1、导入pymysql库和jieba库
这里使用的是中科大的镜像,很快。
安装jieba库同理。
2、编写代码
# -*- coding: utf-8 -*-
# @Time: 2020/8/25 19:24
# @Author: fanlumaster
# @File: douban.py
# @Software: PyCharm
import pymysql
import jieba
# 连接数据库
db = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='123456', db='douban', charset='utf8')
cursor = db.cursor()
# 测试,打印一下mysql版本
cursor.execute("select version()")
data = cursor.fetchone()
print("Database Version:%s" %data)
# 执行查询语句
sql = 'select * from posts'
cursor.execute(sql)
result = cursor.fetchall()
# 开始打印
print("开始打印")
i = 1
str = ""
for res in result:
print(i)
# print(res[5])
str += res[5]
i = i + 1
# print(res)
print(str)
cursor.close()
# 开始用jieba统计词频
words = jieba.lcut(str)
counts = {}
for word in words:
if len(word) == 1: # 排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word, 0) + 1 # 这里的0表示如果word这个键不在字典中,就添加这个键,并且默认为0,如果加上后面的1,就合理了
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True) # 以出现的次数为标准,从大到小
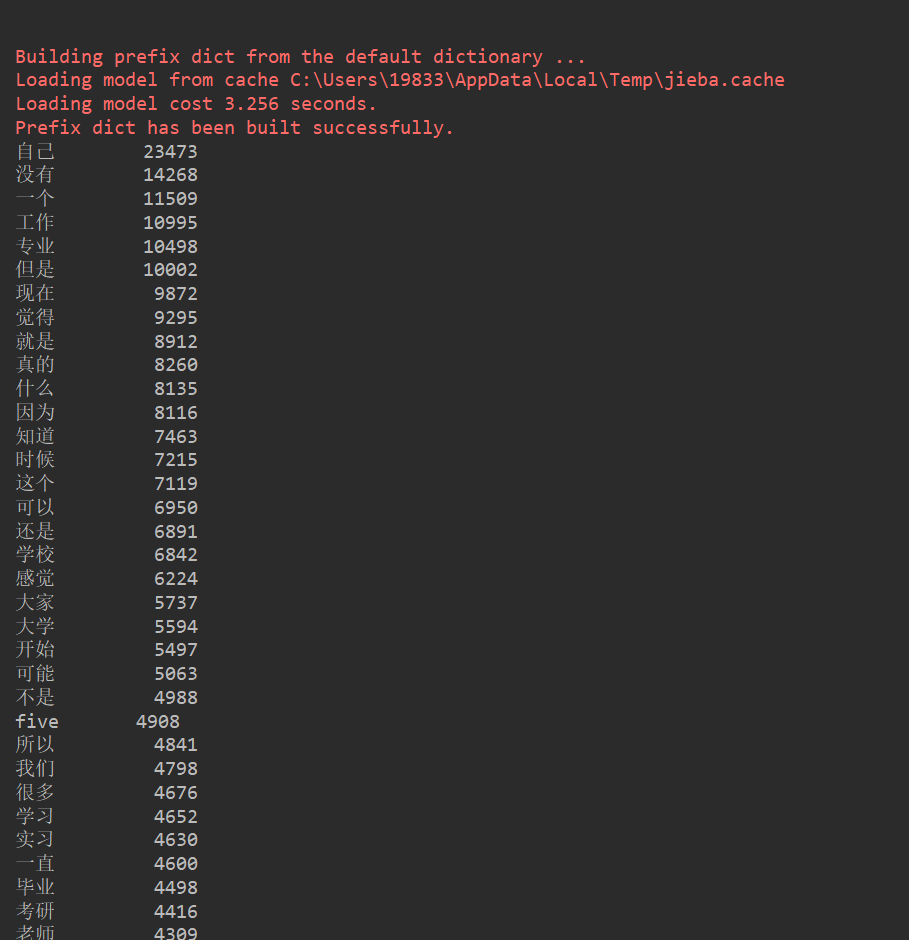
for i in range(100):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
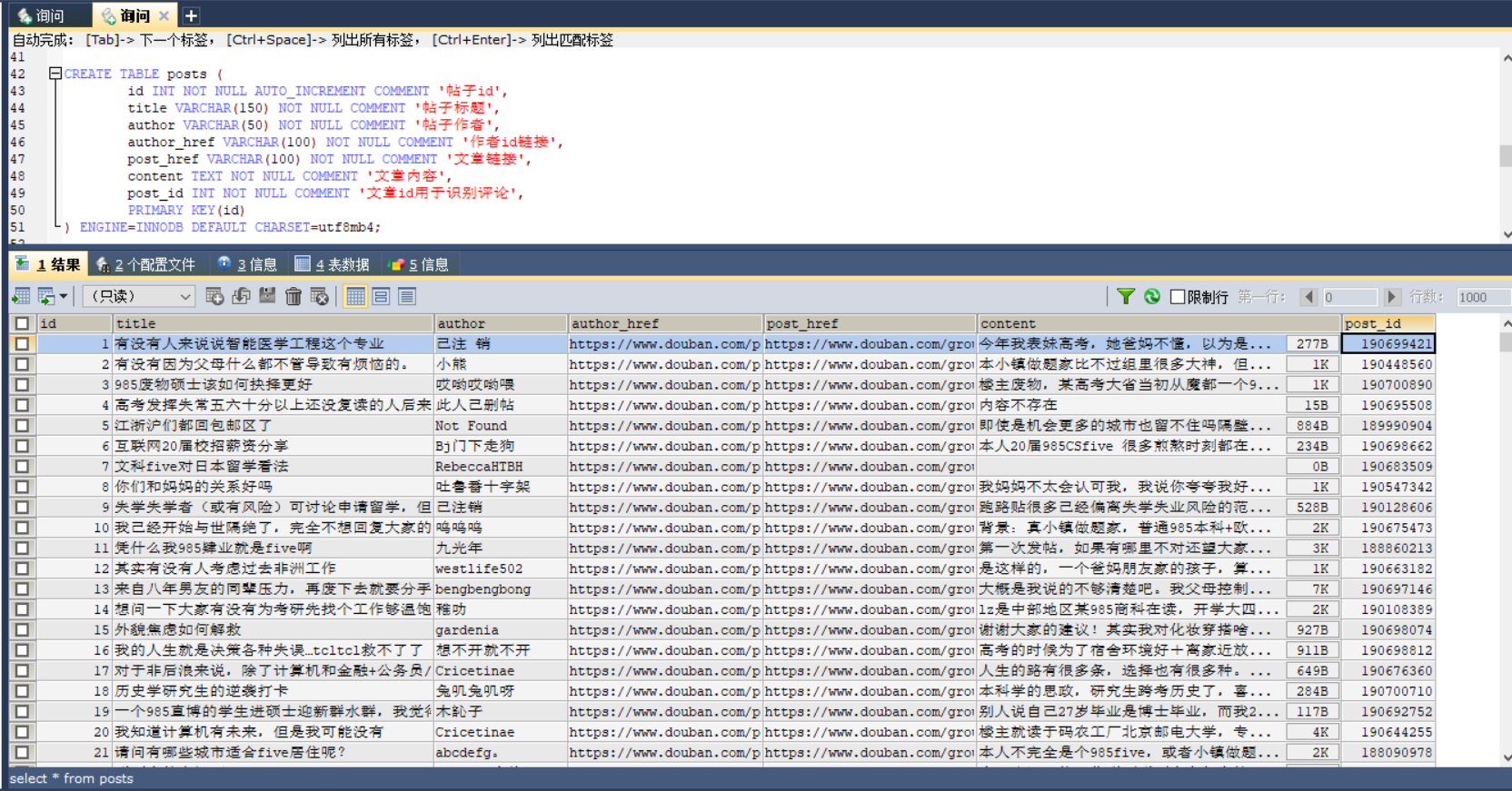
mysql的数据库是之前用Java从豆瓣的小组爬取下来的一个小组的帖子,这里只是去除了主帖的数据。
有一说一,数据有14000多条,大概十几mb的样子,所以jieba执行起来还怪慢的。
运行结果:
数据库: