文章目录
1. 软件在大数据方向的应用
Python:机器学习深度学习
java:Hadoop和Flink底层语言支持都是基于java
Scala:Spark框架
2. 大数据方向应用:
- 新基建和数字化转型助力大数据行业升级
- 欧美国家经过数字化转型,制造业成本减少20%-30%左右,营收增加20%-30%左右。物流成本降低30%,营收增加30%等等。
- 从传统物流到智慧物流的转变,通过手机物流数据,利用物流数据的手段普及到整个零售行业。
3. 大数据的应用流程
- 数据如何采集
- 数据如何储存
- 数据如何ETL(数据清洗)
- 数据分析——得到统计指标
- 数据挖掘——对已有的数据进行价值化的提取
- 数据报表展示——业务或数据的决策
例子:物流项目:
- 采集:仓储,物流管理系统、用户下单层面
- 存储:HDFS,HBase
- 数据清洗:缺失值,异常值
- 数据分析:统计各种指标
- 数据建模:通过机器学习模型达到预测,AI+大数据为物流行业赋能
- 数据报表展示:基于业务决策——物流智能选址
4. 传统数据分析的痛点:
当前数据类型包括以下三种:
- 半结构化:JSON,Xml
- 非结构化:视频、音频
- 结构化:Mysql
传统数据分析在应用过程中有以下痛点
Mysql+Oracle:无法解决非结构化数据,数据量增大如何处理
python数据分析
优势:Python生态中数据科学库完整,并有支持深度学习机器学习的库
劣势:Python生态数据分析框架,例如pandas,多数是基于单机版数据分析,对于分布式数据支持需要引入大数据框架,无法解决
传统数据分析瓶颈:当数据达到一定量级,传统数据库做的是纵向扩展,所以瓶颈是存在的。(当数据量超出存储能力时候,我们只能纵向增加内存,瓶颈永远存在)
大数据分析的优势
不同于传统的数据分析,大数据是通过廉价的PC机通过网络连接在一起,构建分布式的计算和分布式的存储。
大数据分析的特点有:
- 数据量大:GB-TB-ZB之间差别1024倍,数据呈现指数级别增长
- 数据种类多:结构化、半结构化和非结构化
- 速度快:
- 第一代计算引擎MR
- 第二代计算引擎Hive
- 第三代计算引擎Impala和Spark
- 第四代计算引擎Flink(阿里参与建设)
- Hive和Spark离线数据分析,而Flink是做实时数据分析的
- 价值密度低:在大数据基础上如何对数据进行价值化提取(全量级数据呈现指数增长,有价值数据呈现部分增长)有价值数据在总数据中比例低,所以我们需要机器学习算法对数据进行价值提取。
5. 大数据的应用流程与生态圈
数据如何采集
- Flume+Sqoop+Canal+DataX
数据如何储存
- HDFS+Hbase
数据如何ETL(数据清洗)
MapReduce
Spark
Flink
kylin
Impala
数据分析——得到统计指标
MapReduce
Spark
Flink
kylin
Impala
数据挖掘——对已有的数据进行价值化的提取
SparkMI
SparkMlib
Alink
数据报表展示——业务或数据的决策
BI
Apache SuperSet
6. 大数据技术框架应用
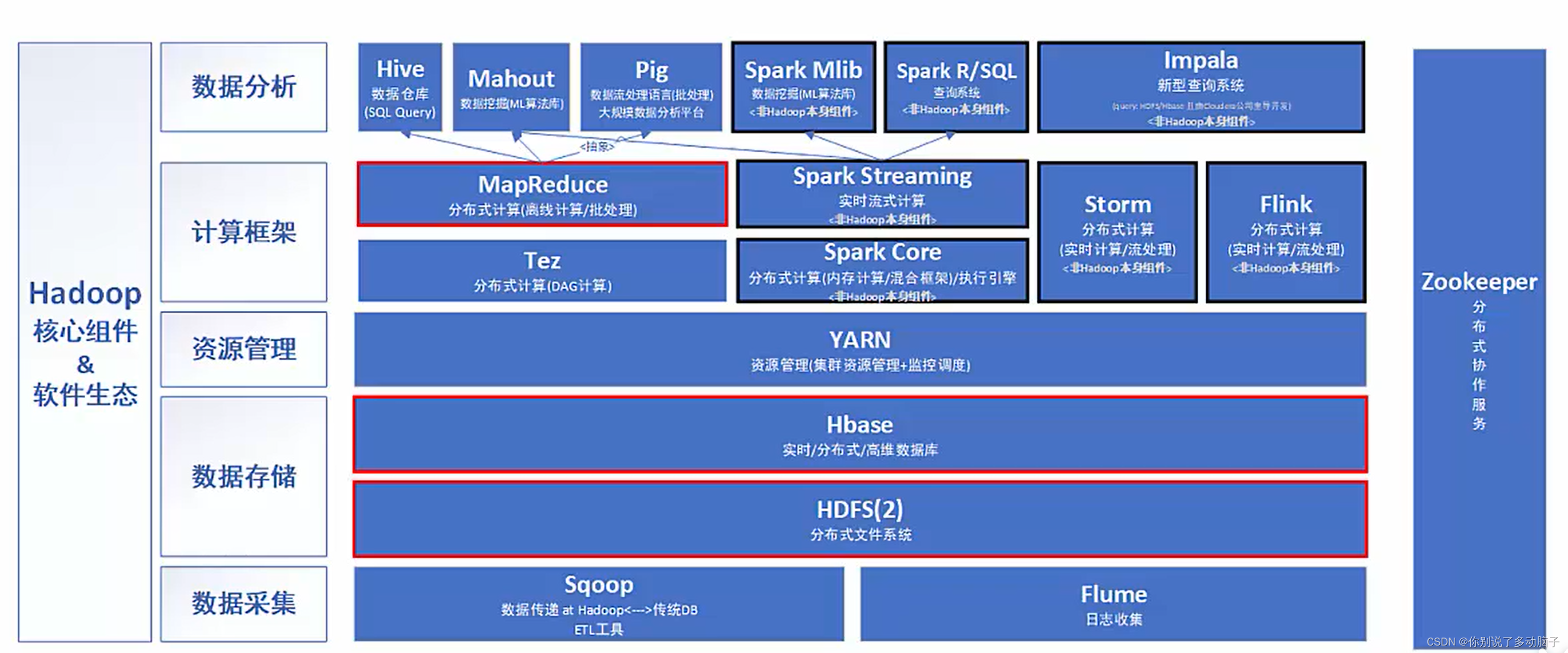
7. Flink框架应用
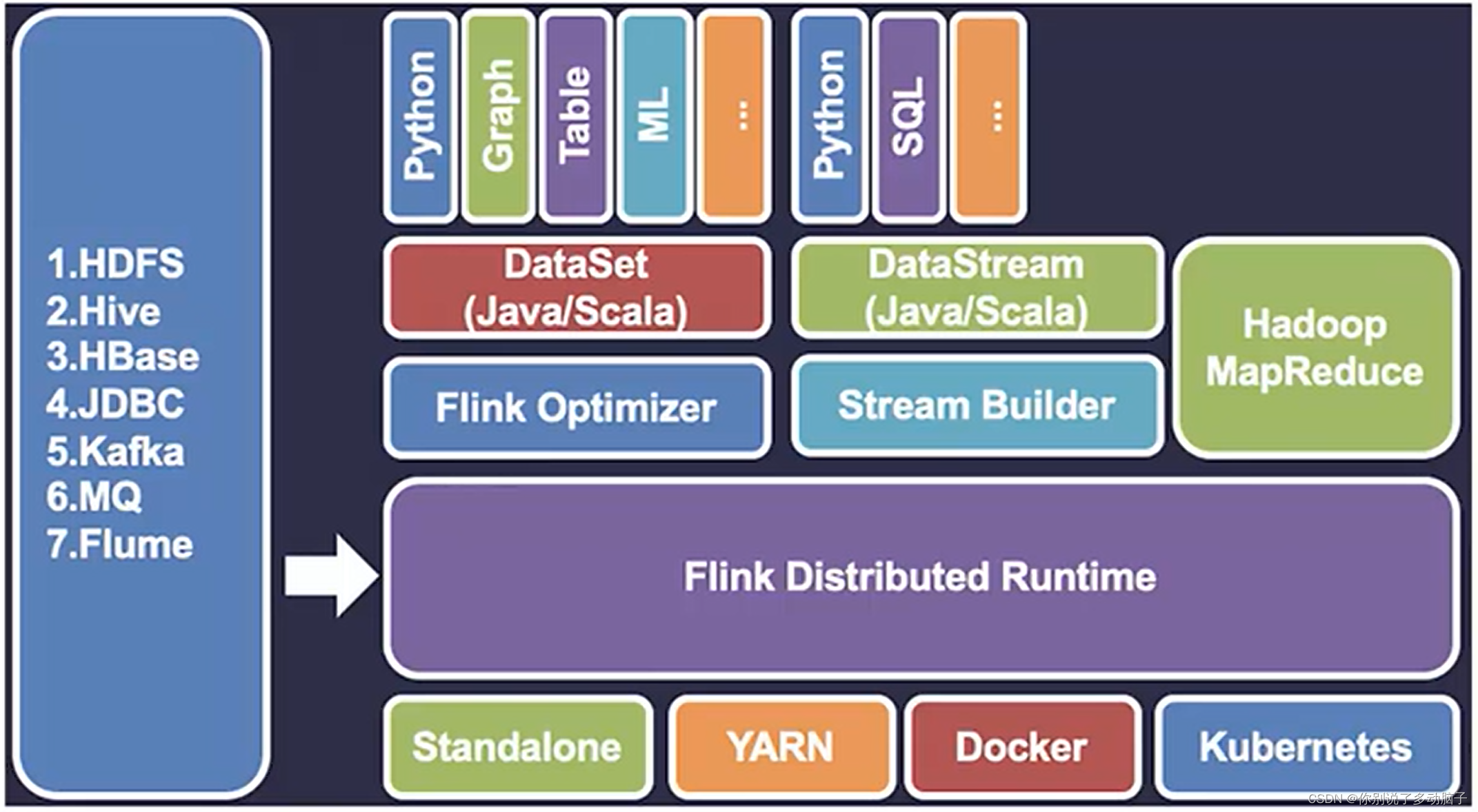
Apache Flink是一个用于分布式流和批处理数据处理的开源平台。Flink的核心是流数据流引擎,为数据流上的分布式计算提供数据分发、通信和容错。Flink在流引擎之上构建批处理,覆盖本机迭代支持,托管内存和程序优化。Flink核心思想与SparkStreaming类似,针对数据集的微批处理框架,在相对不高的延迟下(秒级)完成批量数据的近实时处理。
阿里巴巴16年,以9000w欧元的价格收购了在柏林的一家开源的流计算引擎的创业公司,从此开启Flink高速发展之路。19年,阿里内部的blink合入flink1.9版本中。
特性:
- 收集数据,按照时间进行微批数据的切分,并进行分布式处理,数据处理吞吐量大;
- 由于针对批次数据加工,相对延迟高于Storm,且无法完成实时事务性处理(例:银行即时转账等业务)。
Flink 官方文档:https://flink.apache.org/
8. Pyflink
将Flink的分布式能力赋予python,将python丰富的数据分析库,应用于Flink
为什么Spark和Flink等组件都纷纷支持Python语言?
- 当前有大量的Python语言流行度和Python的开发者
- Python在数据挖掘和机器学习方面常使用的语言
- 能够基于使用PySpark及PyFlink完成的对应数据分析和挖掘的项目任务
- Python+大数据组合(解决业务中还得重新学习Spark或Flink框架的问题)
- 通过Python结合Matplotlib完成数据的EDA(数据探索性分析),同时我们可以通过Pyhon和Spark的结合PySpark完成SparkSql大数据分析和SparkMllib的大数据挖掘。
如何能够借助Python语言和大数据框架完成建模
借助Python的Django和Flask完成Web任务,通过Python的Scrapy完成数据爬虫工作
亦可通过Python的Numpy、Pandas和Matplotlib数据科学库完成数据分析任务
但当数据量增加内存无法加载大量数据计算的时候,可能需要Python和大数据框架的结合处理、分析和对数据进行建模
PySpark的SparkSql完成分布式计算任务,使用Python操作SparkMllib完成数据挖掘和机器学习任务
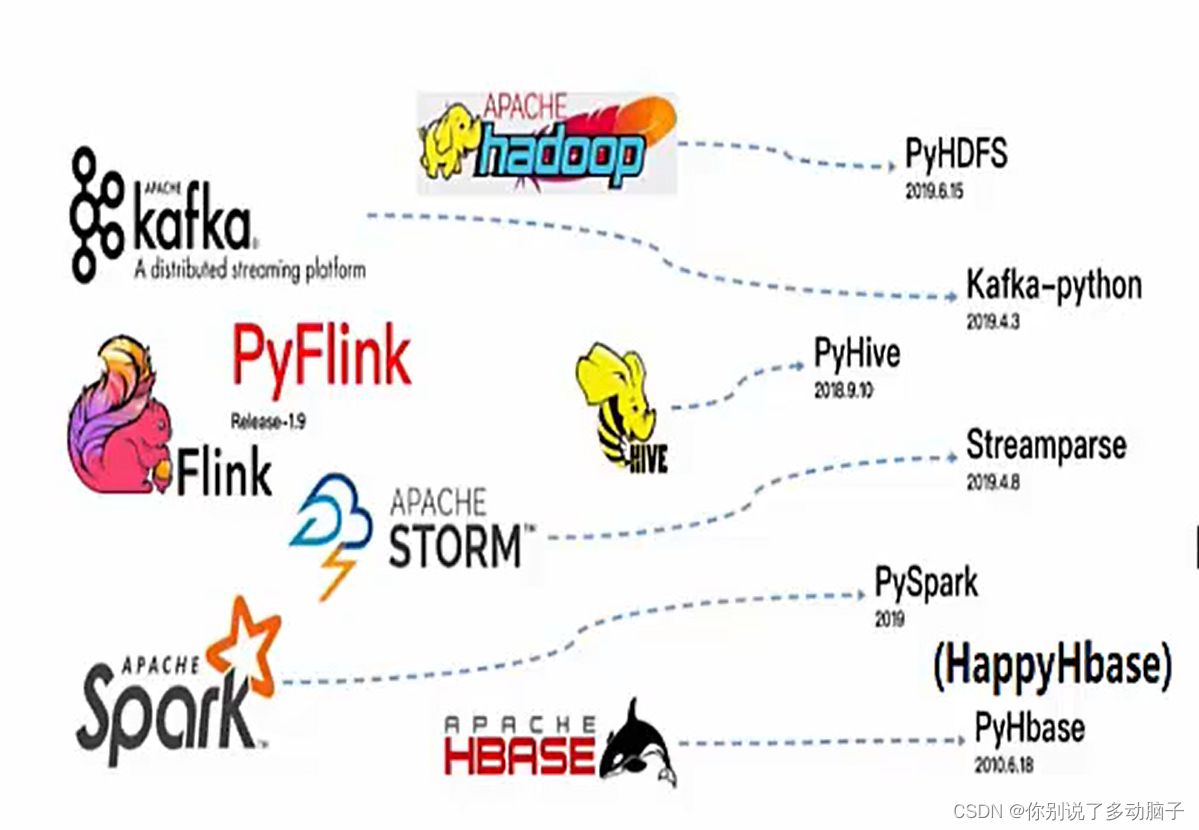
Python如何支持Flink:
Flink要做到,批处理(处理批量数据)和流处理(处理实时数据)的统一
DataStream API支持流计算;DataSet API支持批计算
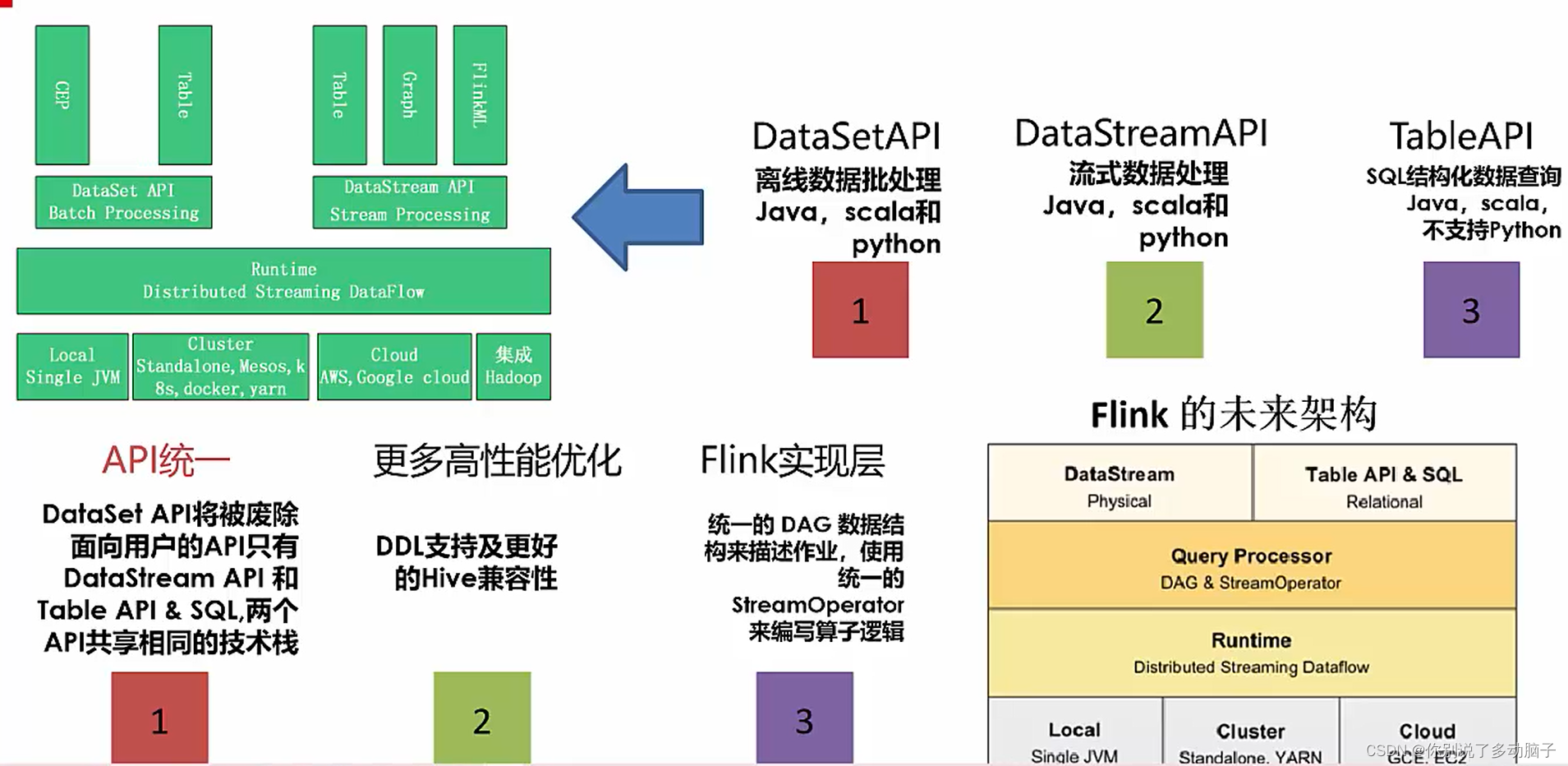
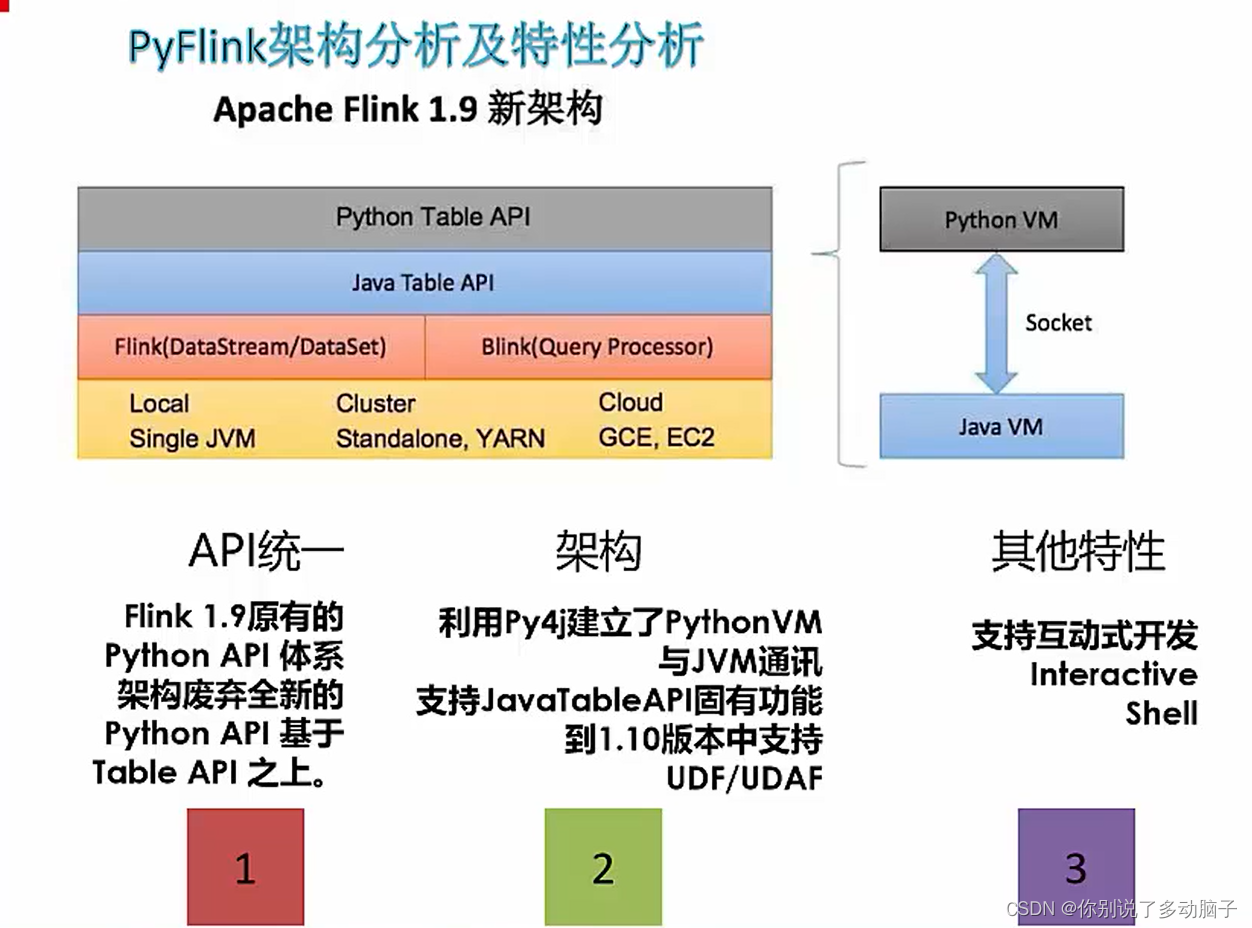
- 1.9版本之后的PyFlink将PyFlink部署到PyPi上可以直接安装:
pip install apache-Flink
9. 搭建大数据Python知识体系
- 大数据技能
- java
- mysql,Oracle
- hadoop
- Nosql存储
- Flink技术栈
- Spark技术栈
- Python大数据分析技能
- 机器学习
- SparkML
- FlinkML
- PySpark——PyFlink分布式计算核心技能
- PySpark
- PyHive
- Kafka-Python
- PyFlink案例实战