flink state原理
- 1. 状态、状态后端、Checkpoint 三者之间的区别及关系?
- 2.把状态后端从 FileSystem 变为 RocksDB 后,Flink 任务状态存储会发生那些变化?
- 3.什么样的业务场景你会选择 filesystem,什么样的业务场景你会选 rocksdb 状态后端?
- 4.Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是onReadAndWrite
- 5.operator-state 和 keyed-state 两者的区别?最大并行度又和它们有什么关系?举个生产环境中经常出现的案例,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
- 6.ValueState 和 MapState 各自适合的应用场景?
- 7.Flink 配置 State TTL 时都有哪些配置项?每种配置项的作用?
- 8.Flink State TTL 是怎么做到数据过期的?首先我们来想想,要做到 TTL 的话,要具备什么条件呢?
1. 状态、状态后端、Checkpoint 三者之间的区别及关系?
拿五个字做比喻:“铁锅炖大鹅”,铁锅是状态后端,大鹅是状态,Checkpoint 是炖的动作。
状态:本质来说就是数据,在 Flink 中,其实就是 Flink 提供给用户的状态编程接口。比如 flink 中的 MapState,ValueState,ListState。
状态后端:Flink 提供的用于管理状态的组件,状态后端决定了以什么样数据结构,什么样的存储方式去存储和管理我们的状态。Flink 目前官方提供了 memory、filesystem,rocksdb 三种状态后端来存储我们的状态。
Checkpoint(状态管理):Flink 提供的用于定时将状态后端中存储的状态同步到远程的存储系统的组件或者能力。为了防止 long run 的 Flink 任务挂了导致状态丢失,产生数据质量问题,Flink 提供了状态管理(Checkpoint,Savepoint)的能力把我们使用的状态给管理起来,定时的保存到远程。然后可以在 Flink 任务 failover 时,从远程把状态数据恢复到 Flink 任务中,保障数据质量。
2.把状态后端从 FileSystem 变为 RocksDB 后,Flink 任务状态存储会发生那些变化?
结论:是否使用 RocksDB 只会影响 Flink 任务中 keyed-state 存储的方式和地方,Flink 任务中的 operator-state 不会受到影响。
首先我们来看看,Flink 中的状态只会分为两类:
- keyed-state:键值状态,如其名字,此类状态是以 k-v 的形式存储,状态值和 key 绑定。Flink 中的 keyby 之后紧跟的算子的 state 就是键值状态;
- operator-state:算子状态,非 keyed-state 的 state 都是算子状态,非 k-v 结构,状态值和算子绑定,不和 key 绑定。Flink 中的 kafka source 算子中用于存储 kafka offset 的 state 就是算子状态。
如下图所示是 3 种状态后端和 2 种 State 的对应存储关系:
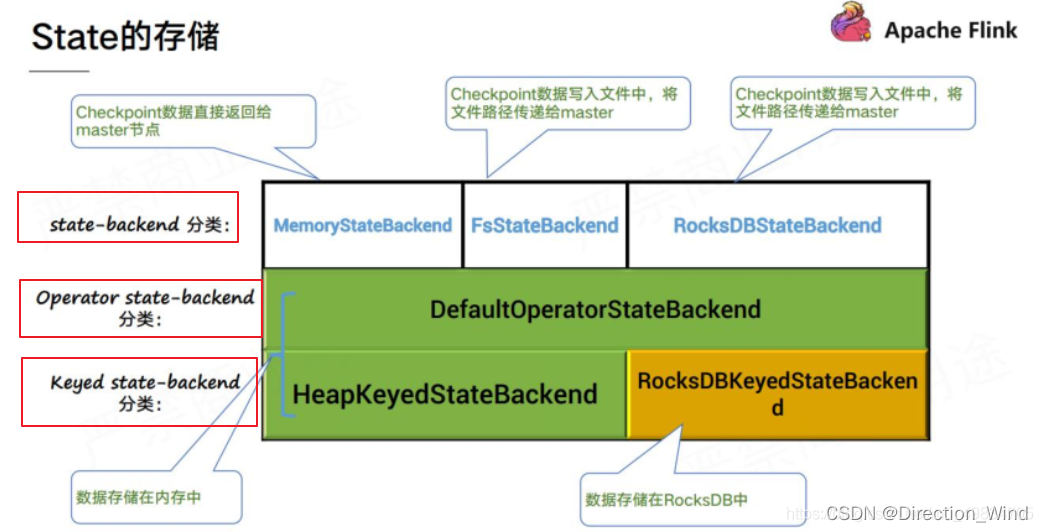
- 横向(行)来看,即 Flink 的状态分类。分为 Operator state-backend、Keyed state-backend;
- 纵向(列)来看,即 Flink 的状态后端分类。用户可以配置 memory,filesystem,rocksdb 3 中状态后端,在 Flink 任务中生成 MemoryStateBackend,FsStateBackend,RocksdbStateBackend,其声明了整个任务的状态管理后端类型;
- 每个格子中的内容就是用户在配置 xx 状态后端(列)时,给用户使用的状态(行)生成的状态后端实例,生成的这个实例就是在 Flink 中实际用于管理用户使用的状态的组件。
因此对应的结论就是:
1.** Flink 任务中的 operator-state**。无论用户配置哪种状态后端(无论是 memory,filesystem,rocksdb),都是使用 DefaultOperatorStateBackend 来管理的,状态数据都存储在内存中,做 Checkpoint 时同步到远程文件存储中(比如 HDFS)。
2. Flink 任务中的 keyed-state。用户在配置 rocksdb 时,会使用 RocksdbKeyedStateBackend 去管理状态;用户在配置 memory,filesystem 时,会使用 HeapKeyedStateBackend 去管理状态。因此就有了这个问题的结论,配置 rocksdb 只会影响 keyed-state 存储的方式和地方,operator-state 不会受到影响。
3.什么样的业务场景你会选择 filesystem,什么样的业务场景你会选 rocksdb 状态后端?
在回答这个问题前,我们先看看每种状态后端的特性:
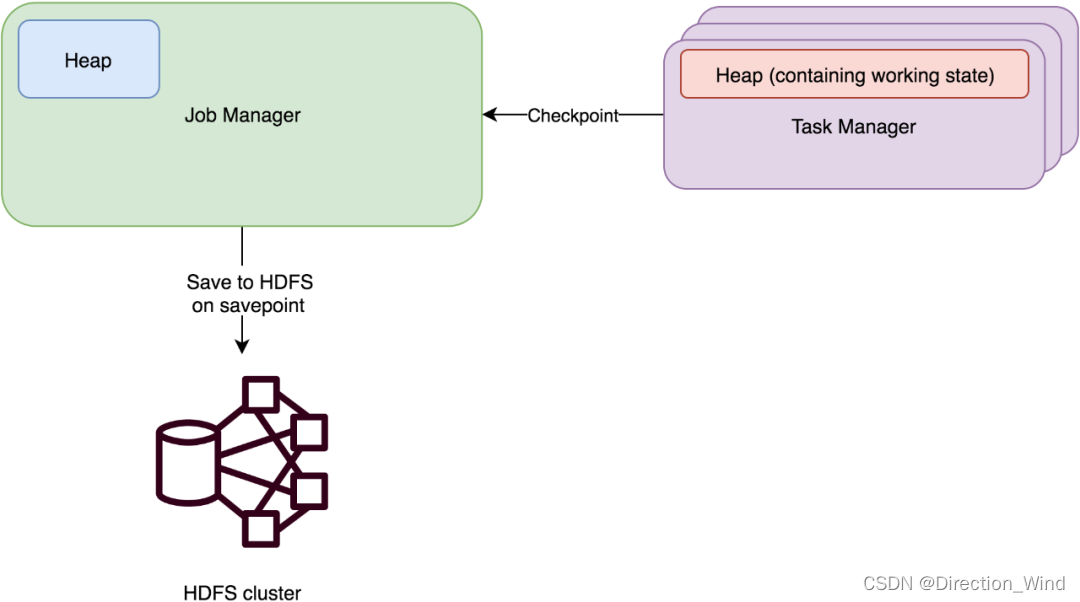
MemoryStateBackend
原理
运行时所需的 State 数据全部保存在 TaskManager JVM 堆上内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到 JobManager 进程 的内存中。执行 Savepoint 时,可以把 State 存储到文件系统中。
1 基于内存的状态管理器,聚合类算子的状态会存储在JobManager的内存中
2 单次状态大小默认最大被限制为5MB,可以通过构造函数来指定状态初始化内存大小。无论单次状态大小最大被限制为多少,都不可大于akka的frame大小(1.5MB,JobManager和TaskManager之间传输数据的最大消息容量)。状态的总大小不能超过 JobManager 的内存。
3 是Flink默认的后端状态管理器,默认是异步的
4 主机内存中的数据可能会丢失,任务可能无法恢复
5 将工作state保存在TaskManager的内存中,并将checkpoint数据存储在JobManager的内存中
适用:本地开发和调试 状态比较少的作业
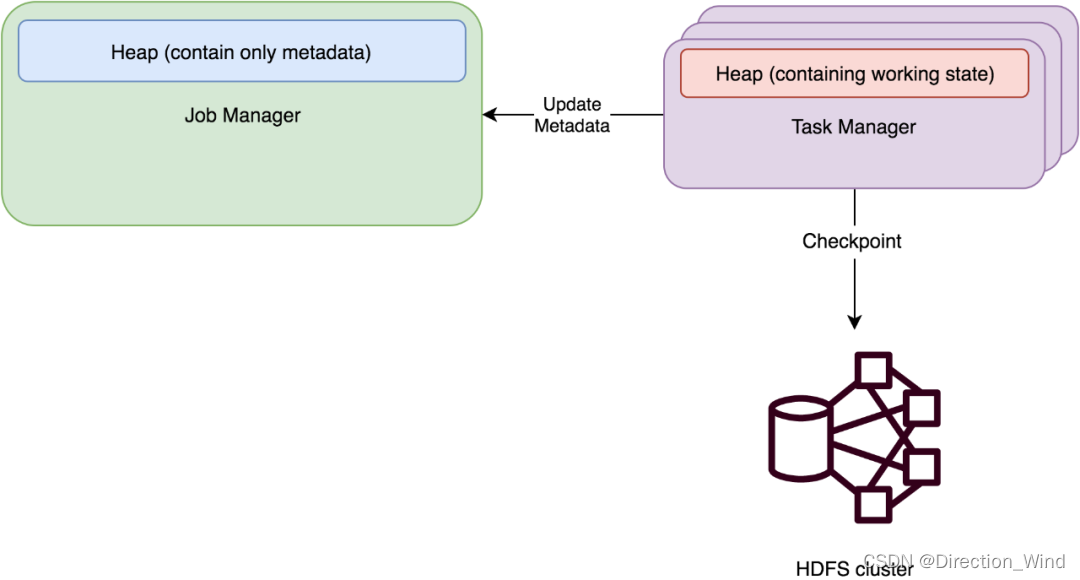
FsStateBackend
原理
运行时所需的 State 数据全部保存在 TaskManager 的内存中,执行 Checkpoint 的时候,会把 State 的快照数据保存到配置的文件系统中。TM 是异步将 State 数据写入外部存储。
- 1 基于文件系统的状态管理器
- 2 如果使用,默认是异步
- 3 比较稳定,3个副本,比较安全。不会出现任务无法恢复等问题
- 4 状态大小受磁盘容量限制
- 5 将工作state保存在TaskManager的内存中,并将checkpoint数据存储在文件系统中
- 适用:状态比较大,窗口比较长,大的KV状态
RocksDBStateBackend
原理
使用嵌入式的本地数据库 RocksDB 将流计算数据状态存储在本地磁盘中。在执行 Checkpoint 的时候,会将整个 RocksDB 中保存的 State 数据全量或者增量持久化到配置的文件系统中。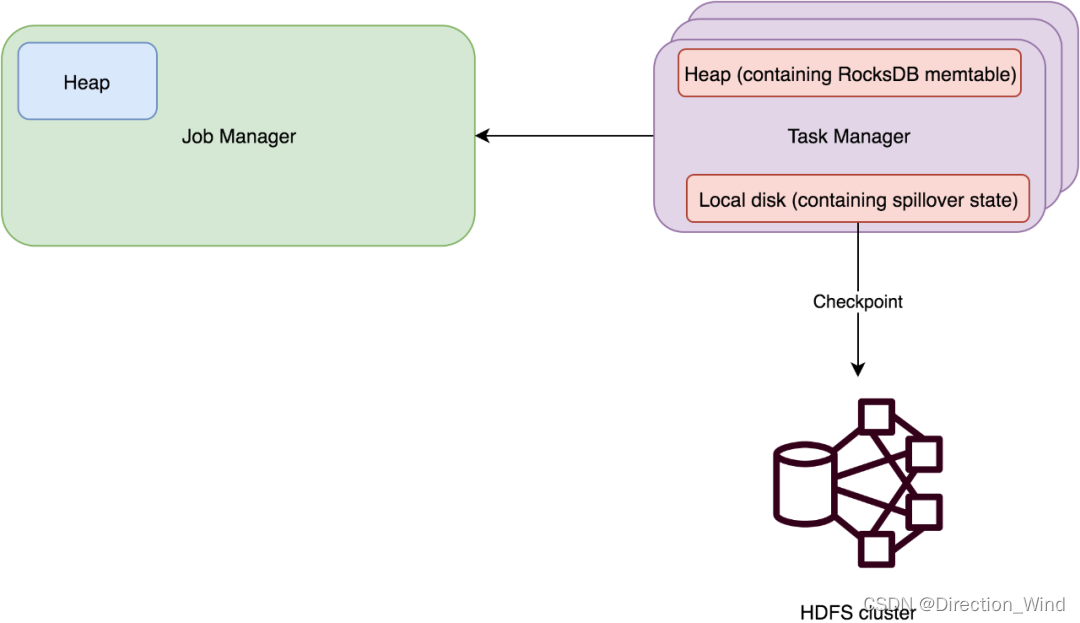
- 1 状态数据先写入RocksDB,然后异步的将状态数据写入文件系统。
- 2 正在进行计算的热数据存储在RocksDB,长时间才更新的数据写入磁盘中(文件系统)存储,体量比较小的元数据状态写入JobManager内存中(将工作state保存在RocksDB中,并且默认将checkpoint数据存在文件系统中)
- 3 支持的单 key 和单 value 的大小最大为每个 2^31 字节(2GB)
- 4 RocksDBStateBackend是目前唯一支持incremental的checkpoints的策略
- 5 默认使用是异步
到生产环境中:
⭐ 如果状态很大,使用 Rocksdb;如果状态不大,使用 Filesystem。
⭐ Rocksdb 使用磁盘存储 State,所以会涉及到访问 State 磁盘序列化、反序列化,性能会收到影响,而 Filesystem 直接访问内存,单纯从访问状态的性能来说 Filesystem 远远好于 Rocksdb。生产环境中实测,相同任务使用 Filesystem 性能为 Rocksdb 的 n 倍,因此需要根据具体场景评估选择。
恢复
从 checkpoint 重启时,首先进入 RocksDBKeyedStateBackendBuilder 的 getRocksDBRestoreOperation 方法
// rockdb restore 入口方法
private AbstractRocksDBRestoreOperation<K> getRocksDBRestoreOperation(
int keyGroupPrefixBytes,
CloseableRegistry cancelStreamRegistry,
LinkedHashMap<String, RocksDBKeyedStateBackend.RocksDbKvStateInfo> kvStateInformation,
RocksDbTtlCompactFiltersManager ttlCompactFiltersManager) {
if (restoreStateHandles.isEmpty()) {
return new RocksDBNoneRestoreOperation<>(
keyGroupRange,
keyGroupPrefixBytes,
numberOfTransferingThreads,
cancelStreamRegistry,
userCodeClassLoader,
kvStateInformation,
keySerializerProvider,
instanceBasePath,
instanceRocksDBPath,
dbOptions,
columnFamilyOptionsFactory,
nativeMetricOptions,
metricGroup,
restoreStateHandles,
ttlCompactFiltersManager);
}
KeyedStateHandle firstStateHandle = restoreStateHandles.iterator().next();
if (firstStateHandle instanceof IncrementalKeyedStateHandle) {
return new RocksDBIncrementalRestoreOperation<>(
operatorIdentifier,
keyGroupRange,
keyGroupPrefixBytes,
numberOfTransferingThreads,
cancelStreamRegistry,
userCodeClassLoader,
kvStateInformation,
keySerializerProvider,
instanceBasePath,
instanceRocksDBPath,
dbOptions,
columnFamilyOptionsFactory,
nativeMetricOptions,
metricGroup,
restoreStateHandles,
ttlCompactFiltersManager);
} else {
return new RocksDBFullRestoreOperation<>(
keyGroupRange,
keyGroupPrefixBytes,
numberOfTransferingThreads,
cancelStreamRegistry,
userCodeClassLoader,
kvStateInformation,
keySerializerProvider,
instanceBasePath,
instanceRocksDBPath,
dbOptions,
columnFamilyOptionsFactory,
nativeMetricOptions,
metricGroup,
restoreStateHandles,
ttlCompactFiltersManager);
}
}
当没有什么 state 需要恢复时,会 new RocksDBNoneRestoreOperation ,当增量做 checkpoint ,恢复的时候 new RocksDBIncrementalRestoreOperation,全量的话是RocksDBFullRestoreOperation。
这里我们以 RocksDBIncrementalRestoreOperation 为例进行分析
@Override
public RocksDBRestoreResult restore() throws Exception {
if (restoreStateHandles == null || restoreStateHandles.isEmpty()) {
return null;
}
final KeyedStateHandle theFirstStateHandle = restoreStateHandles.iterator().next();
boolean isRescaling = (restoreStateHandles.size() > 1 ||
!Objects.equals(theFirstStateHandle.getKeyGroupRange(), keyGroupRange));
if (isRescaling) {
restoreWithRescaling(restoreStateHandles);
} else {
restoreWithoutRescaling(theFirstStateHandle);
}
return new RocksDBRestoreResult(this.db, defaultColumnFamilyHandle,
nativeMetricMonitor, lastCompletedCheckpointId, backendUID, restoredSstFiles);
}
首先呢,最关键性的方法也就是 restore 方法,当进行 rescale 的时候会执行 restoreWithRescaling 方法,其中 restoreStateHandles 可以简单的理解为 需要 restore state 的引用
private void restoreWithRescaling(Collection<KeyedStateHandle> restoreStateHandles) throws Exception {
// Prepare for restore with rescaling
KeyedStateHandle initialHandle = RocksDBIncrementalCheckpointUtils.chooseTheBestStateHandleForInitial(
restoreStateHandles, keyGroupRange);
// Init base DB instance
if (initialHandle != null) {
restoreStateHandles.remove(initialHandle);
initDBWithRescaling(initialHandle);
} else {
openDB();
}
// Transfer remaining key-groups from temporary instance into base DB
byte[] startKeyGroupPrefixBytes = new byte[keyGroupPrefixBytes];
RocksDBKeySerializationUtils.serializeKeyGroup(keyGroupRange.getStartKeyGroup(), startKeyGroupPrefixBytes);
byte[] stopKeyGroupPrefixBytes = new byte[keyGroupPrefixBytes];
RocksDBKeySerializationUtils.serializeKeyGroup(keyGroupRange.getEndKeyGroup() + 1, stopKeyGroupPrefixBytes);
for (KeyedStateHandle rawStateHandle : restoreStateHandles) {
if (!(rawStateHandle instanceof IncrementalRemoteKeyedStateHandle)) {
throw new IllegalStateException("Unexpected state handle type, " +
"expected " + IncrementalRemoteKeyedStateHandle.class +
", but found " + rawStateHandle.getClass());
}
//本地的
Path temporaryRestoreInstancePath = new Path(instanceBasePath.getAbsolutePath() + UUID.randomUUID().toString());
//首先呢会把 rawStateHandle 对应的 state 数据下载到 temporaryRestoreInstancePath 并且作为一个临时的 RocksDB 实例的数据目录
try (RestoredDBInstance tmpRestoreDBInfo = restoreDBInstanceFromStateHandle(
(IncrementalRemoteKeyedStateHandle) rawStateHandle,
temporaryRestoreInstancePath);
RocksDBWriteBatchWrapper writeBatchWrapper = new RocksDBWriteBatchWrapper(this.db)) {
List<ColumnFamilyDescriptor> tmpColumnFamilyDescriptors = tmpRestoreDBInfo.columnFamilyDescriptors;
List<ColumnFamilyHandle> tmpColumnFamilyHandles = tmpRestoreDBInfo.columnFamilyHandles;
// iterating only the requested descriptors automatically skips the default column family handle
for (int i = 0; i < tmpColumnFamilyDescriptors.size(); ++i) {
ColumnFamilyHandle tmpColumnFamilyHandle = tmpColumnFamilyHandles.get(i);
ColumnFamilyHandle targetColumnFamilyHandle = getOrRegisterStateColumnFamilyHandle(
null, tmpRestoreDBInfo.stateMetaInfoSnapshots.get(i))
.columnFamilyHandle;
//会把临时的 rockdb 实例的数据写入到 rocksdb 中
try (RocksIteratorWrapper iterator = RocksDBOperationUtils.getRocksIterator(tmpRestoreDBInfo.db, tmpColumnFamilyHandle)) {
iterator.seek(startKeyGroupPrefixBytes);
while (iterator.isValid()) {
if (RocksDBIncrementalCheckpointUtils.beforeThePrefixBytes(iterator.key(), stopKeyGroupPrefixBytes)) {
// insert data to rocksdb
writeBatchWrapper.put(targetColumnFamilyHandle, iterator.key(), iterator.value());
} else {
// Since the iterator will visit the record according to the sorted order,
// we can just break here.
break;
}
iterator.next();
}
} // releases native iterator resources
}
} finally {
cleanUpPathQuietly(temporaryRestoreInstancePath);
}
}
}
主要就是把对应 state 的 sstFiles、miscFiles 下载到 临时指定的路径中,然后基于这个临时目录启动一个临时的 rockdb,然后将临时的 rockdb 中的数据导入到最终要使用的 rockdb,最后将临时的 rockdb 销毁掉。至于它为什么要两个 rockdb ,就感觉有点奇怪。
4.Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是onReadAndWrite
⭐ 结论:Flink SQL API State TTL 的过期机制目前只支持 onCreateAndUpdate,DataStream API 两个都支持
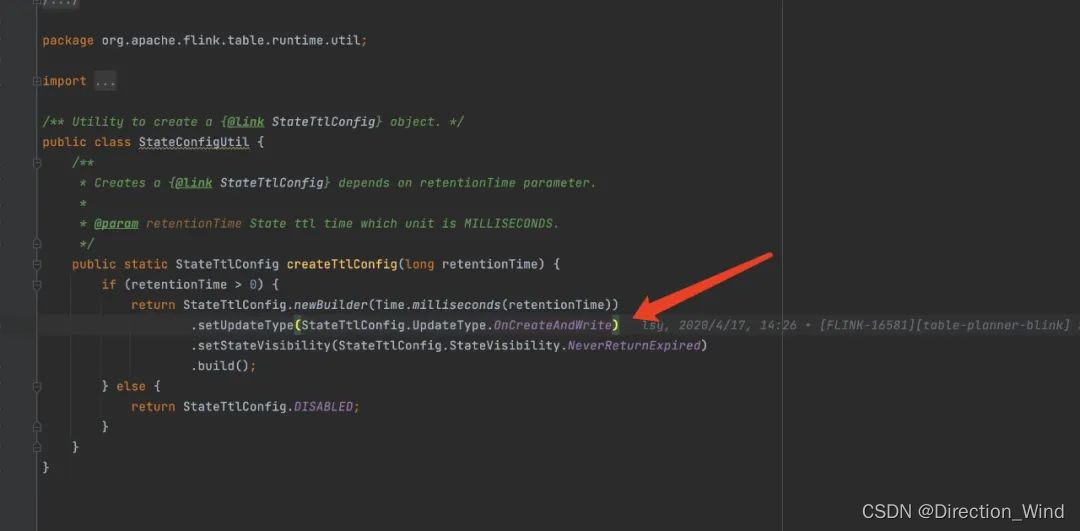
⭐ 剖析:
- onCreateAndUpdate:是在创建 State 和更新 State 时【更新 State TTL】
- onReadAndWrite:是在访问 State 和写入 State 时【更新 State TTL】
⭐ 实际踩坑场景:Flink SQL Deduplicate 写法,row_number partition by user_id order by proctime asc,此 SQL 最后生成的算子只会在第一条数据来的时候更新 state,后续访问不会更新 state TTL,因此 state 会在用户设置的 state TTL 时间之后过期。
5.operator-state 和 keyed-state 两者的区别?最大并行度又和它们有什么关系?举个生产环境中经常出现的案例,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
⭐ 总结如下:
⭐ operator-state:
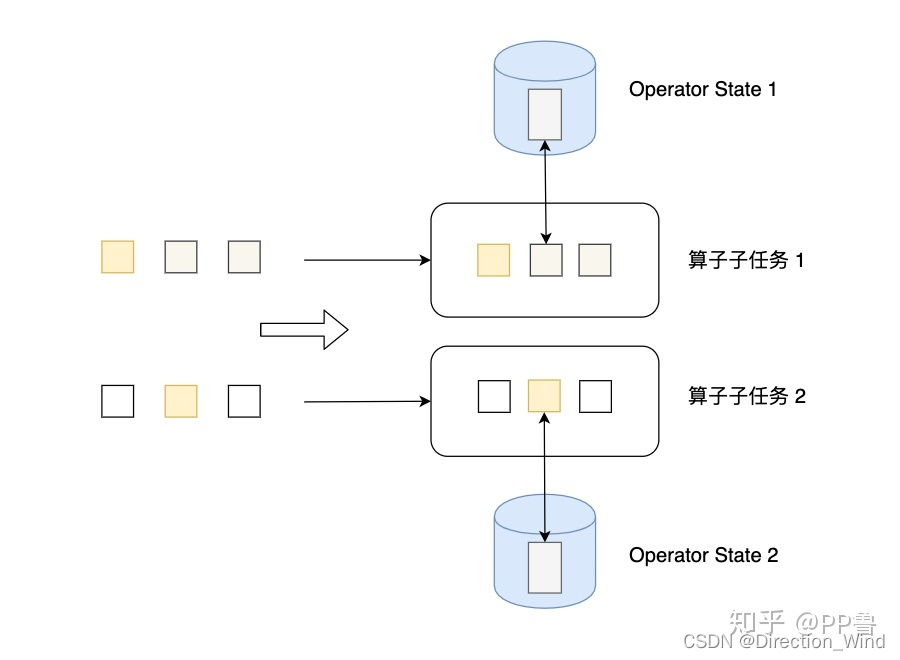
⭐ 状态适用算子:所有算子都可以使用 operator-state,没有限制。
⭐ 状态的创建方式:如果需要使用 operator-state,需要实现 CheckpointedFunction 或 ListCheckpointed 接口
⭐ DataStream API 中,operator-state 提供了 ListState、BroadcastState、UnionListState 3 种用户接口
⭐ 状态的存储粒度:以单算子单并行度粒度访问、更新状态
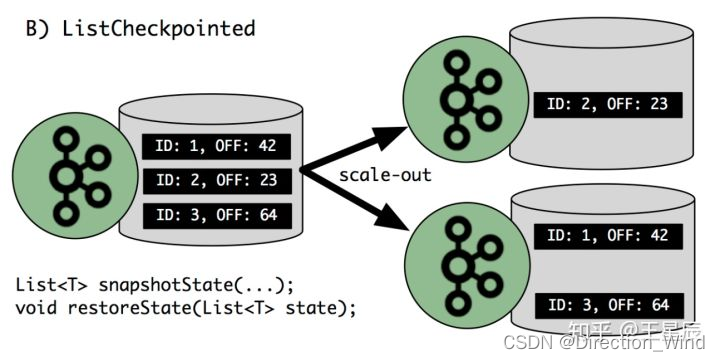
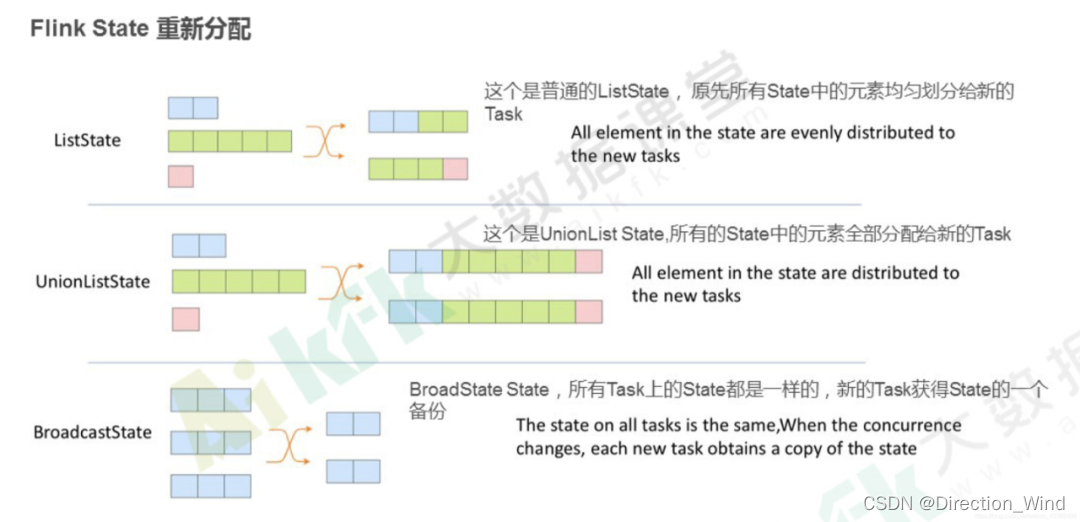
⭐ 并行度变化时:a. ListState:均匀划分到算子的每个 sub-task 上,比如 Flink Kafka Source 中就使用了 ListState 存储消费 Kafka 的 offset,其 rescale 如下图
BroadcastState:每个 sub-task 的广播状态都一样 c. UnionListState:将原来所有元素合并,合并后的数据每个算子都有一份全量状态数据
⭐ keyed-state:
- ⭐ 状态适用算子:keyed-stream 后的算子使用。注意这里很多同学会犯一个错误,就是大家会认为 keyby 后面跟的所有算子都使用的是 keyed-state,但这是错误的 ❌,比如有 keyby.process.flatmap,其中 flatmap 中使用状态的话是 operator-state
- ⭐ 状态的创建方式:从 context 接口获取具体的 keyed-state
- ⭐ DataStream API 中,keyed-state 提供了 ValueState、MapState、ListState 等用户接口,其中最常用 ValueState、MapState
- ⭐ 状态的存储粒度:以单 key 粒度访问、更新状态。举例,当我们使用 keyby.process,在 process 中处理逻辑时,其实每一次 process 的处理 context 都会对应到一个 key,所以在 process 中的处理都是以 key 为粒度的。这里很多同学会犯一个错 ❌,比如想在 open 方法中访问、更新 state,这是不行的,因为 open 方法在执行时,还没有到正式的数据处理环节,上下文中是没有 key 的。
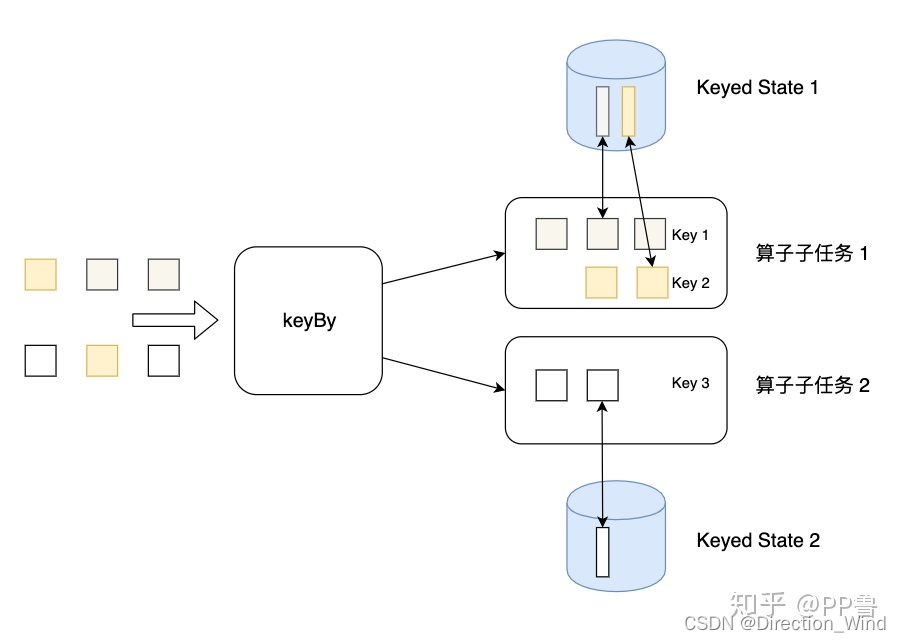
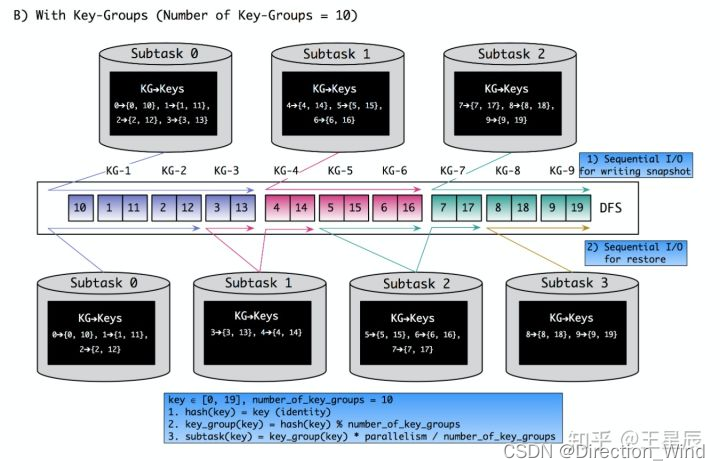
- ⭐ 并行度变化时:keyed-state 的重新划分是随着 key-group 进行的。其中 key-group 的个数就是最大并发度的个数。其中一个 key-group 处理一段区间 key 的数据,不同 key-group 处理的 key 是完全不同的。当任务并行度变化时,会将 key-group 重新划分到算子不同的 sub-task 上,任务启动后,任务数据在做 keyby 进行数据 shuffle 时,依然能够按照当前数据的 key 发到下游能够处理这个 key 的 key-group 中进行处理,如下图所示。注意:最大并行度和 key-group 的个数绑定,所以如果想恢复任务 state,最大并行度是不能修改的。大家需要提前预估最大并行度个数。
6.ValueState 和 MapState 各自适合的应用场景?
- ⭐ ValueState
- 应用场景:简单的一个变量存储,比如 Long\String 等。如果状态后端为 RocksDB,极其不建议在 ValueState 中存储一个大 Map,这种场景下序列化和反序列化的成本非常高,这种常见适合使用 MapState。其实这种场景也是很多小伙伴一开始使用 State 的误用之痛,一定要避免。
- TTL:针对整个 Value 起作用
- ⭐ MapState
- 应用场景:和 Map 使用方式一样一样的
- TTL:针对 Map 的 key 生效,每个 key 一个 TTL
7.Flink 配置 State TTL 时都有哪些配置项?每种配置项的作用?
Flink 对状态做了能力扩展,即 TTL。它的能力其实和 redis 的过期策略类似,举例:
- ⭐ 支持 TTL 更新类型:更新 TTL 的时机
- ⭐ 访问到已过期数据的时的数据可见性
- ⭐ 过期时间语义:目前只支持处理时间
- ⭐ 具体过期实现:lazy,后台线程
那么首先我们看下什么场景需要用到 TTL 机制呢?举例:
比如计算 DAU 使用 Flink MapState 进行去重,到第二天的时候,第一天的 MapState 就可以删除了,就可以用 Flink State TTL 进行自动删除(当然你也可以通过代码逻辑进行手动删除)。
其实在 Flink DataStream API 中,TTL 功能还是比较少用的。Flink State TTL 在 Flink SQL 中是被大规模应用的,几乎除了窗口类、ETL(DWD 明细处理任务)类的任务之外,SQL 任务基本都会用到 State TTL。
那么我们在要怎么开启 TTL 呢?这里分 DataStream API 和 SQL API:
- ⭐ DataStream API:
private final MapStateDescriptor<String, List<Item>> mapStateDesc =
new MapStateDescriptor<>(
"itemsMap",
BasicTypeInfo.STRING_TYPE_INFO,
new ListTypeInfo<>(Item.class));
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// 使用 StateTtlConfig 开启 State TTL
mapStateDesc.enableTimeToLive(StateTtlConfig
.newBuilder(Time.milliseconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.cleanupInRocksdbCompactFilter(10)
.build());
}
关于 StateTtlConfig 的每个配置项的功能如下图所示: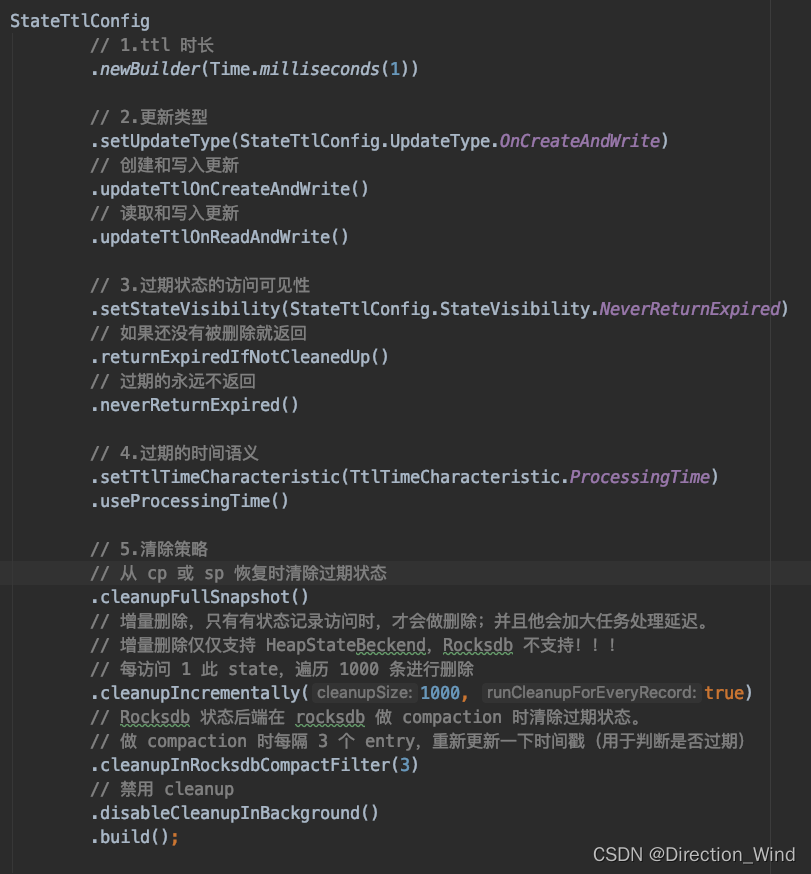
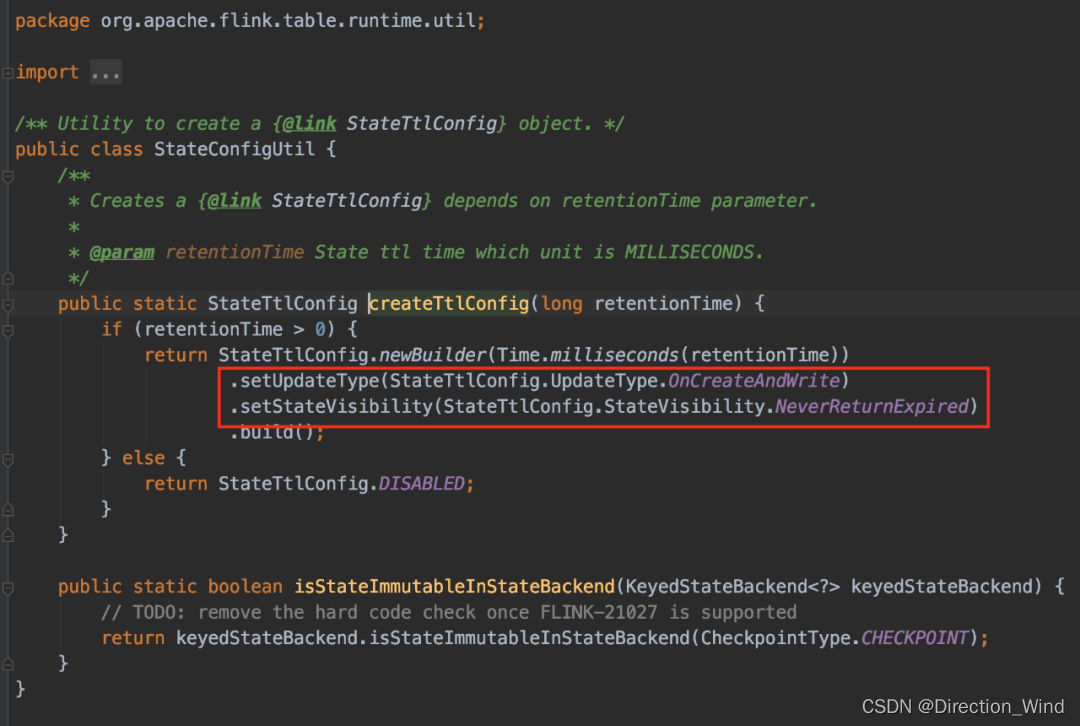
- ⭐ SQL API:
StreamTableEnvironment
.getConfig()
.getConfiguration()
.setString("table.exec.state.ttl", "180 s");
注意:SQL 中 TTL 的策略不如 DataStream 那么多,SQL 中 TTL 只支持下图所示策略:
8.Flink State TTL 是怎么做到数据过期的?首先我们来想想,要做到 TTL 的话,要具备什么条件呢?
想想 Redis 的 TTL 设置,如果我们要设置 TTL 则必然需要给一条数据给一个时间戳,只有这样才能判断这条数据是否过期了。
在 Flink 中设置 State TTL,就会有这样一个时间戳,具体实现时,Flink 会把时间戳字段和具体数据字段存储作为同级存储到 State 中。
举个例子,我要将一个 String 存储到 State 中时:
- ⭐ 没有设置 State TTL 时,则直接将 String 存储在 State 中
- ⭐ 如果设置 State TTL 时,则 Flink 会将 <String, Long> 存储在 State 中,其中 Long 为时间戳,用于判断是否过期。
接下来以 FileSystem 状态后端下的 MapState 作为案例来说:
⭐ 如果没有设置 State TTL,则生产的 MapState 的字段类型如下(可以看到生成的就是 HeapMapState 实例):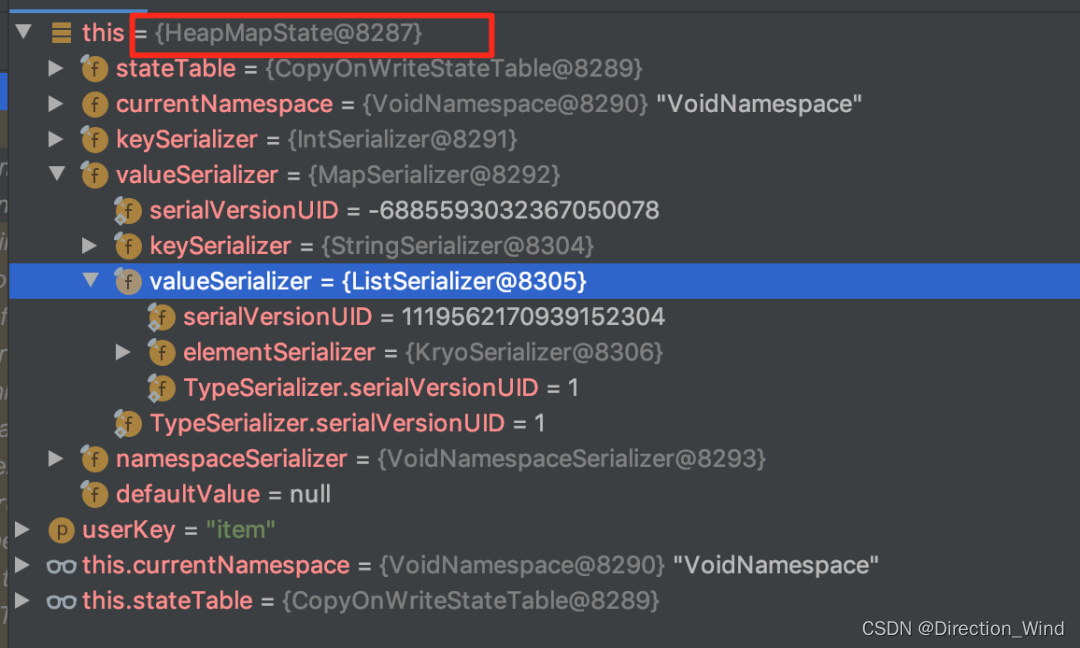
⭐ 如果设置了 State TTL,则生成的 MapState 的字段类型如下(可以看到使用到了装饰器的设计模式生成是 TtlMapState):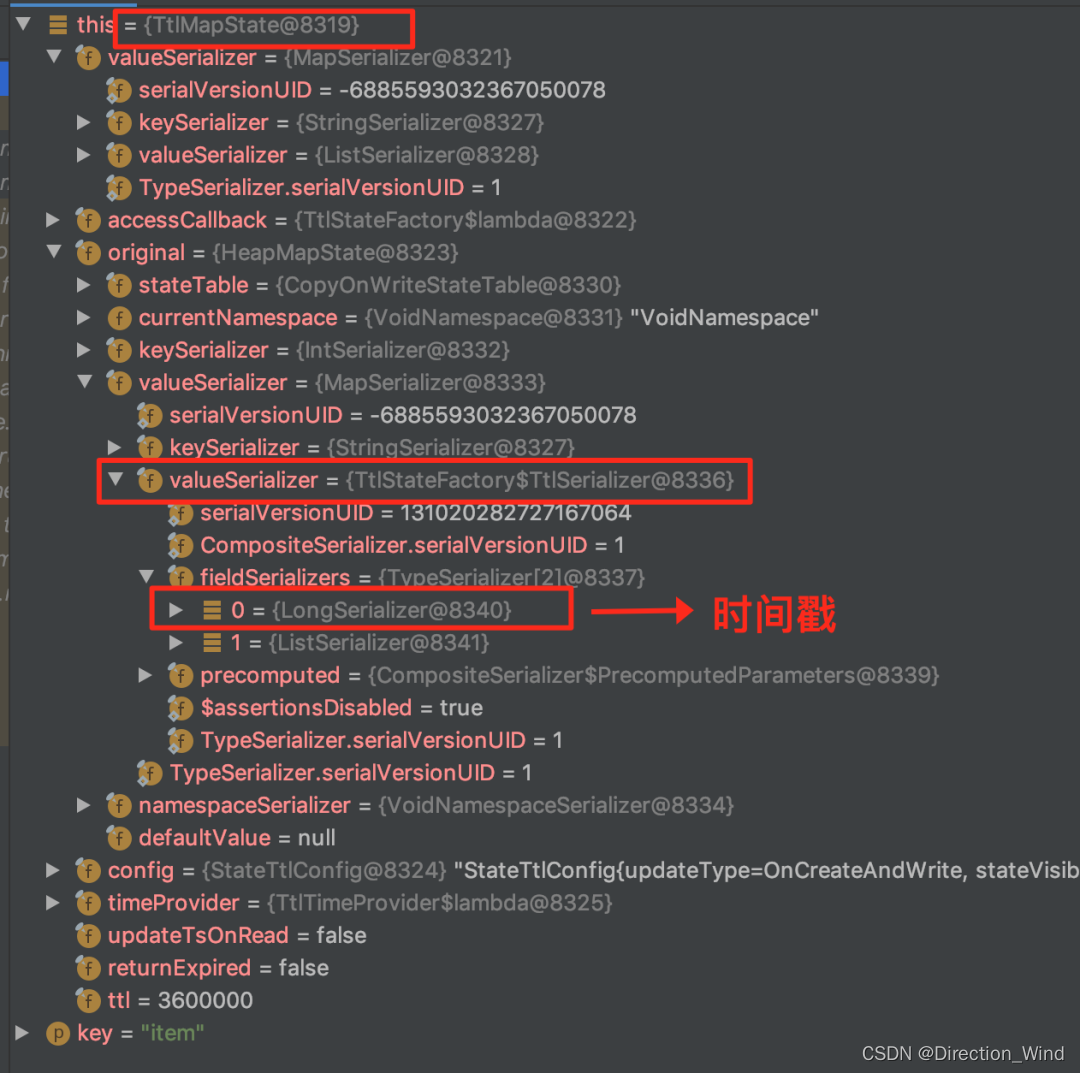
注意:
任务设置了 State TTL 和不设置 State TTL 的状态是不兼容的。这里大家在使用时一定要注意。防止出现任务从 Checkpoint 恢复不了的情况。但是你可以去修改 TTL 时长,因为修改时长并不会改变 State 存储结构。
了解了基础数据结构之后,我们再来看看 Flink 提供的 State 过期的 4 种删除策略:
- ⭐ lazy 删除策略:就是在访问 State 的时候根据时间戳判断是否过期,如果过期则主动删除 State 数据
- ⭐ full snapshot cleanup 删除策略:从状态恢复(checkpoint、savepoint)的时候采取做过期删除,但是不支持 rocksdb 增量 ck
- ⭐ incremental cleanup 删除策略:访问 state 的时候,主动去遍历一些 state 数据判断是否过期,如果过期则主动删除 State 数据
- ⭐ rocksdb compaction cleanup 删除策略:rockdb 做 compaction 的时候遍历进行删除。仅仅支持 rocksdb
8.1.lazy 删除策略
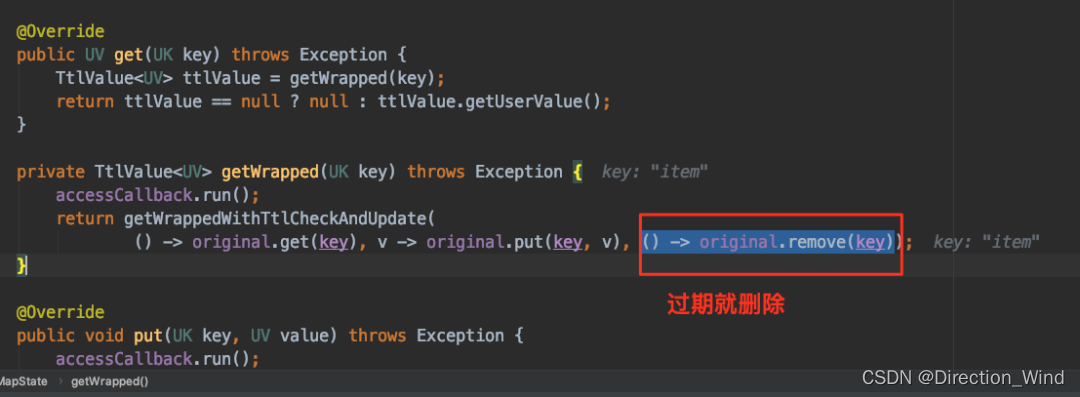
访问 State 的时候根据时间戳判断是否过期,如果过期则主动删除 State 数据。以 MapState 为例,如下图所示,在 MapState.get(key) 时会进行判断是否过期:
这个删除策略是不需要用户进行配置的,只要你打开了 State TTL 功能,就会默认执行。
8.2.full snapshot cleanup 删除策略
从状态恢复(checkpoint、savepoint)的时候采取做过期删除,但是不支持 rocksdb 增量 checkpoint。
StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build()
8.3.incremental cleanup 删除策略
访问 state 的时候,主动去遍历一些 state 数据判断是否过期,如果过期则主动删除 State 数据。
StateTtlConfig
.newBuilder(Time.seconds(1))
// 每访问 1 此 state,遍历 1000 条进行删除
.cleanupIncrementally(1000, true)
.build()
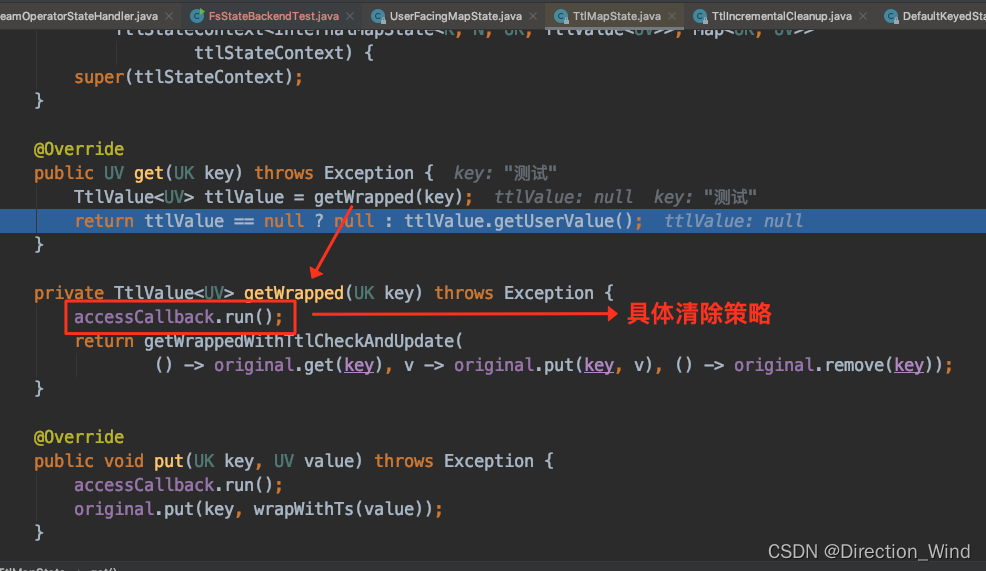
注意:
- ⭐ 如果没有 state 访问,也没有处理数据,则不会清理过期数据。
- ⭐ 增量清理会增加数据处理的耗时。
- ⭐ 现在仅 Heap state backend 支持增量清除机制。在 RocksDB state backend 上启用该特性无效。
- ⭐ 因为是遍历删除 State 机制,并且每次遍历的条目数是固定的,所以可能会出现部分过期的 State 很长时间都过期不掉导致 Flink 任务 OOM。
8.4.rocksdb compaction cleanup 删除策略
仅仅支持 rocksdb。在 rockdb 做 compaction 的时候遍历进行删除。
StateTtlConfig
.newBuilder(Time.seconds(1))
// 做 compaction 时每隔 3 个 entry,重新更新一下时间戳(这个时间戳是 Flink 用于和数据中的时间戳来比较判断是否过期)
.cleanupInRocksdbCompactFilter(3)
.build()
注意:rocksdb compaction 时调用 TTL 过滤器会降低 compaction 速度。因为 TTL 过滤器需要解析上次访问的时间戳,并对每个将参与压缩的状态进行是否过期检查。对于集合型状态类型(比如 ListState 和 MapState),会对集合中每个元素进行检查。