前几周的车道线检测方法都是在公开的数据集上进行的检测,而在小车上摄像头对于车道线的检测需要进一步思考,场地不确定以及小车高度摄像头高度的不确定,使得车道线的检测困难重重。更具体的讲,前些周的工作适合摄像头高度较高的情况下进行检测,在一开始的数据集标注时,车道线就被视为一条细线,前面提及的模型对于这种情况下的路况十分适合。而在小车的高度下,它所拍摄到的摄像头的高度汽车高度相差很大,在不能调整摄像头的前提下,我选择了继续探索图像分割方面的深度学习模型。
首先便是对于Unet的探索,该模型是图像分割领域基础的模型,具有开创性的意义。
Unet模型
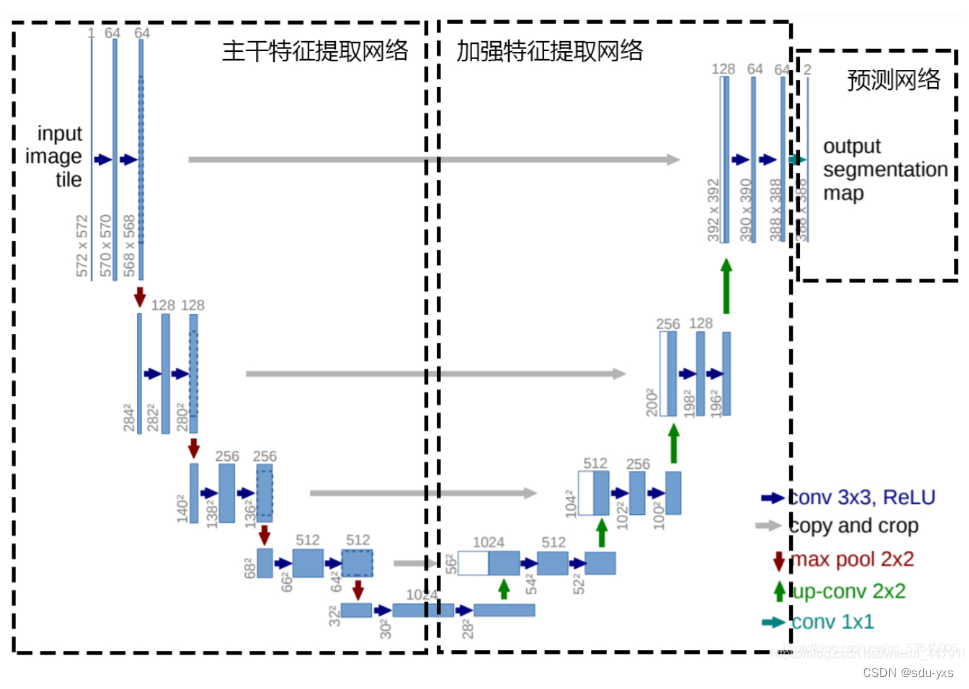
第一部分是主干特征提取部分,我们可以利用主干部分获得一个又一个的特征层,Unet的主干特征提取部分与VGG相似,为卷积和最大池化的堆叠。利用主干特征提取部分我们可以获得五个初步有效特征层,在第二步中,我们会利用这五个有效特征层可以进行特征融合。我使用的unet网络该部分主要是由两层卷积和激活函数组成
class conv_block(nn.Module):
"""
Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.conv(x)
return
第二部分是加强特征提取部分,我们可以利用主干部分获取到的五个初步有效特征层进行上采样,并且进行特征融合(对上采样得到的结果进行通道的堆叠),获得一个最终的,融合了所有特征的有效特征层。这也是Unet的精髓所在,添加了skip-connection的机制,从而使得融合了更多有效的特征,使得模型的预测会更准确。
该部分主要是一个反卷积和激活函数组成,而代入的tensor则是上一层的输出和对应的同层之间的第一部分的张量
class up_conv(nn.Module):
"""
Up Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x
第三部分是预测部分,我们会利用最终获得的最后一个有效特征层对每一个特征点进行分类,相当于对每一个像素点进行分类。
模型尝试
因此针对该网络我展开了制作训练集,训练,测试等一系列的操作:
标注数据集
数据集需要使用labelme进行标注,得到相关的车道线分割json数据集,通过和上篇文章相同的ultra-fast-lane-detection模型相同的方法。
进行数据处理和读取
class PipeDataset(Dataset):
def __init__(self, DatasetFolderPath, ImgTransform, LabelTransform, ShowSample=False):
self.DatasetFolderPath = DatasetFolderPath
self.ImgTransform = ImgTransform
self.LabelTransform = LabelTransform
self.ShowSample = ShowSample
self.SampleFolders = os.listdir(self.DatasetFolderPath)
def __len__(self):
return len(self.SampleFolders)
def __getitem__(self, item):
SampleFolderPath = os.path.join(self.DatasetFolderPath, self.SampleFolders[item]) # 样本文件夹路径
FusionImgPath = os.path.join(SampleFolderPath, 'img.png')
LabelImgPath = os.path.join(SampleFolderPath, 'label.png')
FusionImg = Image.open(FusionImgPath)
LabelImg = Image.open(LabelImgPath)
LabelImg = np.array(LabelImg)*255
LabelImg = Image.fromarray(LabelImg)
# %% 保证样本和标签具有相同的变换
seed = np.random.randint(2147483647)
random.seed(seed)
FusionImg = self.ImgTransform(FusionImg)
random.seed(seed)
LabelImg = self.LabelTransform(LabelImg)
# %% 显示Sample
if self.ShowSample:
plt.figure(self.SampleFolders[item])
Img = FusionImg.numpy()[0]
Label = LabelImg.numpy()[0]
Img = (Normalization(Img) * 255).astype(np.uint8)
Label = (Normalization(Label) * 255).astype(np.uint8)
Img = cv2.cvtColor(Img, cv2.COLOR_GRAY2RGB)
Img[..., 2] = Label
plt.imshow(Img)
plt.show()
return FusionImg, LabelImg, self.SampleFolders[item]
def PipeDatasetLoader(FolderPath, BatchSize=1, ShowSample=False):
TrainFolderPath = os.path.join(FolderPath, 'Train')
TrainDataset = PipeDataset(TrainFolderPath, TrainImgTransform, TrainLabelTransform, ShowSample)
TrainDataLoader = DataLoader(TrainDataset, batch_size=BatchSize, shuffle=True, drop_last=False, num_workers=0, pin_memory=True)
ValFolderPath = os.path.join(FolderPath, 'Val')
ValDataset = PipeDataset(ValFolderPath, ValImgTransform, ValLabelTransform, ShowSample)
ValDataLoader = DataLoader(ValDataset, batch_size=1, shuffle=False, drop_last=False, num_workers=0, pin_memory=True)
return TrainDataset, TrainDataLoader, ValDataset, ValDataLoader
def Normalization(Array): # 数组归一化到0~1
min = np.min(Array)
max = np.max(Array)
if max - min == 0:
return Array
else:
return (Array - min) / (max - min)
训练过程
LrScheduler = torch.optim.lr_scheduler.StepLR(Optimizer, step_size=LrDecayPerEpoch, gamma=LrDecay) # 设置学习率策略
for Epoch in range(1, Epochs + 1):
# %% 训练
Unet.train() # 训练模式
# torch.cuda.empty_cache() # 释放缓存占用, 耗时大概0.05s
# 训练一个Epoch
TrainLoss = 0
print('Epoch:%d, LR:%.8f ' % (Epoch, LrScheduler.get_lr()[0]), end='>> ', flush=True)
for Iter, (InputImg, Label, SampleName) in enumerate(TrainDataLoader):
print(Iter, end=' ', flush=True)
InputImg = InputImg.float().to('cuda')
Label = Label.float().to('cuda')
Weight = Label * (WeightCoefficient-1) + 1
Criterion.weight = Weight
Optimizer.zero_grad()
with torch.set_grad_enabled(True):
OutputImg = Unet(InputImg)
BatchLoss = Criterion(OutputImg, Label)
BatchLoss.backward()
Optimizer.step()
TrainLoss += BatchLoss.item()
AveTrainLoss = TrainLoss / TrainDataset.__len__() * BatchSize # 平均每幅图像的loss
print(", Total loss is: %.6f" % float(AveTrainLoss))
logging.warning('\tTrain\tEpoch:{0:04d}\tLearningRate:{1:08f}\tLoss:{2:08f}'.format(Epoch, LrScheduler.get_lr()[0], AveTrainLoss))
# %% 测试
if Epoch % ValidPerEpoch == 0 or Epoch == 1:
Unet.eval() # 训练模式
torch.cuda.empty_cache() # 释放缓存占用
ValLoss = 0
print('Validate:', end='>>', flush=True)
for Iter, (InputImg, Label, SampleName) in enumerate(ValDataLoader):
print(Iter, end=' ', flush=True)
InputImg = InputImg.float().to('cuda')
Label = Label.float().to('cuda')
Weight = Label * (WeightCoefficient - 1) + 1
Criterion.weight = Weight
with torch.set_grad_enabled(False): # 等同于torch.no_grad()
OutputImg = Unet(InputImg)
BatchLoss = Criterion(OutputImg, Label) # CrossEntropyLoss的Target必须没有通道的维度,即(BatchSize, W, H)
ValLoss += BatchLoss.item()
AveValLoss = ValLoss / ValDataset.__len__()
print("Total loss is: %.6f" % float(AveValLoss))
logging.warning('\t\t\t\t\t\t\t\t\t\t\t\t\t\t\tValid\tEpoch:{0:04d}\tLearningRate:{1:08f}\tLoss:{2:08f}'.format(Epoch, LrScheduler.get_lr()[0], AveValLoss))
# %% 保存
if Epoch % SavePerEpoch == 0:
torch.save(Unet.state_dict(), os.path.join(SaveFolder, '{0:04d}.pt'.format(Epoch)))
# %% 每隔一定epoch后更新一次学习率
LrScheduler.step()
测试
# %% 测试
Unet.eval() # 训练模式
torch.set_grad_enabled(False)
OutputS = [] # 存储检测数据,用于指标计算
LabelS = []
for Iter, (Input, Label, SampleName) in enumerate(ValDataLoader):
end = timer(8)
print(SampleName)
InputImg = Input.float().to(Device)
OutputImg = Unet(InputImg)
Output = OutputImg.cpu().numpy()[0]
Label = Label.detach().cpu().numpy()[0]
OutputS.append(Output)
LabelS.append(Label)
end('5555')
# 生成效果图
OutputImg = OutputImg.cpu().numpy()[0, 0]
OutputImg = (OutputImg*255).astype(np.uint8)
Input = Input.numpy()[0][0]
Input = (Normalization(Input) * 255).astype(np.uint8)
ResultImg = cv2.cvtColor(Input, cv2.COLOR_GRAY2RGB)
ResultImg[...,2] = OutputImg
# plt.imshow(Label[0])
plt.show()
cv2.imwrite(os.path.join(SaveFolder, SampleName[0] + '.png'), ResultImg)
总结
Unet的效果很好,但是他有以下几个缺点:
1.模型参数过多,生成的模型文件过大,有110M。
2.模型的测试过程中帧数过低,在我的1650显卡上只有十几帧。
3.模型测试中占用的资源过多,这样在Tx2的板子上不知道能不能承受的住。