Hive中,并且使用where条件
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.22:1251:orcl --username zhaoxiaoqi --password 123456 --table emp -m 1 --columns ‘EMPNO,ENAME,JOB,SAL,DEPTNO’ --hive-table emp1 --where ‘DEPTNO=10’
参数解释:
–where:指定条件
9、使用Sqoop导入Oracle数据到Hive中,并且使用查询语句
./sqoop import --hive-import --connect jdbc:oracle:thin:@192.168.1.22:1251:orcl --username zhaoxiaoqi --password 123456 --table emp -m 1 --query ‘select * from emp where SAL < 2000 and $CONDITIONS’ --target-dir ‘使用查询语句必须指定hive文件存放路径’ --hive-table emp1
参数解释:
–query:查询语句
10、使用Sqoop将Hive中的数据导入到Oracle中
./sqoop export --commect jdbc:oracle:thin:@192.168.1.22:1521:orcl --username zhaoxiaoqi --password 123456 -m 1 --table 表名 --export-dir ‘HDFS中的文件路径’
11、使用sqoop将mysql的数据导入到HDFS中
准备一张表

需求 将 bbs_product 表中的前100条数据导 导出来 只要id brand_id和 name 这3个字段
数据存在 hdfs 目录 /user/xuyou/sqoop/imp_bbs_product_sannpy_ 下
bin/sqoop import
–connect jdbc:mysql://172.16.71.27:3306/babasport
–username root
–password root
–query ‘select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100’
–target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_
–delete-target-dir
–num-mappers 1
–compress
–compression-codec org.apache.hadoop.io.compress.SnappyCodec
–fields-terminated-by ‘\t’

ps: 如果导出的数据库是mysql 则可以添加一个 属性 --direct
1 bin/sqoop import
2 --connect jdbc:mysql://172.16.71.27:3306/babasport
3 --username root
4 --password root
5 --query ‘select id, brand_id,name from bbs_product where $CONDITIONS LIMIT 100’
6 --target-dir /user/xuyou/sqoop/imp_bbs_product_sannpy_
7 --delete-target-dir
8 --num-mappers 1
9 --compress
10 --compression-codec org.apache.hadoop.io.compress.SnappyCodec
11 --direct
12 --fields-terminated-by ‘\t’
加了 direct 属性在导出mysql数据库表中的数据会快一点 执行的是mysq自带的导出功能
第一次执行所需要的时间
第二次执行所需要的时间 (加了direct属性)
追加数据到已存在表中之id
sqoop import --connect jdbc:mysql://192.168.203.7:3306/test --username root --password root --table teacher --target-dir /mydb/teacher -m 1 --check-column id --incremental append --last-value 7
参数解释:
–check-column:追加列名
–incremental append --last-value 7 :参数id大于7的追加
加数据到已存在表中之时间:lastmodified
sqoop import --connect jdbc:mysql://192.168.203.72:3306/test --username root --password 123 --table teacher --target-dir /teacher1 -m 1 --check-column last_modified --incremental lastmodified --last-value ‘2018-10-04 16:37:31’
前提:你表中的数据有datetime类型的字段,安装这个字段追加。
将SQL数据库test中的teacher表中last_modified大于’2018-10-04 16:37:31’的数据加hdfs上的teacher1目录上,
用时间追加的数据保存在不是一个文件中
12、拷贝mysql数据表到hdfs上
1、在mysql中创建对应字段的数据库表,测试用student
2、HDFS中的文本文件以,作分隔符分割字段,文件名student.txt
3、命令如下,参数依次为mysql数据库地址,用户名密码,mysql数据库表名,HDFS文件所在位置,分隔符
sqoop export --connect jdbc:mysql://192.168.203.7:3306/test --username root --password root --table student --export-dir /student.txt --fields-terminated-by ‘,’;
三、通过sqoop查看本地MySQL信息
sqoop list-tables -connect jdbc:mysql://192.168.203.7:3306/test --username root --password root
表示查看test这个数据库中的所有表信息,如下图
sqoop list-databases -connect jdbc:mysql://192.168.203.7:3306/ --username root --password root
表示查看mysql所有数据库,如下图类似
13、SQOOP 导出Hive数据到MySQL
基本知识:
Sqoop导出的基本用法:https://sqoop.apache.org/docs/1.4.6/SqoopUserGuide.html#_syntax_4 的10. sqoop-export
内容摘要:
本文主要是对–update-mode参数的用法进行了验证。结论如下:
–update-mode模式有两种updateonly(默认)和allowinsert
updateonly:该模式用于更新Hive表与目标表中数据的不一致,即在不一致时,将Hive中的数据同步给目标表(如MySQL、Oracle等的目标表中),这种不一致是指,一条记录中的不一致,比如Hive表和MySQL中都有一个id=1的记录,但是其中一个字段的取值不同,则该模式会将这种差异抹除。对于“你有我无”的记录则“置之不理”。
allowinsert:该模式用于将Hive中有但目标表中无的记录同步到目标表中,但同时也会同步不一致的记录。可以这种模式可以包含updateony模式的操作,这也是为什么没有命名为insertonly的原因吧。
测试场景一:全量导出
准备原始数据:
为简化处理,先在MySQL中创建原始数据表wht_test1,并添加测试数据,如下所示:
2. 将原始表中的数据导入到Hive中。
sqoop import --connectjdbc:mysql://localhost:3306/wht --username root --password cloudera --tablewht_test1 --fields-terminated-by ‘,’ --hive-import --hive-table default.wht_test1 --hive-overwrite -m 1
执行完该操作后,导入的数据在HDFS的/user/hive/warehouse/wht_test1目录下。
3. 创建导出表。
在MySQL中创建结构相同的表,用于导出数据:
CREATE TABLEwht_test2 LIKE wht_test1;
从Hive(HDFS)导出数据。
sqoop export --connectjdbc:mysql://localhost:3306/wht --username root --password cloudera --tablewht_test2 --fields-terminated-by ‘,’ --export-dir /user/hive/warehouse/wht_test1
执行完该操作后,MySQL的wht_test2表中插入了Hive中的数据,如下所示:
测试场景二:增量导出,在源数据中增加2条记录,查看不同模式导出结果
编辑HDFS中的数据文件,添加两行新的记录,编辑后的文件内容如下所示:

Ø updateonly模式:
sqoop export --connectjdbc:mysql://localhost:3306/wht --username root --password cloudera --tablewht_test2 --fields-terminated-by ‘,’ --update-key c_id --export-dir /user/hive/warehouse/wht_test1
查看结果,可以看出Updateonly模式不能导出新增数据: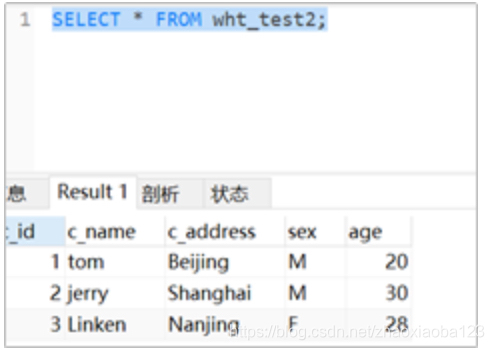
Ø allowinsert模式:
sqoop export --connectjdbc:mysql://localhost:3306/wht --username root --password cloudera --tablewht_test2 --fields-terminated-by ‘,’ --update-key c_id --update-mode allowinsert --export-dir /user/hive/warehouse/wht_test1
查看结果,新增数据被导出:
测试场景三:修改Hive表数据,修改age的值,并新增一行记录,然后重新导出,看目标表中的数据是否会被修改
编辑HDFS中的数据文件,编辑后的文件内容如下所示:
sqoop export --connectjdbc:mysql://localhost:3306/wht --username root --password cloudera --tablewht_test2 --fields-terminated-by ‘,’ --update-key c_id --update-mode updateonly --export-dir/user/hive/warehouse/wht_test1
查看结果,Hive表中修改的数据被更新,但updateonly模式不会导出新插入的记录:
测试场景三:allowinsert模式(导出不同HDFS源文件中的新增数据)
Hive表可能有多个分区,在此新增一个目录,并保存结构相同的数据,使用allowinsert模式查看导出结果。
查看结果,新增数据被导出:
新增数据目录wht_test1_part,该目录下的数据文件如下所示:
执行导出命令:sqoop export --connect jdbc:mysql://localhost:3306/wht --usernameroot --password cloudera --table wht_test2 --fields-terminated-by ‘,’ --update-key c_id --update-mode allowinsert --export-dir/user/hive/warehouse/wht_test1_part
查看导出结果,可以看出新增数据被导出: