一、DPDK原理
网络设备(路由器、交换机、媒体网关、SBC、PS网关等)需要在瞬间进行大量的报文收发,因此在传统的网络设备上,往往能够看到专门的NP(Network Process)处理器,有的用FPGA,有的用ASIC。这些专用器件通过内置的硬件电路(或通过编程形成的硬件电路)高效转发报文,只有需要对报文进行深度处理的时候才需要CPU干涉。
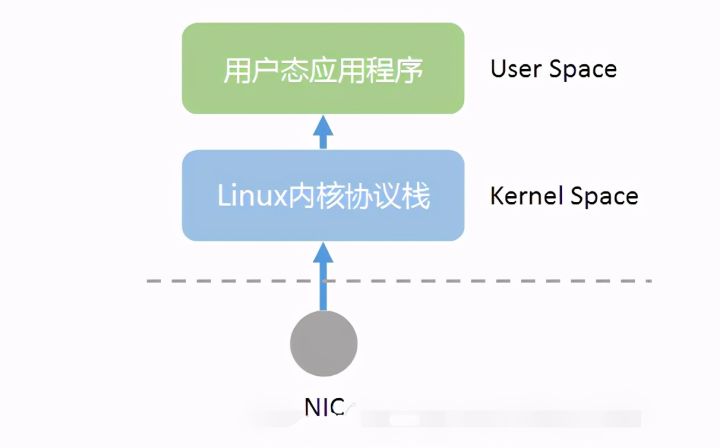
但在公有云、NFV等应用场景下,基础设施以CPU为运算核心,往往不具备专用的NP处理器,操作系统也以通用Linux为主,网络数据包的收发处理路径如下图所示:
在虚拟化环境中,路径则会更长:
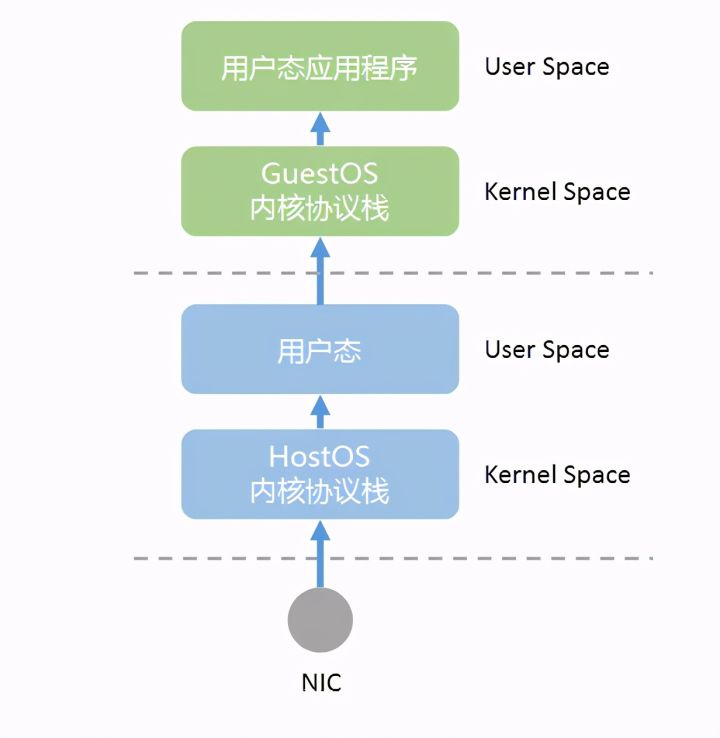
由于包处理任务存在内核态与用户态的切换,以及多次的内存拷贝,系统消耗变大,以CPU为核心的系统存在很大的处理瓶颈。为了提升在通用服务器(COTS)的数据包处理效能,Intel推出了服务于IA(Intel Architecture)系统的DPDK技术。
DPDK是Data Plane Development Kit的缩写。简单说,DPDK应用程序运行在操作系统的User Space,利用自身提供的数据面库进行收发包处理,绕过了Linux内核态协议栈,以提升报文处理效率。
DPDK是一组lib库和工具包的集合。最简单的架构描述如下图所示:

上图蓝色部分是DPDK的主要组件(更全面更权威的DPDK架构可以参考Intel官网),简单解释一下:
PMD:Pool Mode Driver,轮询模式驱动,通过非中断,以及数据帧进出应用缓冲区内存的零拷贝机制,提高发送/接受数据帧的效率
流分类:Flow Classification,为N元组匹配和LPM(最长前缀匹配)提供优化的查找算法
环队列:Ring Queue,针对单个或多个数据包生产者、单个数据包消费者的出入队列提供无锁机制,有效减少系统开销
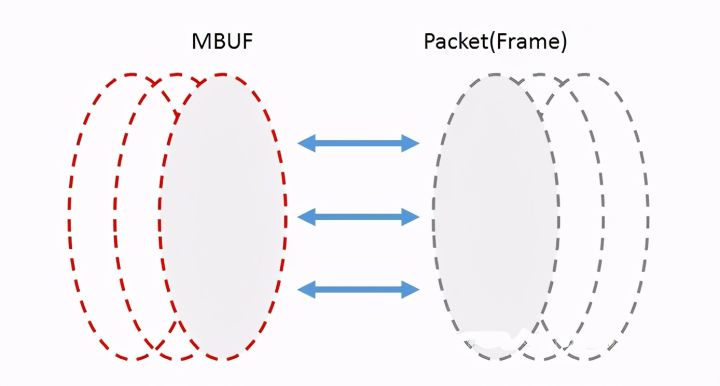
MBUF缓冲区管理:分配内存创建缓冲区,并通过建立MBUF对象,封装实际数据帧,供应用程序使用
EAL:Environment Abstract Layer,环境抽象(适配)层,PMD初始化、CPU内核和DPDK线程配置/绑定、设置HugePage大页内存等系统初始化
这么说可能还有一点点抽象,再总结一下DPDK的核心思想:
用户态模式的PMD驱动,去除中断,避免内核态和用户态内存拷贝,减少系统开销,从而提升I/O吞吐能力
用户态有一个好处,一旦程序崩溃,不至于导致内核完蛋,带来更高的健壮性
HugePage,通过更大的内存页(如1G内存页),减少TLB(Translation Lookaside Buffer,即快表) Miss,Miss对报文转发性能影响很大
多核设备上创建多线程,每个线程绑定到独立的物理核,减少线程调度的开销。同时每个线程对应着独立免锁队列,同样为了降低系统开销
向量指令集,提升CPU流水线效率,降低内存等待开销
下图简单描述了DPDK的多队列和多线程机制:
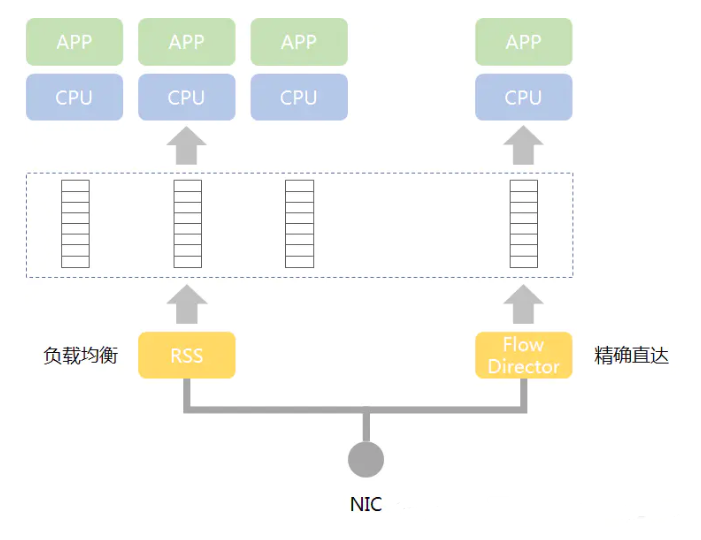
DPDK将网卡接收队列分配给某个CPU核,该队列收到的报文都交给该核上的DPDK线程处理。存在两种方式将数据包发送到接收队列之上:
RSS(Receive Side Scaling,接收方扩展)机制:根据关键字,比如根据UDP的四元组<srcIP><dstIP><srcPort><dstPort>进行哈希
Flow Director机制:可设定根据数据包某些信息进行精确匹配,分配到指定的队列与CPU核
当网络数据包(帧)被网卡接收后,DPDK网卡驱动将其存储在一个高效缓冲区中,并在MBUF缓存中创建MBUF对象与实际网络包相连,对网络包的分析和处理都会基于该MBUF,必要的时候才会访问缓冲区中的实际网络包
以上就是DPDK的基础知识,关于如何在应用程序中使用DPDK,以及系统应该如何针对报文收发的成熟优化方式,后面一边学习与实践,一边记录。
二、DPDK学习路线总结 DPDK学习路线以及视频讲解点击 学习资料 获取
1.dpdk PCI原理与testpmd/l3fwd/skeletion
2.kni数据流程
3.dpdk实现dns
4.dpdk高性能网关实现
5.半虚拟化virtio/vhost的加速