python爬虫之BeautifulSoup4数据提取案例
本文采用bs4爬取bilibili全站排行榜,并打印成excel表格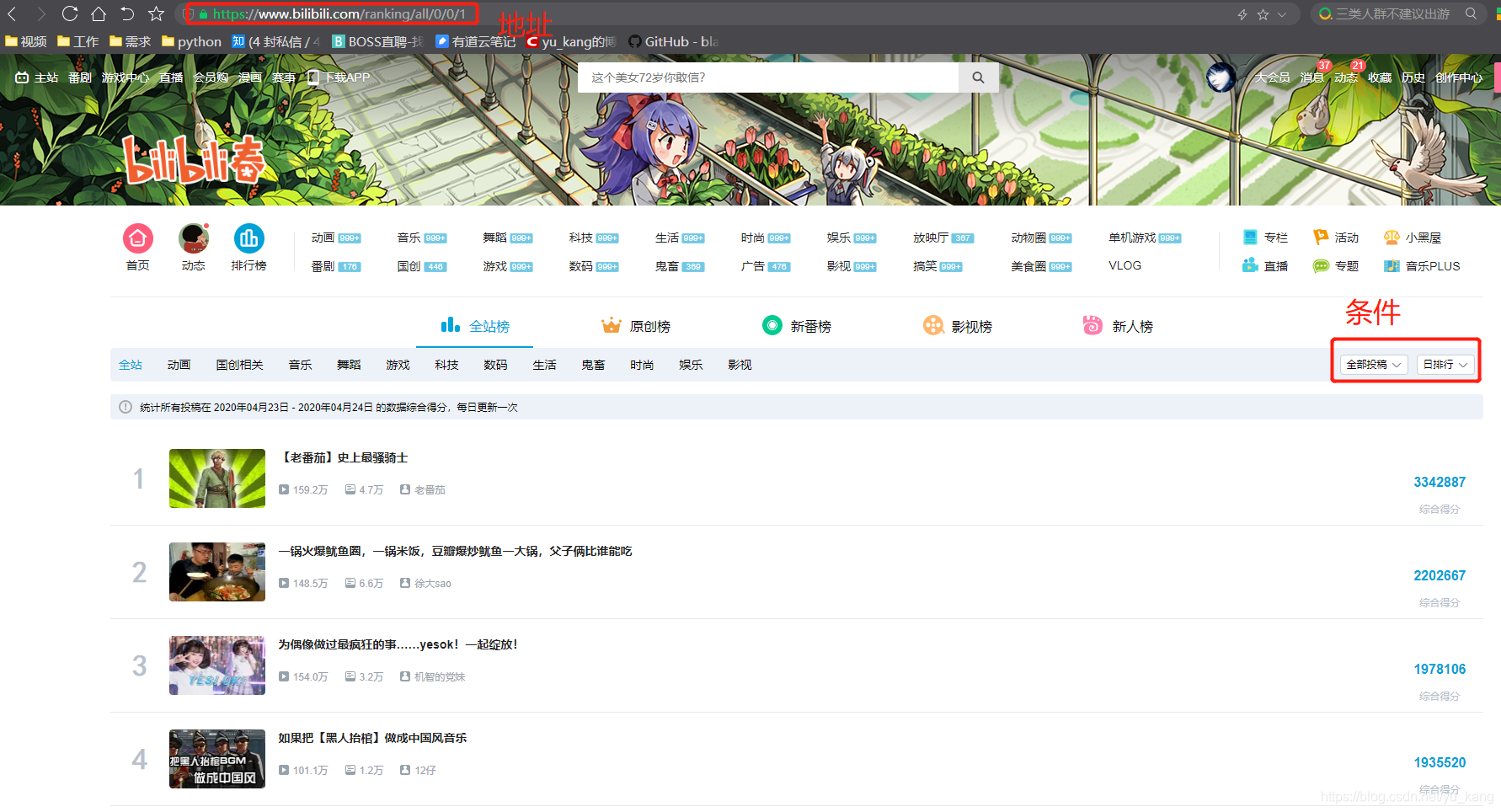
f12查看页面布局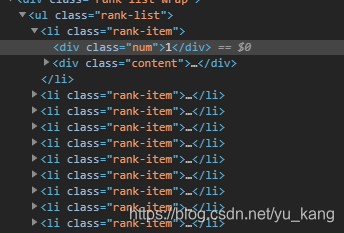
编码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/4/16 0016 20:46
# @Site : blibili全站榜
# @Author : Yuk
# @File : bilibili_bs4.py
import bs4
import requests
import openpyxl
# 搜索条件
recent = 1 # 近期投稿
whole = 0 # 全部投稿
day = 1 # 日排行
three_day = 3 # 三日排行
weekend = 7 # 周排行
month = 30 # 月排行
# 获取链接
def get_url(type='all', tg=0, day=3, base_url='https://www.bilibili.com/ranking/'):
"""
:param type: 榜单类型:默认all(全站榜)
:param tg: 投稿:默认0(0全部投稿 1近期投稿)
:param day: 日期:默认3(三日排行)
:param base_url: 基础路径
:return: 拼接后url
"""
return base_url + type + '/0' + '/' + str(tg) + '/' + str(day)
headers = {'user-agent': 'Mozilla/5.0'}
days = weekend
res = requests.get(get_url(day=days), headers=headers)
soup = bs4.BeautifulSoup(res.text, 'lxml')
wb = openpyxl.Workbook()
ws = wb.create_sheet(str(days) + '日排行')
# 设置列宽
ws.column_dimensions['C'].width = 100
ws.column_dimensions['D'].width = 45
ws.column_dimensions['G'].width = 15
ws.column_dimensions['H'].width = 45
# 标题
ws.append(['排行', '图片', '标题', '链接', '播放量', '点击量', 'up主', 'up主个人空间', '综合得分'])
for tag in soup.select("li[class='rank-item']"):
_list = [] # 行数据
# 排行
num = tag.find('div', {'class': 'num'}).string
_list.append(num)
# 图片
img = tag.find('div', {'class': 'img'}).find('img').attrs['src']
_list.append(img)
link_info = tag.find('a', {'class': 'title'})
# 标题
title = link_info.string
_list.append(title)
# 链接
link = link_info.attrs['href']
_list.append(link)
# 播放量、点击量、up主、up主个人空间
data_box = tag.find_all('span', {'class': 'data-box'})
play = data_box[0].text
view = data_box[1].text
author = data_box[2].text
author_link = 'https:' + data_box[2].parent.attrs['href']
_list.append(play)
_list.append(view)
_list.append(author)
_list.append(author_link)
# 综合得分
score = tag.find('div', {'class': 'pts'}).div.string
_list.append(score)
ws.append(_list)
# 保存excel
wb.save('d:/bilibili热门视频_' + str(days) +'日排行.xls')
wb.close()
生成的excel数据
查看日排行
版权声明:本文为yu_kang原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。