首先,问题已解决,重新梳理思路,侧重阐述整个过程、问题解决方案。
前言
在业务划分+技术迭代的背景下,需要重新进行日志收集,即服务日志存储到hdfs。
一、流程图
基于下图可知,此次迭代的变更点,主要是kafka的消息生产。
升级Kubernetes容器,主要原因:极致弹性的资源扩缩。
主要执行步骤如下:
- 申请kafka、增加topic
- 申请sls
- 申请logstash、安装插件
- t-streaming平台部署脚本
- 网络加白
a. sls 与 logstash
b. logstash 与 kafka
c. kafka 与 t-streaming平台
d. kubernetes 与 sls(阿里云默认联通)
二、报错信息
java.nio.channels.ClosedChannelException
Traceback (most recent call last):
File "gauss_demo.py", line 41, in <module>
start()
File "gauss_demo.py", line 32, in start
kafkaParams={"metadata.broker.list": broker, "group.id": group_id})
File "/software/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/spark/python/lib/pyspark.zip/pyspark/streaming/kafka.py", line 130, in createDirectStream
File "/software/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__
File "/software/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/spark/python/lib/py4j-0.10.7-src.zip/py4j/protocol.py", line 328, in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o71.createDirectStreamWithoutMessageHandler.
: org.apache.spark.SparkException: java.nio.channels.ClosedChannelException
java.nio.channels.ClosedChannelException
java.nio.channels.ClosedChannelException
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$checkErrors$1.apply(KafkaCluster.scala:366)
at org.apache.spark.streaming.kafka.KafkaCluster$$anonfun$checkErrors$1.apply(KafkaCluster.scala:366)
at scala.util.Either.fold(Either.scala:97)
at org.apache.spark.streaming.kafka.KafkaCluster$.checkErrors(KafkaCluster.scala:365)
at org.apache.spark.streaming.kafka.KafkaUtils$.getFromOffsets(KafkaUtils.scala:222)
at org.apache.spark.streaming.kafka.KafkaUtilsPythonHelper.createDirectStream(KafkaUtils.scala:720)
at org.apache.spark.streaming.kafka.KafkaUtilsPythonHelper.createDirectStreamWithoutMessageHandler(KafkaUtils.scala:688)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
三、排查思路
整体排查思路,包括kafka、生产者、消费者
- kafka
1)网络是否打通
logstash 与 kafka
kafka 与 t-streaming平台
2)topic是否创建,是否正常服务
3)group是否创建,是否正常服务(0.10.x版kafka,不支持自动创建group,需手动创建) - 生产者
1)网络是否打通
sls 与 logstash
logstash 与 kafka
2)Kubernetes容器
插件是否缺失(logtail)
配置是否有误(logstore、日志路径)
3)Logstash数据采集
插件是否缺失(input、filter、output)
配置是否有误(input、filter、output) - 消费者
1)网络是否打通
kafka 与 t-streaming平台(网段、端口)
2)实时消费脚本
配置是否有误(broker、topic、group)
脚本是否有误
kafka与jar包版本是否兼容
3)offset是否设置
若不设置,默认从最新的offset读取消费,可能无数据支持消费
若新消费者,建议设置为smallest (earliest),任务从最开始的offset读取消费,相当于重播所有数据
总言之,消费任务启动后,需确保有消息可消费
四、逐步排除修复
作为消费端,个人按照kafka、消费者、生产者顺序排查(角度不同,顺序不同哈)
4.1 topic、group是否已创建
1⃣️ 查阅kafka版本、topic数量、group数量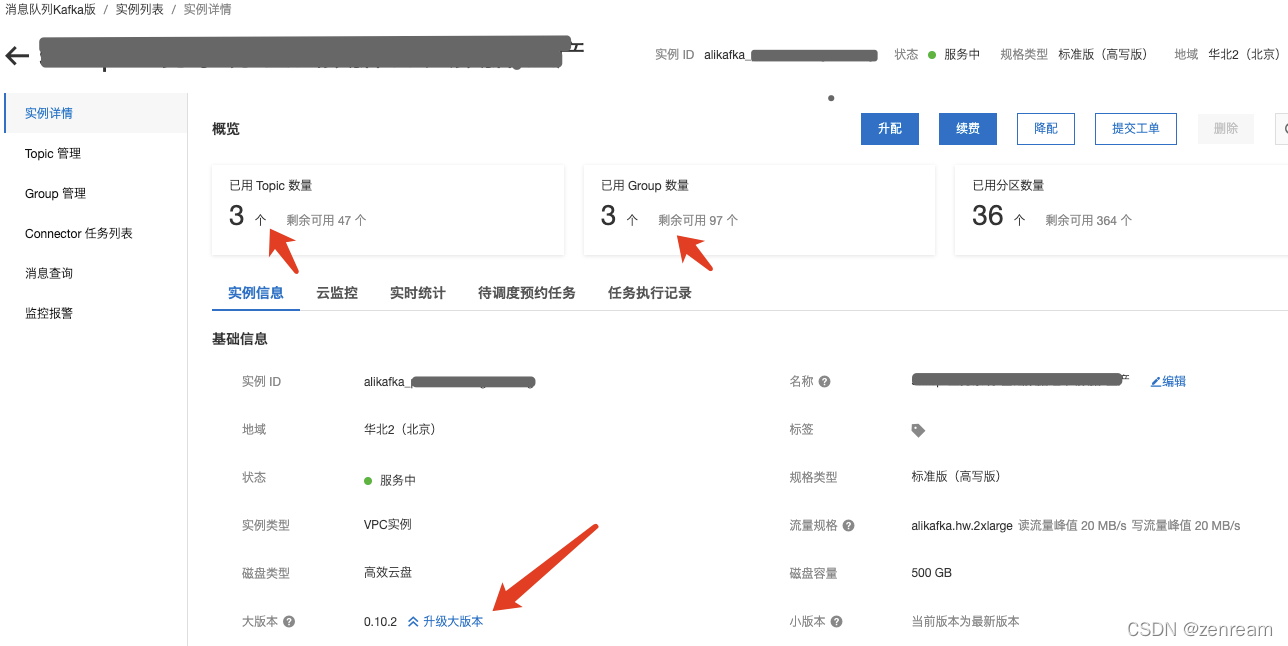
注:kafka大版本2.2.0支持自动创建group,0.10.2版本需要手动创建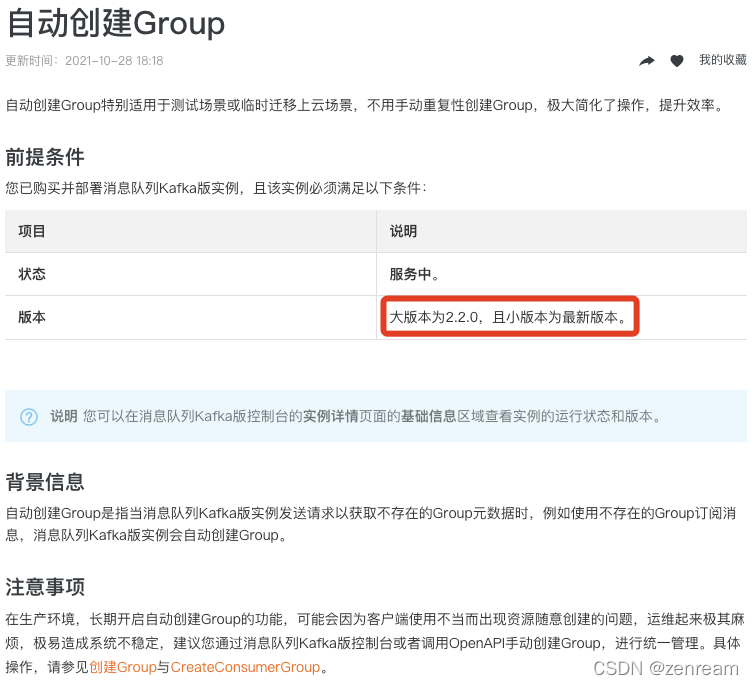
结果:topic已创建,group未创建(0.10.2版kafka,不支持自动创建group,需手动创建),已修复
4.2 kafka与t-streaming网络是否打通
1)网段
1⃣️ 查阅kafka接入点白名单,确定hadoop集群网段已加白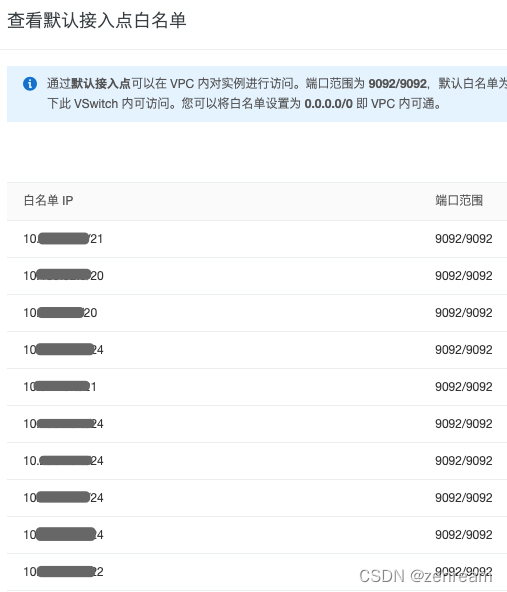
2⃣️ 在提交机,使用ping、telnet命令检测网络联通性
ping ip,检查网络是否通畅或者网络连接速度的命令
telnet ip port,探测指定ip是否开放指定端口
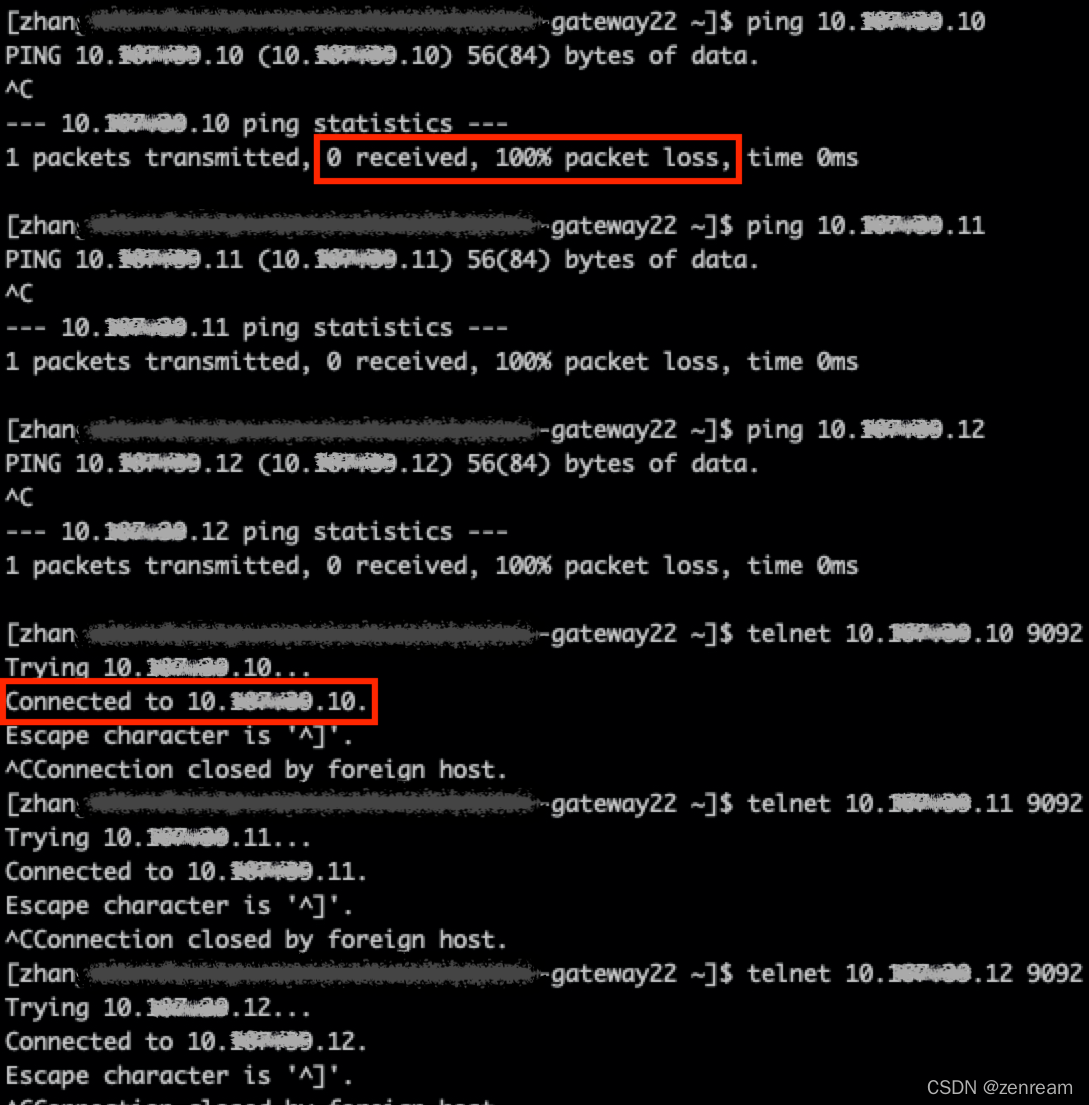
结果:hadoop集群网段已接入kafka白名单,在提交机检测kafka网络联通性,ping不通,telnet通
2)端口
1⃣ 消费过程中,使用socket测试tcp连通性
查看application日志,socket探测时返回False,即网络不通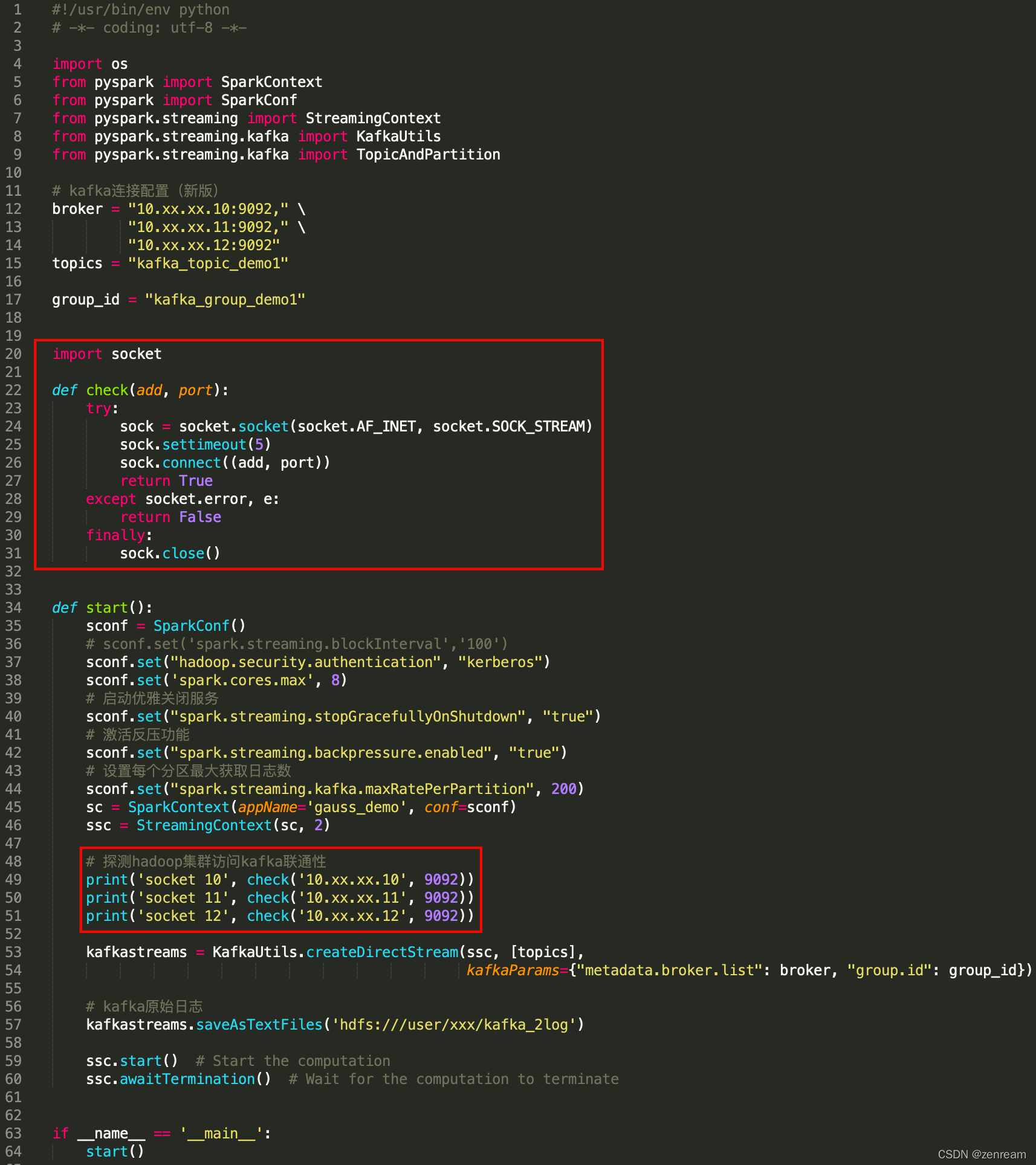
2⃣ 在提交机telnet通,application日志反映网络不通,为什么???用spark yarn提交流程解释
– 实质:spark 会提交任务到hadoop集群,需要保障hadoop集群机器到kafka实例网络联通
– 原因:kafka在阿里云,hadoop集群在机房,机房与阿里云交互,需走专线,在专线两端做路由配置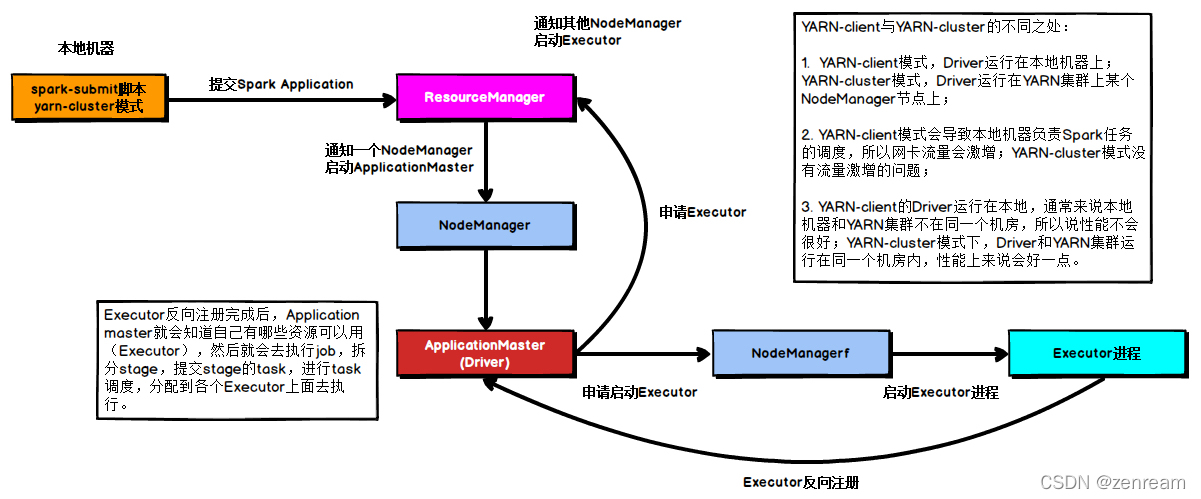
3⃣ 添加路由策略后,再次执行1⃣,使用socket测试tcp连通性,application日志返回True,即网络已畅通
结果:hadoop集群未对kafka端口放行,已修复
4.3 消费代码是否有误(可跳过)
copy线上伪代码
1⃣ gauss_demo.py(spark streaming消费kafka存储至hdfs) 2⃣ gauss_demo.sh(spark-submit执行脚本)
2⃣ gauss_demo.sh(spark-submit执行脚本) 3⃣ spark-streaming-kafka-0-8-assembly_2.11-2.1.0.jar
3⃣ spark-streaming-kafka-0-8-assembly_2.11-2.1.0.jar
4⃣ 替换gauss_demo.py的kafka配置参数,确认可成功消费
结果:自查代码无误 + 旧版kafka校验,确认消费代码无误
4.4 未指定offset
1⃣ 核查hdfs文件,发现文件内容为空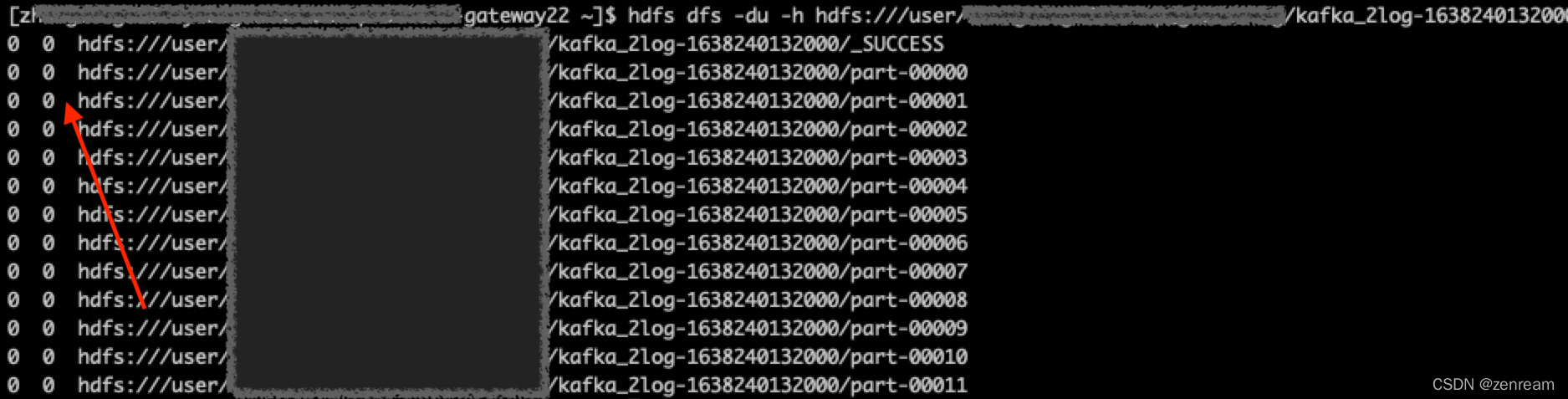
2⃣ 查阅阿里云kafka云监控页面
– topic无订阅关系,有服务器消息总量 – topic近一小时,未生产消息
– topic近一小时,未生产消息 – topic有消费者消费流量
– topic有消费者消费流量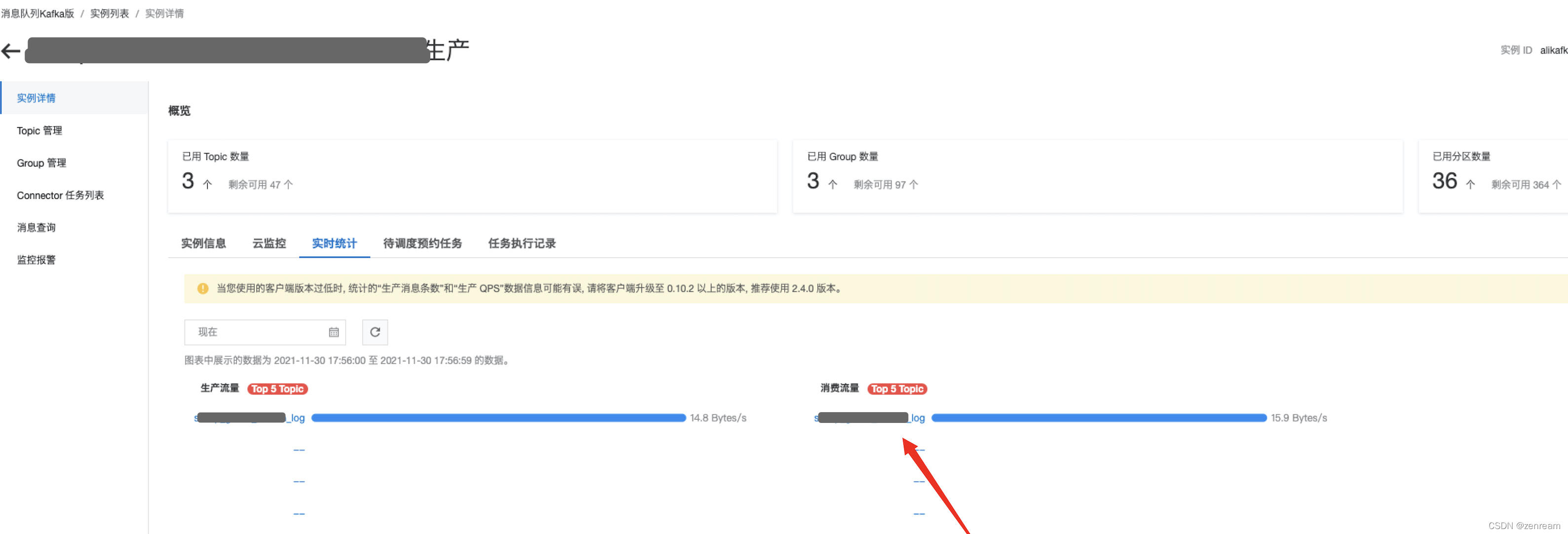
3⃣ 猜测:消费不到消息是由于任务启动后没有生产消息,或消费者未指定offset
4⃣ 方案佐证:生产者实时批量生产消息,消费者实时消费当前消息(或者消费策略offset使earliest),监控流量波动正常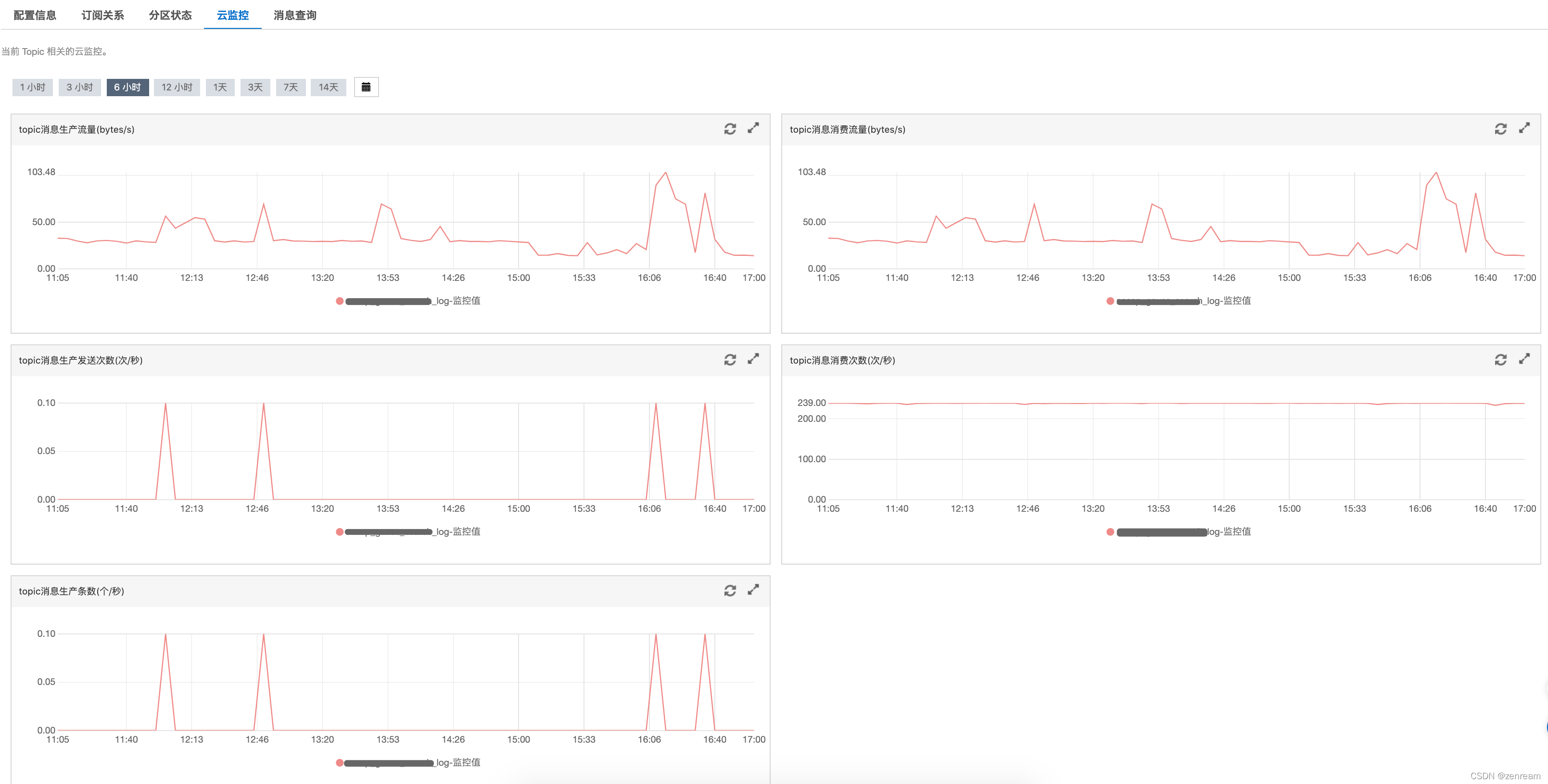
结果:消费不到数据是由于任务启动后没有生产消息,未设置消费offset,已修复
4.5 kafka与jar包版本是否兼容
1⃣ 查阅kafka实例版本 – 使用spark-streaming-kafka-0-8,kafka应选择0.8.2.1 or higher(spark官网给出了版本选择要求:sparkstreaming+kafka版本选择)
– 使用spark-streaming-kafka-0-8,kafka应选择0.8.2.1 or higher(spark官网给出了版本选择要求:sparkstreaming+kafka版本选择)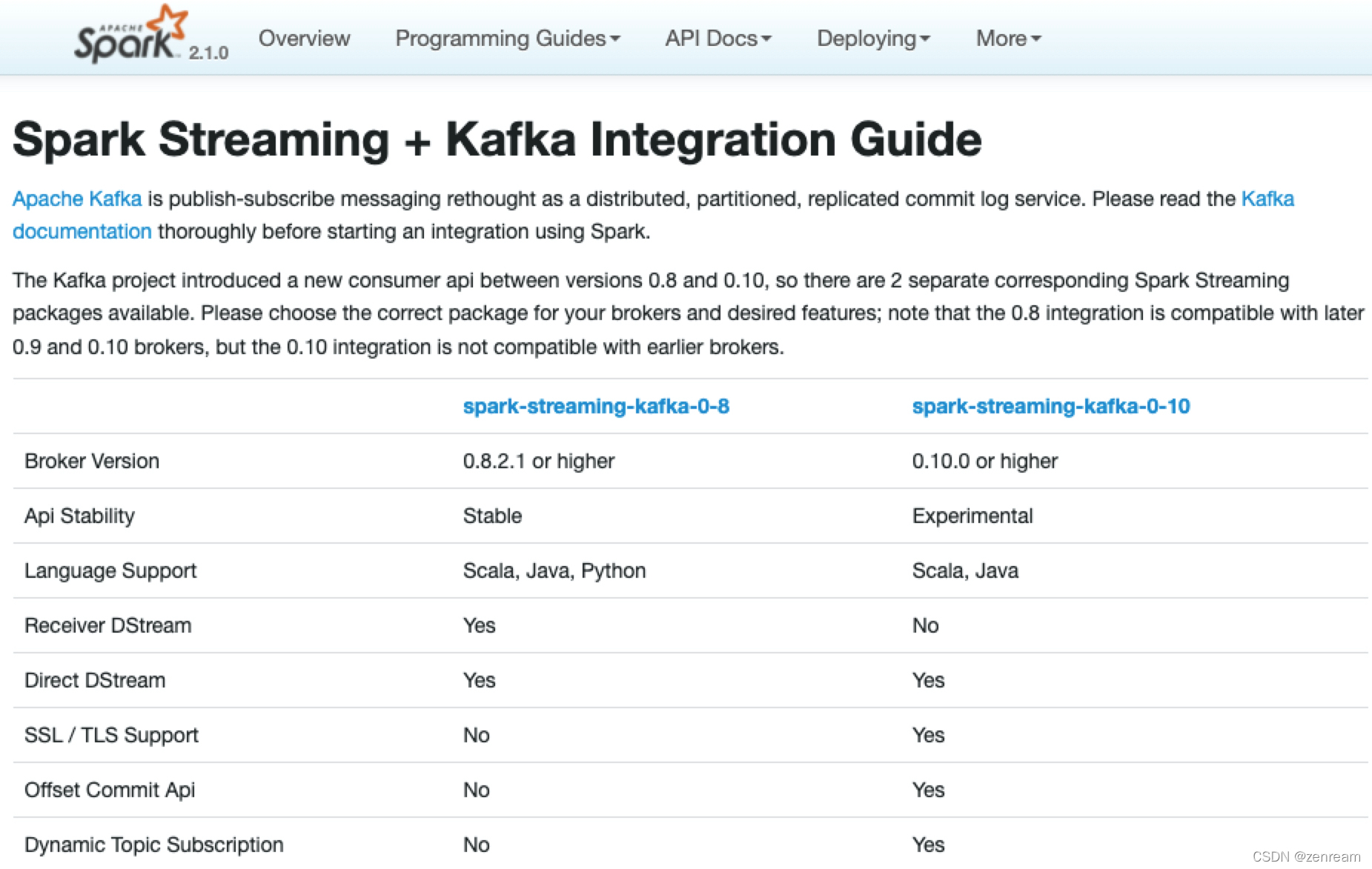
2⃣ 为避免未知异常,决定降低kafka版本,与线上kafka保持一致,新建0.10.2版本kafka
结果:kafka与spark-streaming-kafka的jar包版本兼容
4.6 生产者是否推送数据到kafka
1⃣ 查阅阿里云kafka云监控页面
打开方式:阿里云 - 消息队列kafka版 - 实例列表 - topic管理 - topic详情
– 发现订阅关系,没有数据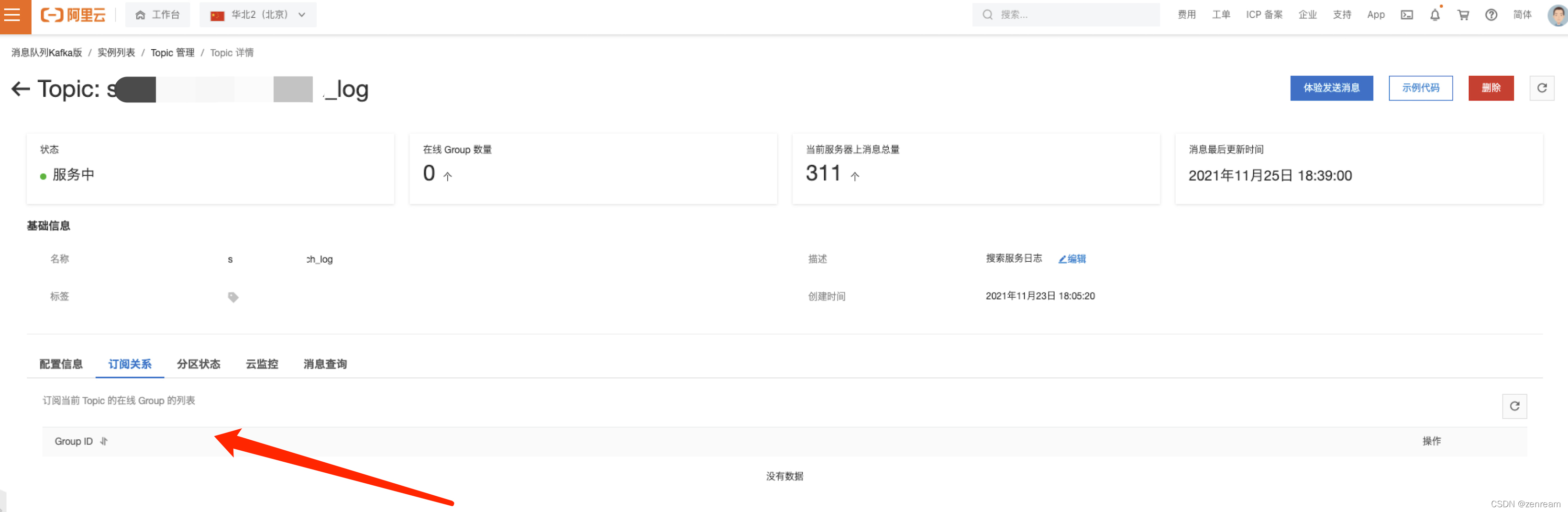
– topic消息生产流量、topic消息生产发送次数、topic消息生产条数均为0,无任何波动起伏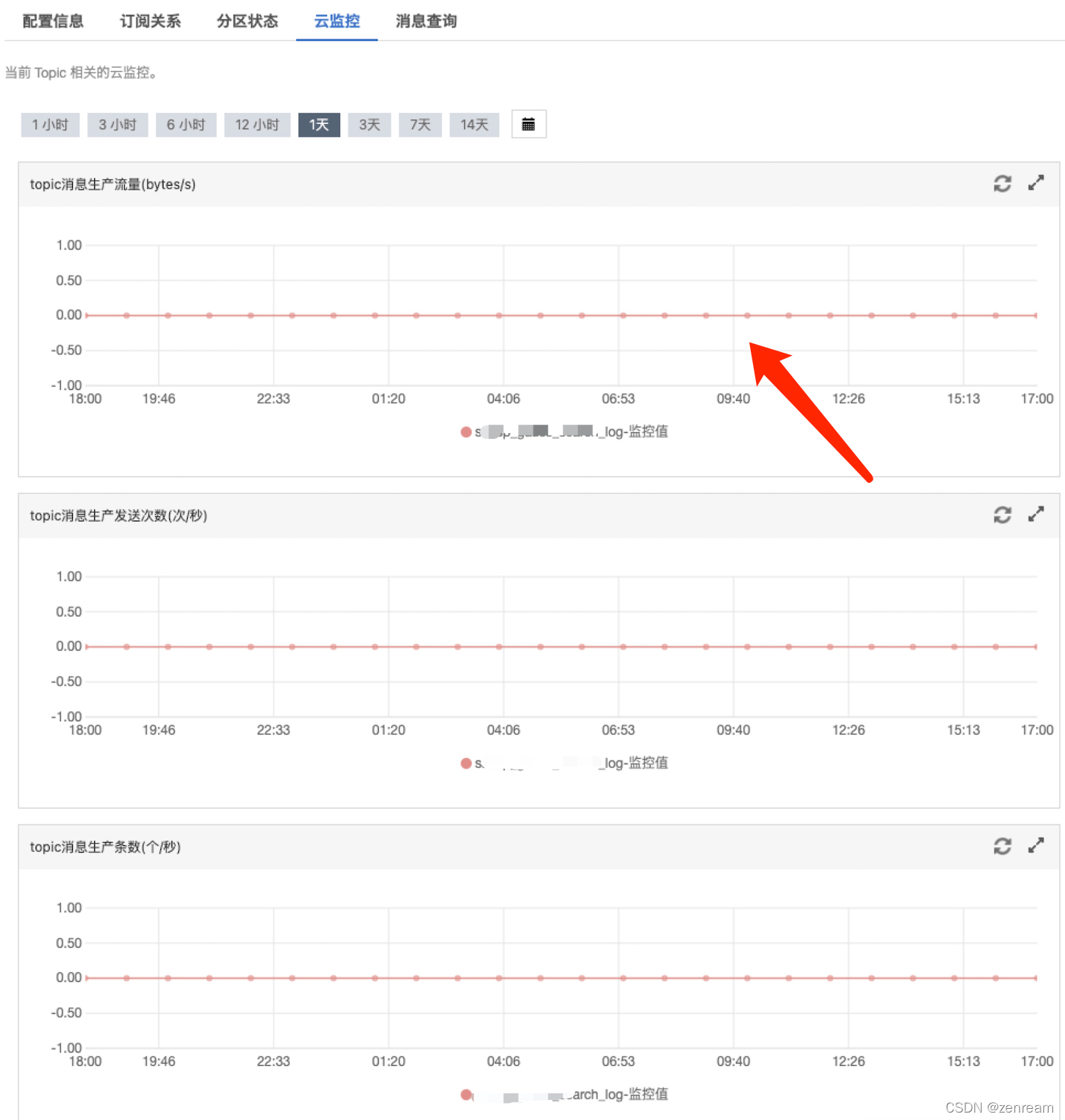
2⃣ 查阅阿里云SLS日志服务
– SLS日志服务采集Kubernetes容器日志,正常采集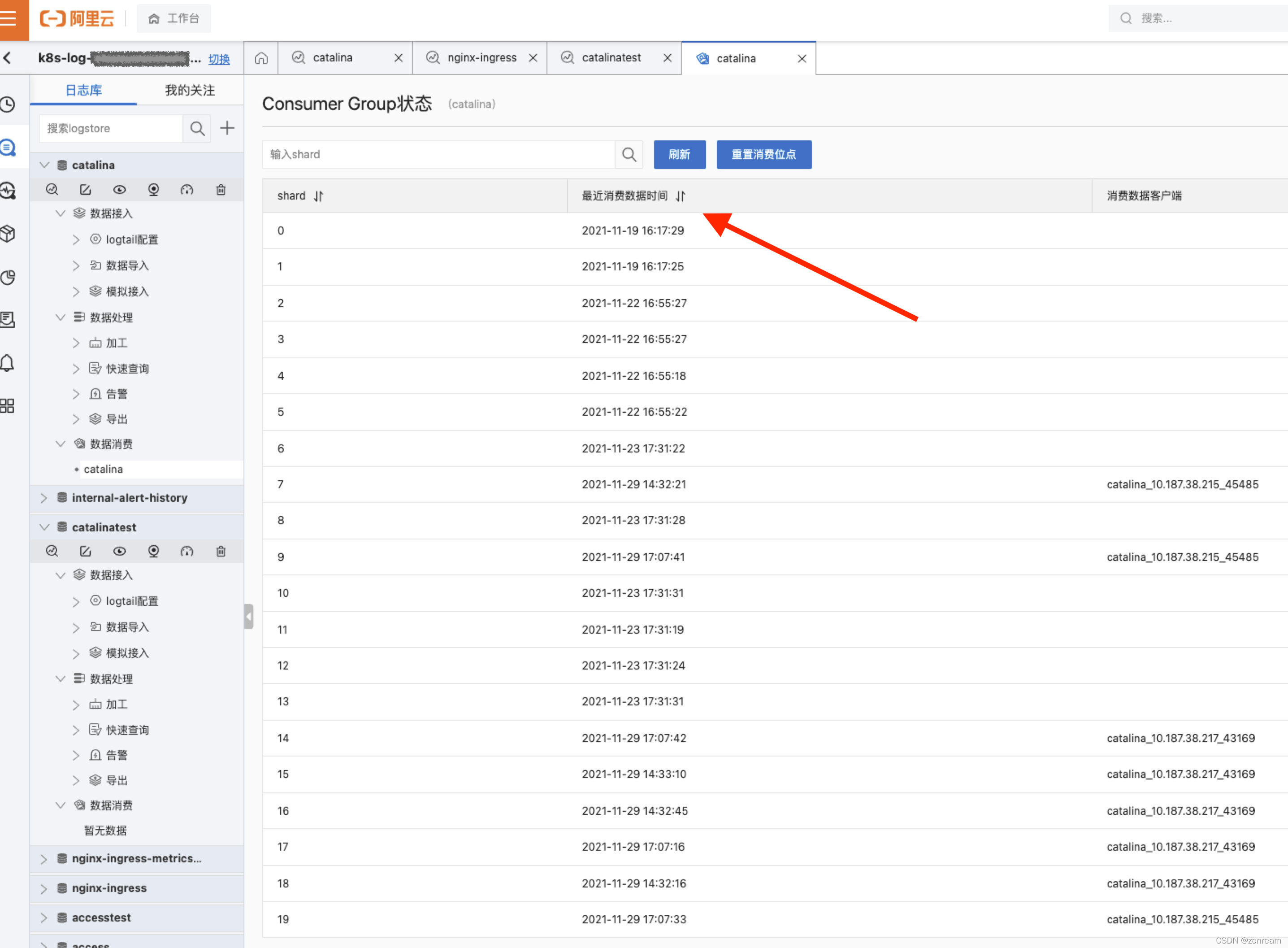
3⃣ 查阅Logstash
通过配置日志服务的Input插件对接Logstash,获取日志服务中的日志数据,并写入到Kafka中(阿里云官网:Logstash消费)
– 核对Logstash管道配置,确认无误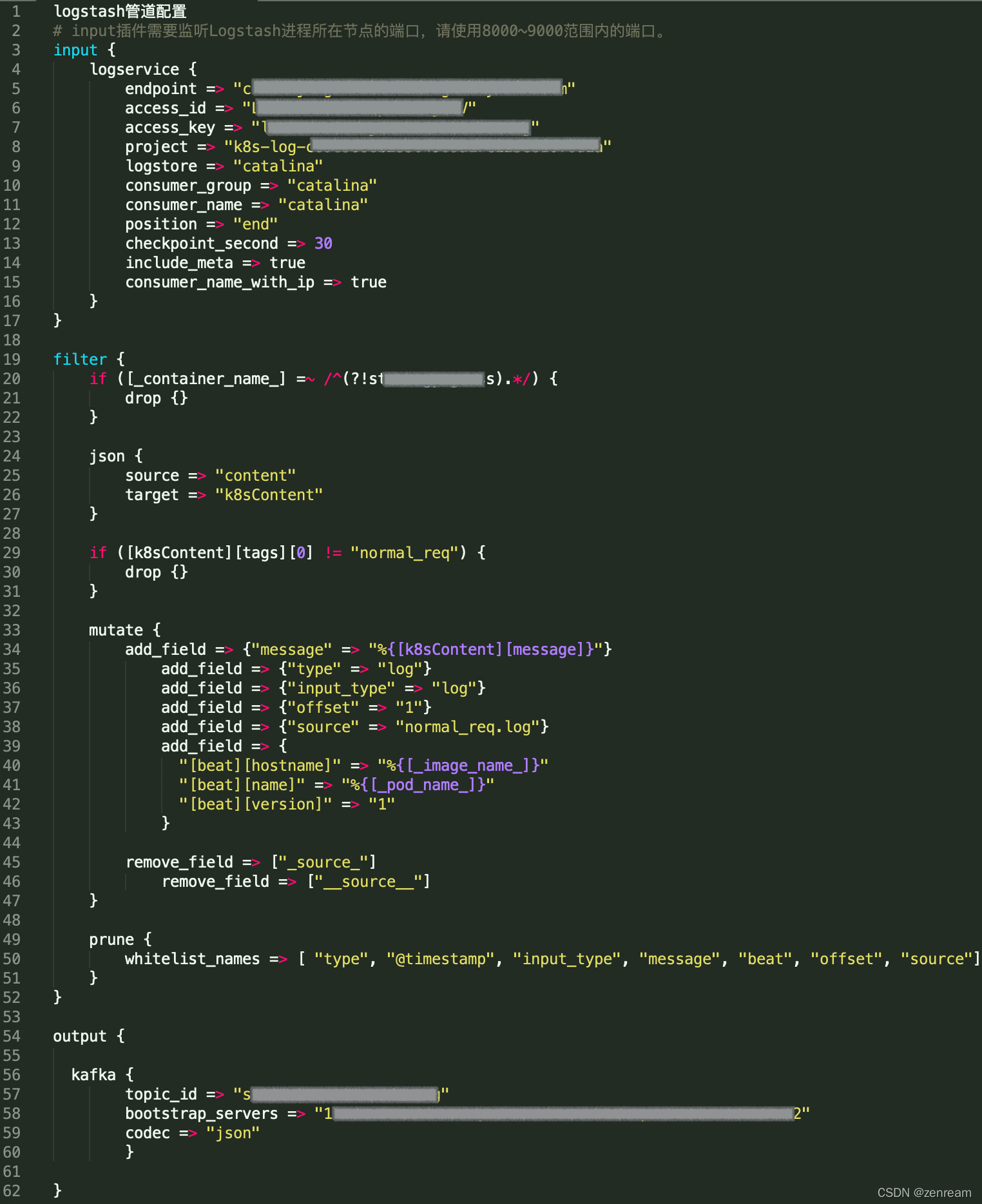
– 核对Logstash插件配置,未安装logstash-input-sls、logstash-filter-prune插件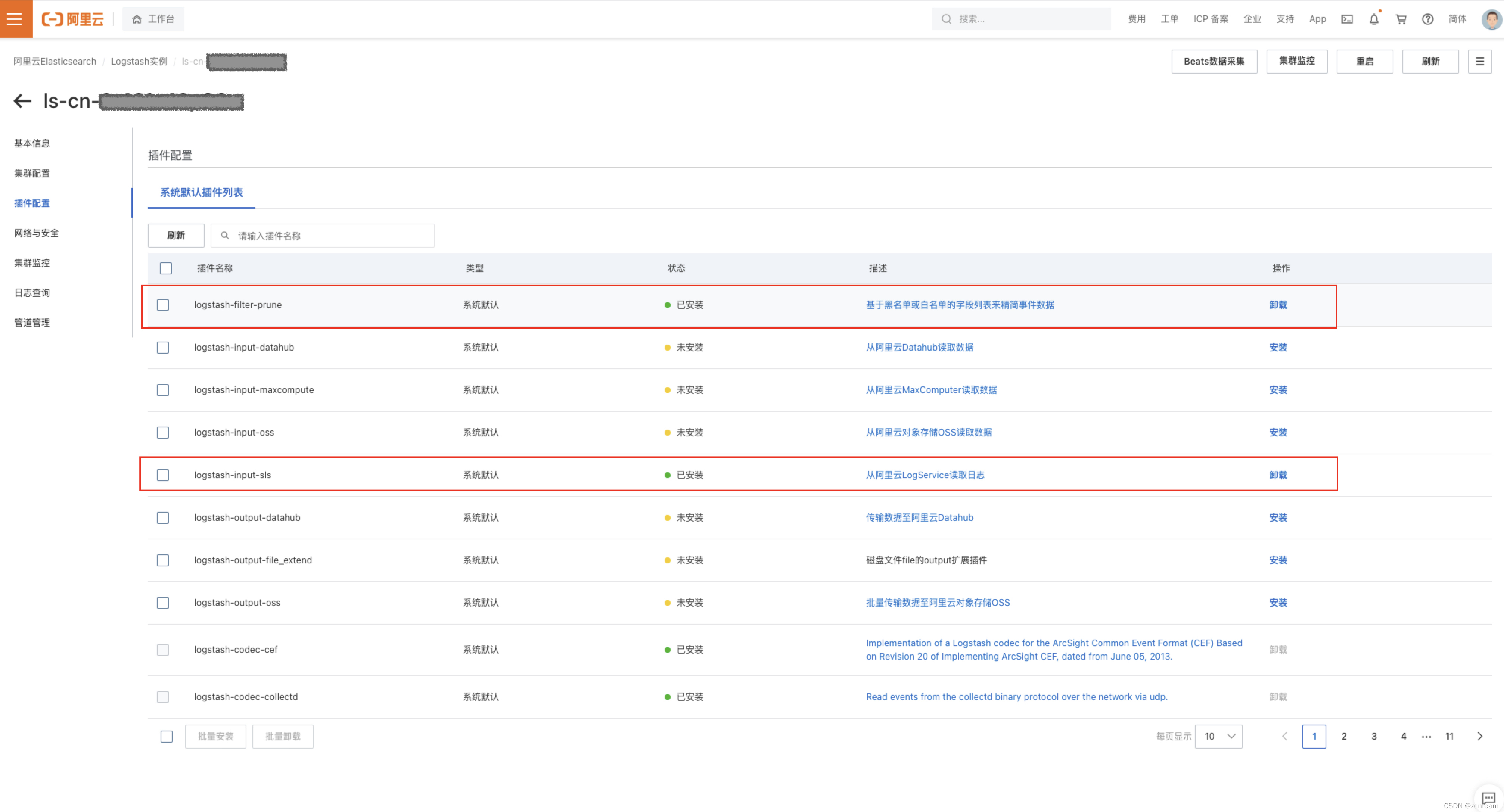
– 安装缺少的logstash插件,监控消息生产流量,确定成功推送数据到kafka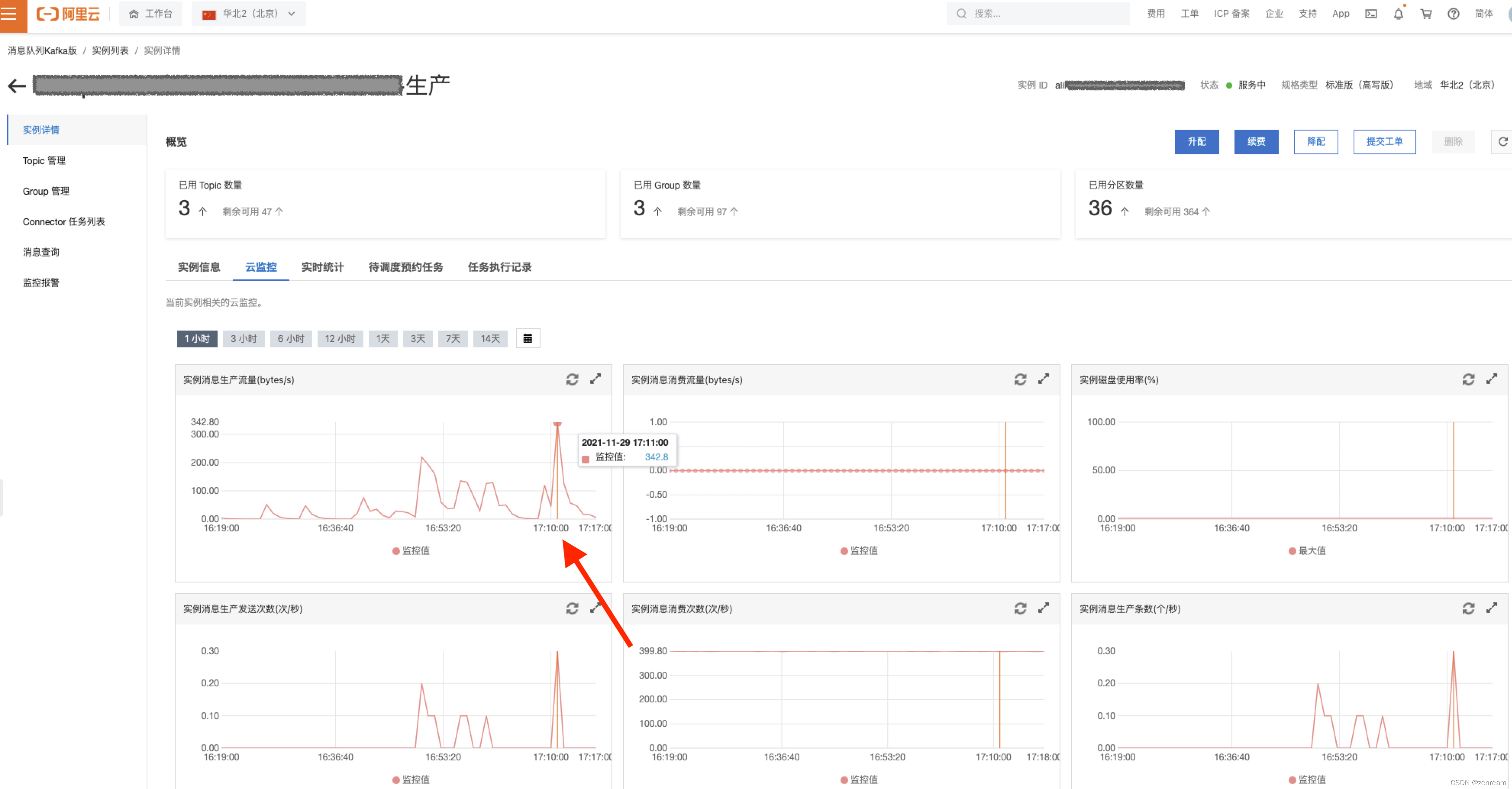
结果:生产端缺少Logstash部分插件,未成功推送数据到kafka,已修复
五、参考
阿里云:kafka自动创建group
阿里云:通过日志服务采集Kubernetes容器日志
阿里云:Logtail采集
阿里云:Logstash消费
阿里云:创建Logstash采集配置和处理配置
socket探测服务接口联通性
阿里云:kafka健康自检指南
感谢在此期间给予帮助的合作伙伴♥️