Python pandas常用操作
1、数据结构
1.1、Series
Series:一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。仅由一组数据也可产生简单的Series对象。
注意:Series中的索引值是可以重复的。
Series创建方法
1.1.1、创建方法
pandas.Series()方法
1.1.2、属性

1.2、DataFrame
DataFrame:一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
DataFrame的每一列都可以看做成一个Series
1.2.1、创建方法
pandas.DataFrame( data, index, columns, dtype, copy)
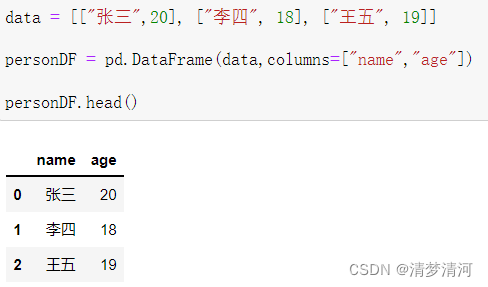
2、取值
2.1、按照列取值
personDF["列名1",..."列名n"]
2.2、按照行索引取值
personDF.loc[[行索引列表],[列索引列表]]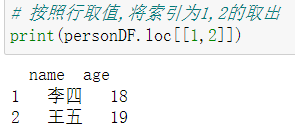
切片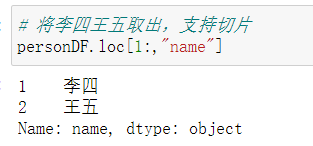
2.3、高级索引
布尔索引
可以传入一个True与False的列表控制是否选择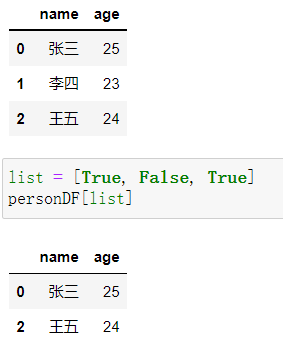

2.4、设置/取消索引

3、操作数据
3.1、删除数据
drop([行列名称], axis=0, inplace=False)
- axis 默认为0,也就是删除行,为1就是删除列
- inplace 默认为False,就是不改变原数据,可以手动指定为True就是改变原数据
删除行
# 删除索引为a和b的行
dataframe.drop(['a','b'])
删除列
frame.drop(['col'], axis = 1)
3.2、排序和排名

3.3、查询数据框信息

3.4、应用函数
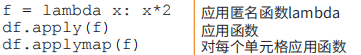
使用匿名函数将age列数值加5,效果如下
3.5、缺失值

去除缺失值
df.dropna()
使用预设值去填充NaN
df.fillna(预设值)
常用平均值填充
df.fillna(df.mean())
3.6、数据去重

drop_duplicates()
参数说明
- subset : column label or sequence of labels, optional
用来指定特定的列,默认所有列 - keep : {‘first’, ‘last’, False}, default ‘first’
删除重复项并保留第一次出现的项 - inplace : boolean, default False
是直接在原来数据上修改还是保留一个副本
3.7、合并数据

pd.merge(left, right, how=‘inner’, on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=(’_x’, ‘_y’), copy=True, indicator=False,
validate=None)
参数说明:
- left: 拼接的左侧DataFrame对象
- right: 拼接的右侧DataFrame对象
- on: 要加入的列或索引级别名称。 必须在左侧和右侧DataFrame对象中找到。 如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
- left_on:左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
- right_on: 左侧DataFrame中的列或索引级别用作键。 可以是列名,索引级名称,也可以是长度等于DataFrame长度的数组。
- left_index: 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 对于具有MultiIndex(分层)的DataFrame,级别数必须与右侧DataFrame中的连接键数相匹配。
- right_index: 与left_index功能相似。
- how: One of ‘left’, ‘right’, ‘outer’, ‘inner’. 默认inner。inner是取交集,outer取并集。比如left:[‘A’,‘B’,‘C’];right[’'A,‘C’,‘D’];inner取交集的话,left中出现的A会和right中出现的买一个A进行匹配拼接,如果没有是B,在right中没有匹配到,则会丢失。'outer’取并集,出现的A会进行一一匹配,没有同时出现的会将缺失的部分添加缺失值。
- sort: 按字典顺序通过连接键对结果DataFrame进行排序。 默认为True,设置为False将在很多情况下显着提高性能。
- suffixes: 用于重叠列的字符串后缀元组。 默认为(‘x’,’ y’)。
- copy: 始终从传递的DataFrame对象复制数据(默认为True),即使不需要重建索引也是如此。
- indicator:将一列添加到名为_merge的输出DataFrame,其中包含有关每行源的信息。 _merge是分类类型,并且对于其合并键仅出现在“左”DataFrame中的观察值,取得值为left_only,对于其合并键仅出现在“右”DataFrame中的观察值为right_only,并且如果在两者中都找到观察点的合并键,则为left_only。
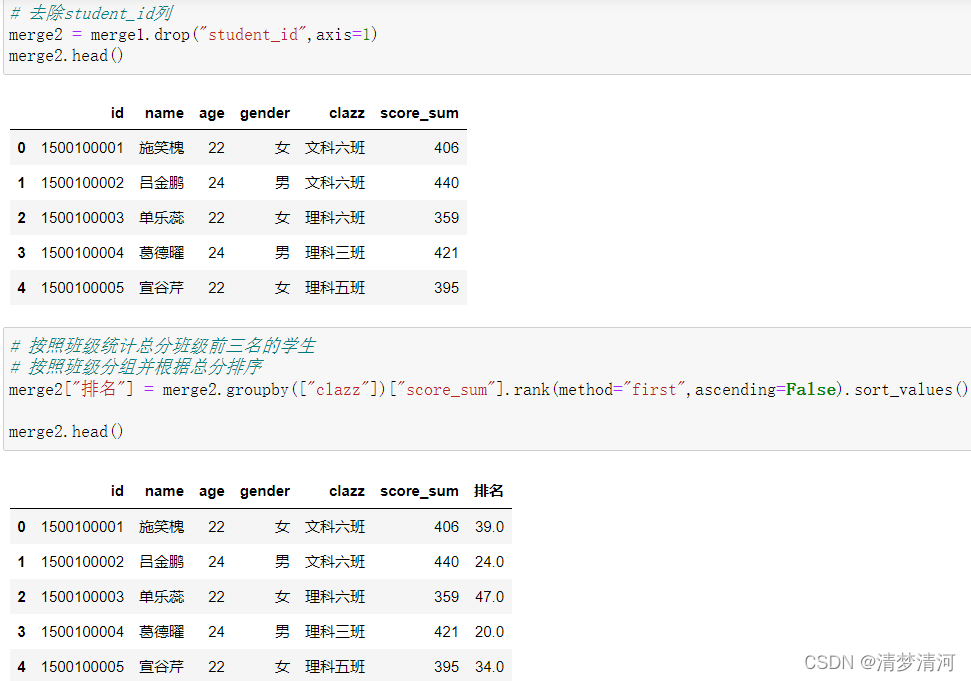
3.8、分组聚合

3.9、添加数据

添加一行数据
ignore_index = True参数默认为False
为False时将不忽略之前的索引,为True时将自动加入新DataFrame的索引