我想让一列数据按照分组,用数据的大小标准化到百分比 ,最小值为0,最大值为1,发现如果直接用python自带的rank(pct=True)不会得到想要的结果
假设数据集如下(这是我搜索rank命令的时候得到的数据):
以下连接有对rank函数的详细介绍:
https://jishuin.proginn.com/p/763bfbd654b6
data = pd.DataFrame({'班级':['1班','1班','1班','1班','1班','2班','2班','2班','2班','2班'],'姓名':['韩愈','柳宗元','欧阳修','苏洵','苏轼','苏辙','曾巩','王安石','张三','小伍哥'],'成绩':[80,70,70,40,10,60,60,50,50,40]})
data['姓名'] = data['姓名'].str.rjust(3,'〇') 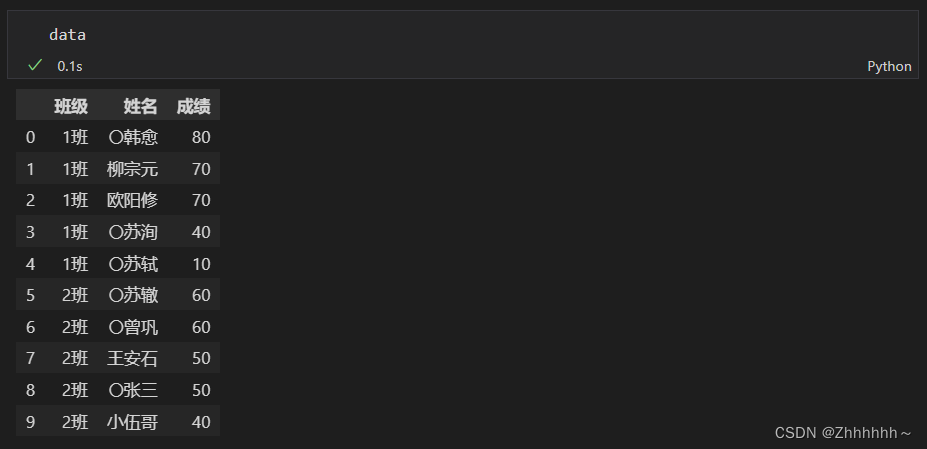
如果使用rank函数,并且想要最低值为0,最高值为1,得到的结果如下
def group_rank(x,col):
max = x.max
count = x.count()[0]
x['成绩排名'] = (x[col].rank(pct=True)-1/count)*count/(count-1)
return x
check = data.groupby('班级').apply(group_rank,col='成绩')
check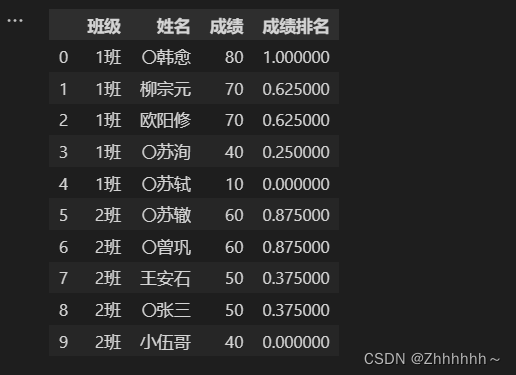
这种rank的百分比,即使标准化到0-1之后,也不是我想要的结果,然后自己写函数:
def check(x,col):
max = x[col].max()
min = x[col].min()
x['percentile'] = (x[col]-min)/(max-min)*100
return x
data.groupby('班级').apply(check,col='成绩')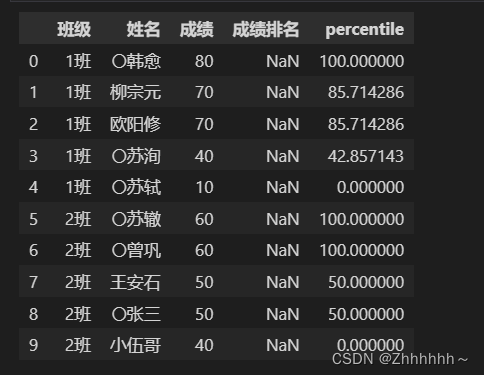
这才是想要的按照值的比例分配后得排名,所以有时候直接用函数可能得不到想要的结果。
版权声明:本文为weixin_49401792原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明。