前言
本章的内容十分丰富,可分为四大类:显著性检验(7.1,7.2,7.3)、似然比检验(7.4)、分布拟合检验(7.4)、非参数检验(7.5,7.6),每一类又有若干种不同的检验方法。本文将重点讲解上述四类检验的基本概念、基本原理,不会详细讲解具体的检验方法。原理弄懂了,具体的检验方法可以参考书中的套路。
一、显著性检验及其基本概念
本节对应书中的7.1节,我按照自己的理解重写了一遍。当我第一次阅读本章的时候,很快就碰壁了(读到“势函数”的时候)。书中关于显著性水平、检验p值的定义也比较抽象,为此我增加了一些描述性的文字,尽量把这些概念、定义解释清楚。最后才对“势函数”进行研究。我把书中遇到的新概念分为以下三类:
(1)参数类(或者称“假设类”)
原假设:
对立假设:
所谓“假设检验”是在部分总体参数未知的情况下,对未知参数进行猜测(提出假设),然后利用抽样结果(证据)对假设进行验证,并作出“接受”或“拒绝”假设的判断。
因此“假设”(名词)是针对未知参数的猜测,它描述了未知参数在参数空间
它具有以下特点:
- 以最常见的情况作为原假设。例如:女士品茶,大部分人不具备区分MT,TM的能力,因此原假设为“该女士无此鉴别能力”;生产合金,设计值不低于110,因此一般情况下合金强度不低于设计值,原假设为
。
- 对立假设分为3种情况:
(2)样本类
检验统计量:由样本观测值组成,用于判断原假设是否成立。它是我们作出检验判断的证据、依据。
检验统计量所在样本空间可以划分为两个不相交的部分:
拒绝域
接受域
(3)概率类
“假设”位于参数空间,“证据”位于样本空间,参数与样本是通过总体分布联系的。因此从“证据”推断“假设”是否成立,不是一个简单的判断题,而是一个概率计算问题。以“假设”为前提条件,出现目前抽样结果的概率是多少呢?我们将根据概率计算的结果,决定拒绝或者接受原假设。
显著性水平
- 第一类错误:当
2. 第二类错误:当
犯第一类错误的概率
犯第二类错误的概率
书中通过“势函数”证明,当样本量固定时,
“费希尔的显著性检验”优先限制犯第一类错误的概率。
显著性水平
显著性水平
检验的p值
对于同样的抽样结果,选择不同的显著性水平
对于同样的抽样结果,有一个特性是不变的,就是样本(检验统计量)位于拒绝域的概率,
这样理解p值是不是比书上的定义容易一些呢?其实它们是一样的,来检验一下:
当
当
由于
(4)势函数
前文详细讨论了“参数、样本、概率”等概念,“势函数”(功效函数)的作用是将三者联系起来,并赋予数学意义上的严谨。
它的形式如下(式1)
另一形式为(式2)
简单解释一下:
- 它是以
- 它的输出是一个概率值(介于0到1之间);
- 本质上,它表示随着参数选择不同,样本统计量X落在拒绝域的概率(式1);形式上,它表示“拒真”和“拒伪”的概率(式2),即原假设为真,样本落在拒绝域的概率;或者原假设为假,样本落在拒绝域的概率。
势函数是假设检验中最重要的概念之一,也不太容易理解。而且一般的题目不会直接使用它,有些书甚至不讲这部分内容。理解和掌握它,对于学习一些较深的内容是有好处的。
下面通过一些例子来加深理解:
设
它的势函数是什么?
既然假设是针对总体均值
首先,建立样本与假设的联系,样本均值
把
当样本均值
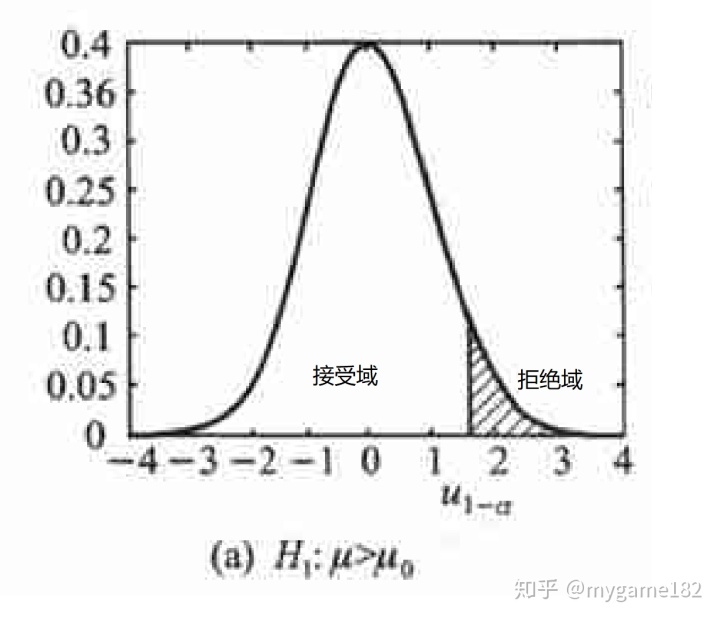
然后,确定检验统计量
由于原假设认为
当
这就涉及
由于
结果得到“拒绝域”
最后,正式研究势函数,根据势函数的定义
已知
已知
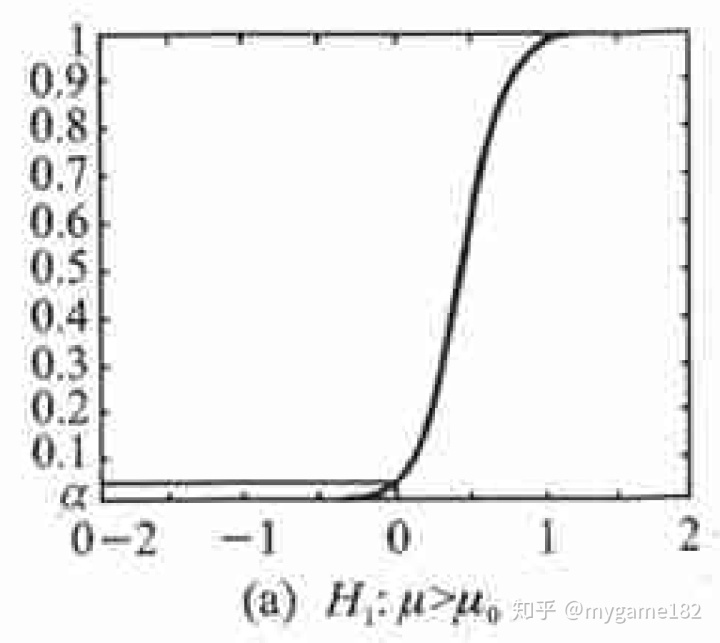
当
由于
位于
结论:
- 由此可见,我们无法脱离显著性水平、检验统计量以及拒绝域来谈论势函数。只根据假设是无法写出势函数的;
- 在确定“拒绝域”的范围后,只需判断
二、 似然比检验
如果说“显著性检验”与区间估计相似,那么“似然比检验”就是最大似然估计法的延伸。
“似然比”,顾名思义,就是两个似然函数之比。
设
似然比的定义如下:
其中sup{}表示函数
注意:
- 分子的参数空间为
- 分母的参数空间为
为什么似然比能够判断原假设的真伪呢?
当原假设为真,两个似然函数的最大值都在
若把
临界值c 可通过显著性水平
三、拟合优度检验
这是一种非参数检验方法,对总体分布的形式建立假设并进行检验。