逻辑回归模型
逻辑回归是回归模型还是分类模型?
分类模型。分类与回归最大的差别在于输出变量Y的形式不同,前者Y取有限个离散值,后者的Y是连续值。
为什么名字中带“回归”二字?
逻辑回归就是用回归的方法(用函数拟合自变量和因变量关系),加上一个分类规则,对结果分类。
逻辑回归(Logistic Regression),简称为LR,是机器学习中的一种分类问题。常用于二分类问题。比如预测用户是否点击特定商品,判断肿瘤是阴性还是阳性。
1逻辑函数(sigmoid函数)
逻辑函数,又称为sigmoid函数,其返回值是 0 到 1 之间的数,正好对应为概率的返回值。表示形式为
1 1 + e − z \frac{1}{1+e^{-z}}1+e−z1
g(z)越趋近于 1,表示结果为 1 的概率越大,且概率值就等于 g(z),反之,当 g(z)越趋近于 0,表示结果为 0 的概率越大,且概率值等于 1- g(z)。
对应的函数图像是一个取值在0和1之间的S型曲线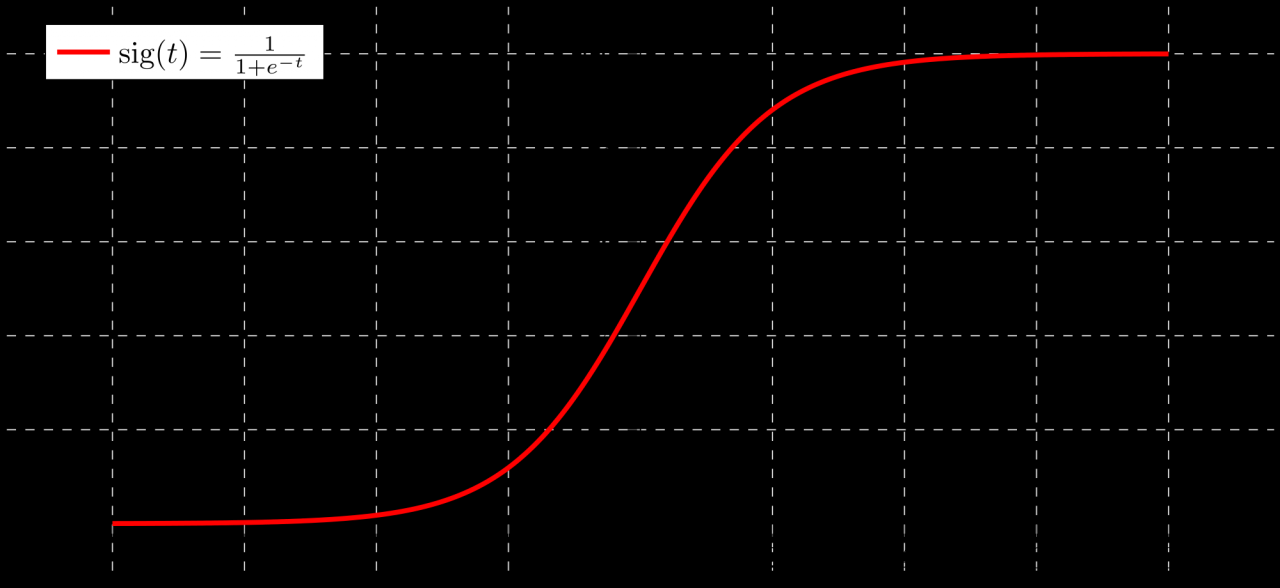
这个函数起源于人们对人口增长的研究,由一个比利时科学家推导出来。
2逻辑回归模型
2.1模型定义
逻辑回归模型用条件概率分布P(Y|X)表示, 当随机变量Y取值为1或0时,称为二项逻辑回归模型。二项逻辑回归模型是目前使用最广泛的逻辑回归模型,因此如非特别说明,本文中逻辑回归模型一般代指二项逻辑回归模型。
模型公式如下,
p ( Y = 1 ∣ x ) = e w x + b 1 + e w x + b p(Y=1|x)=\frac{e^{wx+b}}{1+e^{wx+b}}p(Y=1∣x)=1+ewx+bewx+b
p ( Y = 0 ∣ x ) = 1 1 + e w x + b p(Y=0|x)=\frac{1}{1+e^{wx+b}}p(Y=0∣x)=1+ewx+b1
x ∈ R n x\in{R^n}x∈Rn是输入,y ∈ { 0 , 1 } y\in\{0,1\}y∈{0,1}是输出, w ∈ R n w\in{R^n}w∈Rn,b ∈ R b\in{R}b∈R,w称为权值向量,b称为偏置,w*x为w和x的内积。当w,x为多维矩阵时,b可忽略不计。
逻辑回归是为了解决分类问题,需要找到一个足够区分度的决策边界(wx+b), 在这个基础上找到分类概率与输入变量的关系,然后通过比较概率值判断属于哪一类。
为什么选择sigmoid函数作为逻辑回归模型的判别函数?
判别函数:用来表示和鉴别某个特征矢量属于哪个类别的函数
条件概率服从指数族分布,进而可以推导出sigmoid函数。具体过程省略
2.2模型参数估计
在实际应用中,随机变量X已知,只需要求出参数w, 就可以计算出事件预测结果概率,如果概率大于阈值,我们认为样本是正类,否则样本是负类。
如何确定w的值呢?
模型的目的就是尽可能准确的将样本分类,换句话就是让预测的结果全部准确的概率最大。因此采用最大似然估计。
为什么不用采用的最小二乘法?
用最小二乘法得到的损失函数不是关于参数w的凸函数,在求解过程中会得到局部最优,不容易得到全局最优。
设 p ( Y = 1 ∣ x ; w ) = h ( x ) p(Y=1|x;w)=h(x)p(Y=1∣x;w)=h(x), p ( Y = 0 ∣ x ; w ) = 1 − h ( x ) p(Y=0|x;w)=1-h(x)p(Y=0∣x;w)=1−h(x)
单个样本预测正确的概率
(3) p ( y i ∣ x ; w ) = ( h ( x ) y i ( 1 − h ( x ) ) 1 − y i p(y_i|x;w)=(h(x)^{y_i}(1-h(x))^{1-{y_i}} \tag{3}p(yi∣x;w)=(h(x)yi(1−h(x))1−yi(3)
所有样本预测正确概率即似然函数
(4) ∏ i = 1 N [ h ( x i ) y i ] [ 1 − h ( x i ) ] 1 − y i \prod_{i=1}^N[h(x_i)^{y_i}][1-h(x_i)]^{1-{y_i}}\tag{4}i=1∏N[h(xi)yi][1−h(xi)]1−yi(4)
对数似然函数
(5) L ( w ) = ∑ i = 1 N [ y i ( w ∗ x i ) − l o g ( 1 + e x p ( w ∗ x i ) ] L(w)=\sum_{i=1}^N[y_i(w*x_i)-log(1+exp(w*x_i)]\tag{5}L(w)=i=1∑N[yi(w∗xi)−log(1+exp(w∗xi)](5)
N为样本总个数,x i x_ixi表示第i个样本,y i y_iyi表示第i个样本的类别
极大似然函数取对数后的损失函数,求解参数速度比较快。因为梯度更新速度与x,y有关,和sigmoid函数本身无关。
对L(W)求极大值,得到w的估计值。问题就变成了以对数似然函数为目标函数的最优化问题。通常采用的方法是梯度上升法(下降法)。
2.3梯度上升算法
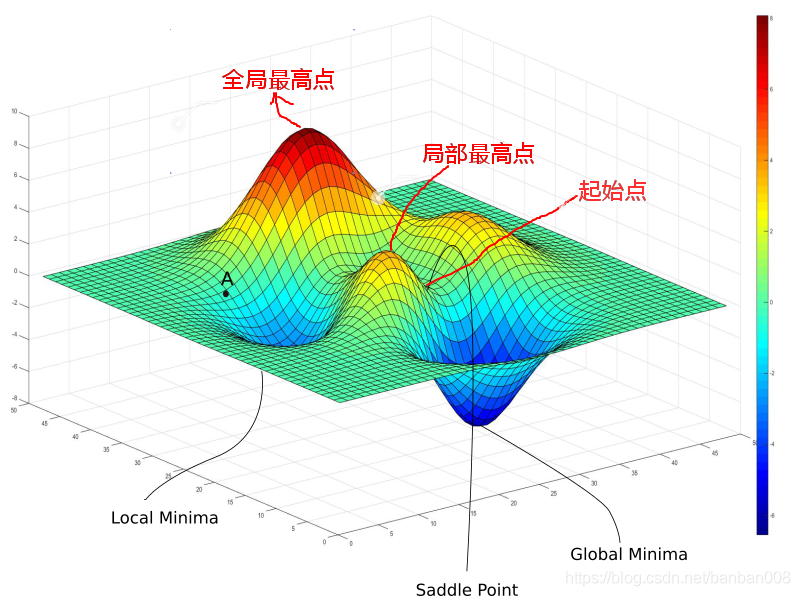
梯度上升算法是一种迭代算法,选取适当初始值x,不断迭代,更新x的值,直到梯度不断减小,最后趋于0。梯度指的是能够使函数变化最快的向量。
通俗来讲,梯度上升是个爬坡的过程,每一次迭代都是在找最陡峭的路也是最快的路爬到山顶。见下图
表示公式
(6) X i + 1 = X i + α ∗ ∂ f ( X i ) X i X_{i+1} = X_i + \alpha* \frac{\partial {f(X_i)}}{X_i}\tag{6}Xi+1=Xi+α∗Xi∂f(Xi)(6)
α \alphaα是步长
根据表达式(5)(6)得出对数似然函数的梯度迭代公式
(7) w i + 1 = w i + α ( y i − h ( x i ) ) x i w_{i+1}=w_i+\alpha(y_i-h(x_i))x_i\tag{7}wi+1=wi+α(yi−h(xi))xi(7)
梯度下降算法与梯度上升算法原理一致,区别在于梯度上升是求函数的极大值,而梯度下降是求函数的极小值。
表示公式
(8) X i + 1 = X i − α ∗ ∂ f ( X i ) X i X_{i+1} = X_i - \alpha* \frac{\partial {f(X_i)}}{X_i}\tag{8}Xi+1=Xi−α∗Xi∂f(Xi)(8)
2.4多项逻辑回归
上面介绍的逻辑回归模型用于二分类问题。如果是多分类问题,则采用多项逻辑回归模型
。假设离散型随机变量Y的取值集合是{1,2,…,K},那么回归模型为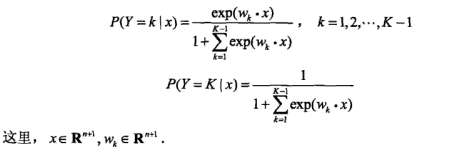
2.5正则化
正则化是为了防止模型过拟合(过拟合现象是指对训练数据预测很好但是对未知数据预测不行的现象),而在代价函数(cost function)后面加上一个小尾巴惩罚项,用来限制模型参数值不要过大。一般是在目标函数中加一个正则化项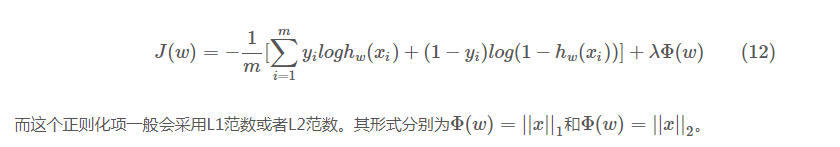
2.5.1 L1范数
L1范数ϕ ( w ) = ∣ w ∣ \phi(w)=|w|ϕ(w)=∣w∣,当采用梯度下降方式来优化目标函数时,对目标函数进行求导,正则化项导致的梯度变化当w j w_jwj>0时取1,当w j w_jwj<0时取-1.
当w j w_jwj大于0的时候,w j w_jwj会减去一个正数,导致w j w_jwj减小,而当w j w_jwj小于0的时候,w j w_jwj会减去一个负数,导致w j w_jwj又变大,因此这个正则项会导致参数w j w_jwj取值趋近于0,也就是为什么L1正则能够使权重稀疏,这样参数值就受到控制会趋近于0。L1正则还被称为 Lasso regularization。
2.2.2 L2范数
L2范数∑ w j 2 \sum{w_j}^2∑wj2,同样对它求导∂ ϕ ( w ) ∂ w j = 2 w j \frac{\partial{\phi(w)}}{\partial{w_j}} = 2w_j∂wj∂ϕ(w)=2wj,得到梯度变化为(一般会用λ 2 {\lambda}\over{2}2λ来把这个系数2给消掉)。同样的更新之后使得wj的值不会变得特别大。在机器学习中也将L2正则称为weight decay,在回归问题中,关于L2正则的回归还被称为Ridge Regression岭回归。weight decay还有一个好处,它使得目标函数变为凸函数,梯度下降法和L-BFGS都能收敛到全局最优解。
需要注意的是,L1正则化会导致参数值变为0,但是L2却只会使得参数值减小,这是因为L1的导数是固定的,参数值每次的改变量是固定的,而L2会由于自己变小改变量也变小。而(12)式中的λ也有着很重要的作用,它在权衡拟合能力和泛化能力对整个模型的影响,λ越大,对参数值惩罚越大,泛化能力越好。
3模型评价
3.1优点
- 形式简单,模型的可解释性非常好。从特征的权重可以看到不同的特征对最后结果的影响,某个特征的权重值比较高,那么这个特征最后对结果的影响会比较大。
- 训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。
- 资源占用小,尤其是内存。因为只需要存储各个维度的特征值。
- 方便输出结果调整。因为输出的是每个样本的概率分数,可以很容易的对这些概率分数 进行划分阈值(大于某个阈值的是一类,小于某个阈值的是一类)。
3.2缺点
- 容易欠拟合,精度不高。因为形式非常的简单(非常类似线性模型),很难去拟合数据的真实分布。
- 很难处理数据不平衡的问题。举个例子:如果我们对于一个正负样本非常不平衡的问题比如正负样本比 10000:1.我们把所有样本都预测为正也能使损失函数的值比较小。但是作为一个分类器,它对正负样本的区分能力不会很好。
- 处理非线性数据较麻烦。逻辑回归在不引入其他方法的情况下,只能处理线性可分的数据,或者进一步说,处理二分类的问题 。
3.3应用
- 用于预测,常用于流失预警、客户响应
- 用于分类,适合做很多分类算法的基础组件
- 用户分析:单一因素对某一个事件发生的影响因素分析(特征参数值),主要在流行病学中应用较多
4一句话总结
逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法得到目标函数,运用梯度下降来求解参数,来达到将数据二分类的目的
5参考文献
统计学习方法,李航,P78
Logistic回归与梯度上升算法
逻辑回归的常见面试点总结
逻辑回归(logistics regression)
最大似然估计(MLE)与最小二乘估计(LSE)的区别
Logistic回归总结
机器学习面试之逻辑回归输出的值是真实的概率吗?
解释logistic回归为什么要使用sigmoid函数
【机器学习算法系列之二】浅析Logistic Regression
Sklearn-LogisticRegression逻辑回归(有处理样本不均衡时设置参数的方法)